
基于协同过滤算法的个性化图书推荐系统研究
2016-12-15 19:41肖斌徐佳庆张宇洋
电脑知识与技术 2016年27期
肖斌+徐佳庆+张宇洋
摘要:针对高校数字图书馆对读者需求信息挖掘不足,无法主动为读者提供个性化图书推荐服务的问题。该文引入所罗门学习风格量表,多维度、全方位的构建读者特征模型,并提出基于随机算法与协同过滤推荐算法的混合推荐算法。首先,读者通过数据量表测试得到其学习风格,然后根据读者的浏览矩阵,在同种学习风格的用户群体中进行用户之间的相似度计算,最后采用Top-N的策略向用户进行图书推荐,为读者提供符合其个性特征的图书。实验结果表明,应用该算法能有效提高系统的推荐质量,达到良好的推荐效果。
关键词:协同过滤;图书推荐系统;个性化推荐;混合算法;学习风格量表
中图分类号:TP301 文献标识码:A 文章编号:1009-3044(2016)27-0155-04
Abstract:Aiming at the problem of digital library in Colleges and universities lack of reader demand information mining, unable to provide personalized book recommendation service for readers. In this paper, we introduce the Solomon learning style scale, multiform dimension, construction of a full range of readers feature model, and puts forward a hybrid recommen-dation algorithm based on the random algorithm and user based collaborative filtering . Firstly, the reader by amount of data scale test get their learning style, then according to the readers browsing matrix, in the same learning style of the user groups of users between similarity calcu-lation, finally adapt the top-N strategies to recommend books to users, provide the reader with the book that satisfies their personalized need.Experimental results show that the proposed algo-rithm can effectively improve the quality of the recommend system and perform significantly better.
Key words:collaborative filtering; book recommendation system; personalized recommendation; hybrid algorithm; learning style scale
1 概述
如今,高校图书馆的图书储量非常丰富,但是,读者想要准确快速找到符合自己个性化需要的图书资源却比较困难。一方面,信息资源过于庞大,检索信息需要花费很大的时间和精力,另一方面,用户的个性化需求也不尽相同,难以满足所有用户的实际需求。如何利用现代信息技术满足读者在学习生活中的个性化需求是当前高校图书馆一个亟待解决的问题。通过对海量的信息进行数据挖掘,同时基于挖掘出的知识开展个性化的图书推荐是当前高校转变服务方式,提高服务质量的有效手段之一。
目前,主流的非结构化文本数据推荐服务分为基于内容的推荐,基于关联规则的推荐和基于协同过滤的推荐等三类。其中,基于内容的推荐,是在没有足够的数据下,可以向具有不同兴趣偏好的用户推荐非流行的项目。LIBRA是很早的基于内容的图书推荐系统,由每位用户提供的训练例子,使用贝叶斯学习算法,从Web提取图书的标题等信息,推荐图书[1]。其特点是,算法简单,查准率和查全率较高。但是内容提取的能力有限,面对高校的数量庞大,内容复杂的信息资源难以准确全面进行内容挖掘。而基于关联规则的推荐是根据用户浏览或者购买的日志生成规则,通过生成的规则来推算用户可能还会对哪些商品感兴趣[2],最早的基于关联规则的推荐系统有IBM的Websphere,ILOG和BroadVision等等。在图书推荐领域,引用关联规则是为了发现借阅记录中不同图书之间的关联规则,当多本书存在一定的置信度,支持度,则存在一定的关联[3]。其特点是,算法复杂,查准率较高,但同时它无法发现读者的新的或者隐含的阅读兴趣,容易生成无效的规则。基于协同过滤的推荐思想是认为用户的兴趣偏好是可以通过具有类似行为或偏好的用户群进行分析和预测得出的,利用最近邻预测技术,预测当前用户可能感兴趣的项目[4]。它适用于在有足够的用户数据的时候,可以向具有相同兴趣偏好的用户推送受欢迎的推荐,但是数据往往是稀疏的[5]。
在高校的特定的信息环境中,馆藏资源数量庞大,类型各异且学科覆盖广泛,大量的跨学科,跨专业乃至新型学科和边缘学科图书的存在,造成基于内容的图书推荐系统所构建的模型很难全面准确表征图书资源的内容,因此推荐质量比较低,难以满足高校师生对推荐资源的个性化的需求。高校图书馆读者较高的借阅频次,相似的知识结构以及共同的知识背景,使得高校图书馆存在着大量相似度较高的借阅记录,基于规则的推荐难以提供产生合适的关联性规则,最终难以推荐符合读者个性化需求的图书资源。
基于以上的研究,为了达到更好的推荐效果,可以将读者进行分类,构建出读者的学习风格模型,根据读者表现出的具体的学习风格,推荐符合其学习特征的图书,并依据该模型采用改进的协同过滤算法开展个性化的图书推荐,以较低的计算复杂度,挖掘包含读者潜在兴趣在内的个性化信息需求,达到为高校读者提供高质量的个性化的图书推荐服务的目的。
2 基于协同过滤的个性化图书推荐模型
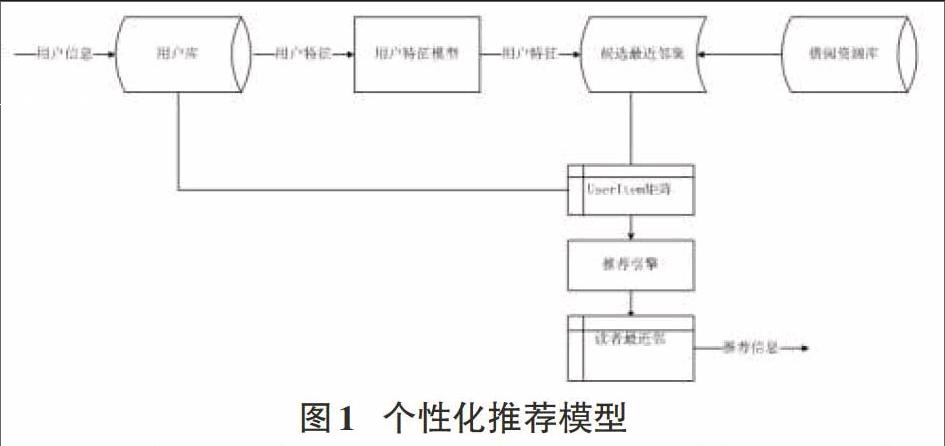
传统的基于项目评分的协同过滤算法仅依据用户的信息获取行为及评分情况进行预测,缺乏对触发用户信息需求动因的深层次的分析,因此无法从本质上保证预测结果的准确性,而且容易造成数据稀疏。本文提出一种改进的基于协同过滤的个性化图书推荐模型如图1所示:
在该模型中,当读者登录系统时,首先引导用户进行数据量表的数据测试,显式地将用户进行分类,并构建出读者的模型库。当新的读者登录系统并已经拥有了自己的学习特征风格时,就在读者模型库中找到其候选的最近邻集,再根据最近邻集构建User-Item矩阵,并产生目标读者的最近邻,最后根据目标读者最近邻的阅读行为挖掘出与读者个性化需求相匹配的图书,实现对目标读者的个性化推荐。
2.1 读者特征模型的构建以及候选最近邻的生成
Felder-Silverman量表(也称所罗门学习风格量表)是由Felder和Solo-man于1997年开发。它从信息加工,感知,输入和理解四个方面将学习风格划分为4组,分为8个维度,包括:活跃型与沉思型,感悟型和直觉型,视觉型和言语型,序列型和综合型。用于系统前测推断用户学习风格,已经得到越来越多的研究者的认可,其具有良好的实用性和信效度,能够比较全面反应学习者的学习风格。
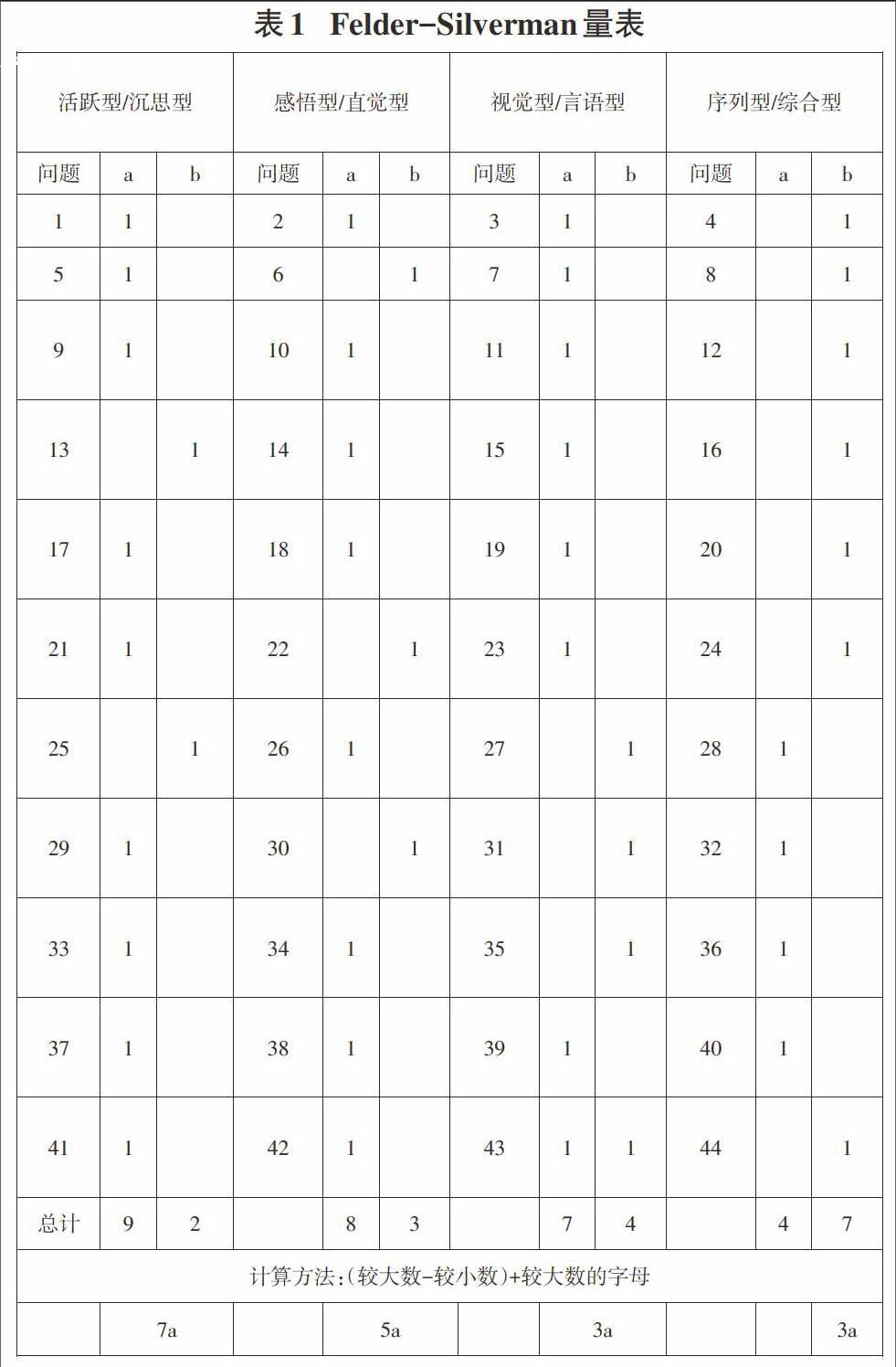
学习者的学习风格是依据 Felder-Silverman 学习风格问卷(Index of Learning Styles Questionnaire,ILS) 推断出的,该问卷由 44道题目 (每道题有 a,b 两个选项) 组成,学习风格每种维度都对应 11 道题(如表1所示)。当用户登录系统时,首先进行问卷量表的数据测试,即进行自我评价的调查。通过问卷的手段,利用文本挖掘技术,建立用户的学习风格模型。
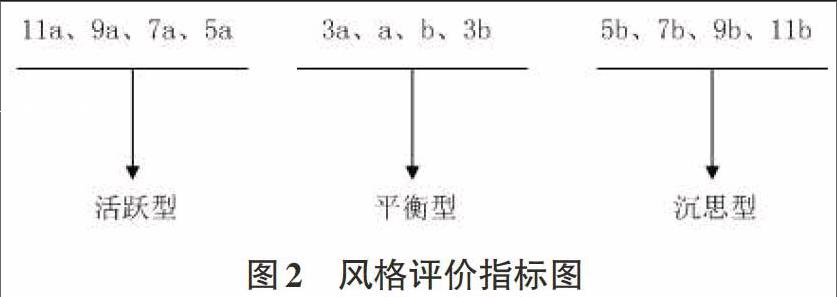
上表中,当用户登录系统时,通过问卷调查,针对系统给出的44道问题开始自我评价,针对每道问题,若符合自己实际情况,则标记对应的a或b为数字1,最终计算每个维度的总计值,方法为:(较大数-较小数)+较大数的字母。若存在某个用户User1,在第一维度的评分如表1所示,它的第一维度的最终得分为7a,再根据风格评价指标图2所示,则User1第一维度上的类型为活跃型,类似地在其他维度上,可以测出其他类型,最终形成了该用户在四个维度上的学习特征模型。
由此可见,Felder-Silverman 学习风格问卷是一种多方位,多维度的分类标准,以这种标准,用户的特征可以得到最大限度的确定,方便了系统根据其学习风格模型进行图书的推荐,同时由于基于用户的协同过滤算法需要和样本数据中的每一个学习者进行兴趣相似度的计算,所以存在计算量大的弊端。通过这种显式的分类,计算用户间的相似度便集中在了同种学习风格的用户之间,在一定程度上降低了算法的时间复杂度。因此,通过每位读者登录系统前的自测,便给不同的读者赋予了不同的学习风格特征,每一种特定的学习风格特征集合即为一种候选最近邻集合UserList,对已登录读者的分类结果如读者分类结果表2所示:
2.2 读者最近邻生成
对于每个候选最近邻集合中的读者Ui,Ui∈UserList(i),先得到Ui和目标读者在一定的期限内借阅图书的浏览矩阵BrowseMatrix,利用修正的余弦相似度计算公式计算与读者最相似的Top-N个读者作为目标读者的最近邻。公式如下:
其中,sim(u1,u2)表示读者u1和u2的相似度,book表示读者u1,u2共同产生评分的图书。
2.3 产生推荐的书目
采用的混合推荐算法包括随机推荐算法和基于用户的协同过滤算法。其中,随机推荐算法主要可以解决冷启动和稀疏矩阵问题,挖掘用户的潜在兴趣,提高系统的泛化能力。基于用户的协同过滤推荐则是根据用户之间的相似度,最大限度地挖掘目标用户感兴趣的图书。系统设定一个启用基于用户协同过滤算法的阈值TR,当达到此阈值时启用基于用户的协同过滤算法。
基于目标用户浏览矩阵的不同状态,在初始阶段有三种不同的典型特征:1)图书浏览矩阵为空。2)登录用户的浏览矩阵为空 3)登录用户所浏览的图书的数目不足以达到启用Users—CF算法进行推荐。此时系统满足这三种状态特征即采用随机推荐。
在过渡阶段主要两个主要的特征:1)图书浏览矩阵不为空。2)登录用户所浏览的图书的数目不为空,但是达不到要启用User—CF算法的阈值。过渡阶段的推荐仍然需要采用随机推荐算法进行。
在平稳阶段,用户的浏览的图书的数目足以达到启用Users-CF算法,此时便可以主要使用Users-CF算法进行推荐,同时,可以在推荐的总数中设定一定数目的以随机推荐算法推荐得到的图书,从而提高推荐的多样性,提高系统的泛化能力。
基于用户的协同过滤的推荐方法的主要思路是,在某读者user(i)最近邻集合User-List(i)中,遍历每一本存储在数据库中且用户已经评分过的图书booki,如果目标用户没有浏览过该图书booki,并且读者最近邻集合中任意一用户Ui喜欢该图书,则将该图书推荐给目标用户。算法1显示了基于用户协同过滤算法的改进后的一种混合推荐算法,输入参数包括用户的Id,推荐的书目Tn,启用协同过滤算法的阈值TR;输出参数为通过混和算法最终推荐后的图书矩阵Tr。
3 图书资源特征库的构建
如果新用户第一次登录系统,进行问卷量表的数据测试,根据其显式的学习风格特征,并结合候选最近用户的已有的浏览图书记录,为新用户随机推荐n本图书,保证该新的用户有过浏览图书浏览的记录,在新用户浏览图书时,新用户可以对随机推荐的图书进行显式或者隐式的打分。所谓显示的打分,意味着新的学习者,在浏览该图书后主动地给该图书进行评分,我们在实验中假定评分的最高分值为5分,如果其打分的分值不小于3分,则代表喜欢该图书,则在其兴趣喜好矩阵中对该图书标记为1,否则标记为0;所谓隐式的打分,即根据新的学习者在该图书浏览上停留的时间,进行打分,我们设定一个时间的阈值,如果学习者阅读的时间达到该阈值,则代表其对这本书感兴趣,同样,在图书资源特征库中,对该图书的浏览喜好矩阵中,标记为1,否则,标记为0。
4 实验结果及分析
实验数据来自西南石油大学数字图书馆,针对计算机科学学院,理学院,化工院,法学院四个学院,借阅时间在2015年9月1日至2016年3月1日的共计101721条借阅记录进行清理和处理,借阅记录中读者信息包括(读者ID、借阅时间、实际归还时间等),同时,图书信息包括(书名、作者,出版社、出版年、单价和索引号等)。在实验中基于用户的协同过滤算法是基于已有的数据集进行的,在本实验中,我们将实验数据分为两部分来处理,用经过我们清洗和整理的前5000条数据作为实验数据,后5000条数据作为测试数据,用于验证该模型的拟合效果和推荐效果。事实上,在初始阶段,所有的新的用户的浏览矩阵为空,但是随着推荐的数目越来越多,新的浏览过的图书又会被记录到已有的用户浏览矩阵当中,最终,我们则可以基于用户的浏览矩阵和兴趣矩阵计算该推荐模型的召回率和多样性。
在实验中,根据算法中所需要的不同参数,调整参数值的大小,根据其之间的相互影响,通过反复实验,达到最佳的推荐效果。经过在相同条件下的反复多次实验,在实验1中,我们依次将启用基于用户的协同过滤算法的阈值设置为1,2,3,4,分别实验了在推荐书目为10,20,30本情况下的召回率。图-3不同阈值下的召回率实验结果图显示了在推荐书目数量为20本,最相似的邻居个数为40个时,召回率Recall达到峰值0.675。
在实验2中,设定了用户的兴趣相似度最近邻为40人,随着推荐书目的增多,算法多样性值呈递增趋势,当推荐时的书目为40本时,推荐效果的多样性Diversity达到峰值0.85.最后实验结果如图-4不同推荐书目下的多样性实验结果图所示。
实验的推荐查准率如图5,推荐差准率结果图显示,在推荐20本图书,并且选择40个最近邻时,达到系统的最佳推荐查准率73%,已经达到良好的推送质量。
5 结束语
本文提出了一种对读者学习风格模型的构建的策略,并结合改进后的基于用户协同过滤的混合推荐算法,有效地提高了推荐的质量,达到了为读者提供个性化图书资源的目的。通过反复多次的仿真实验,有效地解决了原有的基于用户协同过滤算法的稀疏矩阵和冷启动问题,达到了良好的推荐。
参考文献:
[1]Raymond J.Mooney, Loriene Roy. Content-Based Book Recommending Using Learning for Text Categorization. In Proceedings of the Fifth ACM Conference on Digital Libraries, 2000: 195-204.
[2]王静.基于关联规则的图书销售网站个性化推荐系统设计与实现[D]. 电子科技大学,2012.6.
[3]陈定权,朱维凤.关联规则与图书馆书目推荐. 情报理论与 实践,2009,32(6):81-84.
[4]安德智,刘光明,章恒.基于协同过滤的图书推荐模型 图书情报工作,2011,54(1):35-38.
[5]董坤.基于协同过滤算法的高校图书馆图书推荐系统研究. 现代图书情报技术, 2011(11).
