
成品油零售顾客分级的探索研究
2016-12-12 12:24张蕾甄超姜卫
现代营销·学苑版 2016年10期
张蕾+甄超+姜卫
摘要:顾客分级的目的是清晰地识别不同价值的顾客,为企业的营销决策提供依据。目前,大部分企业用消费额度、消费频率等单一指标(价值维度)进行分级。该做法方便快捷、便于管理,但容易丢失部分有价值顾客。本文结合加油卡顾客的数据,进行了价值维度选取、指标判断、量化分析、模型聚类等方面的探索研究,并通过某省四年的数据进行了实证分析,根据聚类模型结果和实际营销需求给出了零售顾客分级的建议。
关键词:顾客分级;聚类模型;RFM模型
顾客分级的目的是清晰地识别不同价值的顾客,为企业的营销决策提供依据。目前,大部分企业用消费额度、消费频率等单一指标(价值维度)进行分级。该做法方便快捷、便于管理,但容易丢失部分有价值顾客。一些银行信用卡、航空公司及B2C电子商务卡,以复合指标(如信用卡用户的存款余额、持卡时间、信用历史、消费种类等)进行分级,可更全面地分离出高价值顾客。
一、国内外应用与研究现状
1.顾客分级的作用和目的
一般意义上讲,顾客分级是按照一定的标准将企业现有顾客分为不同群体,依据其年龄、性别、收入、职业、地区等信息来衡量其对企业的不同价值和重要程度。排序后确定为不同的层级,为企业资源分配提供依据。其必要性体现在三个方面:一是不同的客户带来的价值不同;二是企业的资源有限,需要根据投入的回报情况进行合理分配;三是顾客需求多样化,对企业的需求期待存在差异。分级为企业的资源分配提供依据,从而牢牢抓紧最有价顾客,提高客户关系管理效率。
2.顾客分级应用现状
目前我国的顾客分级主要应用于银行信用卡业务、航空公司以及B2C电商三个领域。
银行信用卡业务。我国商业银行信用卡体系在运行过程中产生了大量的睡眠卡,引起资源浪费、客户流失、信用风险增加、业务效率低下等问题。通过对客户按照一定的标准进行合理细分,有利于发卡银行进行有效的风险管理,提高整体效益。目前银行信用卡客户分级的方法包括对客户的信用评级以及根据客户的透支行为、消费行为、贡献性进行分级。
航空公司。美国西北大学教授Paul Wangle曾经在研究中指出,旅客分为交易旅客和关系旅客两种,而一般来说,机票打折真正吸引的是交易旅客,这种旅客对比所有航空公司的票价之后进行购买。客户分级则能够帮助航空公司把不同种类的客户区分开来,通过把营销成本花在最该花的旅客上,使得成本达到效率最大化,降低运营成本。
B2C电子商务。通过对不同群体的客户进行分析,可以使电子商务运营商明确不同客户需求,使得运营策略得到最优的规划;还可以发现潜在客户,进一步扩大商业规模。相比传统商务模式,电子商务由于由商务网站运行,可以提供大量的购物客户的信息,使得电子商务更合适进行客户的分级。
3.顾客分级的研究现状
目前的顾客分级方法主要使用单一维度分类、多个因素聚类以及RFM模型等方法。单一维度分类就是按照某种维度,比如消费累计额度的多少对顾客进行分级,额度越高级别越高。这种方法在零售行业的应用较为广泛。多个因素聚类是一种对具有共同趋势和模式的数据元组进行分组的方法,各类之间的相似程度很小;而在类的内部,数据相似程度很大。比如在银行的信用卡客户分类上,可根据开卡客户的存款余额、持卡时间、信用历史、消费种类等信息对客户进行聚类,后续通过决策树、判别分析等方法对新客户进行预测性分类。RFM模型是通过三项变量,即最近消费时间间隔 (Recency)、消费频率(Frequency)、消费金额(Monetary)来细分客户,形成顾客评级指标。目前在航空业、电子商务等方面的应用较广。
综上所述,顾客分级是企业围绕顾客需求,有效配置营销资源的手段;且在应用和研究方面的发展都较为成熟。目前的中国成品油零售的顾客分级方法仍停留在单一维度的指标方面,虽然操作简单,但是在顾客的立体化描述、需求刻画等方面的准确性较差。有必要应用新的数据和方法对中国成品油零售的顾客分级进行新的探索研究。
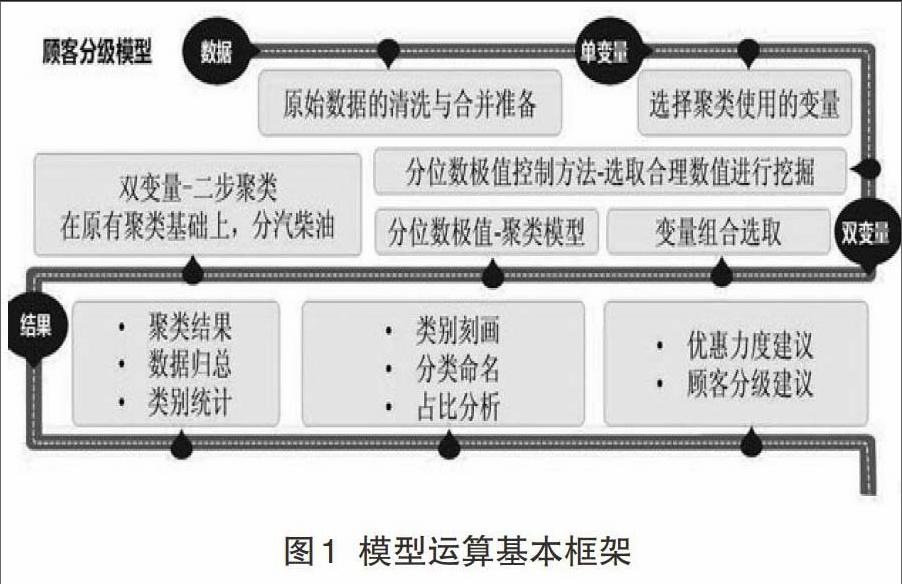
二 、模型设计和基本方法
传统的顾客分类模式主要是根据整体的汇总数据,根据不同维度来进行分类,大多使用的是基本的统计分布计算方法。随着信息技术的完善,目前顾客分类模式有所改变,其改善方式以数据挖掘及数据分析为主,常用的数据挖掘技术包括关联分析、序列分析、分类分析、聚类分析、预测、孤立点分析等,同时也对用于模型运行所需的数据量提出了新的要求。在成品油零售行业,根据单一维度进行顾客分类已经较为普遍,但是在数据的使用和方法上仍然较为传统。本文在数据和方法上进行了发展和改善,并进行了探索性的实证研究。
1.数据来源及清洗方法
本文使用的数据主要来自顾客消费过程中由设备自动记录的数据,包括顾客在加油站发生的充值、消费行为数据。主要包括充值额度、充值时间、充值低点、消费额度、消费时间、消费地点、消费类别等数据指标,时间范围是2010年1月1日-2014年10月30日。
为了保证分级的数据质量,需要对数据进行筛选和清洗。根据数据特点,本文作者使用相关的方法进行了处理。主要包括三点:一是充值和消费数据都存在分布不平均得问题,因此难以兼顾等额与等量分割,为解决此问题,模型主要使用一般聚类方法。二是数据中异常值大且多,数据统计及散点图显示,数据样本中异常值大量且广泛的分布在数轴的右侧,很难自动归为一类;为解决此问题,可以考虑用分位数对极值加以限制,排除异常值后再进行聚类。三是数据量大,一般来说某个省连每年的消费记录在300万条以上,样本量约50万,在没有大型计算机的情况下应选择较为简单的算法。
2.基本思路
第一步:从五个维度判断顾客价值
(1)消费总额:顾客实际购买总额越高,对企业的价值越大。(2)充值总额:顾客提前储存的价值,是顾客品牌忠诚的体现;充值总额越高的顾客黏性越大,潜在价值越大。(3)消费次数:意味着顾客的行为忠诚,消费次数高的顾客有可能每次加油都在本公司;他们心理上忠诚于中石油的品牌,更有可能推荐顾客,为企业创造价值。(4)充值次数:顾客在行为上信任该品牌;(5)消费类别:购买高利润油品的顾客对企业的价值更大。
第二步:以消费和充值为指标的双变量顾客分级方法
可从五个指标中选择消费总额和充值总额作为顾客分级的基本指标,将消费类别作为区分指标进一步细分顾客群体(以利营销)。主要考虑有二:一是消费次数与消费总额、充值次数与充值总额高度相关,可合并考虑;二是消费次数虽然能够体现顾客忠诚(心理上的),但准确判断顾客是否因为自身忠诚进而向其他顾客推荐等,实际操作难度较大,暂不考虑。这种分类可以同时评价两个维度的顾客价值:一是实际消费中贡献的价值(显性价值);二是由于忠诚而产生的价值(隐性价值),即某时期内该顾客充值总额度非常高。按照这一思路,至少应分离出四类顾客,即两个维度的排列组合:消费低+充值少、消费低+充值多、消费高+充值少、消费高+充值高。
第三步:以汽油、柴油、非油毛利及沉淀资金利息等进一步细分级别
顾客价值主要体现在其消费和充值行为对企业的利润贡献,因此汽油、柴油、非油、沉淀资金等给企业带来的利润差异是决定顾客分级的主要标准。因此,在分档的基础上,再考虑这些差异(或者给以系数,以利综合测算);或者给以某种级别以利有针对性的营销。对高档次的顾客,这种级别递增的分级方式有助于针对性营销,鼓励顾客进入高级别序列。
3.模型优化
一般来说,传统顾客分类主要使用的是分类分析方法,可以简单地概括为“先定类别,再分类”。即通过分析具有类别的样本的特点,得到决定样本属于各种类别的规则或方法,利用这些规则和方法对未知类别的样本分类时应该具有一定的准确度。
在成品油顾客分类时,利用分类技术,可以根据顾客的消费水平和基本特征分类。对于大数据基础上的顾客分类,主要使用的是聚类分析方法,即“先分类,再定类别”。即根据物以类聚的原理,将本身没有类别的样本聚集成不同的组,并对每一个这样的组进行描述的过程,其主要依据是聚到同一个组中的样本应该彼此相似,而属于不同组的样本应该足够不相似。
根据前文所述的数据特点以及分析思路,本研究构建的分析模型如下:一是直接进行单变量聚类,其目的是通过聚类对顾客消费行为单个属性进行分析,研究变量在多维度聚类中是否可用。二是在初步聚类的基础上,尝试90%-99%的不同分位数控制聚类,目的是选择合适的分位数,既能够排除异常值又能够保证整体聚类的准确性。三是选择合适的变量完成多维度聚类,并在聚类结果的基础上根据营销业务需求确定顾客分级情况。
三、实证分析
基于以上分析,研究人员提取了某省个人记名卡数据(消费记录约1500万条,记名卡数量约75万),建立了四年数据基础上的训练集,通过SAS统计聚类模型进行了实证研究。
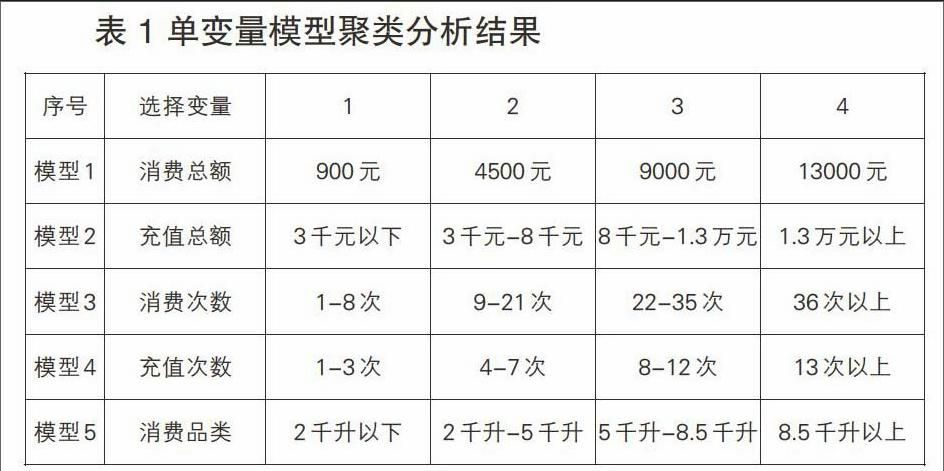
1.单一指标聚类模型
采用“分位数控制极值-快速聚类”的方法 构建单变量维度分级模型,使用消费总额、充值总额、消费次数、充值次数、消费品类(购买量)分别构建了五个模型,按照4级分类。
模型运算过程中,尝试了90%-99%分位数下的聚类方式,发现90%分位数可以更加显著地对目标客户群体进行聚类,在此情况下对客户的分级更为清晰,特征更为明显。以单变量对顾客初步聚类分析结果,可以从不同角度探究客户的整体数量上的分布结构。
从变量指标的由低到高来看,在所选取的样本中,位于最低水平的客户数量大约在46万左右,占比大约65%;其次数量大约在16万左右,占比大约20%;再往上数量大约在6万左右,占比大约10%;再往上客户数量大约在2.3万左右,占比大约5%;水平最高但水平分布较分散的客户数量大约在8万左右,占比大约10%左右。不同指标的聚类数据量存在一定的差异,但整体上都符合这一比例。具体维度上的顾客分类的均值如下表所示。
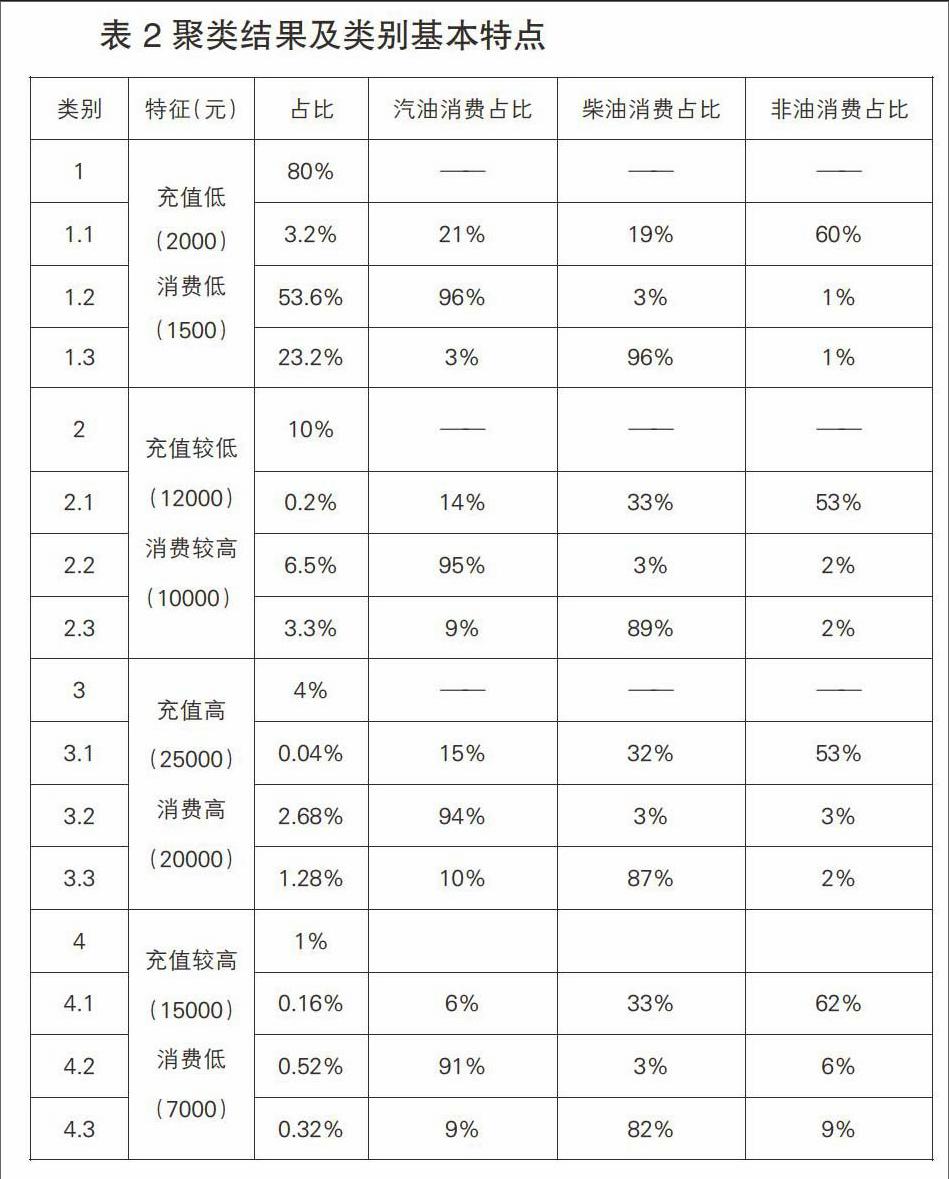
2.多变量聚类模型
按照前文所述研究思路,多变量聚类模型分为两步完成。
首先采用与单变量聚类模型同样的方法,综合消费总额和充值总额两个指标完成模型构建(次数选择95%分位数进行控制)。聚类组合是两个维度排列组合产生的结果,模型运行产生四档顾客:充值低+消费低、充值较低+消费较高、充值高+消费高、充值较高+消费较低。
再进一步聚类,可细分至汽油、柴油(亦可以测算非油)顾客。对已经形成的四类样本加入消费类别变量后再聚类,返现有必要对第一类顾客进一步分类,主要理由有:一是第一类顾客占比较高,达到全部样本的80%,有必要根据顾客行为习惯进一步划分;二是发现第一类顾客在行为习惯方面存在明显的差异, 以非油消费为主的顾客汽油消费占比偏高,不同于其他三类。
最后,给定“汽油、柴油、非油毛利率、沉淀资金利率”等财务指标,汽油和非油毛利率高于柴油,在相同消费情况下汽油和非油消费者对公司的价值相对较高;消费行为能够实际转化为公司的利润,实现顾客价值,而充值行为只能产生沉淀资金,通过资金利率实现利润,在相同情况下消费多的顾客对公司价值相对较高。因此,将第一大类中柴油消费占比较高的1.3单独列为一类,得到5级分类结果,具体特征描述如下表:
3.营销参考
模型运行结论在具体营销过程中,需要根据实际情况测算具体的优惠或者回馈力度。本文使用5级李克特量进行大体描述,1表示最低,5表示最高。具体的分级参考见表4,其中普通级顾客占比约为25%,对其消费和充值不做标准限值,只要使用本公司加油卡即可纳入顾客管理范畴;次中级顾客数量占比约60%,消费额标准为1500元(考虑到实际营销中一般以500元的倍数区分档次,这里同样使用500元的倍数),充值额标准为2000元;中级顾客数量占比约为1%,消费额标准为7000元,充值额标准为15000元;次高级顾客消费额和充值额标准约为10000元和12000元;高级顾客消费额和充值额标准为20000元和25000元。
如上分级后,至少可以作如下营销方面考虑:普通级顾客消费额及充值额均偏小,维护营销必要性不强。次中级顾客占比最多,是主要营销顾客群体,不但优惠力度要高于普通级顾客,策略上还应鼓励其多充值以增加顾客黏性。中级顾客占比最少,这一级设置的主要目的是增大对次中级顾客的吸引力,故优惠力度应有较大幅度跨越(顾客数少,总成本不高);针对这一级顾客消费低、充值多的特点,策略上应鼓励其增加消费。中高级顾客忠诚度较高,应适当提高优惠力度,策略以持续维护为主。
四 、应用前景
本文所述模型属于静态模型,使用过去实际发生的顾客行为数据测算训练集,根据聚类结果形成顾客分级的建议标准。此模型的优点有:一是能够根据已有数据信息,给出明确的分级分档建议,有助于公司制定政策、员工营销讲解、顾客熟知了解。二是对成品油零售中的顾客消费行为指标选择进行了筛选,突破了单一维度分类分级的局限性。
静态模型的缺点在于,随着时间的变化顾客行为会有所变化,无法根据顾客行为变化指标实现动态监测和及时营销。因此,如果能够利用加油站的信息系统,在现有静态模型的基础上引入RFM动态化指标(消费或者充值时间间隔 Recency、消费或者充值频率Frequency、消费或者充值金额Monetary),则能够更好地实现对加油站零售顾客的针对性维护和营销。
参考文献:
[1][美]科特勒,凯勒著.梅清豪译.营销管理(第12版)[M].上海:上海人民出版社,2006.
[2]邵焱,谭恒.刘玉芳.现代市场营销学[M].北京:清华大学出版社,2007.
[3]刘浩熙.数据挖掘在客户关系管理综合决策中的应用[D].北京邮电大学硕士论文,2008.
[4]于亚飞,周爱武.K-Means 聚类算法的研究[J].计算机技术与发展,2011,21(2)
[5]王永贵等.基于顾客权益的价值导向型顾客关系管理——理论框架与实证分析[J].管理科学学报,2005,12(8):27-36.
[6]刘义,万迪,张鹏.基于购买行为的客户细分方法比较研究[J].管理科学,2003,16(1):69-71.
