
基于3D-Mesh互连网络的粗粒度逻辑阵列研究*
2016-11-30 09:17赵宗国戴紫彬耿九光
电子技术应用 2016年5期
赵宗国,李 伟,2,戴紫彬,耿九光
(1.解放军信息工程大学,河南 郑州 450000;2.复旦大学 专用集成电路与系统国家重点实验室,上海 201203;3.71315部队,河南 商丘476000)
基于3D-Mesh互连网络的粗粒度逻辑阵列研究*
赵宗国1,李伟1,2,戴紫彬1,耿九光3
(1.解放军信息工程大学,河南 郑州 450000;2.复旦大学 专用集成电路与系统国家重点实验室,上海 201203;3.71315部队,河南 商丘476000)
提出了一种3D-Mesh拓扑互连网络结构,其支持动态可重构配置,数据路径位宽为32 bit。基于该3D-Mesh拓扑互连网络结构,设计了一种拥有48个 RPE(Reconfigurable Process Element)和 16个 RSE(Reconfigurable Storage Element)的异构粗粒度逻辑阵列(Isomerism Coarse-Grained Reconfigurable Array,ICGRA)。基于COMS 55 nm工艺库进行后端设计,ICGRA总面积为28.52mm2。同时在 300 MHz系统时钟、1.08 V Vcc电压、室温条件下系统总功耗为2.88 W。其中3D-Mesh拓扑互连网络面积占系统总面积的3.8%,功耗占系统总功耗的7%。与相关设计对比,该结构动态重构速率提高2倍~60倍。且采用该3D-Mesh拓扑网络之后,运算单元利用率也大幅度提高。
粗粒度逻辑阵列;片上网络;3D-Mesh;可重构
0 引言
目前,随着PCI-E、USB3.0等高速接口协议的出现,SoC接口的数据传输已经可以达到几吉比特每秒的速率,但是原始的SoC中单核密码处理引擎几十兆比特每秒的处理速度已经远远不能满足需求。许多研究机构为解决密码处理引擎处理速度慢的问题,提出了很多解决方案,其中可重构多核密码处理引擎的研究是现如今比较热衷的一个方向,但是由于随着处理引擎核心数目的增多,面积功耗密度急剧增大,限制了多核密码处理引擎的处理速度,同时也限制了多核密码处理引擎发展速度。

图1 GPP、CGRA和ASIC灵活性趋势
为解决限制多核密码处理引擎发展的问题,许多研究机构开始转向粗粒度可重构逻辑阵列(Coarse-Grained Reconfigurable Array,CGRA)研究。如图1所示,CGRA拥有通用处理器(GPPs)的灵活性和专用集成电路(ASICs)性能的折中。CGRA运算单元的粒度大多按照密码算法的数据宽度确定,一般8 bit、16 bit、32 bit最为常见。CGRA中不需要大容量指令RAM存储指令,不存在译码处理指令,因此CGRA便能够省去大量的读写RAM功耗,在一定程度上极大地降低了功耗。并且CGRA中的硬件资源按照一定的调度适配算法进行适配,可以达到最高的硬件资源利用率与最优的性能指标。现在国内外有许多类似的研究,例如:卡内基梅隆大学提出了基于线性阵列的可重构系统 PipeRench[1];斯坦福大学开发了可重构多媒体阵列协处理器 REMARC(Reconfigurable Multimedia Array Coprocessor)[2];解放军信息工程大学杨晓辉等人提出了基于二维阵列的可重构密码处理模型RCPA[3]等。这些处理架构都是基于同构处理单元设计,其拓扑互连架构都是基于二维结构拓扑互连的,这会导致适配时数据路径拥堵、硬件资源利用率低等问题。
若CGRA中可重构处理单元采用异构布局,会导致适配时不能连续适配,降低了适配灵活性。为解决异构运算单元的影响,本文设计了一种基于 3D-Mesh的异构粗粒度可重构逻辑阵列,其数据网络吞吐率可以达到76.8 Gb/s。基于该ICGRA适配AES算法性能可以达到3.8 Gb/s,适配SM3算法性能可以达到5.5 Gb/s。能够很好地解决密码SoC中高速接口速率高而处理引擎速率低的瓶颈。
1 3D-Mesh拓扑结构
为了更好地研究拓扑互连形式,本章首先讨论了不同的拓扑互连方案与数据路径组织方案,然后提出了一种快速3D-Mesh互连架构,接下来描述了3D架构中双层网络的设计思想与原理,最后给出了粗粒度密码逻辑阵列的总体结构设计方案。
1.1数据流组织方案研究
在现有的研究中,Mesh拓扑由于其规整性与易扩展性被大量采用[4]。Tour拓扑结构由于其具有更大的网络连通性也广受研究人员钟爱[5]。
采用以上两种形式互连结构的阵列中数据处理单元(PEs)采用异构设计会严重影响硬件利用率。但是由于密码运算流程的特殊性,需要设计大量的可重构配置存储部件 S盒(SBox),为了缩小硬件面积,这些存储部件多是用RAM实现,但是就算这样,其面积还是不可小觑。因此这部分硬件资源不能像其他普通处理单元那样设置比较多的数目,因此本文设计了一种异构粗粒度密码逻辑阵列ICGRA。图2为ICGRA的数据路径流图,图中的可重构处理单元(RPE)为密码核心运算单元,其内部是由4类基本的粗粒度密码运算单元以Crossbar全互连的形式互连而成,可以完成密码算法流程中的大部分计算性任务。可重构存储单元(RSE)可以配置成基本数据存储部件,存储运算过程中的轮密钥以及轮运算结果等数据,还可以配置完成密码算法中的S盒运算等查表类运算操作。

图2 ICGRA数据路径组织结构
由于S盒等查表类运算操作在密码流程中所占比例为25%左右,因此本文设计的ICGRA中RPE与RSE交错设置,并且RPE的数量是RSE的两倍。这样能够达到最大的硬件资源利用效率。
1.2拓扑逻辑研究
在现有的研究中,粗粒度密码逻辑阵列中Mesh拓扑结构大多是基于 2维坐标的,Mesh网络中运算单元进行异构设计,必须考虑解决以下问题:
(1)布线通道占用运算单元,降低硬件资源利用率。如图3所示,如果首先在L2列进行运算单元的适配,接下来需要L4列硬件资源(假设L3与L4是异构单元),此时就必须占用L3的布线通道,导致L3的部分运算单元无法使用。
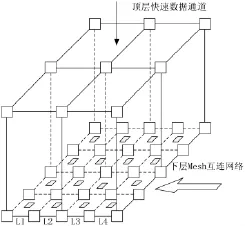
图3 3D-Mesh拓扑架构
(2)增大适配软件与适配算法的设计困难性。由于各列相邻的运算单元是不同的,所以适配软件所看到的可用资源就是不同的,因此设计软件和算法时就增加了极大的困难性。
为了解决以上两个方面的问题,本文提出了一种3D-Mesh拓扑互连架构。如图3所示,设置了上下两层Mesh互连网络,两层网络在特定的数据节点可以进行数据交互。本文设计的双层网络中,下层网络为异构Mesh网络,内部包含运算单元、布线通道、配置单元以及数据方向转换单元;上层没有运算单元,并且其数据方向转换单元与配置单元数量为下层网络的50%。这样设计可以最大程度提高网络内部异构单元的利用率。
采用该3D拓扑互连架构,L1与 L3、L2与L4之间都存在快速数据交互通道,如果将L1数据交换到L3,可以采用顶层数据交互通道,不影响L2资源的正常使用,极大地提高了硬件资源的利用率;其次所有的布线通道在适配软件看来是完全相同的可用资源,即适配软件和适配算法设计的过程中,资源相当于同构存在,降低了软件的设计困难性。
1.3网络微结构研究
图4所示是本文设计的3D-Mesh拓扑架构网络微结构。该拓扑网络共有两层,底层是标准的Mesh拓扑网络结构,如图4(a)所示,内部有数据方向转换单元和数据计算单元。上层是数据通道层,如图4(b)所示,有隔行或列的快速数据交换通道,能够完成数据的快速交换且不占用计算单元周边的数据交换通道。
两层网络可以靠双层网络连接点电路进行数据交换,如图4(c)所示。底层对应位置的CB结构增加一个输出端口,通过双层网络连接点连接至对应顶层CB一个输入端口。顶层CB输出的数据通过双层网络连接点接至RPE(或RSE)的数据层数据选择器的输入端,选择之后再进入RPE(或RSE)。因此每一个RPE(或RSE)数据输入来源虽然增加了,但是其输入端口并没有增多。设计适配软件和适配算法时,仅是增加了可利用的数据通路资源,并不会增加设计复杂度。

图4 3D-Mesh拓扑网络微架构
在进行阵列设计时,充分考虑了其易扩展性,底层Mesh网络设计时进行了方向无差别设计,即底层网络中任意一个数据节点(除阵列边缘)可以与其上、下、左、右任意方向的相邻节点进行数据交互。特别设计了如图4(d)所示的SB(Switch Box)数据方向转换节点,可完成任意方向输入数据向其它3个方向进行数据分配的功能。
1.4阵列架构研究
基于前文设计的3D-Mesh网络结构,设计了如图5所示的粗粒度密码逻辑阵列结构。为了充分发挥3DMesh网络结构的灵活性以及其计算单元的性能优势。必须有一个合理的粗粒度阵列架构支撑。

图5 粗粒度可重构阵列架构
(1)动态配置信息切换机制
在设计粗粒度密码逻辑阵列架构的过程中,设计了分页式的配置信息存储结构:Conf.reg0和 Conf.reg1,可支持配置信息动态切换。两页配置存储结构中的配置信息互不影响,在一页配置信息应用时,另一页可以更换。根据适配算法由主控制器MCU动态选择所需要的配置页面,并将其内部配置信息写入到 3D-Mesh网络结构中,完成硬件结构动态重组。
(2)分离式节点控制网络
由于3D-Mesh拓扑网络中的数据方向控制节点分立于网络中,通过配置可以完成数据方向的改变,但是密码算法的典型特征就是轮运算形式。通常一轮运算中硬件结构是不需要改变的,且循环迭代多轮,如何实现轮数控制,这在3D-Mesh数据网络中是不能完成的。基于此,本文为3D-Mesh数据网络上层特别设计了一层分立式节点控制网络。其可以完成轮数计数、比较、判断等控制性操作。由于该层控制结构独立于数据网络,并且分立式设置,因此更大地增加了数据网络的灵活性。
2 路由算法研究
本文设计时,对提出的3D-Mesh网络理论上进行了合理性分析与论证。但要想能够发挥架构的性能,还需要一种合理的适配路由机制。基于此,本文针对提出的3D-Mesh拓扑网络,设计了一种硬件资源寻路适配算法,如表1所示。
在使用算法1进行算法适配时,如果数据需要隔行或列跳转,如图6中所示,从R1直接跳至R3。此时有两条可用选择路径,其中路径A为:R1→C1→C2→C3→R3;另一条路径B为:R1→C1→C4→C5→C3→R3。虽然路径B经过4个CB节点,而路径A只经过3个CB节点,但是路由算法还是会选择路径B。因为路径A中C1、C2、C3都是直接与 RPE(或 RSE)相连接的 CB节点,其路径长度为3,路径B中只有C1和C3是直接与RPE(或RSE)相连接的CB节点,其路径长度为 2,所以从此处看来路径B相比于A为最短路径。

表1 就近资源寻路算法
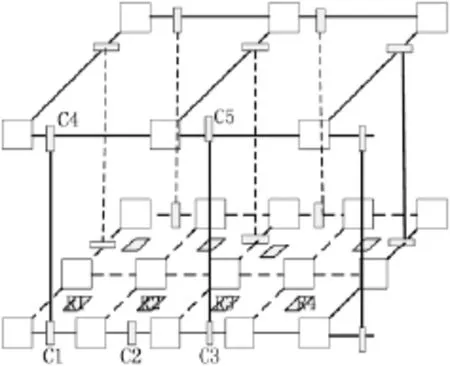
图6 寻路算法路径长度计算示意图
3 性能分析与对比
表2描述了本文设计的 3D-Mesh拓扑结构与相关的文献中的Mesh(或Tours)拓扑结构在粗粒度逻辑阵列中应用的对比。由于拓扑逻辑结构不同,寻找相同的对照点是非常困难的。表2中展示了一些相似的关键性能参数。由于不同设计所采用的工艺不同,且针对领域和功能单元数量不同,设计总面积没有可比性。但是通过表中数据可以看出,本文设计的 3D-Mesh互连网络所占整个 ICGRA面积的3.8%,比文献[7]中 2D-Mesh的7%节省一半。功耗评估结果显示,互连网络占 ICGRA总功耗的2.8%,相比同类设计,网络功耗所占比例也大幅度降低。在300 MHz系统时钟主频下,对网络数据吞吐率进行了评估,可以达到76.8 Gb/s。因为本文中采用了动态重构设计,可以支持系统运行时重构,且重构仅用5个系统时钟周期左右,是文献[5]动态重构速度的2倍,是文献[6]重构速度的60倍。
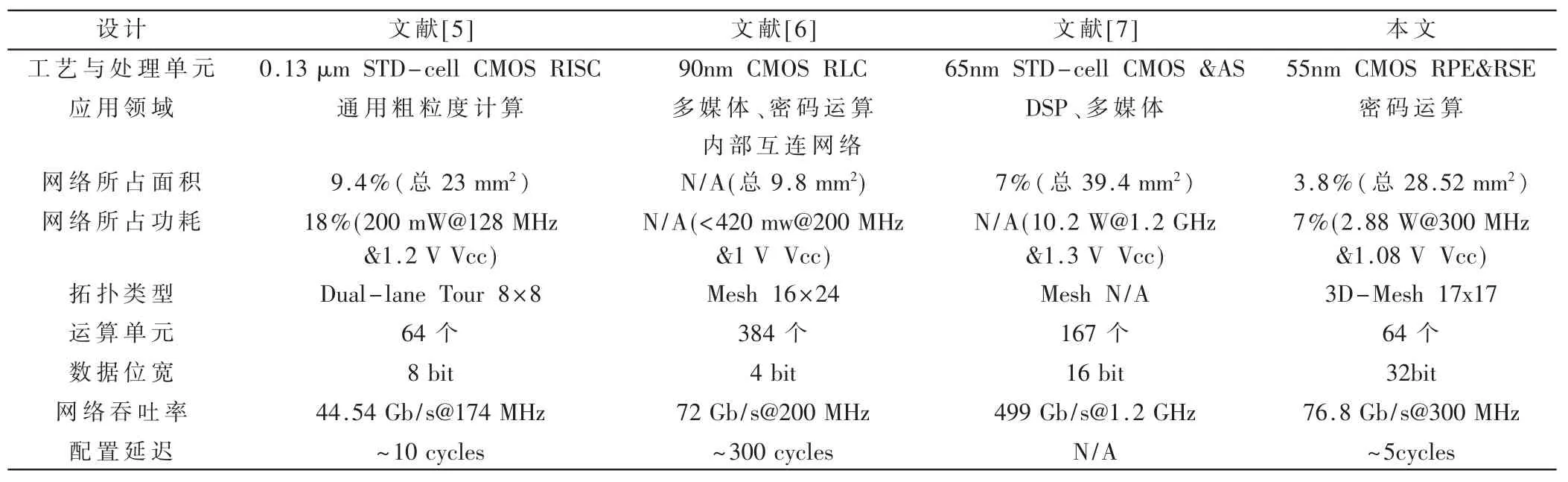
表2 相关性能参数节点对比
4 总结
本文针对粗粒度可重构逻辑阵列提出了一种3DMesh拓扑网络结构,通过与相关设计进行对比,可以看出该 ICGRA具有更高的数据吞吐率和更低的功耗,且其支持动态可重构配置,配置速率相比于同类设计提高2倍~60倍。在SoC系统设计中,非常适合内部嵌入该ICGRA,打破了密码 SoC中接口速率快而处理引擎速率低下的瓶颈。
[1]GOLDSTEIN S C.PipeRench:A coprocessor for streaming multimedia acceleration[C].Proc.of the 26th Annual Int’l Symp.on Conputer Architecture,IEEE CS Press,Los Atlamtos,Calif.2000.
[2]MIYAMORI T,OLUKOTUN K.REMARC:Recongurable multimedia array coprocessor[C].IEICE Trans,Information System,1999:389-397.
[3]杨晓辉.面向分组密码处理的可重构设计技术研究[D].郑州:解放军信息工程大学,2007.
[4]Kunjan Patel.SYSCORE:A coarse grained reconfigurable array architecture for low energy biosignal processing[J].IEEE International Symposium on Field-Programmable Custom Computing Machines,2011:109-112.
[5]PHAM P H.An on-chip network fabric supporting coarsegrained processor array[J].IEEE T ransactions on very large scale integration(VLSI)systems,2013:178-182.
[6]ROSSI D,CAMPI F,SPOLZINO S,et al.A heterogeneous digital signal processor for dynamically reconfigurable computing[J].IEEE J.Solid-State Circuits,2010,45(8):1615-1626.
[7]TRUONG D N,CHENG W H,MOHSENIN T,et al.A 167-Processor computational platform in 65 nm CMOS[J].Solid-State Circuits,IEEE Journal of,2009,44(4):1130-1144.
Research on 3D-Mesh topology interconnection network in the coarse grained reconfigurable cryptographic logic array
Zhao Zongguo1,Li Wei1,2,Dai Zibin1,Geng Jiuguang3
(1.PLA Information Engineering University,Zhengzhou 450000,China;2.State Key Laboratory of Fudan University Special Integrated Circuit and System,Shanghai 201203,China;3.The 71315 Army,Shangqiu 476000,China)
This paper presents a 3D-Mesh interconnection network structure with 32 bit data path,which can support dynamic reconfiguration.Based on the 3D-Mesh topology interconnection network structure,a new type of isomerism coarse-grained reconfigurable array with 48 RPE and 16 RSE is designed.Based on the 55 nm COMS process library to design,the total area of ICGRA is 28.52mm2.At the same time,total power consumption of the system is 2.88 W@300 MHz&1.08 V Vcc in the room temperature.The network area of 3D-Mesh topology is 3.8%of the total area of the system,and the power consumption is 7%of the total system power.In comparison with the related classes,the structure dynamic reconstruction rate is 2~60 times higher.After using the 3D-Mesh topological network,the utilization rate of the arithmetic unit is also improved greatly.
ICGRA;network on chip;3D-Mesh;reconfigurable
TP309.7
A
10.16157/j.issn.0258-7998.2016.05.008
国家自然科学基金(61404175)
2015-10-11)
赵宗国(1990-),男,硕士研究生,主要研究方向:安全专用芯片设计。
李伟(1983-),男,讲师,主要研究方向:专用集成电路设计。
戴紫彬(1966-),男,教授,博士生导师,主要研究方向:专用集成电路设计、芯片可重构设计。
中文引用格式:赵宗国,李伟,戴紫彬,等.基于 3D-Mesh互连网络的粗粒度逻辑阵列研究[J].电子技术应用,2016,42 (5):27-31.
英文引用格式:Zhao Zongguo,Li Wei,Dai Zibin,et al.Research on 3D-Mesh topology interconnection network in the coarse grained reconfigurable cryptographic logic array[J].Application of Electronic Technique,2016,42(5):27-31.
猜你喜欢
保健医苑(2022年4期)2022-05-05
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26
哈尔滨工业大学学报(2022年5期)2022-04-19
摄影世界(2022年1期)2022-01-21
数学小灵通(1-2年级)(2020年6期)2020-06-24
学与玩(2018年5期)2019-01-21
知识经济·中国直销(2018年12期)2018-12-29
商周刊(2017年6期)2017-08-22
中学生数理化·八年级数学人教版(2017年2期)2017-03-25
语文世界(小学版)(2016年9期)2016-09-14
