
基于机器学习的微博机器用户识别研究
2016-12-20 03:27金丹滕洁琪
中国高新技术企业 2016年30期
金丹 滕洁琪

摘要:文章以微博用户为研究对象,从发博行为、博文内容、用户关系和发博设备四个方面建立特征维度,借助机器学习的方法构建有效的机器用户识别模型,分别在决策树C4.5和随机森林算法下验证了该模型的识别性能,证实了该方法的可行性和准确性,对维护健康的网络环境有一定的指导意义。
关键词:微博;机器用户;机器学习;用户识别;决策树C4.5;随机森林算法 文献标识码:A
中图分类号:TP391 文章编号:1009-2374(2016)30-0004-04 DOI:10.13535/j.cnki.11-4406/n.2016.30.003
1 概述
微博作为一种社会信息传播平台,以其易操作、低门槛、传播速度快等优点,受到公众更多的青睐。然而,随着微博的普及和互联网络技术的升级,一些不良分子借助新兴技术手段,譬如,依靠批量发布助手、自动广播器等自动化软件来操控账户,由此构成了机器用户。机器用户能够模仿真实用户发布、转发、评论博文,这类用户不具备感情、逻辑和互动性,却以其良好的伪装性,大量发布虚假信息,扩散舆论谣言,严重扰乱网络的正常秩序,破坏网络环境。机器用户造成的危害具体概括为以下四点:(1)耗费系统资源,降低平台效率,影响用户体验;(2)污染社交环境,降低用户信任度,造成平台虚假繁荣现象;(3)难以辨别信息真实性,干扰用户正常判断力;(4)从数据分析角度,这些机器用户的存在部分掩盖了真实用户的特征,对后续数据挖掘、用户分析等研究造成了干扰。
鉴于此,机器用户的识别是一个紧迫而困难的工作,构建有效的机器用户识别模型,借助相关算法快速、准确地识别微博中的机器用户,对减少网络谣言的传播、净化网络环境有重要的意义。
2 相关研究
早期对社交网站不良用户的研究主要集中在对垃圾用户,例如网络水军、广告用户、僵尸粉用户的识别研究上,而机器用户出现的时间并不长,对它的研究还不多,仅有的研究大多数以Twitter为平台,其成果无法直接应用于新浪微博等中文微博平台。
国内方面,刘勘等向自动化软件公司申请并获取了机器用户样本,提取了行为模式、微博内容、用户关系和发布平台四个维度的八个特征属性,基于随机森林训练了一个机器用户识别系统,机器用户的识别准确率达到了96.7%。中国的微博起源于Twitter,国外基于Twitter的机器用户研究主要有以下几人:Chu等从用户行为、Twitter内容和账户属性的角度建立分类系统,将Twitter用户分成机器用户、人类用户和半机器用户。Main采用决策树C4.5算法训练分类器,从用户的发博间隔、垃圾词语检测、重复博文检测、社交分值和发博设备五个方面构建模型,对训练结果采用了比较分析法,分别选用2个主要属性,发博间隔和垃圾信息检测,还有完全采用5个属性时分类器的效果差异。结果表明,发博间隔是机器用户的重要特征,有着更好的区分度。Zhang等构建了一个基于每条Twitter发布时间的检测机器用户方法,并用此模型得到Twitter中大约有16%的活跃账户具有较高自动化行为。Wang提取3个基于图模型的Twitter用户特征和3个基于Twitter内容的属性并设计算法,识别出Twitter中的机器用户。
3 基本思路及相关方法
机器用户的识别问题可以看作是一个将用户分为机器用户和真实用户的二分类问题:设用户的全集是U,类别集合C={,},表示机器用户集合,表示真实用户集合,机器用户的识别问题就是求一个分类函数F,将U中的用户映射到C上。
(1)
上述映射函数F即代表了一个分类器,它可由机器学习算法习得,在本研究中选取决策树C4.5和随机森林算法。
C4.5算法是目前决策树中最常用的算法。它在树的构造过程中进行剪枝,并且用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足。C4.5决策树算法不仅能对离散型数据、连续属性的离散化进行处理,还能够对不完整数据进行处理。
随机森林算法是Leo Breiman提出的一种利用多个树分类器进行分类和预测的方法。随机森林不仅训练和预测速度快而且不容易出现过度拟合的问题。
4 特征研究
通过深入观察和分析,发现机器用户在发博行为、微博内容、用户关系和发布平台4个方面存在显著差异,因此本文对这4个维度的特征进行深入分析。
4.1 发博行为特征
发布博文是用户在微博上的主要活动之一。经过浏览机器用户的发博历史,发现机器用户发博方式呈现两种极端:一类机器用户依靠不断转发某一条博文来增加人气;另一类机器用户依靠不断发布某领域原创博文来维持粉丝的粘性。因此,我们定义转发率来观察机器用户和真实用户的异同。转发率为:
(2)
用户发布博文包括原创和转发,表示某用户发博总数,表示该用户转发博文的数量,表示用户转发博文比率。
CDF累积分布曲线能够定量地显示数据的分布,每一条CDF曲线代表了一群样本某一特征的数据分布,CDF曲线上的每个点对应统计特征的一个值以及统计特征小于这个值的样本数量占总样本数量的百分比。利用CDF曲线,可以很容易地找到多个样本群体对应一个统计特征在数据分布上差异,而这种差异正是我们寻找的特征的“区分度”。从图1是转发率累积分布图,真实用户转发率分布较均匀,随着转发率的增加,曲线稳步上升,而机器用户转发率在0.9之前,曲线平缓,波动不大,而在转发率大于0.9后猛然上升,可见机器用户中大部分用户仅以转发为主,几乎不发表自己的言论。
4.2 博文内容特征
从上文转发率可知,机器用户的转发率非常高,并且转发的原作者集中且单一,如何通过转发来描述转发行为的重复情况,在微博后台数据集群中,用户发博日志存储的形式有一个字段为被转发博文的作者rootuid,据观察经验,机器用户总是固定某一个或某一些用户的博文,被转发用户重复率非常高,因此,定义重复率为:
(3)
表示转发博文的原创用户相同的博文数,表示所有转发的博文数,重复率一定程度上反映了用户的倾向和意图,普通用户转发的博文多种多样,机器用户目的单一,转发的原作者的范围狭窄,因此根据用户是否频繁转发某一用户的博文,具有一定的区分度。
图2所示为被转发用户重复率的累积分布图,机器用户的转发用户重复率明显高出真实用户,表示机器用户总是固定频繁地转发某些人的博文,最典型的是机器用户中的明星水军用户,长期圈粉某一位公众明星,批量转发此人微博,并加入该明星话题词,从而达到提高人气和利用影响力进行炒作的目的。
4.3 用户关系特征
用户关系是社交网络上的重要体现之一,机器用户中认证用户较多,他们利用认证身份的优势以及借助自动化手段发布优质博文,收获更多的粉丝。而真实用户是将现实生活中的关系映射到其社交关系中,因而其关注数和粉丝数相差不大。根据以上分析,定义名誉率,计算公式如下:
(4)
式中:为用户粉丝数,为用户关注数,名誉率越接近0,表示关注数远远大于粉丝数,受欢迎度接近1,表示粉丝量大,言论会受到众多关注,更受欢迎。名誉度指标反映的是用户粉丝量占总体关系的比例,该指标越高说明此用户粉丝越多,越受粉丝欢迎。受欢迎指数的CDF曲线图如图3所示,横坐标为受欢迎指数的值,取值范围是0~1,纵坐标表示统计值小于该值的样本数量占总样本的比例,因此曲线偏向左边,则该组样本的受欢迎指数偏低,反之,曲线偏向右边,该组样本的受欢迎指数较高。
由图3可见,机器用户的受欢迎度比真实用户名誉率更高。因为机器用户并不是通过大量关注普通用户,来获取更多的被关注机会,操纵这些机器账号的用户更多的是通过创造良好的口碑和微博形象,提供更有价值的信息,以此来吸引粉丝,这些粉丝与博主具有相同的兴趣,乐于接受博文更新。由受欢迎度累积分布图来看,在相同概率下,机器用户比真实用户具有更高的受欢迎度,而真实用户通常利用微博浏览兴趣话题,因而关注量大于粉丝量。
4.4 发博设备特征
机器用户通常借助第三方平台来更新博文信息流,发博设备作为区分特征之一是有效的,发博设备有Mobileweb和Wap、Web应用、浏览器、平板电脑、手机和桌面。
如图4所示,87%以上真实用户的发博行为都发生在移动端,而机器用户仅有50%的用户在移动端发布博文,机器用户常用的设备是Web应用即第三方软件平台,由此可见,机器用户大多是在PC平台操作,借助Web应用软件来批量发送博文,而普通用户仅把微博作为及时记录心情和新鲜事的工具。
图1 转发率累积分布图 图2 重复率累积分布图图
图3 名誉率累积分布图 图4 发博设备分布情况
5 模型构建
从上文提出的行为、内容、关系和平台4个特征维度,分别是转发率、重复度、名誉率、设备信息。识别某用户是否为机器用户的算法就是根据这几个特征构建模型。本文使用机器学习工具Weka来训练和测试算法模型,基于微博数据和分类算法决策树C4.5和随机森林构建模型。选用决策树和随机森林算法,是因为决策树和随机森林在解决分类问题的良好性能。
5.1 数据来源
本文数据样本均来自于新浪微博数据仓库。抽取用户样本的规则是基于机器用户单位发博量巨大的显著特征,抽取2016年2月一整月发博数最高的前3000个账号标记为机器用户,真实用户按照合理发博数随机取2406为初始实验数据。
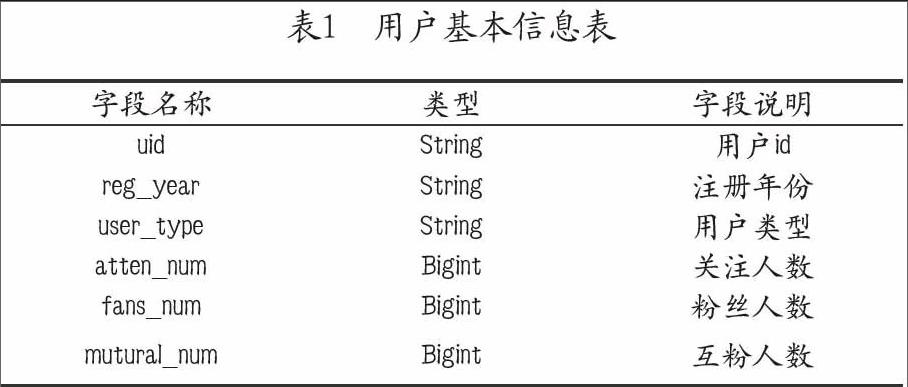
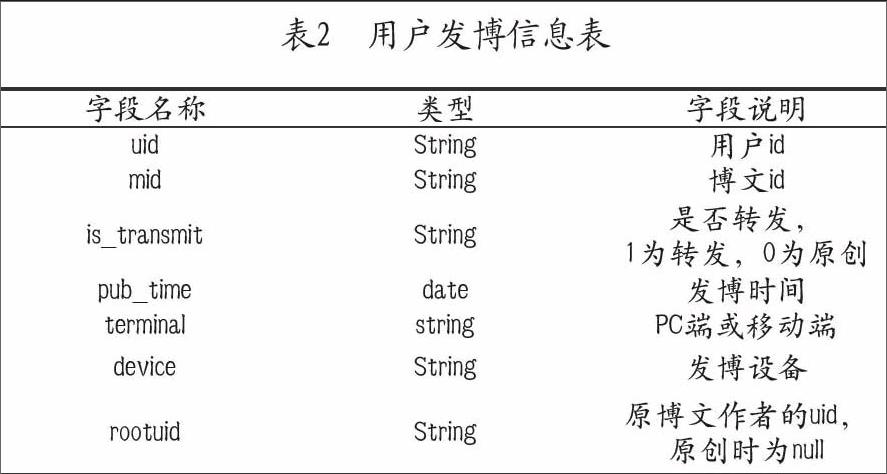
本文所选数据包含以下方面:用户的基本属性、用户的关系属性、用户的行为属性和用户发布博文属性,数据存储表信息如下:
5.2 模型构建与评估标准
从前文提出的发博行为、博文内容、用户关系和发博设备四个特征维度,计算得到数值型变量、转发率、重复率、名誉率,发博设备是标识性变量,识别机器用户的分类器就是基于这四个特征值构建的模型,识别的流程图如图5所示:
对于一个二分类问题,模型预测可能产生四种不同的结果,如表3所示:
实验评价模型的标准有:命中率(TP Rate),误判率(FP Rate),正确率(Precision),召回率(Recall),F值(F-measure)和ROC area,这些指标的计算公式是:(1)命中率:TP Rate=TP/(TP+FN):正样本分类成正样本数/正样本总数;(2)误判率:FP Rate=FP/(FP+TN):负样本分类成正样本数/负样本总数;(3)正确率:Precision=TP/(TP+FP):返回的正确样本数/返回的样本总数;(4)召回率:Recall=TP/(TP+TN):返回的正确样本数/全部的正确样本数;(5)F值:F-measure=2*Precision*Recall/(Precision+Recall);(6)ROC area(Receiver Operating Characteristic):在ROC空间中,每个点的横坐标是FPR,纵坐标是TPR。ROC是计算曲线下的面积,面积越接近1,说明模型效果越好。
5.3 实验与结果分析
基于上述模型,本文标注了一些数据集,用于测试和检验模型的有效性。实验数据来源于新浪微博数据仓库,随机选取约4000用户作为实验样例。实现方法上,本文分别采用基于C4.5决策树的分类算法和改进决策树的随机森林分类算法对模型进行训练,并用10折交叉验证的方法验证模型。本文利用机器学习工具集Weka分别用上述两种算法训练模型,两种算法的模型效果分别如表4和表5所示。图6是这两种算法统计对比图。
实验中,本文标记了3771个用户数据,其中机器用户2069个、真实用户1702个,从分类结果来看,决策树C4.5和随机森林对机器用户的识别效果相差不大,但随机森林稍微优于C4.5,从表4看到,C4.5的准确率94.2%,而表5中随机森林的准确率为94.4%。整体来讲,随机森林模型优于决策树C4.5模型。
为了检验各个特征属性对模型效率的影响,分别去除某一特征,查看模型性能的变化情况。表6列出了分别去除发博平台、名誉率、重复率和转发率这4个特征之后,性能指标的变化情况。从数据中可以看出:(1)对于决策树C4.5算法来说,去掉名誉率和转发率,模型性能略微提升,模型中去掉任意一个是合理的。但对于随机森林来说,去掉任何一个指标,都将导致性能的下降,因此随机森林宜保留全部特征属性;(2)重复率对模型效率起到重要作用,去掉重复率以后,模型的效率下降幅度明显,仅仅在0.7左右,并且对决策树模型影响偏大,识别效率不到0.7;(3)发博平台对整体模型,无论是决策树还是随机森林都有一定贡献。
图7是决策树C4.5和随机森林分别去掉每个属性后,F值的对比,可见除了重复率,去掉发博平台、名誉率和转发率中的任意一个属性,F值均可达到0.9以上。
以上分析可见,重复率这一属性对模型的影响效率非常明显。若只考虑这一属性特征,训练模型后得到的准确率决策树和随机森林分别为93.3%和92.7%。已经达到很好的区分度,结合机器用户的发博动机和意图,一部分以网络水军为主体的明星人气造势者以及另一部分以广告营销为主体的广播扩散型商业机器用户,从这一点考虑,频繁和长久的转发相同账号的博文是情理之中的。
6 结语
本文针对国内新浪微博机器用户的特点,从发博行为、微博内容相似情况、用户关系、发布平台4个维度构建模型指标,分别利用决策树C4.5和随机森林算法实现了对机器用户的有效识别。实验表明,本文采用的模型指标和分类模型能有效地识别微博中的机器用户,而且转发博文的高度重复是机器用户的重要特征。本文的工作对避免虚假、有害信息的扩散,营造积极健康的网络环境有重要意义。由于网络信息传播模式变化较快,机器用户采用的方法也会不断变化,因此进一步的研究需要及时关注机器用户的最新特点和变化趋势,及时调整或构建新的识别模型。另外,除了微博平台,机器用户在论坛、贴吧、新闻评论、商品评论等其他网络平台上也较活跃,针对这些平台中的机器用户也需要构建相应的识别模型。
参考文献
[1] 刘勘,袁蕴英,刘萍.基于随机森林分类的微博机器用户识别研究[J].北京大学学报(自然科学版),2015,(2).
[2] Chu,Z.,et al.Detecting Automation of Twitter Accounts:Are You a Human,Bot,or Cyborg[J].IEEE Transactions on Dependable and Secure Computing,2012,9(6).
[3] Main,W.and N.Shekokhar.Twitterati Identification System[J].Procedia Computer Science,2015,(45).
[4] Zhang C M,Paxson V.Detecting and analyzing automated activity on twitter[A].Passive and Active Measurement[C].Springer Berlin Heidelberg,2011.
[5] Wang,A.H.Detecting Spam Bots in Online Social Networking Sites:A Machine Learning Approach[M].Data and Applications Security and Privacy XXIV,2010.
[6] Breiman L.Random forests[J].Machine Learning,2001,45(1).
猜你喜欢
环球时报(2022-07-13)2022-07-13
作文大王·低年级(2022年3期)2022-03-19
环球时报(2022-03-14)2022-03-14
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
电影(2018年8期)2018-09-21
小学生作文·小学低年级适用(2018年12期)2018-04-11
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
校园英语·下旬(2016年2期)2016-03-18
郑州大学学报(医学版)(2015年1期)2015-02-27
