
基于频繁集的伴随车辆检测算法研究
2017-01-20 09:50赵秋实史燕中方志蒋遂平
软件 2016年4期
赵秋实 史燕中 方志 蒋遂平

摘要:为从海量机动车行驶数据中找出车辆的伴随车辆信息,本文依据伴随车辆的行为特点及关联挖掘原理提出了一种基于频繁项集的伴随车辆检测算法。通过分析伴随车辆的行驶特点,设定频繁项集的支持度和时间阈值,实现了从单项集到多项集的迭代过程。利用流数据处理方法,添加了针对伴随车辆检测的流数据处理方法,最终使算法可以快速的在海量数据中检测到车辆的伴随车辆信息。经实验验证,本算法可以快速正确的检测出车辆的伴随车辆信息。
关键词:机动车;数据挖掘;频繁集;伴随车辆:大数据
中图分类号:TP391.41 文献标识码:A DOI:10.3969/j.issn.1003-6970.2016.04.018
0 引言
随着社会经济发展,机动车普及程度迅速提高,极大地方便了人们的日常生活,但是同时也让公安部门更难侦破以机动车为交通工具的违法犯罪活动。近年来,部分城市开始建立基于RFID汽车电子标识系统,通过在各卡点采集汽车电子标识信息,用以完成交通数据的采集与分析。相比于传统利用摄像头进行车牌识别的系统,其数据准确度及可信性更高。由于一个城市每天的数据量一般都超过百万条,半年累计的数据量很容易超过了亿条,通过传统的统计学方法已经无法快速的进行处理。因此,借助大数据的数据挖掘方法对交通数据进行分析、挖掘,可以快速的寻找出交通数据中所包含的模式,对城市交通安全的保障具有重要作用。
单机动车行驶轨迹具有一定规律,多机动车行驶轨迹则会交叉重叠,所有轨迹在空间和时间上具有相似性,因此就导致伴随车辆问题的出现。伴随车辆发现是其中一项急待解决实际问题,针对此问题,方艾芬等人利用关联规则进行伴随车辆发现算法研究,通过求集合交集求出伴随车辆,提出利用时间窗结构优化算法,但在挖掘开始前需要指定车辆才能进行计算。吴子珺等人通过生成车辆行驶轨迹,利用计算出车辆行驶过程中发现的可能伴随的车辆频次来计算轨迹相似度并以此判断伴随车辆。这两种算法在计算伴随车辆过程中都需要多次扫描数据库,耗时较长,且算法从全局角度分析是采用排除法得到伴随车辆,在此过程中有较大可能排除真实的伴随车辆数据。因此本文综合两种算法特点,选择使用频繁项集发现算法处理不同卡点的采集数据,且在计算前不必指定车辆,可以挖掘出所有车辆的伴随车辆信息。
频繁项集发现是大数据处理中的一类主要技术。最早的频繁项集发现算法Apriori于1993年由Agrawal等人提出,基于Apriori的大量改进算法和应用也随之出现,本文算法采用了改进算法中部分的优化思想,利用频繁项集的相关概念将伴随检测问题转化为项集发现问题,并针对伴随车辆检测问题实现了改进的Apriori算法,通过实验验证了算法可以正确的完成伴随车辆检测,经分析算法效率更好,且也可对实时数据进行处理。
1 相关定义及算法原理
1.1 相关定义
定义1假设有集合S={s1,s2,…,sn}是包含了所有项的集合,若有另一集合I是集合s的子集,即满足I?S,则称集合I为项集。
定义2如果I是一个项集,I的支持度(support)是指包含I向集合T(即I?T)数量。
定义3假定有支持度阈值s(support thresh-old),如果I的支持度不小于s,则称I是频繁项集(frequent itemset)。
定义4伴随车辆指在某一特定时间段内,多个车辆一起通过多个卡点,且时间差小于预设时间阈值,当检测次数超过假定检测阈值时,称这些通过多个卡点的车辆为伴随车辆。
1.2 算法原理
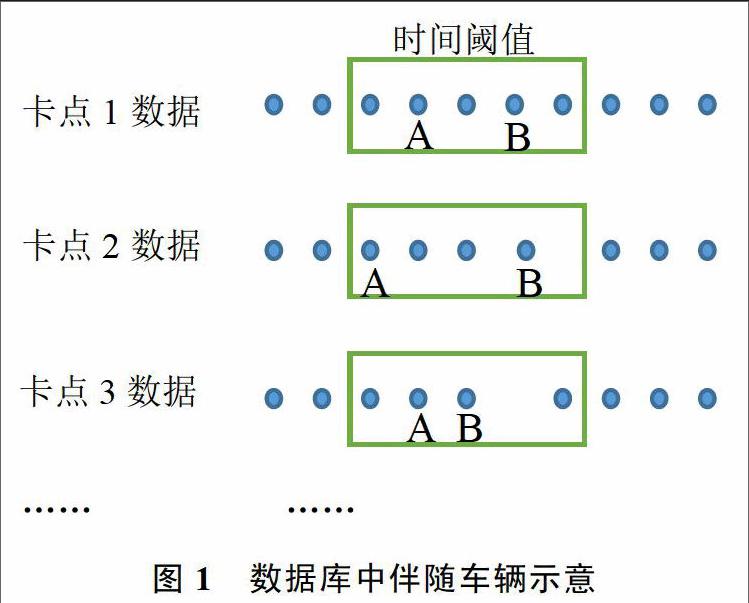
在卡点采集车辆行驶数据时,每采集到一条数据就传递到后台服务器进行处理和存储,因此数据的存储顺序和时间相关,是典型的时间序列。分析伴随车辆定义可知,若选定查找车辆A的伴随车辆,则需要查找在一定时间内伴随车辆A通过多个卡点的车辆,假设此时有车辆B是车辆A的伴随车辆,则在数据库中应有如图1所示的数据关系:
从图1中可以看出,特定车辆和其伴随车辆在数据库中具有较强的关联性,大多数关联规则的数据挖掘过程可以分解为两步:
1.频繁项集产生:发现满足最小支持度阈值的所有项集,即频繁项集;
2.规则产生:从频繁项集中提取具有高置信度的规则。
在这两步中,第一步花费了挖掘过程的大部分时间和计算量,也是算法的关键所在。频繁项集产生算法基本过程为:
1.扫描数据库,计算单项集支持度,生成频繁1-项集L1;
2.利用L1查找频繁2-项集L2;并迭代查找,直到不能再扩展时,停止算法。在第k次迭代时,首先生成候选k-项集CLk,然后扫描数据库得到Lk。
3.在生成频繁项集的基础上,得到满足最小置信度的关联规则。
在迭代过程中每一次扩展都需要扫描一次数据库,这极大的延长了挖掘时间,因此需要设计减少数据库扫描次数。在频繁项集生成过程中会产生大量候选集,在候选项集和频繁项集加上频次统计,则候选项集和频繁集即可等同于数据库数据,因此可利用第k步生成的所有项集内容及其频次来计算生成(k+1)项集。即为本文中检测伴随车辆所使用的算法。
2 伴随车辆频繁项集挖掘算法
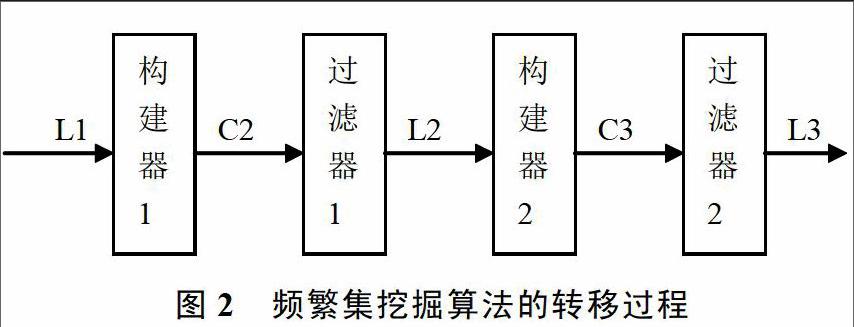
伴随车辆挖掘算法利用频繁项集挖掘算法。根据频繁集挖掘方法,频繁项挖掘的主要计算过程就是从k项集合(在机动车数据挖掘过程中即为有k个汽车电子标识的集合)到下(k+1)项集的转移过程。对于元素数目为k的集合,存在两个频繁项集集合:
(1)候选的k项集集合Ck,这个集合中的k项集需要计算后才能确定是否为真正的频繁项集;
(2)大小为k的真正频繁k项集Lk。
整个转移过程由一系列构建器和过滤器组成,如图2所示,其中,构建器用于产生候选的k项集集合Ck,过滤器用于产生真正频繁k项集Lk,整个过程可以进行到过滤器输出的频繁k项集Lk为空才结束。
在异常群组挖掘中,k项集表示为:
<{V1,V2,…,Vk},Tb,Te,S,C> (1)
其中,{V1,V2,…,Vk}是汽车电子标识的集合,Tb是k辆机动车中最早到达卡点的时间,Te是k辆机动车中最后离开卡点的时间,S是卡点,C是k项集出现的次数。K=1时称为汽车电子标识的单项集,此时Tb=Te。
构建器k的算法和过滤器k的算法分别如算法1、算法2所示。构建器k产生候选k项集集合Ck,过滤器k生成频繁k项集Lk。在构建器1中,初始输入的单项集都是频繁的。
算法1构建器k算法
输入:频繁的k项集:
<{V1,V2,…,Vk},Tb,Te,S,C>
输出:候选的(k+1)项集:
<{V1,Vk,…,Vk,Vk+1},Tb,Te,S,C>
伪代码:
1)k项集的{V1,Vk,…,Vk},Tb,Te,S,C>队列Q1初始化为空
2)(k+1)项集<{V1,Vk,…,Vk,Vk+1},Tb,Te,S,C>的队列Q2初始化为空
3)For each输入k项集<{V1,Vk,…,Vk,Vk+1},Tb',Te',S>>do
4)For each Q2中k项集{V1,Vk,…,V'k},T'b,T'edo
5)If S=S'&&max(Te,T'e)-min(Tb,T'b)≤THt&-&{{V1,V2,…,Vk}∪{V'1,V'2,…,V'k}={V"1,V"2,…,V"k,V”k+1}
6)If Q2中已经有{V"1,V"2,…,V"k,V"k+1}
7)Q<{2中<{V"1,V"2,…,V"k,V"k+1},Tb,Te,S,C>的计数C增加l
8)Else
9)<{V"1,V"2,…,V"k,V"k+1},min(Tb,T'b),max(Te,T'e),S,1>加入Q2
10)End if
11)End if
12)If<{V"1,V"2,…,V"k,V"k+1},Tb,Te,S,C>的计数c≥(k+2)×k/2
13)输出<{V"1,V"2,…,V"k,V"k+1},Tb,Te,S,C>
14)End if
15)End for
16)End for
算法2过滤器k的算法
输入:候选的(k+1)项集:
<{V1,V2,…,Vk,Vk+1},Tb,Te,S>
输出:频繁的(k+1)项集:
<{V1,V2,…,Vk,Vk+1},Tb,Te,S>
伪代码:
1.(k+1)项集<{V1,V2,…,Vk,Vk+1},Tb,Te,S>的队列Q1初始化为空
2.(k+1)项集<{V1,V2,…,Vk,Vk+1},Tb,Te,S>的队列Q2初始化为空
3.For each输入(k+1)项集<{V1,V2,…,Vk,Vk+1},Tb,Te,S>do
4.If Q2中已经有<{V1,V2,…,Vk,Vk+1},Tb,Te,S>
5.Q2中<{V1,V2,…,Vk,Vk+1},Tb,Te,C>的计数C增加1
6.Else
7.<{V1,V2,…,Vk,Vk+1},Tb,Te,C>加人Q2
8.End if
9.<{V1,V2,…,Vk,Vk+1},Tb,Te,S>加入Q1
10.End for
11.For each Q1中<{V1,V2,…,Vk,Vk+1},Tb,Te,S>do
12.If Q2中<<{V1,V2,…,Vk,Vk+1},Tb,Te,C>的计数C≥THs
13.输出<{V1,V2,…,Vk,Vk+1},Tb,Te,S>
14.End if
15.End for
构建器算法中,{V1,V2,…,Vk}∪{V'1,V'2,…,V'k}={V"1,V"2,…,V"k,V"k+1}表示将两个分别包含k个机动车的集合并为一个包含(k+1)个机动车的集合。例如,{A,B,D}∪{A,C,D}={4,B,C,D},但{A,B,D}和{C,D,E}则无法合并为一个包含4个机动车的集合。
构建器算法中,各个卡点S的输入数据、处理和输出是分离的,互不相关。因此,构建器算法完全可以并行化,为每个卡点分配一个构建器任务,并行处理,提高挖掘的速度。在实际挖掘中,各个采集点采集到的交通流数据是按时间排列,可以直接输入到构建器1中,实现异常群组的实时挖掘。
在整个挖掘过程中,涉及2个阈值,THt和THs。其中,THt是时间阈值,当k辆机动车在时间间隔THt内出现在某个采集点时,就认为这k辆机动车时同时出现;THs是频繁集的支持度,当某个k项集<{V1,V2,…,Vk},Tb,Te,S>的{V1,V2,…,Vk}出现次数不小于THs,才认为是频繁的。
整个挖掘过程采用频繁集递增的转移方式,在每个采集点,一旦有机动车被识别到,就与前面指定时间间隔内的其它机动车组合成候选的2项集,然后逐步向k项集转移,并没有采用直接枚举出某个采集点在指定时间间隔内识别的机动车的全部组合的方式。因为采用明枚举指定时间间隔内的机动车的组合,将产生大量的候选数据,另外,如果两个时间间隔有重叠,还需要消除组合枚举中的重复,效率极低。
在数据库不发生变化时,每次进行计算的伴随车辆结果都会相同。但在实际中,数据库一直会加入新的采集数据,若每次都重新使用数据库数据进行计算则会导致大量的重复计算。因此在实际应用时,卡口处采集的数据传人后台时先进行计算,之后再将数据存储到数据库中。计算过程是将当前的过车信息处理成为l项集<{V1},Tb,Te,S>,并加入到原扫描数据库生成的L1中。若L1中不存在则为<{V1,V2,…,Vk},Tb,Te,S,1>,若L1中存在将原记录频次增加l。利用此方法可以实现实时数据的处理,完成实时伴随车辆挖掘过程。
3 实验及结果分析
我们利用实际的数据对实现的挖掘算法进行了验证。实际数据来自于某一体育赛事中的基于RFID的汽车电子标识系统,安装在道路上方的读写器在12天内采集了超过1万辆机动车的约40万个单项集数据。表1给出了部分原始单项集数据,其中,汽车电子标识ID是RFID标签ID的后64比特,采集时间是1970年0时0分0秒开始的秒数。从单项集数据开始可以挖掘出频繁同时出现的机动车。由于赛事中机动车中的行驶是成批活动的,因此理论上正确挖掘的结果会体现出这个特征。
固定频繁集的最小支持度THs=5,对于单项集到2项集的挖掘,时间间隔阈值THt分别取30秒、25秒、20秒、15秒、10秒、5秒,表2给出了各种时间间隔下的输入的频繁单项集L1数目、得到的候选2项集数目C2,中包含的有2个机动车的集合CV2的数目、满足最小支持度THs的频繁2项集数目L2,L2中包含的有2个机动车的集合LV2的数目。从表可以看出,173271对机动车共出现了225513次,被认为是“频繁”的只有2419对,它们共出现了23532次;此外,随着时间间隔的减少,C2和L2的数目也在减少,这与实际情况一致。
固定频繁集的最小支持度THs=5秒,时间间隔阈值THt=30秒,得到的挖掘结果见表3。从表3可知,随着k值的增大,频繁k项集Lk的数目也随着下降,这与实际情况符合。
4 结论
本文根据汽车电子标识系统中对伴随车辆检测的需求,提出了基于频繁项集的伴随车辆挖掘算法,通过实际数据测试证明了算法的有效性。相比于以前的伴随车辆检测算法,本文算法在总体上是增量变化,因此算法可靠性更高。且当数据发生变化时只需将新数据加入到1项集的频次中,不需要再次扫描数据库,节省了大量时间,适用于实时数据挖掘。由于构建器算法在本质上是并行,因此,将其改进为Map/Reduce计算模式,完全可以适合于实时伴随车辆检测和多目标的伴随车辆检测。
猜你喜欢
公民与法治(2022年7期)2022-07-22
中国特种设备安全(2022年1期)2022-04-26
电子制作(2019年24期)2019-02-23
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
