
基于用户评分和项目类偏好的协同过滤推荐算法
2017-01-21 14:49王宇飞宋俊典戴炳荣
软件导刊 2016年12期
关键词:协同过滤
王宇飞+宋俊典+戴炳荣


摘 要:协同过滤(Collaborative Filtering)算法一般采用Pearson相关系数、索伦森指数等方法衡量用户之间的相似性。但是,这些方法难以区分个人的习惯和偏好,以至于计算结果准确度低、区分度差。因此提出从评分差异、评分偏好、置信度3个方面衡量用户的评分相似性,结合项目类偏好去衡量用户相似性。真实数据集上的测试结果显示,改进后的算法比传统度量方法获取到的平均绝对误差(MAE)值更小,能够有效地提高推荐质量。
关键词:协同过滤;评分相似性;项目类偏好;个性化推荐技术
DOIDOI:10.11907/rjdk.162155
中图分类号:TP312
文献标识码:A文章编号:1672-7800(2016)012-0025-05
0 引言
随着个性化推荐技术的迅速发展,个性化推荐不仅为电子商务带来了巨大的商业价值,也为人们的社会生活提供了极大便利[1],具有高效、准确、个性化等特征。作为现有推荐系统中应用最成功的推荐技术之一,基于协同过滤的推荐技术分析不同用户行为所产生的数据来推荐他们可能喜欢的项目,这些数据包含用户浏览历史、购买记录、用户评分等[2-5]。随着协同过滤算法在不同领域的广泛应用,其也逐渐暴露出数据稀疏性[6]、可扩展性[7]、新加入用户或项目冷启动[8]等各方面的问题。
近年来,国内外研究者在协同过滤领域开展了较为丰富的研究,取得了一系列重要研究成果。杨兴耀[9]等构建信任模型来实现评分矩阵填充,从项目和用户属性来对项目的相似性进行评估,并使用调节因子进行两方面协调处理,提高了算法的精确度;赵伟等[10]通利用K-means算法对用户进行聚类,并在用户类中应用协同过滤算法以实现个性化推荐,有效地提高了算法推荐的准确率和扩展性;徐红燕等[11]利用项目各属性的评价分数来评估用户偏好,并结合历史属性分数的变化情况和属性评分相似性综合实现推荐,提高了算法的推荐准确度;方献梅、高晓波[12]引入TF-IDF算法计算用户兴趣权重,构建用户-兴趣矩阵来提高推荐质量。
因此,从评分差异、评分偏好、项目类偏好、用户和项目属性等方面对协同过滤(Collaborative filtering)算法实现改进值得研究。
1 基于用户的协同过滤推荐算法
基于用户(User-based)的协同过滤算法中,用户往往喜欢与他们有相同或相似品味、爱好的一些用户以往所喜欢的项目[13],算法中对于相似性的度量通常采用PCC(Pearson相关系数)、COS(余弦相似度)、SRS(索伦森指数)[14]和JMSD(Jaccard均方差)[15],具体公式如下:
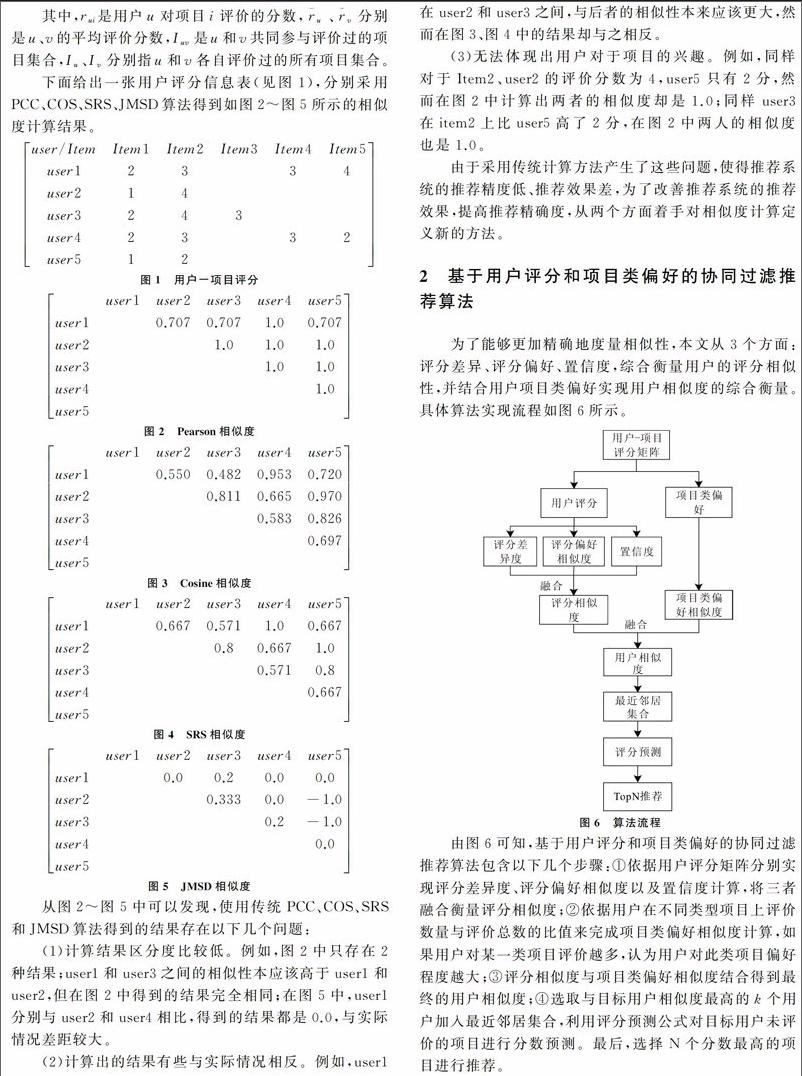
下面给出一张用户评分信息表(见图1),分别采用PCC、COS、SRS、JMSD算法得到如图2~图5所示的相似度计算结果。
从图2~图5中可以发现,使用传统PCC、COS、SRS和JMSD算法得到的结果存在以下几个问题:
(1)计算结果区分度比较低。例如,图2中只存在2种结果;user1和user3之间的相似性本应该高于user1和user2,但在图2中得到的结果完全相同;在图5中,user1分别与user2和user4相比,得到的结果都是0.0,与实际情况差距较大。
(2)计算出的结果有些与实际情况相反。例如,user1在user2和user3之间,与后者的相似性本来应该更大,然而在图3、图4中的结果却与之相反。
(3)无法体现出用户对于项目的兴趣。例如,同样对于Item2、user2的评价分数为4,user5只有2分,然而在图2中计算出两者的相似度却是1.0;同样user3在item2上比user5高了2分,在图2中两人的相似度也是1.0。
由于采用传统计算方法产生了这些问题,使得推荐系统的推荐精度低、推荐效果差,为了改善推荐系统的推荐效果,提高推荐精确度,从两个方面着手对相似度计算定义新的方法。
2 基于用户评分和项目类偏好的协同过滤推荐算法
为了能够更加精确地度量相似性,本文从3个方面:评分差异、评分偏好、置信度,综合衡量用户的评分相似性,并结合用户项目类偏好实现用户相似度的综合衡量。具体算法实现流程如图6所示。
由图6可知,基于用户评分和项目类偏好的协同过滤推荐算法包含以下几个步骤:①依据用户评分矩阵分别实现评分差异度、评分偏好相似度以及置信度计算,将三者融合衡量评分相似度;②依据用户在不同类型项目上评价数量与评价总数的比值来完成项目类偏好相似度计算,如果用户对某一类项目评价越多,认为用户对此类项目偏好程度越大;③评分相似度与项目类偏好相似度结合得到最终的用户相似度;④选取与目标用户相似度最高的k个用户加入最近邻居集合,利用评分预测公式对目标用户未评价的项目进行分数预测。最后,选择N个分数最高的项目进行推荐。
2.1 用户评分相似度
2.1.1 用户评分差异度
将两用户共同评价项目的评分看作两组数据,这两组数据差值的均方根值体现了它们差异性大小。均方根越大,表示两人整体上的评分差异越大,认为两者相似程度越低。在图1中,user1、user2、user3对Item1、Item2的评分分别是:{2, 3}、{1, 4}和{2, 4},由此可知,user1和user2的分差是{1, 1},均方根为1,user1和User3的平均分差是{0, 1},均方根为0.707。因此,计算得到user1和user3比user1和user2更相似,符合实际情况,比PCC、COS、SRS这3种方法得到的计算结果更加准确可信。通过式(1)实现均方根的计算,并使结果处于0~1之间。具体实现如下:
Iuv在式(5)中表示两用户u、v共同评价过的项目集合,rui与rvi则分别代表u、v分别对项目i的评价分数。
2.1.2 评分偏好相似度
现实生活中不同用户有着各自的打分习惯,有些用户对自己所感兴趣的项目打分很高,对其它项目打分较低;有些用户对于所有项目的评分都偏低或者偏高。因此,选取平均评分作为衡量是否喜欢的标准相比文献[16]选择中位数的可信度更高。当评分高于平均分时,表示喜欢此项目,反之则表示不喜欢。
因此,当两个用户在同一个项目上的实际评分与各自平均评分的差值同为正或为负时,表示两人评分偏好趋于相近。通过式(8)可以得到两者在同一项目上的偏好差距,并由所有差异的平均值来反映用户间真实的偏好差距,差距越大表示两者偏好相似性越低。因此,采用以下公式来完成偏好差距计算以及偏好相似性定义:
Iuv同式(5)中的Iuv,Huv(i)指用户u、v在同一个项目上的偏好差距,rui、avgu分别代表用户u对项目i的评价分数和平均评分。
2.1.3 置信度
对置信度的定义一般采用Jaccard函数来表示。认为若两用户一起评价过的项目很少,即便计算出这两人的相似度很高,两者的相似性仍然存在质疑[8]。
但是当两个用户评价的项目数量差距较大时发现,即使评价数量少的一方与多的一方评价的项目完全重叠,得到置信度结果依然很低。为此,分别从用户双方角度定义相对于各自的置信度,然后取平均值,以改善出现上述问题时导致置信度始终过小的情况。
Iuv同式(5)中的Iuv,u、v各自评价过的项目集合分别用Iu、Iv表示。
2.1.4 最终的用户评分相似度
综上,用户的评分相似度为:
2.2 项目类偏好相似度
一个项目可能包含多种不同的类型,例如一部电影,它可能既是科幻片也是爱情片。这里通过图7来展示所有项目的类型所属,如果一个项目包含某一类型,用“1”表示,反之,用“0”表示,k表示项目的类型总数。
现实生活中,若用户对于某一类项目评价的次数越多,可以认为用户在此类项目上的偏好程度越大。由用户评分信息可以得到如图8所示的类型偏好矩阵。
其中,Gij表示ui对Cj类项目的偏好程度。同时,以用户的平均评分作为衡量标准,当用户对某一项目的评分大于平均评分时,表示在此项目上用户的偏好为正,反之则认为偏好为负(将等于平均分的项目也归于偏好为负)。所以根据用户的项目偏好情况,其类型偏好也可以分为正向偏好和负向偏好。(1)正向偏好:
3 实验结果及分析
3.1 数据集
实验中使用的数据集是著名的MovieLens(ML)数据集[17],它是由美国的GroupLens研究团队在明尼苏达大学历时约7个月收集的。该数据集被分为5组,每一组中的数据有两成将用作算法的测试集,剩余的作为训练集使用。每一组中用于实验的评分数量共有100 000条,评分等级的范围是在1~5分,1分等级最低,5分等级最高。另外在每一组中,每一位用户都参与评价过至少20部电影,每一部电影可能属于一种或多种类型,还包含了电影、用户各自的基本属性信息。此电影数据集的数据稀疏度为:
1-100,000943×1,682=0.937
3.2 评价标准
MAE被定义为预测值和实际值之间绝对误差的平均值,是使用最广泛的推荐质量评价指标,被用于评估推荐准确性。本文使用MAE作为评价指标,假定某一用户u对任意一部电影j的实际评分为rj(u),与其相对应的预测所得分数为Rj(u),具体公式如下:
3.3 实验结果
本文对5组数据分别进行测试,例如在表1中“u1.base”和“u1.test”这一组数据,其中“u1.base”和“u1.test”分别作为训练集和测试集。
对测试集中的所有用户进行测试(取所有测试用户MAE的平均值作为测试结果),最近邻居用户的数量K分别取值:5、10、20、30、40、50、60、70、80,经过测试,各自的推荐效果如图10~图14所示。
从实验所得的推荐效果图中可以看出,使用除了PCC之外的其它方法,当最近邻居数据从K=5到K=30时,推荐质量会迅速提高;从K=30往后,推荐质量的提高速度逐渐放缓,趋于平稳状态,相比之下使用本文算法的推荐质量更高。
4 结语
本文从用户已有的评价分数信息中挖掘用户潜在的评分差异、习惯、类型的评价数量分布,提出从用户评分、项目的类型偏好两个方面对相似度进行综合评定的计算方法。对比传统4种方法分别进行实验所产生的测试结果,可以证明采用本文方法在推荐准确性方面有明显提高。未来,将在现有的研究成果上继续进行优化,并且在缓解数据稀疏、冷启动方向开展深入研究。
参考文献:
[1] CHEN H,LI Z,HU W.An improved collaborative recommendation algorithm based on optimized user similarity[J].Journal of Supercomputing,2015:1-14.
[2] BOBADILLA J,HERNANDO A,ORTEGA F,et al.Collaborative filtering based on significances[J].Information Sciences,2012,185(1):1-17.
[3] ZHANG J,LIN Y,LIN M,et al.An effective collaborative filtering algorithm based on user preference clustering[J].Applied Intelligence,2016:1-11.
[4] JIA C X,LIU R R.Improve the algorithmic performance of collaborative filtering by using the interevent time distribution of human behaviors[J].Physica A Statistical Mechanics & Its Applications,2015:236-245.
[5] KOOHBORFARDHAGHIGHI S,KIM J.Using structural information for distributed recommendation in a social network[J].Applied Intelligence,2013,38(38):255-266.
[6] 高倩,何聚厚.改进的面向数据稀疏的协同过滤推荐算法[J].计算机技术与发展,2016,26(03):63-66.
[7] SHANG Y,LI Z,QU W,et al.Scalable collaborative filtering recommendation algorithm with MapReduce[C].International Conference on Dependable, Autonomic and Secure Computing,2014:103-108.
[8] BARJASTEH I,FORSATI R,ROSS D,et al.Cold-start recommendation with provable guarantees:a decoupled approach[J].IEEE Transactions on Knowledge & Data Engineering,2016,28(6):1.
[9] 杨兴耀,于炯,吐尔根·依布拉音,等.基于信任模型填充的协同过滤推荐模型[J].计算机工程,2015(5):6-13.
[10] 赵伟,林楠,韩英,等.一种改进的K-means聚类的协同过滤算法[J].安徽大学学报:自然科学版,2016,40(2):32-36.
[11] 徐红艳,杜文刚,冯勇,等.一种基于多属性评分的协同过滤算法[J].辽宁大学学报:自然科学,2015,42(2):136-142.
[12] 方献梅,高晓波.基于用户兴趣的协同过滤推荐算法[J].软件导刊,2016,15(2):50-51.
[13] DONGZHAN ZHANG,CHAO XU.A collaborative filtering recommadation system by unifying user similarity and item similarity[J].LNCS,2012,7142(2):175-184.
[14] PIRASTEH P,HWANG D,JUNG J E.Weighted similarity schemes for high scalability in user-based collaborative filtering[J].Mobile Networks & Applications,2014,20(4):497-507.
[15] BOBADILLA J,SERRADILLA F,BERNAL J.A new collaborative filtering metric that improves the behavior of recommender systems[J].Knowledge-Based Systems,2010,23(6):520-528.
[16] RYDEN F.Tech to the future:making a "kinection" with haptic interaction[J].IEEE Potentials,2012,31(3):34-36.
[17] Movielens 100K dataset[EB/OL].http://grouplens.org/datasets/movielens/100k/.
(责任编辑:孙 娟)
