
基于云平台的数据储存与文件管理研究
2016-12-12 05:44辛跃华
科教导刊 2016年28期
辛跃华
摘 要 当前数字信息和互联网技术快速发展,基于互联网的应用和服务层出不穷,随之而来的是,网络之间需要处理的数据也是呈现出几何倍数增长。对大量数字信息和服务数据给予及时处理,并且向用户提供安全有效的网络服务,变得极为关键。随着云计算的出现,为数据的处理方式提供了有效的方案,利用虚拟机、网络资源池、共享存储存储器等技术,用户可以便捷的进行应用的迁移和扩展,进而使得传统的PC机作为处理模式的方式逐渐被淘汰。不过伴随着云计算的逐渐使用,如何获得高效率、低成本的存储空间与管理云端大数据逐渐成为很多研究人员关注的热点问题,这需要具有良好的云端平台以及优化的数据库结构、处理模式设计。
关键词 数字信息 云计算 数据库
中图分类号:TP311.52 文献标识码:A DOI:10.16400/j.cnki.kjdks.2016.10.024
Abstract The digital information technology and the Internet have rapid development, the use of the Internet to is used to provide service to all kinds. At the same time, the network between the need to deal with the data is also showing a geometric ratio growth. For a large number of service information and data to give treatment, and to provide users with safe and effective network services, has become extremely critical. With the advent of cloud computing, making for processing of these data for the effective solution to provide its proposed use of fast and convenient Internet technology and has a high security data storage technology, which makes the traditional PC as a way of processing mode is gradually phased out. But with the growing use of cloud computing, to obtain high efficiency and low cost of storage and management of a cloud of data gradually become a lot of enterprises and researchers have paid attention to the problem, which need to have good cloud platform and database structure, and the process model of the design.
Keywords digital information; cloud computing; database
0 引言
在信息化快速发展的今天,互联网内部的数据越来越多,其服务的种类也是越来越多,伴随着数字技术和智能终端技术的进步,以及网络带宽的扩展,网络通讯量爆炸式增长,给互联网系统带来严重负担。目前存在一个问题,即在互联网内部系统资源利用效率不高,一些应用需要大量的计算与储存资源,而另外一些系统的资源大部分处于空闲状态。对这些问题,解决的要点是实现资源与计算能力的虚拟化,解决海量数据的管理和存储,通过分布式共享机制提升服务质量。云计算自提出以来,受到了业界的普遍关注,很大程度上改变了整个IT技术发展的方向。
云计算是一种全新的计算方式,基于网络基础架构的虚拟化,使之具有安全可靠的数据存储与处理能力,进而使得传统的PC作为基础的信息处理模式发生了很大变化。因为云计算技术具有分布式、可扩展、高性能、高可靠等优势,较以往以数据库为中心的计算模式,具有很好的发展潜力与优越的性能。伴随着企业信息化的不断发展,大部分数据开始在网络上多个节点中分散存储,网络间对这些数据的快速传播逐渐成为人们越来越关注的问题。由于云计算逐步广泛应用,对这些数据的管理以及存储如何实现快速和较低成本,也是人们关注与研究的热点问题。特别是针对那些对云计算有着专门研究的相关机构,其首先要解决的问题就是要摆脱传统的存储模式,其原因就是大量的新增数据出现,那些旧的存储方式以及信息处理模式已经无法为新的业务和计算流程提供服务。针对上述问题,本文设计一种新的数据存储解决方案,能够利用云计算技术,以及文件虚拟化管理模式,为面向爆炸式增长的数据提供快速访问和读写服务。
1云计算平台中数据存储方式
1.1数据模型
存在于云计算平台的大部分数据都属于半结构化数据或是结构化数据,利用分布式数据库管理保存这些数据。分布式数据库必须为每个数据集建立一个稀疏的、长期储存的、多维度的映射表格。用户将数据存储在表格内部,在每一行里面都含有一个排序的主键以及任意多个数列。不过因为稀疏程度不同,在一张表格的内部每行数据都是不同列进行排列。例如对名字的格式定义为<族>和<标签>,利用的都是字符串的基本结构模式,每一张数据表格都是具有一个合集,这样合集模式不会改变,等同于关系表基本关系结构模型。但是label数值对所有行都能够进行有效变更,通过改变表面结构来实现有关变化。
针对分布式数据库来说,每一个关系表都拥有一个目录,其对应的表数据文件都存储在该目录下,对文件的操作都属于数据库内部封闭操作,即我们能够将每一行当作是一个原子元素,对所有元素都能够实施加锁。在更新每一个关系表的时候要标记好更新时间。在更新数据后会进行新版本的获取,同时在数据内部还会留有原来版本,这样的数值就是能够以时间为依据来开始有关设置,比如说针对两个最新的版本,或者就是要对近四天的版本进行保存。在客户端能够对距离某时间最近的版本进行选择利用,或是对所有版本进行一次获取。
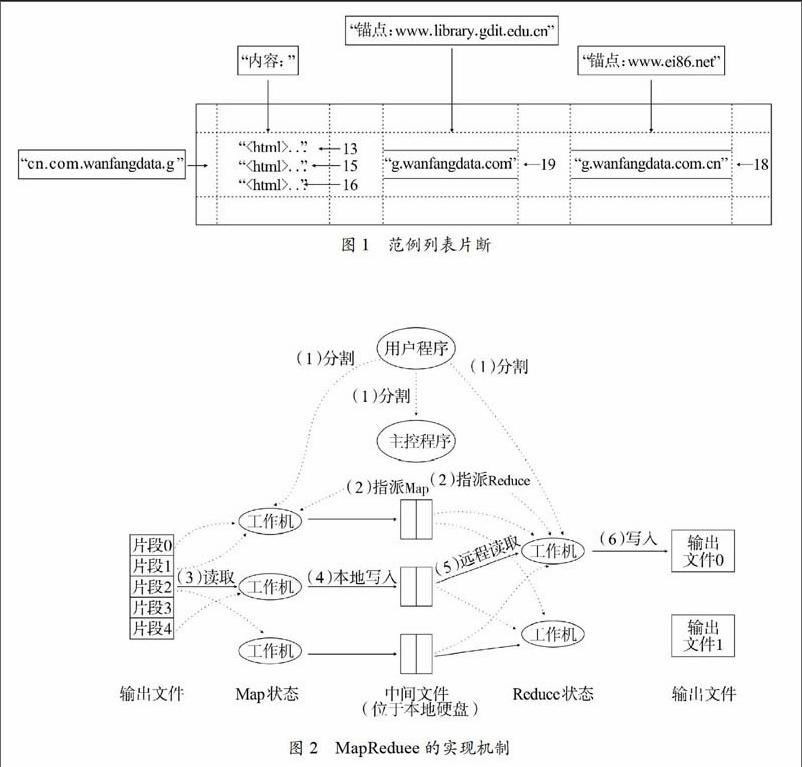
如图1所示,每一行的主键名是一个反向URL,例如cn.com.wanfangdata.g,在基本阵列族存放网页内容,锚点列族存放网页链接文本,例如wanfangdata的主页被企业信息网(http://www.ei86.net)的主页所利用,因为该行含有名叫做“锚点:www.ei86.net”的列。对于每一个锚链只具有一个版本,利用的标记装置为时间戳,比如具有t9以及t8等,但是对于内容表项,具有的版本可以多项化,例如图1中划分了三个时间戳,标记为t3、t5以及t6。
1.2分布式数据库体系结构
在服务器所具备的体系结构中,需要以主从服务器具备的基本结构为依据,借助于服务器节点集群的资源,并通过Master来管理操作分布式数据库。节点服务器所具备的主要功能是节点访问模式,对于内部slave服务器节点,在主master服务器内会将这些节点进行同时注册。此时若是主服务器出现故障,则会导致整个系统瘫痪,我们采用双备份冗余机制来避免此类问题的发生。由主master服务器切换到从master服务器,并获取slave服务器列表。节点同主服务器的关系保存在节点内部,其他类型节点被分配到不同服务器中。同时依据数据列表含有的特征函数,主服务器需要时刻感知节点所在位置,用户可以在自己的客户端上获得相关节点的元数据信息和具体位置信息。云计算的数据表格与传统关系数据库存在非常大的不同,云计算属于稀疏分布类型,其中存在的映射和排序非常多,而传统关系数据库则相反。所有以模式为基础的映射数据库仅能够进行键-数据的映射模式的表示,这对数据库的结构进行了极大简化。
2数据的处理结构
在文件分布式存储问题上面,利用并行数据处理引擎MapReduce软件可以很好的解决这类问题,其可以对海量数据给予非常好的处理,并且根据编程模式,能够有效处理大规模数据的并行运算过程。这种处理模式有着非常多的优点:
首先就是对容错、并行处理模式的封装,并且针对计算进行本地化的处理,使得那些比较小的节点也是可以获得均衡的负载,同时在外部还具有强大功能的数据接口。然后就是拥有良好的通用性。最终使其能够对很多不同问题给予有效解决。MapReduce实现的机制如图2所示。
MapReduce的主要处理流程包括以下操作。其一是分割,首先把输入文件切分成若干小份,数据块大小为16M-4MB不等,其可以通过用户设定的参数来获得,集群能够对有关操作进行实现,启动集群内部大部分任务。第二就是能够借助于Map/Reduce来对有关任务进行初始化并执行,在大部分执行程序中来进行管理主控程序的主机,其他部分中存在的工作机都是通过制定的模式完成的。对于主控程序来说,主要任务就是指派空闲的工作机来完成相关任务。其三为对程序的读取,对于指派的Map任务来说读取相关数据,在输入数据内部获得相关的数值,这些数值被用户定义的Map函数处理之后被转存到缓存区域。其四为本地写入,针对向内存进行缓存的中间键值会以函数存在的周期特点为依据,分别放入R个不同区域,并且在本地磁盘之中进行写入。第五为在远端读取,对于执行规约任务的工作机被通知这些键数值具体的位置之后,可以利用远程控制的模式来获得Map任务工作机里面具有的本地缓存的数据。第六位对文件数据给予传输,对Reduce工作的判别是通过其所有的中间数据来实现的,该中间数据借助于唯一一个中间关键字来同其所发送的关键字进行对应,并通过中间数值为Reduce函数进行定义。在完成Reduce任务以及Map任务后,在管理机构会执行有关程序,并向程序使用起点进行返回,接着开展前面的程序操作。
3.云存储平台的数据库设计
3.1系统基本结构
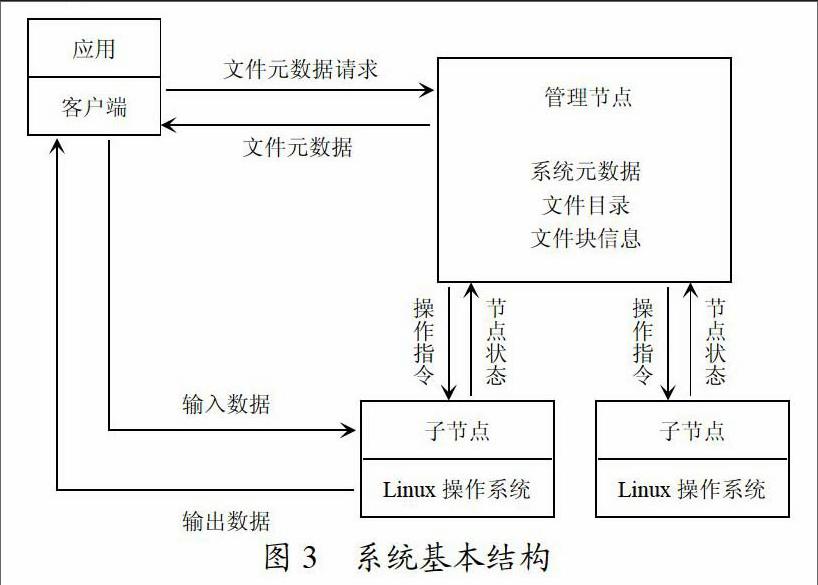
依据云计算系统具有的基本结构,本文设计的云存储平台主要功能模块以及基本结构如图3所示。在这个结构里面,管理节点对所有子节点和用户端关键信息进行存储,主要包括文件块信息、文件目标还有系统的元数据。客户端发出对文件元数据的读写请求,管理节点接收到该指令后,会以请求的信息为依据读取客户端的数据信息并返回。在客户端获取到源文件数据后,便能够在子节点连接所需数据,来实现数据的输入和输出,同时其还能对子节点以及节点间的联系进行管理,保持畅通,在对数据进行输入时,管理节点能够借助于操作指令来降低子节点的资源占用率,子节点会向管理节点进行变更信息的返回。
对于文件的存储组织模块,利用的基本单元是数据块。一个文件可以具有很多的块,在每一个块里面仅可对一个文件内容给予有效存储,文件大小是64M。该种选择存在很多优势:首先可以减少访问量,进而使得客户端与管理节点之间的交互大大减少,同时如果用户需要对同一个文件块进行读写操作的时候只需要向客户端管理节点提出请求,就可以完成相关的操作。其次,能够有效降低网络内部消化,能够在对大文件持续访问时,借助于保持节点数据TCP长连接来对网络开销给以有效降低,最终使得管理节点的管理得以减少。
3.2云计算中文件分布式存储流程
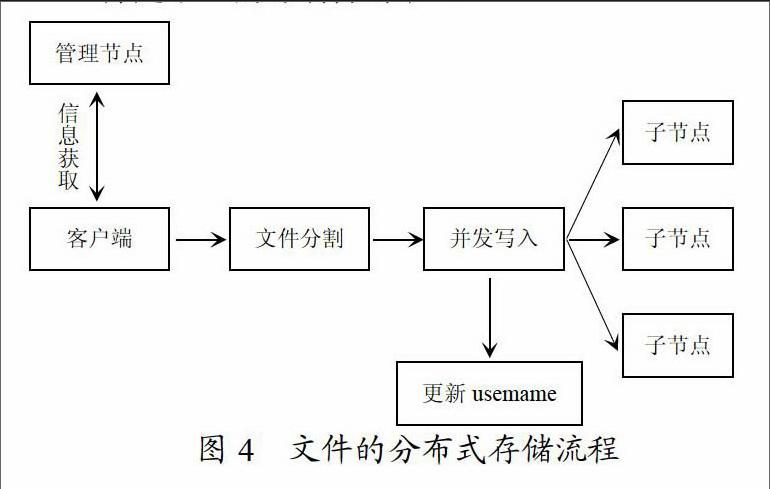
在实现命令数据以及信息数据的传输的时候是要借助不同计算机进行的。命令数据的CMD作用主要就是有效管理节点以及子节点,借助于命令数据对其需要实现的任务进行判断。信息数据系统可对每一个任务实现数据的拷贝,比如对文件信息部分以及具有的信息功能进行相关的描述,不过这些数据一般具有比较大的数据量。我们通过将计算迁移到存储的方式,降低传输压力,在系统中用户文件数据的传出是非常少的,这极大的提高了系统的运行效率。在进行文件的存储的时候,系统应该先借助于客户端同管理节点的连接对其含有的root.dat文件来说通过数据模式来读取,提供给用户的是有效节点位置的IP地址信息。在利用node.dat文件来获得相关的位置信息,由于管理节点对子节点的IP地址列表来获得相关的信息,利用上面具有的信息对多线程的数据进行启动与连接等活动,同时还可以对这些数据进行分别存储,最后最终对username表进行更新以此来在访问过程中进行文件分布状况的重新获取。在某个节点上进行username文件的存储,管理节点便以现存username文件的分布状况为依据,将节点的IP地址分配给用户来进行username文件的存放,文件名便成为用户的用户名,因为系统中用户名具备唯一特性,因此所有的username都是唯一的,具体见图4。
在图4中,主要借助消息传递机制,利用基础函数接口对MPI程序进行描述来完成为文件的并行写入和分割,MPI程序能够快速获取机器名和进程标志,并对比较阻塞的信息进行传递,实现复杂数据结构的传递,以此来有效实现Map/Reduce并行计算功能。
4 结束语
本文针对在云计算环境下存在的文件管理以及数据存储的安全模式进行深入研究,在对云计算服务进行有效利用的基础上,对其优势:高性能和低成本以及弹性计算和存储能力给予充分发挥,使得云计算平台中存在的成本较低和高速的数据存储问题进行有效解决,针对存在的云储存问题提出了一种灵活的解决方案。
参考文献
[1] 王德文. 基于云计算的电力数据中心基础架构及其关键技术[J]. 电力系统自动化,2012,v.36;No.48911:67-71,107.
[2] 曲朝阳,朱莉,张士林. 基于Hadoop的广域测量系统数据处理[J]. 电力系统自动化,2013,v.37;No.50604:92-97.
[3] 王德政,申山宏,周宁宁. 云计算环境下的数据存储[J]. 计算机技术与发展,2011,v.21;No.16804:81-84,89.
[4] 董浩浩,韩德志. 一种基于大数据处理的异构私有云系统[J]. 数学的实践与认识,2014,v.4405:157-165.
[5] 费贤举,王树锋. 基于云环境下的海量大数据存储系统设计[J]. 计算机测量与控制,2014,v.22;No.19007:2259-2261,2273.
猜你喜欢
财经(2017年2期)2017-03-10
电脑知识与技术(2016年21期)2016-10-18
大学教育(2016年9期)2016-10-09
科技视界(2016年20期)2016-09-29
北极光(2016年4期)2016-06-06
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
数字技术与应用(2014年12期)2015-05-04
中国高新技术企业(2015年10期)2015-03-19
