
面向对象的多版本传感器观测服务模式匹配方法
2016-12-22 08:06侯景伟
华中师范大学学报(自然科学版) 2016年6期
何 杰, 侯景伟
(宁夏大学 资源环境学院, 银川 750021 )
面向对象的多版本传感器观测服务模式匹配方法
何 杰*, 侯景伟
(宁夏大学 资源环境学院, 银川 750021 )
以多版本传感器观测服务(Sensor Observation Service,简称SOS)模式为研究对象,从SOS实现规范数据类型UML图中解析出SOS服务模式组成对象,提出一种面向对象的模式匹配方法,把服务模式匹配问题转换为模式对象的匹配问题.重点阐述了模式对象的分解、关联子对象识别、及子对象匹配等相关技术.最后,以两种版本的SOS模式匹配试验验证了方法的有效性.
传感器观测服务; UML; 面向对象; 对象匹配
模式匹配[1-5]是当前研究的一个热点和重点问题,也是众多应用,如基于web的服务查询和集成、电子商务、数据同化等不可缺少的关键步骤.然而,在当前,不管是语法模式匹配[1,5-6]方法还是语义(本体)[2-4,7]模式匹配方法,它们都从微观上,以每个模式元素为单位参与匹配,而且通常需要对两个待匹配的模式文件中所有元素进行比较,由于参与匹配元素的增多,特别是大尺度的模式匹配问题,造成匹配性能较差;同时,随着参与匹配元素的增多,匹配复杂度提高,误匹配率也会增多,从而影响匹配精度.针对这些问题,国际上有人提出基于模式片段匹配的方法来提高模式匹配性能和质量,如在H.Do和Rahm设计的COMA++[8]系统中,首先对模式进行分块,然后对这些模式分块进行匹配,但由于COMA++采用启发式分块规则,造成模式分块要么太多,要么太少,且在识别相似分块时,通常只考虑分块的根节点信息,造成匹配质量不高.在国内,东南大学的胡伟等人提出的Falco[9]系统则根据输入的本体实体在结构和语言学上的相似性把两个本体中所有相似的实体单元,通过聚类算法形成一个个大的本体块,由于其算法中涉及的本体信息多且复杂,从而影响了系统的性能.
在地理信息网络服务中,传感器观测服务(SOS)[10]内容最复杂、应用最广,它提供了一个标准的接口来管理和提取各种不同传感器系统的元数据和观测.在本文中,以SOS服务模式为例,研究不同版本服务模式的差异,及差异造成了诸如类在命名上的变化、属性上的变化(如新增属性)、继承关系上的变化等.从本质上讲,这些服务模式具有面向对象特征.为此,本文提出了一种面向对象的模式匹配方法(Object-Oriented Schema Matching,简称OOSM),试图把待匹配模式文件当作一个对象类,在综合考虑Falco[9]系统通过聚类算法形成本体块,及COMA++[8]系统采用的启发式分块方法的基础上,采用直接利用类的继承层次关系把类分解成一个个子类或子对象.然后通过计算子类名称字符、词义及注释相似度来找出待匹配的两个模式类的所有相似或关联子对象.最后设计一种匹配算法对所有相似子类进行匹配,最终达到通过匹配规模的减少和匹配算法的改进来提高匹配性能和质量.
1系统体系结构及部件
图1是系统体系结构.

图1 系统体系结构Fig.1 Architecture of the schema matching system
系统由模式类生成,模式类分解,相似类识别及模式子类匹配四个部件组成.模式类生成部件主要实现把输入的模式文件生成对应的模式类,并用对应的类图表示;模式类分解部件则根据模式类包含的子类或对象间的层次关系,把模式类分解成一个个独立的子类;相似类识别部件则从分解的所有源和目的子类中识别出相似或关联的子类;最后子类匹配部件对这些相似子类进行匹配,并对所有子类匹配结果进行组合,得到最终匹配结果.同时,在子类匹配过程中,可以人工从匹配器库中选择合适的匹配器及匹配器组合方法.
2系统实现
2.1模式类生成
OGC(Open Geospatial Consortium)为不同类型的网络服务间的互操作定义了技术和实现规范,它们使用标准的XML 模式定义语言(XSD)定义了网络服务实例文档应该遵循的结构和使用的数据类型.从本质上讲,XML模式定义是面向对象的,所以把XML模式文件转换为一种面向对象的模式类表示是合适的.
一个XML模式文档中定义了4种类型的数据结构:复杂类型(complexType),简单类型(simpleType),元素(element),属性(attribute).此外,XML模式定义语言还定义了19种内置的原子数据类型,如string类型,及25种派生数据类型(由原子数据类型派生),如normalizedString派生于string.下面来定义各种规则把不同数据类型转换为面向对象的类型.
规则1:所有的复杂类型(complexType)都映射为一个类类型,复杂类型名字为对应的类名,复杂类型内部定义的变量,如果类型为内置原子类型,则映射为类的属性,如果是派生类类型则映射为复杂类的一个嵌套子类.
规则2:所有的简单的数据类(simpleType)型映射为类的属性,其定义的枚举值为属性的默认值.
规则3:所有的元素(element)及属性,如果其类型为原子数据类型,则映射为类的属性,否则映射为类的一个嵌套子类.
以SOS GetCapabilities响应文件为例,其模式文件包括ows∶CapabilitiesBaseType,sos∶Fileter_Capabilities,sos∶Contents等3个模式片段,在XMLSpy软件中,其模式结构图如图2所示.根据本节定义的转换规则,很容易把其转换为模式类表示,其类名为Capabilities,下面包含3个子类,每个子类又包含其它子类或属性,图3显示了模式片段转换后的UML静态图表示.

图2 GetCapabilities响应文件结构Fig.2 Structure of GetCapabilities response file

图3 GetCapabilities响应文件UML表示Fig.3 UML diagram of GetCapabilities response file
2.2模式类分解
为了操作方便,把模式类的UML静态表示图转换为一个面向对象系统的有向图,图中每个类或子类用一个节点表示,节点的标签用类名表示,节点间的有向边表示类间的关系(如继承,关联,聚合等).下面对有向图及相关操作进行定义.
定义1在OOSM对象模型图中,每个对象用一个五元组
在定义1中,编号根据图的广度优先遍历方法获得.节点类型包括简单基本数据类型(如integer,char,string等)及复杂数据类型,如类类型.在OOSM有向图中,直接的前驱节点最多一个,没有前驱节点的节点为图的根节点,而直接的后继节点可以有多个,没有后继节点的节点称为叶子节点.
定义2在OOSM对象模型图中,每个有向图用一个三元组〈R,V,E〉表示,其中R表示有向图的根节点,V表示顶点或节点集合,E是边集合.
在定义2中,R是有向图中唯一一个没有前驱的节点,且经过R可以到达有向图中任意节点.
模式类的分解是基于模式类的有向图进行的,分解规则定义如下.
模式类分解规则:给定任何一个待分解的模式类图,首先判断模式类中是否包含嵌套的子类或对象,如果模式类为空,或者包含的全是原子属性,没有子类,则分解结束;否则,我们对模式类进行分解,分解方法为:把所有与模式类(父类)有直接关系的各种子类或对象提取出来,成为一个个独立的子类.算法的伪代码表示如下:
算法1:图分解算法PartitionGraph(G).
输入:面向对象系统的有向图G.
输出:子图集合subGraphs.
subGraphs=Φ
if(hasSubClass(G))
subGraphs=getSubGraph(G)
End if
上述算法中,hasSubClass(G)用来判断图是否包含可分解的子类,判断方法即根据图G的根节点的类型来判断,如果根节点是简单数据类型,则图G是不可再分的,否则可以再分.getSubGraph(G)则从图G中分解出直接的子类(子图).分解的过程为:依次处理图G的每个直接后继节点,将这些节点的Pre(前驱)设置为空,则每个后继节点及其所有后继节点构成了一个以该后继节点为根节点的新子图.最小的子图是一个只包含一个叶子节点的节点,节点的前驱及后继均为空.
如给定图3的Capabilities类经过一次分解后得到Filter_Capabilites,Contents,CapabilitiesBaseType 3个子类,其中,Filter_Capabilites又可分解为Spatial_Capabilities,Temporal_Capabilities,Scalar_Capabiities,Id_Capabilities 4个子类,对于Contents子类,它又是由很多的ObserationOffering类组成,CapabilitiesBaseType子类分解成4个属性元素及3个可选子类ServiceIdentification,ServiceProvider,OperationsMetadata.
2.3相似类识别
相似类识别主要是发现源和目的模式类中所有相似子类对,以便对这些相似子类对作进一步匹配.为了提高相似类识别的效率,只考虑所有子类的名称相似值及类的注释文本相似值,而不考虑类的内部结构相似性;同时,只计算相似类间1∶1的关联关系.下面定义2个子类相似值sim(o1,o2).
sim(o1,o2)=α×simstr(o1.Name,o2.Name)+
β×simsyn(o1.Name,o2.Name)+
γ×simglos(o1.gloss,o2.gloss).
(1)
在公式(1)中,simstr(o1.Name,o2.Name)计算的是两个类名字符相似值,在本文中,采用编辑距离算法来计算两个类的名称相似值,即有:
simstr(o1.Name,o2.Name)=
1-editNums/maxLength(o1.Name,o2.Name)
(2)
其中,editNums为把一个字符转换为另一个字符需要的编辑次数,maxLength()返回字符串最大长度.如给定两个类名:”feature”,”fofeature”,根据公式(2)可计算出它们间的字符相似值simstr("feature","fofeature")=1-2/9=0.78.
simsyn(o1.Name,o2.Name)计算的是两个类名的标签概念相似值[11],其具体计算方法如下.
定义3(类名标签词义相似值)设有类名标签A、B,其在WordNet[12]中的同义词集合表示为A=(α1,α2,α3,…,αn),B=(β1,β2,β3,…,βm),其中α1,α2,α3,…,αn,β1,β2,β3,…,βm分别为类名标签A、B的原子义词,则类名标签A、B的内积为:

(3)
其中,simasyn(αi,βj)根据两个原子义词在WordNet中的词义距离的倒数计算出的义词相似值.有了内积,我们就能导出类名标签的范数和原始类名标签的相似值定义.
定义4(类名标签范数和相似值)设有类名标签Α,其范数定义如下:
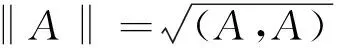
(4)
则两个原始类名标签Α、B间的相似值定义如下:
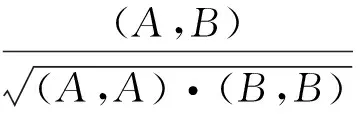
(5)
simglos(o1.gloss,o2.gloss)用来计算两个类的注释文本相似值,我们采用的是基于向量空间模型的余弦算法,定义如下.
定义5(文本相似度)设有源模式类的注释文档di={ti1,wi1;ti2,wi2;…; tin,win},目的模式类的注释文档dj={tj1,wj1;tj2,wj2;…; tjn,wjn},其中ti1,ti2,…, tin;tj1,tj2,…, tjn为源和目的注释文档的特征项,wi1,wi2,…, win;wj1,wj2,…, wjn为对应的文档特征项的权重,则文档di、dj的文本相似值用公式表示为:
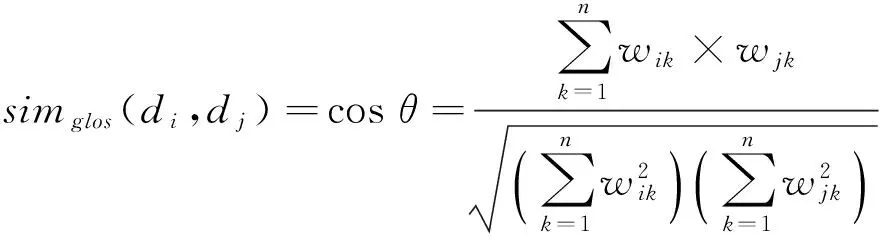
(6)
其中,θ为两个文档向量的空间夹角.
在两个子类的相似值计算中,由于不同类型相似值的作用程度不同,如对于类名的字符相似值,由于同名异义、同义异名现象使得在很多情况下,类名的字符相似值并不能准确表示两个子类的相似程度,所以各个类型相似值权重不同,对公式(1)中的α、β、γ取值满足α<β≤γ,且α+β+γ=1.
对于源类的每个子类,当计算出其与目的类的所有子类的相似值后,我们选择相似值最大者(maxSim)、且相似值大于门限值(threshold)的子类对作为候选相似子类对(subGPairs).如果某个最大相似值的值小于规定的门限值,此时,把这种子类对作为次候选相似子类对(secondSubGPairs).当源和目的类的所有子类初次识别完成后,判断是否有次候选相似对产生,如果没有,子类识别结束,输出最终相似子类对,否则,进行二次子类识别,即,处理所有的次候选相似对.处理过程为:如果源子类可以分解(包含有子类),分解源子类,然后把目的子类与源子类的所有子类比较(见算法2中的函数getMaxSim),如果没有候选相似子类对,则逆向比较,即如果目的子类可以分解,则把源子类和目的子类的所有子类比较,如果仍然不满足候选相似子类条件,则处理结束,否则输出对应的候选相似子类.算法2是子类(子图)识别算法的伪代码.
算法2:子类识别算法SimilarClassIdentity(subGraphs1,subGraphs2).
输入:源和目的子图subGraphs1,subGraphs2.
输出:候选相似子图对subGPairs.
subGPairs=Φ, secondSubGPairs=Φ;
foreach(class o1 in subGraphs1){
maxSim=0.0;
foreach(class o2 in subGraphs2){
if(sim(o1,o2)>=maxSim)
maxSim=sim(o1,o2);
}
if(maxSim>threshold)
subGPairs+=new Pair
else
secondSubGPairs+=new Pair
}
if(secondSubGPairs==Φ)
return subGPairs;
else{
foreach(Pair p in secondSubGPairs){
class oo=p.getFirstClass();
class oo2=p.getSecondClass();
if(oo.canPaitition()){
class tmpClass=getMaxSim(PartitionGraph(oo),oo2);
subGPairs+=new Pair
}else if(oo2.canPaitition()){
class tmpClass=getMaxSim(PartitionGraph(oo2),oo);
subGPairs+=new Pair
}
}
return subGPairs;
}//算法结束.
识别后的候选相似子类对被分成两种类型,一种为简单的原子子类对,即不可再分解,一种为复杂的子类对,可以继续被分解.下节将对这两种相似子类进行匹配.
2.4子类匹配
针对识别后的两种类型的子类对:简单子类对和复杂子类对,分别设计了简单子类匹配算法和复杂子类匹配算法.
对于简单子类匹配,由于每个子类内部只包含属性成员,没有嵌套子类,所以根据公式(1)计算所有属性成员两两间的名称、标签概念和注释文本组合相似值,同时每组相似值中的最大者、且大于门限值的属性对为匹配的候选映射.
对于复杂子类匹配问题,我们思想是通过类分解,把复杂子类匹配转化为简单子类匹配,即首先使用本文的类分解方法对复杂类进行分解,然后识别分解后的相似子类,最后对子类进行匹配.具体算法描述如下.
算法3:子类匹配算法ObjectMatching(Os,Ot).
输入:候选子类对(Os,Ot).
输出:候选映射Mappings.
1)从对象管理器中选择未匹配子类对(osi,otj).
2)判断子类类型.如果是简单子类,利用公式(1)进行简单子类匹配;如果是复杂子类,则首先把复杂子类转换为简单子类,再利用简单子类算法进行匹配.
3)匹配中间结果处理.即把每轮得到的候选映射路径扩充到模式类的根节点,候选映射转化为匹配的最终映射.
4)如果子类对匹配完,转步骤5),否则返回到步骤1),重新执行上述步骤.
5)输出子类匹配结果,算法结束.
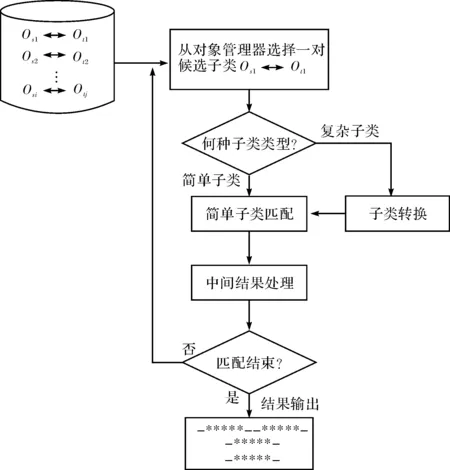
图4 候选子类对匹配流程图Fig.4 Process of the candidate subclass pairs matching
3实验及讨论
本文试验使用的计算机配置为:windows XP 操作系统, 2.5 GHz Intel Core2 Quad处理器,2.0 GB RAM,且安装Sun Java 1.6.0运行库.实验数据我们选取的是SOS 1.0.0版本和2.0.0版本的三种模式文件,分别是:sosGetCapabilities.xsd,文件大小为4 KB;sos GetObservation.xsd,其大小为6 KB;sosGetResult.xsd,大小为5 KB.
3.1模式匹配质量实验
应用①COMA;②COMA++;③OOSM分别进行匹配试验.对于COMA我们选择的配置策略为:平均值法进行相似值聚合和组合,MaxDelta法选择匹配候选者,匹配方法选择AllContext(完全上下文),包含匹配器组合为:NAME(名称),PATH(路径),LEAVES(叶子),PAR ENTS(父亲),SIBLINGS(兄弟).对于COMA++,选择的匹配策略是Fragment-based(基于片段),使用的Node Matcher(节点匹配器)和Context Matcher(上下文匹配器)均为COMA.对于OOSM,相似子类识别选定的门限值为0.7.
用传统的查全率(Recall),精度(Precision)来评估匹配结果,试验结果如图5、图6所示.从图5看出,对于SOS两种不同版本的3种操作模式文件匹配,使用本文面向对象方法得到的查全率最高,平均查全率值达到82%以上,这主要由于面向对象匹配方法中不仅考虑到了元素标签名称组成,还考虑到了标签的节点语义和注释,所以能发现更多那些使用COMA/COMA++没有发现的语义异质性问题.从图5还可以看出,对于操作getCapabilities,getObservation来说,COMA++查全率稍稍高于COMA,对于getResult匹配结果,二者几乎相同,这主要由于getResult两种版本结果差异巨大,模式片段及相似片段少,COMA++作用不明显.从图6可以看出,3种匹配方法精度值满足COMA 图5 匹配查全率比较Fig.5 The Recall of 3 match methods 图6 匹配精度比较Fig.6 The Precision of 3 match methods 3.2模式匹配性能实验 同样,应用上节使用的3种匹配器来进行匹配性能实验,实验数据也同3.1节,实验结果如图7所示.从图7比较看出,不同的类型的模式文件间的匹配,及不同匹配方法性能各不相同.对于同种匹配任务,匹配性能COMA++最好,OOSM次之,COMA最差.这主要由于COMA++在局部上虽然使用的与COMA相同的匹配器,但在整体上采用的是分块策略,匹配规模大大减少,所以性能优于COMA,同时由于COMA++在元素级上的匹配仍然为语法匹配方法,而OOSM在匹配时考虑了节点的语义信息及注释文本信息,所以整体匹配性能稍逊于COMA++.对于结构组成清晰,模式类继承关系简单,容易分块或子类化的模式文件,如对于操作getCapabilities,getObservation模式文件由于易于对象化表达和分块,所以使用COMA++和OOSM都能使性能大幅提高. 图7 3种匹配方法性能比较Fig.7 Performance comparison of three matching methods 异构网络服务模式间特别是不同质的模式文件间结构差异巨大,同时元素语义表达差异明显,造成了模式匹配精度和性能的下降.为了改善性能,提高精度,本文在分析不同版本模式文件结构特征基础上,提出了一种面向对象的模式匹配方法,把模式匹配问题转化为模式子对象间的匹配问题,从整体上减少了模式匹配规模,同时在局部匹配过程中充分考虑模式元素的标签语义信息和注释文本向量信息.实验结果表明,文中提出的方法在匹配性能上比传统模式匹配方法,如COMA,有较大提高,同时在精度上又优于COMA++. 下一步将把面向对象方法用于异质不同类型模式文件间,如SOS与WCS,SOS与WFS间的匹配,同时改善匹配算法,进一步提高匹配性能. [1] SHVAIKO P, EUZENAT J. A survey of schema-based matching approaches[J]. Journal on Data Semantics IV, 2006, 3730:146-171. [2] GIUNCHIGLIA F, SHVAIKO P. Semantic matching[J]. KER Journal, 2003, 18(3):265-280. [3] GIUNCHIGLIA F,SHVAIKO P,YATSKEVICH M.S-Match[J]:An Algorithm and an Implementation of SemanticMatching[C].In:Proceedings of the European Sema-ntic WebSymposium(ESWS),Springer, Heidelberg,2004:61-75. [4] GIUNCHIGLIA F, YATSKEVICH M, GIUNCHIGLIA E. Efficient semantic matching[C]//In Proceedings of ESWC,Heraklion,Greece, 2005: 272-289. [5] 王育红, 陈 军. 基于实例的GIS数据库模式匹配方法[J]; 武汉大学学报(信息科学版), 2008, 33(1):46-50. [6] AUMULLER D, DO H H, MABMANN S, et al. Schema and ontology matching with COMA++[C]//In Proc of the 2005 ACM SIGMOD Int Conference on Management of Data. New York: ACM Press, 2005: 906-908. [7] NOY N, MUSEN M. The prompt suite: interactive tools for ontology merging and mapping[J]. International Journal of Human-Computer Studies, 2003, 59(6):983-1024. [8] DO H H, RAHM E. Matching large schemas:Approaches and evaluation[J]. Information Systems, 2007, 32(6):857-885. [9] HU W,QU Y,CHENG G. Matching large ontologies:A divide-and-conquer approach[J]. DKE, 2008, 67:140-160. [10] OGC. OpenGIS® Sensor Observation Service Implementation Specification [M]. 2006. [11] 何 杰, 陈能成, 郑 重, 等. 利用语义的多版本网络覆盖服务模式匹配方法[J]. 武汉大学学报(信息科学版), 2012, 37(2):210-214. [12] MILLER A G. WordNet:A lexical database for English[J]. Communications of the ACM, 1995, 38(11):39-41. [13] DO H H, RAHM E.COMA-A System for FlexibleCombination of Match Algorithms[C]//In Proceedings of the 28th International Conference on VeryLarge Data Bases, Hongkong,China, 2002. An object-oriented multi-versions sensor observation services schema matching method HE Jie, HOU Jinwei (School of Resource and Environment, Ningxia University, Yinchuan 750021) An Object-Oriented schema matching method is proposed and the schema match is converted into object match using multi-version sensor observation service(SOS) schemas as study objects and SOS service schema objects parsed out from SOS implementation specification presented by Unified Modeling Language (UML) static class diagram. Key problems, such as object decomposition, similar sub-object identification and sub-object match, are focused on. Finally, different version schemas of SOS are utilized to test the effectiveness of the proposed method. sensor observation service; UML; Object-Oriented; object match 2016-09-11. 宁夏自然科学基金资助项目(NZ12110);国家自然基金资助项目(41201393);武汉大学测绘遥感信息工程国家重点实验室开放基金项目(14I03). 1000-1190(2016)06-0805-07 P205 A *E-mail: whujiejie@163.com.


4结论与展望
猜你喜欢
数学年刊A辑(中文版)(2021年4期)2021-02-12
电子技术与软件工程(2019年24期)2020-01-18
电子制作(2019年13期)2020-01-14
移动信息(2018年1期)2018-12-28
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
科教导刊·电子版(2017年17期)2017-07-25
现代计算机(2016年12期)2016-02-28
遥感信息(2015年3期)2015-12-13
山东工业技术(2015年21期)2015-07-27
中国交通信息化(2015年6期)2015-06-06
