
基于Redis实现HBase二级索引的方法
2016-12-15 02:47史金鑫
软件 2016年11期
崔 丹,史金鑫
(1. 北京邮电大学网络技术研究院,北京市 100876;2. 上海欣方智能系统有限公司北京分公司,北京市 100085)
基于Redis实现HBase二级索引的方法
崔 丹1,史金鑫2
(1. 北京邮电大学网络技术研究院,北京市 100876;2. 上海欣方智能系统有限公司北京分公司,北京市 100085)
随着大数据时代的到来,海量数据对传统数据库技术提出了存储和检索性能的挑战。HBase是开源NoSQL数据库,适合于各种非结构化和半结构化的松散数据的存储和管理,目前已经被很多大型企业用于处理海量数据。它基于rowkey的有序存储,对rowkey支持毫秒级的快速检索。然而,随着HBase应用的不断深入,单一的通过rowkey检索数据的方式不再满足需求,在实际应用中,经常需要根据指定字段,或者几个字段进行组合检索。针对该问题,本文提出了一种基于Redis创建HBase 二级索引的方法,使得在实际应用中,支持多条件查询,提升查询的效率和性能。
大数据;HBase;二级索引;rowkey;Redis
本文著录格式:崔丹,史金鑫. 基于Redis实现HBase二级索引的方法[J]. 软件,2016,37(11):64-67
0 引言
随着信息技术的发展,网络己经成为人们交流、娱乐等活动的主要工具,互联网的内容越来越丰富,数据规模也愈加庞大[1]。一些国内外著名的社交网站Facebook、Twitter、LinkedIn,搜索网站Coogle、Yahoo、Baidu、Sougo,购物网站Amazon、Taobao等大型网站,它们的用户规模庞大,网络请求并发性高,需要处理甚至级的数据[2]。大数据时代的到来,对传统关系型数据库的存储和检索性能提出了挑战,无法满足这么大规模数据的高效存储与高并发读写需求。为了解决这个问题,一些公司、研究结构纷纷开发云上的数据库系统,它们统称为NoSQL。NoSQL是指用于存储和处理大规模结构化或非结构化数据,能够随着数据规模增大而扩展的数据库系统[3]。
HBase(Hadoop Database,Hadoop数据库)是参照Google Bigtable实现的开源NoSQL数据库,它具有强一致性、高性能随机写、面向字段且可动态修改、可水平伸缩的特性,适合于各种非结构化和半结构化的松散数据的存储和管理,目前已经被很多大型企业用于处理海量数据[4]。然而,它本身还存在着一些问题, 如仅支持主索引结构,不支持跨行事务等,这些问题都严重制约着HBase的进一步发展。针对该问题,本文提出了一种基于Redis实现HBase二级索引的方法,对HBase表中涉及条
件过滤的字段和rowkey在Redis中建立索引,通过Redis的多条件查询快速获得符合过滤条件的rowkey,之后在HBase中通过获得的rowkey进行查询,提升多条件查询的效率和性能。
1 HBase二级索引技术研究
随着大数据时代的到来,海量数据的规模超过常规数据库工具获取存储管理和分析能力。大数据具有5V1C的特征:数据量巨大(Volume)、数据类型繁多(Variety)、生成速度快(Velocity)、数据易变化(Variability)、数据真实性(Veracity)、数据复杂性(Complexity)[5]。HBase数据库在存储大数据方面性能较好,但是需要进一步优化对海量数据的结构化查询。由于HBase基于rowkey的有序存储,对基于rowkey的查询十分高效,然而进行关系型数据库那样可以随意组合的多条件查询、查询总记录数、分页查询等表现不佳。目前,可通过以下两种方法解决该问题。第一种方法是使用HBase提供的过滤器,该过滤器可以对HBase中的数据在多个维度上进行检索操作。该方法使用起来简单,但局限性较大,过滤器直接扫描HBase表,如果数据表范围很大,会导致查询速度很慢。第二种方法是实现HBase二级索引,通过查询二级索引获得符合条件的rowkey,然后再通过rowkey查询HBase数据。该方法适用范围比较广泛。
二级索引方案类似于关系数据库中的二级索引,为了实现对非rowkey的查询,需要为每一个索引列构建一个索引表,实现索引列与原有rowkey的映射[6]。目前实现HBase二级索引的方法主要是以下两种:
第一种方法通过HBase协处理器生成并访问索引数据,将索引数据单独存储为一张表。该方法的缺点是数据表与索引表的数据一致性很难保证,访问两张不同的表也会增加远程调用的次数和IO开销。
第二种方法是将数据和索引数据存储在相同的分区里,将索引数据定义为一个单独的字段族,也是需要通过协处理器来生成并访问二级索引数据。该方法中,单表的数据容量会急剧增加,对多个字段族进行拆分或合并等操作时可能会造成数据丢失或不一致。
2 基于Redis实现HBase二级索引方法
Redis是一个开源的使用ANSIC语言编写、支持网络、可基于内存亦可持久化的日志型、高性能的Key-Value数据库[7]。根据官方的bench-mark数据,测试完成50个并发执行100000个请求,设置和获取的值是一个256字节字符串时读的速度可达到110000次/s,写的速度可达到81000次/s。它支持存储的数据类型包括字符串、链表、集合、有序集合和哈希类型。通过使用集合和有序集合实现对非rowkey的精确查询和范围查询创建不同的二级索引,以提升多条件查询的效率和性能。
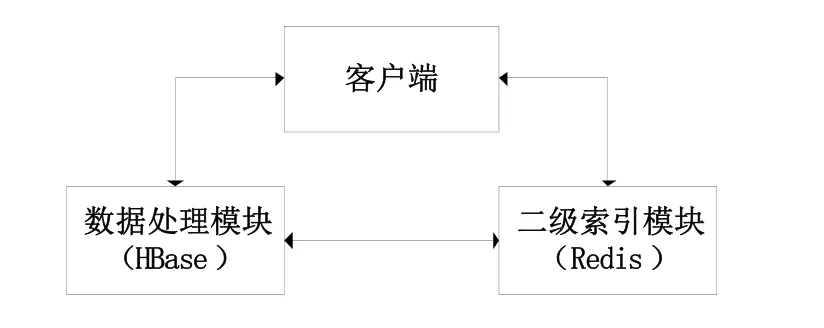
图1 基于Redis实现HBase二级索引的组成结构Fig.1 the structure of achieving the HBase secondary index based on Redis
如图1所示,基于Redis实现HBase二级索引的系统组成主要包括客户端、数据处理模块、二级索引模块。客户端发出数据更新、查询、删除请求,数据处理模块对请求进行分别处理,进行数据的更新、查询和删除,相应地,二级索引模块根据客户端的请求进行二级索引的更新、查询和删除。基于Redis实现HBase二级索引时,协处理器相当于一个回调函数。协处理器通过配置可以实现作用到HBase中所有表,也可以单独指定作用到一张表。当用户操作get/put/delete 数据的时候,HBase的regionserver会在 get/put/delete 方法的时候,回调一个实现协处理器类中的方法,方法中可以获得你get/put/delete的数据,从而实现构建二级索引的操作。
HBase在对非rowkey进行检索的过程如图2所示。将HBase表中涉及条件过滤的字段和rowkey在Redis中建立索引,通过Redis的多条件查询快速获得符合过滤条件的rowkey值,再根据获得的rowkey在HBase中通过rowkey进行查询,进而提高查询的效率。
3 HBase二级索引数据结构设计
在实际应用中,对HBase数据的查询包括两种,一是基于rowkey条件查询,此时不需要对HBase表中数据建立二级索引便可获得较高的查询速度;二是基于非rowkey的条件查询,包括精确查询和范围查询,此时可通过Redis的set和sorted set实现
二级索引,进而获得较高的检索效率。set和sorted set类型极为相似,它们都是字符串的集合,都不允许重复的成员出现在一个set中。它们之间的主要差别是sorted set中的每一个成员都会有一个分数(score)与之关联,Redis正是通过分数来为集合中的成员进行从小到大的排序。然而需要额外指出的是,尽管Sorted-Sets中的成员必须是唯一的,但是score)是可以重复的。
以HBase中数据表为例,如表1,对age建立二级索引:
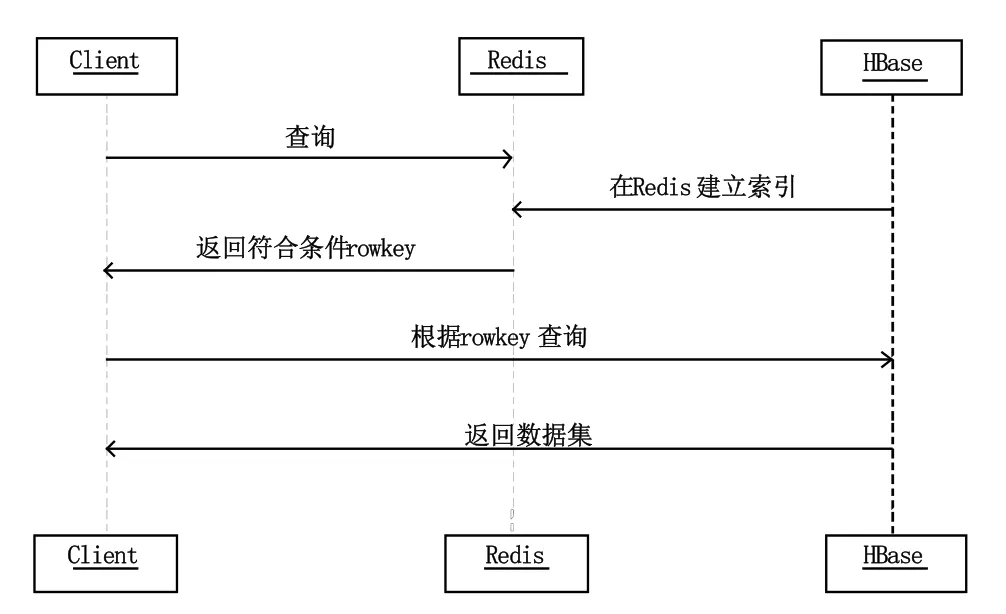
图2 基于Redis实现HBase非rowkey查询过程Fig.2 the process for HBase non-rowkey query based on Redis

表1 HBase数据表Tab.1 a data table of HBase
基于非rowkey的精确条件查询,建立的二级索引结构为key-value,key为列名_值,value为rowkey。使用Redis的set类型进行存储,sadd(key,value)添加二级索引,生成的二级索引如表2所示下:

表2 Redis中set存储二级索引Tab.2 the secondary index stored in Redis set
基于非rowkey的范围条件查询,建立的二级索引结构为key-score-value,key为列名,score为列值,value为列值_rowkey。使用redis的sorted set类型进行存储,方法zadd(key,score,value)添加二级索引,score是按序存储的。生成的二级索引如下:

表3 Redis中sorted set存储的二级索引Tab.3 the secondary index stored in Redis sorted set
4 HBase二级索引数据结构设计
本文在Centos 6.5上部署分布式HBase和Redis系统,安装的软件版本是JDK1.7.0_55,Hadoop 1.1.2,HBase 0.96.2,Redis 3.2.1。在对HBase建立二级索引之后,分别对HBase系统进行了插入和查询数据两方面的性能测试。
本文使用插入语句进行测试,分别在插入语句条数为1 W、10 W和100 W的时候进行测试,并针对列足否有索引的情况分别进行测试。为了减少测试误差,采用多次测试然后取平均值的方法进行测试。插入性能的测试结果如表4所示:
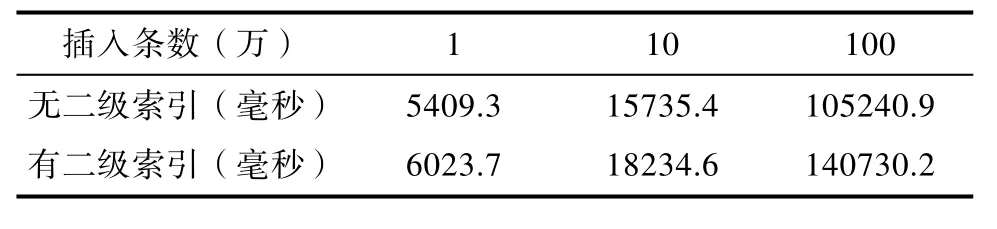
表4 HBase的插入性能测试结果Tab.4 the results of testing for HBase insert performance
根据测试结果可知,在实现二级索引的情况下,插入数据需要耗费更多的时间。这是因为,在HBase中插入数据后,还需要触发协处理器创建相应的二级索引存入Redis。在有索引和无索引的时插入数据,会随着入库数据的条数增加而增加。这两种情况下在HBase插入操作都是根据rowkey进行插入的,而数据表是按照rowkey顺序分布式存储的,因此在需要建立二级索引的情况下多花费的时间即为写入Redis的时间。
本文使用查询语句对HBase查询性能进行测试,分别在查询语句条数为1 W、10 W和100 W进行测试。查询性能的测试结果如表5所示:

表5 HBase的查询性能测试结果Tab.5 the results of testing for HBase select performance
根据测试结果可知,在实现二级索引的情况下,HBase查询性能极大提升。这是因为HBase在执行基于rowkey的查询时,查询速率很高,而在建立二级索引的情况,系统会将对非rowkey的查询,通过查询Redis中的二级索引获得符合条件的rowkey,再通过rowkey在HBase中获得数据集,间接地将基于非rowkey的查询转化为基于rowkey的查询,获得较高的查询效率。
本文对上述所有测试结果进行综合分析,得出如下结论。釆用二级索引能够极大提高数据査询的效率,实现海量数据旳实时查询。通过二级索引进行数据查询、更新和删除操作时,都是先对索引表按rowkey查询取得索引数据,再根据HBase表的rowkey进行相应操作。按照rowkey顺序进行存储,根据rowkey进行查询操作的效率很高。
5 结论
本文提出了一种基于Redis实现HBase二级索引的方法,当客户端向HBase中写数据时,触发协处理器,根据当前表的索引规则在Redis中创建二级索引。在创建二级索引的过程中使用了数据库连接池,减少了由于不断创建新连接的开销,实现快速构建二级索引。在该方法中,实现了多表对应一个协处理器的机制;可对索引字段进行灵活配置,以满足精确查询和范围查询的需求;实现基于内存数据库的二级索引存储机制,将HBase数据表生成的二级索引存储在Redis内存数据库。当客户端发出查询请求时,可以快速查询二级索引,大幅提升访问效率。
[1] 李国杰, 程学旗. 大数据研究: 未来科技及经济社会发展的重大战略领域——大数据的研究现状与科学思考[J]. 中国科学院院刊, 2012, 27(6): 647-657. LI G J, CHENG X Q, XUE W W. Big Data Research: Major Strategic Fields for Future Technology and Economic and Social Development-Research Status and Scientific Thinking of Big Data[J]. Chinese Academy of Sciences, 2012, 27(6): 647-657. (in Chinese)
[2] 王珊, 王会举, 覃雄派等. 架构大数据: 挑战、现状与展望[J]. 计算机学报, 2011, 34(10): 1741-1752. WANG S, WANG H J, QIN X P, et al. Architectural Big Data: Challenges, Status Quo and Prospects[J]. Chinese Journal of Computers, 2011, 34(10): 1741-1752. (in Chinese)
[3] 卢益阳. NoSQL数据管理系统综述[J]. 企业科技与发展, 2011, (17): 31-33. LU Y Y. A Survey of NoSQL Data Management System[J]. Enterprise Science Technology and Development, 2011, (17): 31-33. (in Chinese)
[4] 卓海艺. 基于HBase的海量数据实时查询系统设计与实现[D]. 北京:北京邮电大学,2013. ZHUO H Y. Design and Implementation of Real - time Query System Based on HBase for Massive Data[D]. Beijing: Beijing University of Posts and Telecommunications, 2013. (in Chinese)
[5] 孟小峰, 慈祥. 大数据管理: 概念、技术与挑战[J]. 计算机研究与发展, 2013, 50(1): 146-169. MENG X F, CI X. Big Data Management: Concepts, Technologies and Challenges[J]. Computer Research and Development, 2013, 50(1): 146-169. (in Chinese)
[6] 马友忠, 孟小峰. 云数据管理索引技术研究[J]. 软件学报, 2015, 26(1): 145-166. MA Y Z, MENG X F. Research on Cloud Data Management Index Technology[J]. Journal of Software, 2015, 26(1): 145-166. (in Chinese)
[7] 曾超宇, 李金香. Redis在高速缓存系统中的应用[J]. 微型机与应用, 2013, 32(12): 11-13. ZENG C Y, LI J X. Application of Redis in Caching System[J]. Microcomputer and Its Applications, 2013, 32(12): 11-13. (in Chinese)
Implementation of HBase Secondary Index Based on Redis
CUI Dan1, SHI Jin-xin2
(1. Network Technology Research Institute, Beijing University of Posts and Telecommunications, Beijing 100876, China; 2. Shanghai Cintel Intelligent System Co., Ltd. Beijing Branch, Beijing 100085, China)
With the arrival of the big data era, these massive data challenges traditional storage and retrieval performance for traditional database technologies. HBase is open source NoSQL database, suitable for a variety of unstructured and semi-structured data storage and management of the loose, and has been used by many large enterprises to deal with massive data. It is based on the rowkey of the orderly storage, supporting millisecond-level rapid retrieval based on rowkey. However, with the deepening of HBase applications, a single rowkey retrieval of data by no longer meet the needs of more applications. The practical applications often need to specify the field, or a combination of several fields to retrieve. To solve this problem, this paper proposes a method of creating HBase secondary index based on Redis, which can support multi-conditional query and improve query efficiency and performance in practical application.【Key words】: Bid data; HBase; Secondary index; Rowkey; Redis
TP311
A
10.3969/j.issn.1003-6970.2016.11.015
崔丹(1990-),女,硕士研究生,主要研究方向为数据库集群中间件负载均衡技术
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
当代陕西(2019年14期)2019-08-26
意林图解作文(小学版)(2019年6期)2019-07-16
铁道通信信号(2018年10期)2018-12-06
专利代理(2016年1期)2016-05-17
中国石油企业(2014年4期)2014-11-30
河南科技(2014年24期)2014-02-27
测绘科学与工程(2014年2期)2014-02-27
质量与标准化(2010年5期)2010-05-03
质量与标准化(2010年3期)2010-05-03
