
数据挖掘技术在电站设备故障分析中的应用
2017-01-21 15:55王爽赵会洋
软件导刊 2016年12期
王爽+赵会洋


摘 要:发电站正常高效运行对保障社会发展和人民生活极其重要。电站运行中产生大量的故障记录数据,将数据挖掘技术应用于电站设备故障的大数据分析,发现隐藏在数据中的有用信息,有助于电站管理工作改革和设备管理技术创新。根据某发电集团设备故障统计报告,制定了相应的数据分析方案,研究了文本挖掘、关联分析、聚类分析等多种数据挖掘方法的关键技术,详述了这些技术在电站故障分析中的应用方法及效果。
关键词:电站设备故障;数据挖掘;文本挖掘;关联规则;聚类
DOIDOI:10.11907/rjdk.162187
中图分类号:TP319
文献标识码:A文章编号:1672-7800(2016)012-0121-03
0 引言
电力大数据的信息挖掘和利用将给电力企业带来新一轮商业模式转变和价值创新。文献[1]~[8]研究了数据挖掘技术在火电厂设备故障诊断、状态预测方面的应用;文献[9]~[11]研究了数据挖掘技术在核电厂中的应用,主要用于异常值检测和抗震性推断等;文献[12]~[13]研究了数据挖掘技术在风力发电厂中的应用,主要用于风力、风速的预测;文献[14]~[15]研究了数据挖掘技术在水电站和太阳能发电中的应用。这些研究的开展多基于电站设备运行的实时数据,虽然研究成果在一定程度上促进了电站的健康高效运行和科学管理,但研究范围不全面。本文将基于大量的设备故障历史统计数据,运用文本挖掘、关联规则、聚类等多种数据挖掘技术展开研究,发现其中隐藏的有用信息,为电站的运行管理提供决策支持。
1 数据分析方案设计与数据预处理
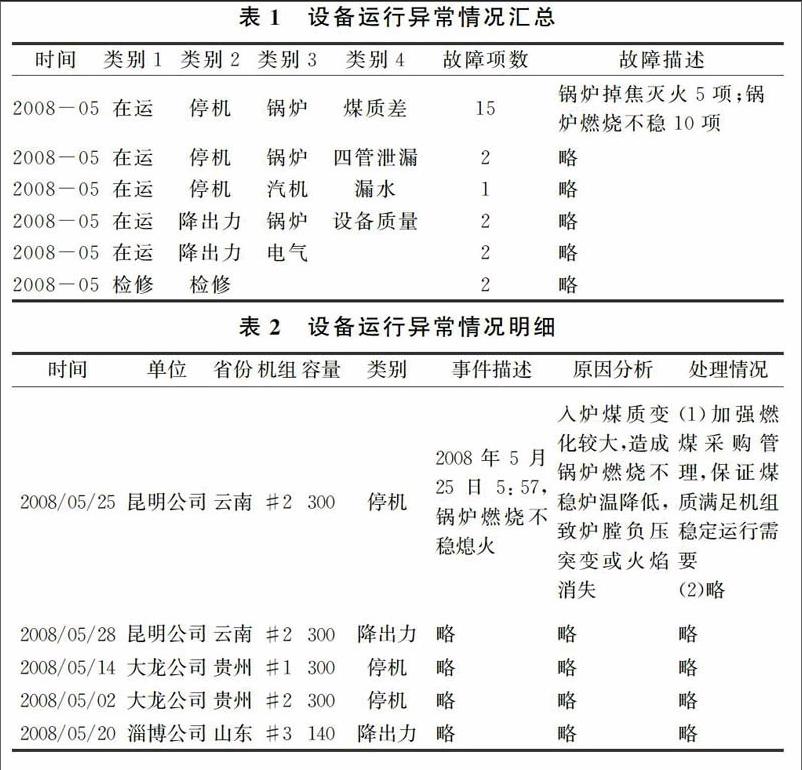
研究所用数据来自某大型发电集团2008-2014年设备运行故障月度报告。报告有word和pdf两种格式,每份报告主要内容有设备运行故障统计概况、具体案例描述等。案例描述提供了设备故障发生的时间、地点、原因等信息,信息的数据类型有日期、数字、文本等。根据数据源的这些特点,制定了如图1所示的数据分析方案。
在数据预处理环节,首先要将各种数据源中的有用信息提取出来。数据提取的原则是便于分析且尽可能少地丢失信息,最终将数据整理成两张Excel表,分别是设备运行故障总表和设备运行故障明细表,它们的结构和样本数据示例如表1和表2所示。由于数据条目较多,在此仅列出每张表的少数几条数据。对于文字内容描述较多的字段,仅列出一条较为完整的数据来说明问题,其它条目内容用“略”来代替。表1中的类别1到类别4从粗到细分别描述了设备故障类别,每条样本数据展现不同类别的故障在特定时间所发生的项数和具体原因描述。表2较为详细地描述了每台设备故障发生的时间、单位、省份、机组号、机组容量、类别、事件描述、原因分析和处理情况。
缺失值处理和数据类型处理是数据预处理环节中另外两个重要工作。缺失值处理方法有删除含有缺失值的个案和可能值插补缺失值。可能值插补缺失值方法有:均值插补、极大似然估计、多重插补等。根据具体分析任务,由分析目的选择缺失值处理方法。以表1为例,当分析文字型数据时,由于缺失量较少,采取了删除含有缺失值个案的方法;当分析故障项数时,采取了同类别均值插补方法。数据类型处理就是根据数据的特征和分析目的确定数据字段类型。以表1为例,时间为日期型,类别1~4为因子型,故障项数为数字型,故障描述为字符型。完成数据预处理环节后,利用多种数据挖掘方法对数据进行隐藏信息挖掘。
2 文本挖掘研究与应用
文本挖掘中最重要的工作就是分词,分词算法采用中国科学院计算技术研究所的中文分词算法ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System)。ICTCLAS基于隐马尔可夫模型HMM(Hidden Markov Model)实现,HMM定义如下:
一个隐马尔科夫模型是一个三元组(∏,A,B)。其中,∏是初始状态的概率分布,∏=(πi),πi表示在t=1时刻,状态为si的概率;
A为状态转移矩阵,A=(aij),aij=P(qt+1=sj|qt=si),表示在t时刻、状态为si的条件下,在t+1时刻状态是sj的概率;
B为混淆矩阵,B=(bjk),bjk=P(ok|sj),表示在隐含状态是sj条件下,观察状态为ok的概率。
将文本挖掘技术应用于电站故障数据挖掘步骤如下:①词典调整。分词的依据是词典,通常词典中只包含常用词汇,因此,在对诸如电力专业领域数据进行文本分析时,需要根据分析要求加入一定量的专业词汇;②分词。利用ICTCLAS分词算法对文本字段进行分词;③词性过滤。为了突出故障原因,需要去掉一些无关的词,例如形容词、数量词、副词等;④构建语料库并处理。构建语料库后就可以进一步处理,例如去除停用词、标点符号、数字、空格等;⑤构建词条文档矩阵(Term-Document Matrix,TDM)并处理。TDM中列出了每个词条在文档中出现的频次,可以去除频次较低的词条项,或进行其它与频次有关的处理;⑥画文本特征词云。通过画文本特征词云直观地展示文本挖掘结果。通过词云展示,可以从大数据中发现热点问题。
通过对表1中停机故障的描述字段进行文本挖掘,得到如图2所示结果。通过图2的分析结果可以看出,停机异常多是由锅炉故障引起的,较为重要的原因是液体泄漏和电气设备跳闸。通过对表1中停机和降出力两类故障的描述字段对比分析,得到如图3所示结果。通过对图3的分析可以看出,停机异常的主要原因是锅炉和汽机的液体泄漏及电气保护,而降出力异常多是由风机和煤质差引起的。
3 关联规则分析与应用
关联规则是描述数据库中数据项之间所存在关系的规则,即根据一个事务中某些项的出现可导出另一些项在同一事务中也出现,亦即隐藏在数据间的关联或相互关系。关联规则广泛应用于金融、电子商务等行业。金融行业可以通过关联规则挖掘出很多与客户有关的关联关系,从而为制定营销策略提供依据。电子购物网站使用关联规则挖掘,可设置商品促销组合、进行商品推荐、定向投放广告等。
关联规则的代表算法有Apriori、FP-tree等。本文利用Apriori方法,对表1中的不同类别关系进行关联分析,分析结果如图4所示。由分析得到:运行设备故障导致停机故障,停机原因主要是锅炉问题。
4 聚类分析研究与应用
聚类分析是利用科学的度量方法,将一组数据按照相似性和差异性分为几个类别,目的是使属于同一类别的数据相似性尽可能大,不同类别数据间的相似性尽可能小。聚类分析应用于许多领域,如商务智能、图像模式识别、Web搜索和生物学等。将聚类分析方法应用于电站的故障数据分析分类及分析结果如下:
(1)按设备故障的宏观类型对省份进行聚类。使用的数据字段有表2中的故障类别(停机、降出力、检修)、省份两个字段。根据分析结果,电力集团可发现各省份子公司设备故障存在相似之处,并据此制定分类管理政策。实行分类管理,可以节约人力、物力、财力等资源。
(2)按设备故障的宏观类型对单位进行聚类。使用的数据字段有表2中的故障类别(停机、降出力、检修)、单位两个字段。如果两个发电公司在故障类别上表现出较大的相似性,聚类算法会将它们聚为一类,电力集团可根据故障类别实现更细粒度的管理。
(3)按故障设备的容量对省份或单位进行聚类。使用的数据字段有表2中的容量、单位两个字段。由于相同容量的发电设备在实现技术、制造单位方面可能存在相似之处,电力集团也可以通过这个分析结果对企业进行分类管理。
根据上述方法(1),使用Centroid聚类算法对数据进行聚类,得到如图5所示的分析结果。由图5可知,聚类结果分为7类。其中,内蒙古、黑龙江、山东、四川构成一类,湖北、陕西、云南、贵州、辽宁4个省份的故障发生情况具有较大相似性分为一类,江苏、山西、宁夏、河北、河南、福建、新疆分为一类,安徽、青海等省份分为一类。
5 结语
数据挖掘技术已经用于电力系统分析并取得了一定的研究成果。在大数据背景下,其应用将更加广泛和深入。本文从新的数据视角对电站设备故障进行分析,研究了文本挖掘、关联规则、聚类等数据挖掘技术在电站设备故障分析中的应用,研究结论对电力企业管理决策制定和设备故障技术创新都有一定帮助。下一步将重点进行以下研究工作:①针对数据进行更加深入细致的剖析,发现其中更多的隐藏信息;②引入更丰富的数据挖掘技术应用于电力数据分析中。
参考文献:
[1] 刘宝玲,何钧,曾暄.嵌套式数据挖掘技术在电站工况分析中的应用[J].电站系统工程,2014(5):13-15.
[2] 邱凤翔,司风琪,徐治皋.电站关联规则的主元分析挖掘方法及传感器故障检测[J].中国电机工程学报,2009(5):97-102.
[3] 牛培峰,张泽,王怀宝.基于模糊聚类神经网络的电站锅炉故障诊断研究[J].微计算机信息,2010(7):40-42.
[4] ZHENG L K,FENG K,XIAO X Q,et al.Early warning of power plant equipment based on massive real-time data mining technology[J].ICFMM,2014(6):1487-1490.
[5] BAO A,PAN W G,WANG W H,et al.Advances in data mining and applications in power plants[J].ICEESD,2011(10):347-487.
[6] JIN T,FU Z G.Application of data mining in power plant unburned carbon in fly ash modeling[J].FSKD,2010(8):2761-2765.
[7] YANG P.Fault diagnosis system for boilers in thermal power plant by data mining[J].Journal of Information and Computational Science,2006(3):117-127.
[8] ZENG D L,YANG T T,CHENG X,et al.Application of data mining method in real-time optimal load dispatching of power plant[J].Zhongguo Dianji Gongcheng Xuebao,2010,30(4):109-114.
[9] LIU D P,ZHENG K T,YAN Q Q,et al.Application of data stream outlier mining techniques in steam generator safety early warning system of nuclear power plant[J].ICMTMA,2013(1):287-290.
[10] MU Y,XIA H,LIU Y K.Study on fault diagnosis technology for nuclear power plants based on time series data mining[J].Hedongli Gongcheng,2011,32(5):45-48.
[11] SHU Y F.Inference of power plant quake-proof information based on interactive data mining approach[J].Advanced Engineering Informatics,2007,21(3):257-267.
[12] OZKAN M B,KK D,TERCIYANLI F,et al.A data mining-based wind power forecasting method:results for wind power plants in Turkey[J].DaWaK,2013(8):268-276.
[13] COLAK I,SAGIROGLU S,DEMIRTAS M,et al.A data mining approach:analyzing wind speed and insolation period data in Turkey for installations of wind and solar power plants[J].Energy Conversion and Management,2013,65(1):185-197.
[14] OHANA I,BEZERRA U H,VIEIRA J P A.Data-mining experiments on a hydroelectric power plant[J].IET Generation,Transmission and Distribution,2012,6(5):395-403.
[15] MACIEJEWSKI H,VALENZUELA L,BERENGUEL M,et al.Analyzing solar power plant performance through data mining[J].Journal of Solar Energy Engineering,2008,130(4):0445031-0445033.
(责任编辑:杜能钢)
猜你喜欢
电力与能源(2017年6期)2017-05-14
语文教学之友(2016年5期)2016-06-15
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
