
ID3分类及其剪枝算法研究
2017-01-21 14:53刘冲杨磊李娜
软件导刊 2016年12期
关键词:决策树
刘冲+杨磊+李娜
摘 要:分类是数据挖掘的一个重要课题。分类的目的是建立一个分类模型,该模型能把数据库中的数据项映射到给定类别中的某一个利用该模型形成分类规则并预测未来数据趋势[1]。决策树归纳是经典的分类算法,构建决策树模型算法中最有影响力的方法是ID3算法。针对ID3算法缺点,使用预剪枝和后剪枝相结合的办法处理决策树中的过学习情况,可生成一个更简单、更精确的决策树。
关键词:ID3分类算法; 决策树; 剪枝算法
DOIDOI:10.11907/rjdk.162536
中图分类号:TP312
文献标识码:A文章编号:1672-7800(2016)012-0033-02
1 ID3分类算法
1.1 ID3算法原理
决策树归纳是经典的分类算法[1]。ID3算法是Quinlan提出的一个著名的决策树生成方法。决策树是指具有以下性质的树:每个内部节点都被标记一个属性,每个弧都被标记一个值,这个值对应于相应父节点属性;每个叶节点都被标记一个类[2]。ID3算法是一种基于信息熵的决策树算法,算法的核心是在生成决策树时使用信息增益作为训练样本集合的分裂度量标准,选择信息增益最大值的属性对训练样本划分,该属性使得划分样本分类所需的信息量最小。该方法可以减少训练样本的划分次数,并尽可能得到一棵简单的决策树来描述相关信息。
1.2 ID3算法缺点
(1)对噪声较为敏感,训练数据的轻微错误会导致不同结果,鲁棒性较差;算法结果随训练集记录个数的改变而不同,不便于渐行渐进学习。
(2)ID3算法只能处理离散属性的数据,对于连续属性数据,必须先进行离散化处理才能使用。如产品名称是一个离散性属性,适合用ID3算法处理,而产品价格是连续性属性,必须对产品价格进行离散化处理后才能使用。
(3) ID3算法不能处理属性为空的记录,而在实际业务数据中,又存在大量的空记录,如果仅仅有一个缺失值就单纯地删除整条记录的话,那么最终可能得到一个很小的训练集,同时这个训练集可能已经丢失了业务数据中所包含的一些重要信息,所以要对缺省属性进行处理才能使训练集适用于ID3算法。
(4)ID3算法在搜索过程中不进行回溯,每当选择了一个属性进行分类后,以后的处理过程就不会再考虑该属性了,这样算法很容易收敛到局部最优而不是全局最优。
(5)ID3算法对于较小的数据集很有效,当这些算法用于非常大的数据库挖掘时,算法效率成为瓶颈。
2 剪枝算法
决策树是分类和预测的强有力工具,而易于理解和表示规则是决策树的优势。在最终形成的决策树上,每个内部节点都被标记一个属性,每个弧都被标记一个值,这个值对应于相应父节点属性;每个叶节点都被标记一个类;每个分枝代表对该属性的测试输出。决策树的生成过程分为两个步骤:一是生成树,二是对树的剪枝,就是去掉一些可能是噪声或者是错误的数据[3]。
样本分为训练集和测试集,给定一个决策树A,如果在假设空间中存在另一个决策树B,使得A在训练集上的错误率比B小,但是在测试集上A的错误率差比B大,则称A为过度拟合训练数据。
导致这种过度拟合现象的发生原因是:①训练样本中存在随机错误或噪声,噪声会导致分类结果冲突,比如对某个实例的每个属性都有相同的属性值,但在训练集和测试集中却有着不同的分类结果;②当训练样本数据量比较小时,特别是当决策树中的某些分枝与客观事实不符合时,很可能出现巧合的规律性[4-5]。第①种情况适应于后剪枝方法,第②种情况适应于预剪枝方法。
(1)预剪枝:在生成决策树之前,通过一定规则较早地停止树的生长。由于预剪枝不必生成整棵决策树,且算法相对简单,效率较高,适合处理大规模数据问题。该方法能大大缩短决策树规则生成时间,但如果阈值设置不准确,会大大降低算法的精确度。预剪枝具体在什么时候停止决策树生长衍生出多种方法:最简单的方法是在决策树生长到某一固定高度时停止树的生长;如果某节点的实例个数与总样本的个数之比小于某个阈值就停止树的生长。
(2)后剪枝:允许决策树过度拟合数据,它由完全生长的树剪去分枝。通过删除节点分枝剪掉树节点。这种方法能保证结果具有较高的准确度,但代价是处理大规模数据分类集时会耗费较多时间。常用的后剪枝算法有REP方法、PEP方法和MEP方法等。后剪枝方法主要是通过不断修改子树使之成为叶节点[6]。
3 ID3改进算法实现
决策树生成后,从根到叶子结点可以创建一条IF-THEN形式规则,规则左边为规则前件,叶子节点的属性值为规则后件。分类规则的质量可以用准确率和覆盖率两个参数度量[7]。
(1)准确率:是指结点在测试集上正确预测的实例数与分配给该节点的实例总数之比,度量该节点能够正确预测目标值的可能性。实际中由于测试集数目较大,求出各个结点的准确率会影响算法的执行效率,故采用总的准确率来评估分类质量,也就是用所有节点在测试集中预测正确的实例数与测试集大小的比例来反映总体评价标准。
(2)覆盖率:指节点中占某一类最多的实例数量与训练样本集中该类的实例数量之比,以此度量从训练集中分配了多少实例给该节点。覆盖率也叫置信度,置信度小于某个阈值的节点会被预剪掉,如果一个父节点所有的子结点都被剪枝掉了,则该父节点成为叶结点。把父节点的节点名替换为该节点中某实例所对应的类标号,并且释放掉分裂属性,以便让后续节点可以重新利用该属性。通过设置置信度阈值,可以较快得到一棵决策树。
3.1 算法数据结构
改进后的算法实现过程中用到的决策树结点代码:
class TreeNode { TreeNode parent; //父节点 String parentAttribute; //指向父结点的哪个属性 String nodeName; //节点名 String[] attributes; //属性数组 TreeNode[] childNodes; //子节点数组 String maxAttribute; //结点中占最多实例数所对应的属性 int errorNum; //记录决策树在测试集中的错误数 double percent; //置信度,置信度小于某个阈值,属性提前停止分裂
}
3.2 算法实现
根据未剪枝前的决策树和测试集递归调用算法,计算出树中每个节点的错误数,然后根据REP剪枝准则来剪枝决策树,代码如下:
public void repairDTree(TreeNode node)
{
TreeNode[] childs = node.childNodes;int total=0;
for (int i = 0; i < childs.length; i++)
if (childs[i] != null)
total=total+childs[i].errorNum; //计算出子结点的错误总数
//如果父节点错误数不大于子结点的错误总数,则删除子结点
if(total>=node.errorNum)
node.childNodes = new TreeNode[0];
else for (int i = 0; i < childs.length; i++)
{
if (childs[i] != null) repairDTree(childs[i]);
}
}
4 实验结果比较
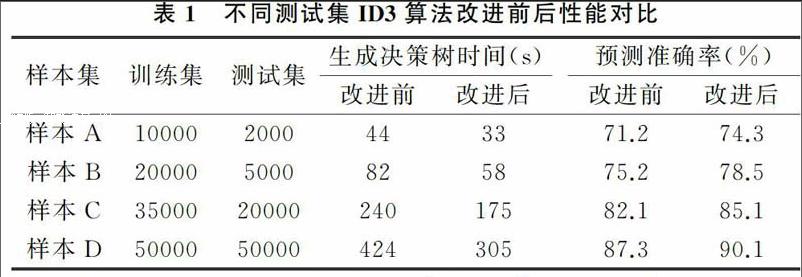
针对不同的训练集,ID3算法在改进前后的性能比较情况如表1所示。从数据仓库中随机抽取4个样本集作为数据来源,且所有实验都在同一配置同一操作系统的机器上进行。
从时间复杂度上分析:改进后的算法在决策树生成时间上明显比改进前短,而且随着数据量的增大,改进前后算法在时间上都非线性递增。数据量越大,递增的幅度越大,在时间复杂度上试验结果与理论相符。
从准确率上分析:ID3改进算法在测试集上的预测准确率比改进前高。由于采用了后剪枝算法,从而消除了决策树生成过程中的过学习问题,提高了预测准确率。ID3算法改进后的预测准确率随着训练集和测试集的增长呈现出线性增长趋势,即样本集越大,效果越明显。
参考文献:
[1] 邹媛.基于决策树的数据挖掘算法的应用与研究[J].科学技术与工程,2010,10(18):4510-4515.
[2] 孙爱东,朱梅阶.基于属性值的ID3算法改进[J].计算机工程设计,2008,29(12): 3011-3012.
[3] 杨学兵.决策树算法及其核心技术[J].计算机技术与发展,2007,17(1):43-45.
[4] 鲁为,王枞.决策树算法的优化与比较[J].计算机工程,2007,33(16):189-190.
[5] 李道国.决策树剪枝算法的研究和改进[J].计算机工程,2005(8):33-46.
[6] 邵峰晶,于忠清.数据挖掘原理与算法[M].北京:中国水利水电出版社,2003.
[7] 朱颢东.ID3算法的优化[J].华中科技大学学报,2010,38(5):9-12.
(责任编辑:杜能钢)
猜你喜欢
世界科学技术-中医药现代化(2021年8期)2021-12-21
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
自动化学报(2018年6期)2018-07-23
成都信息工程大学学报(2018年6期)2018-03-21
电子制作(2017年24期)2017-02-02
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
电测与仪表(2016年2期)2016-04-12
智能系统学报(2015年4期)2015-12-27
郑州大学学报(医学版)(2015年1期)2015-02-27
