
视频中目标检测算法研究
2017-01-20 09:38张明军俞文静袁志黄志金
软件 2016年4期
关键词:目标检测
张明军 俞文静 袁志 黄志金
摘要:由于其实用价值和理论价值,目标检测是智能视频监控技术研究的重点,也是计算机视觉领域的一个研究热点,引起了研究者广泛关注。本文根据视频图像背景和前景目标的动或静的情况进行分类,将目标检测问题分为基于背景建模的目标检测和基于目标建模的目标检测两类。对于每类问题,分别全面综述了该问题的发展、常用算法模型及当前的研究成果等,然后讨论了对各类算法模型的评测指标、评测数据集和评测结果,最后总结了当前这两类目标检测方法存在的不足以及给出了对未来发展的思考和展望。
关键词:目标检测;背景建模;目标建模;智能视频监控
中图分类号:TP391 文献标识码:A DOI:10.3969/j.issn.1003-6970.2016.04.011
0 前言
视频监控是当前社会安防领域的重要组成部分,随着监控摄像头的快速增加,海量的监控视频数据的处理便成了一个重大问题。随着计算机视觉和人工智能的发展,智能视频监控技术应运而生,就是为了解决海量视频分析和处理的问题,并随着社会对安全的重视,该技术也成了当前的研究热点。目标检测是从视频或者图像中提取出运动前景或感兴趣目标,也就是确定当前时刻目标在当前帧的位置和所占大小。因此目标检测是智能视频监控技术的基础,其性能的好坏直接影响了后续目标跟踪、目标分类与目标识别等算法的性能。本文将对目标检测的常见模型和方法进行分析和总结。
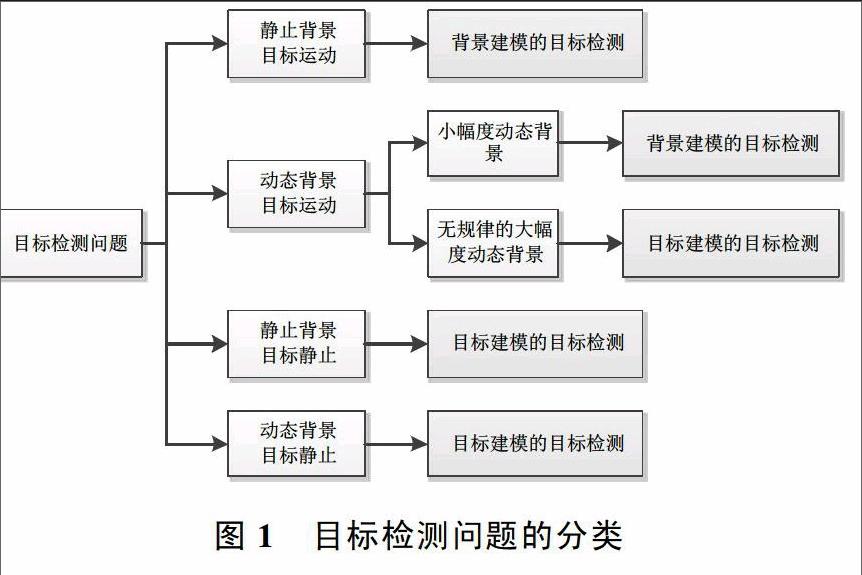
1 目标检测问题的分类
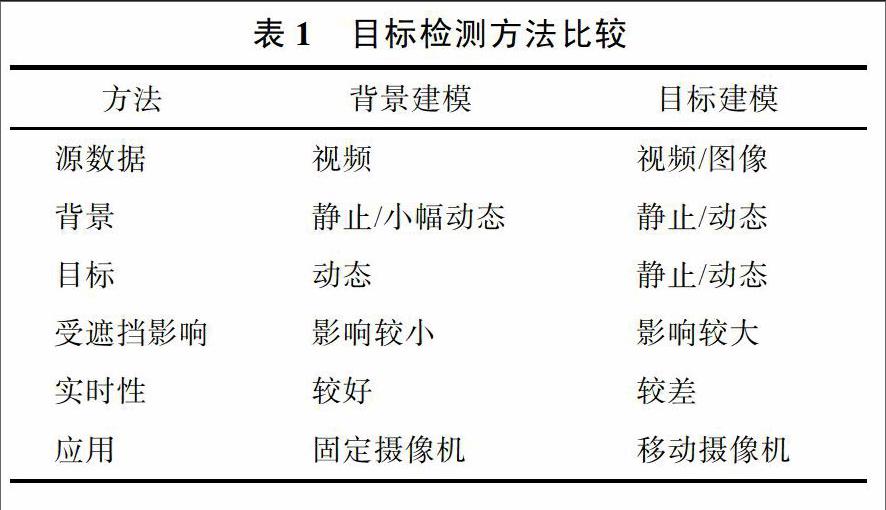
从对象处理的过程来看,主要是从图像的背景和前景目标进行处理,按照图像背景和前景目标的不同情况可以将目标检测分为几类子问题,如图1所示。解决这几类问题的方法可以总结为2大类,分别是基于背景建模的方法和基于目标建模的方法。基于视频的序列图像中,人们对其中运动的物体会更感兴趣,往往也包含主要信息,因此基于视频的目标检测主要是运动目标检测,而这一类目标检测则主要使用基于背景建模的方法。基于背景建模的方法不但要求目标要保持运动,并且要求背景尽可能保持不变(背景静止),当背景发生变化时,则让背景误检为目标,小幅度的背景变化尚可通过方法的改进加以修正,但大幅度的背景变化则让该方法无能为力,基于目标建模的方法却能解决这个问题。基于目标建模的方法不受应用场景的限制,不但可以对静态场景视频进行目标检测,也可以检测单幅静态图像或动态场景视频中的目标。
基于背景建模和目标建模的方法之间的比较如表1所示。
2 基于背景建模的目标检测
2.1 帧间差分法
帧间差分法(Frame difference method)主要考虑相邻视频帧之间背景相对固定,而运动目标则有位置变化,那么相邻帧进行相减,背景部分差值接近于0(理想状态为0),而运动区域的差值则较大。设定一个阈值对背景进行过滤,则提取到运动目标。其数学模型如下:
(1)
(2)其中,It(x,y)It(x,y)表示t时刻像素点(x,y)的灰度值,It-1(x,y)表示t-1时刻像素点(x,y)的灰度值,Dt(x,y))为提取的运动目标的二值图像,T为阈值。
二帧帧间差分法计算量小、实时性强,但检测的目标不完整,存在“空洞”,位置不够精确,在运动方向上目标被拉伸。为了改进二帧帧间差分法的不足,提出了三帧帧间差分法,其主要思想是对前后两次差分图像进行“与”操作。
2.2 背景减除法
背景减除法(Background subtraction method)是用当前帧与背景图像或背景模型进行差分,对结果进行处理后得到运动目标区域。其数学模型如下:
(3)
(4)其中It(x,y)为视频图像序列中t时刻的图像,Bt(x,y)为t时刻的背景图像。式(4)为背景图像的更新,其中α为背景更新率。对△It(x,y)进行阈值处理,可以得到运动目标区域的二值图像Dt(x,y),同式(2)。
由上可知,只要背景不变化,背景减除法的目标检测效果很好。但是,由于背景可能存在光照变化、背景扰动以及由于摄像机抖动导致的小幅度运动等影响,背景都会随着时间而发生变化,所以怎样定义背景和更新背景是该方法的难点和关键。研究者们提出了大量背景建模方法,如中值滤波、均值滤波、线性滤波、基于码本的模型、非参数模型、隐马尔科夫模型、Vibe方法、混合高斯模型(Gaussian Mixture Model,GMM)等。其中,GMM是目前普遍应用的一种背景建模方法。为了改善一些复杂场景的目标检测效果,如去除“鬼影”和“阴影”等,研究者们对原有背景建模算法进行两个方面的改进:一是对算法模型进行改进,以及多种算法结合并利用各自优势进行优化;二是利用算法提取目标之后再对分割目标结果进行优化。
3 基于目标建模的目标检测
3.1 滑动窗口策略的一般框架
基于目标建模的目标检测一般采用滑动窗口的策略,即通过训练好的模板在在图像多个尺度上进行滑动窗口扫描,判断各窗口是目标还是背景从而获取目标。与背景建模的目标检测不同的是,该方法不能提取目标轮廓,而是一个包围目标的框。基于滑动窗口的目标检测的一般框架如图2所示。其中,特征抽取关系到目标检测的可靠性和精度,而建立高效、准确、鲁棒的目标表达模型及分类器则是窗口滑动策略的关键问题。
根据建模方法不同,基于滑动窗口的目标检测主要分为全局刚性模板目标检测模型、基于部件的目标检测模型、基于视觉词包的目标检测模型和深度学习模型等。
3.2 全局刚性模板目标检测模型
通过固定的窗口大小和特征对目标进行全局匹配,因此目标需要刚性不变,对形变目标则不能很好的进行检测。典型的算法模型为Dalai和Triggs提出的HOG(HistogramsofOrientedGradients)模型。HOG是梯度方向直方图特征,其核心思想是局部目标的外形能够被光强梯度或边缘方向密度分布所描述,通过将图像划分成小的连接单元(Cell),在每个Cell内部进行梯度方向统计得到直方图描述。HOG整体检测框架依然是以滑动窗口策略为基础,并且使用线性分类器进行分类。
3.3 基于部件的目标检测模型
基于部件的目标检测模型(Part-Based Model,PBM)主要研究如何利用部件获得目标的局部判别特征,能够解决遮挡目标和多姿态目标等问题。该方法最早提出的模型是图结构(Pictorial Structure),它使用一系列部件以及部件间的位置关系来表示目标。此后,在此基础上先后提出了星座模型(ConstellationModel)、部件拼接模型(Patchwork of PartsModel)以及可形变部件模型(Deformable PartBased Model,DPBM)等。其中,DPBM在当前的目标检测中具有重要的地位。DPBM主要由一个使用粗糙特征的全局模板和若干高分辨率(精细特征)的部件模板构成,还提出了隐支持向量机模型(Latent variable SVM),通过隐变量来建模物体部件的空间配置,并使用判别式方法进行训练优化。
3.4 基于视觉词包的目标检测模型
视觉词包(Bag-Of-Visual Words,BOVW)是一种图像的中层特征描述,可以看作是对图像低层视觉特征的聚合,通过利用图像中包含的视觉单词的统计或分布来表达图像场景内容。BOVW是由Csurka等人于2004年首次将用于文本分类的词包模型用于图像物体分类而产生,由此出现了大量视觉词包模型的研究,文献对此进行了梳理和总结。基于视觉词包的目标检测则主要是通过训练库中的目标构建一个视觉词包,然后对于给定的图像抽取其局部特征,在视觉词包上投票得到该图像基于视觉词包的特征表达,最后采用窗口滑动策略以及SVM分类来检测目标。文献提出基于词包模型和颜色特征组合的食品区域检测算法,文献利用稀疏编码的算法构建视觉词包来定位高分辨率遥感图像中的飞机目标。
3.5 基于深度学习的目标检测模型
深度学习(Deep Learning)是近几年的研究热点,它通过多层神经网络来抽象对数据的特征表达。一个典型的基于深度学习的目标检测方法包括从输入图像上提取区域块,用卷积神经网络计算每个区域块的特征,最后用线性SVM分类器对每个区域块进行分类等步骤。文献提出了基于R-CNN(Regions with Convolutional Neural Network)框架的目标检测方法,文献从利用贝叶斯优化的搜索算法以及惩罚CNN的不准确训练两个方面改进了基于深度CNN的目标检测方法。
4 算法性能评测
4.1 算法评测指标
目标检测算法评测通常采用查全率(Recall,R)和查准率(Precision,P)来评价算法的有效性。定义TP(True Positives)为正确检测数,FP(FalsePositives)为误检数,FN(False Negatives)为漏检数,则查全率和查准率如式(5)、(6)计算。
(5)
(6)
在算法评测上总是期望P值和R值越大越好,然而这两个值往往会出现矛盾,因此就需要综合考虑这两个值,最常见的方法就是F-Measure。F-Measure是P和R的加权调和平均,如式(7)所示。
(7)当α=1时,则有式(8),即常见的F1。
(8)可知F1综合了P和R的结果,当F1较高时则能说明目标检测方法比较有效。此外,还有一种综合P和R的评测指标,即平均查准率(Average Precision,AP)。在R曲线上进行均匀采样得到相应的P值,将这些采样得到的P值的求平均值作为AP值。
4.2 背景建模的目标检测算法评测
众多学者对背景建模的各种算法都进行了大量评测,最具代表性的评测则是Brutzer等人进行的。他们为了评测已有的背景建模方法在不同场景下的性能,人工合成了SABS(StuttgartArtificialBackgroundSubtraction)数据集,该数据集模拟了多种复杂场景,如动态背景、光线突变、噪声干扰、低照度等。他们选取了9种有名的背景建模算法,并在此数据集上进行了性能评测,结果如表2所示。表中性能指标为F-Measure值。
对表2中9种算法的平均性能进行统计如图3所示,可知不同复杂背景对目标检测的影响较大,随着场景复杂度的提升,算法性能下降较快。其中,光线变化、噪声干扰对背景建模的运动目标检测影响较大,而目标与背景表观相似或目标伪装、视频编码则对运动目标检测影响较小。
4.3 目标建模的目标检测算法评测
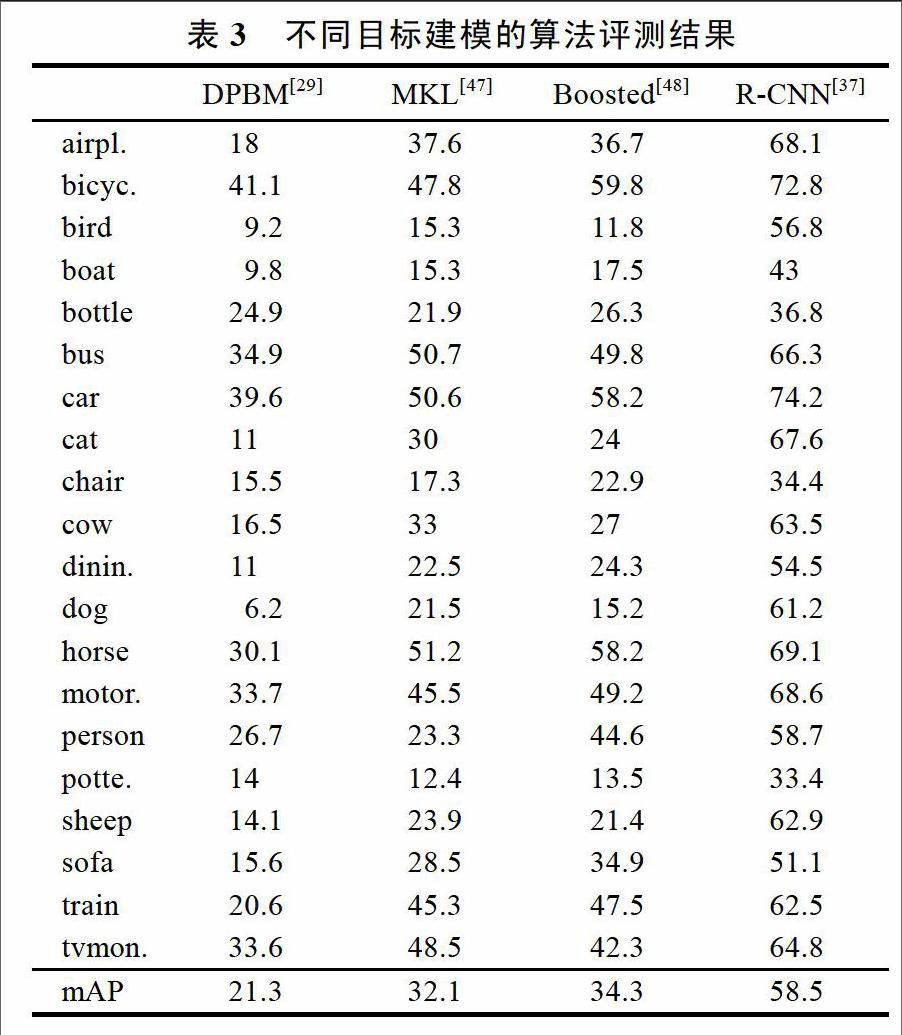
PASCAL VOC数据集是目标检测领域目前公认的评测数据库之一,该数据集的提出也相应的对目标检测算法提出了巨大挑战,促进了目标检测算法的快速发展。从2007年开始,PASCAL VOC数据集类别数目固定为包括飞机(airplane)、自行车(bicycle)、鸟(bird)等20类,以后每年只增加部分样本。PASCALVOC并组织了年度竞赛,吸引了大量研究者使用该数据集评测所提出的算法。我们选取了4种目标检测算法在PASCAL VOC 2007数据集上的评测结果如表3所示。表中性能指标为AP值,mAP(meanAP)为AP均值。
随着大数据和硬件技术的快速发展,也使得在更大规模的数据库上进行研究和评测成为必然。ImageNet便是一种大规模图像数据库,全库截至2013年共有1400万张图像,2.2万个类别,平均每类包含1000张图像。除此之外,ImageNet还构建了一个包含1000类物体120万图像的子集,并以此作为ImageNet竞赛的数据平台,也逐渐成为计算机视觉相关算法评测的标准数据集。
5 总结及展望
基于视频的两类目标检测方法可以解决目标检测的不同子问题,正常情况下优势明显,但在特殊场景下也存在一些不足,如基于背景建模的目标检测方法从复杂背景中提取前景目标则存在较大挑战,基于目标建模的目标检测针对不同的目标或场景则需要训练不同的分类器,目标检测耗时,难以满足实时性等。这是因为这两类目标检测算法都是对中低层特征进行处理,容易受场景噪声、目标和场景的状态多变、目标类型多样等影响。因此,研究者们依然在进行大量研究来提高算法的效率、精度和鲁棒性,其研究的方向及发展趋势主要表现在以下几个方面:
(1)研究结合场景信息和目标状态的分析方法,突破中低层特征的局限,构建特征提取新算子,提高算法的实用性。
(2)研究时域、空域、频域信息,以及不同尺度空间特征信息的结合,综合各种互补的信息,提高目标检测的准确性。
(3)研究深度学习在目标检测中存在的一些困难,如解释性差、模型复杂、计算强度高等问题。深度学习无疑存在一些挑战,但其天然的强大数据表达能力,无疑将会在大数据量的视频中的目标检测及其它视觉研究产生重要影响,也会将目标检测等推向新的高度。
猜你喜欢
科技创新与应用(2016年36期)2017-02-21
科学与财富(2016年28期)2016-10-14
哈尔滨理工大学学报(2015年5期)2016-01-19
湖南大学学报·自然科学版(2015年10期)2015-11-30
现代电子技术(2015年20期)2015-10-26
现代电子技术(2015年14期)2015-07-22
科技与创新(2015年12期)2015-07-21
