
CUDA在教学软件开发中的应用
2017-01-21 15:57刘晓刚
软件导刊 2016年12期
刘晓刚
摘 要:可编程图形处理器GPU已经演化成高并行度、多线程、拥有强大计算能力和极高存储器带宽的多核处理器,图形处理器通用计算技术GPGPU把个人计算机上的显卡用于通用计算,代替CPU完成计算工作,可以大大提升计算效率。采用CUDA技术编程,利用GPU运行教学软件,效果良好,较大地提高了软件的计算能力和运行效率,在CPU价格昂贵,大规模并行计算需求旺盛的今天,CUDA技术可以提高软件运行效率,提高计算能力,同时可减少硬件购置成本,为学校或科研单位节约预算。
关键词:GPU;GPGPU;CUDA;教学软件开发
DOIDOI:10.11907/rjdk.162098
中图分类号:TP319
文献标识码:A文章编号:1672-7800(2016)012-0124-03
0 引言
自2004年以来,CPU的发展已告别主频时代,单核CPU性能的提升日趋平缓,CPU制造公司开始用增加计算核心的方法增强计算能力,多核CPU层出不穷。尽管如此,依然不能满足日益增长的计算需要,一些计算密集型的应用和实时处理程序需要依靠超级计算机的计算性能来完成。同时,在市场对实时、高清晰度三维图形存在极高需求的推动下,可编程图形处理器(Graphics Processing Unit,简称GPU)已经演化成高并行度、多线程、拥有强大计算能力和极高存储器带宽的多核处理器,一种新兴的加速技术应运而生,即图形处理器通用计算技术(General Purpose Computing on Graphics Processing Unit,简称GPGPU),它把个人计算机上的显卡用于通用计算,代替CPU完成计算工作,可以提升计算效率。相比CPU,GPGPU具有体积小、低功耗、低成本的特点,已经成为计算密集型应用的高效解决方案,并在事实上作为第二个通用处理器被大量应用软件使用。而CUDA就是著名的显卡公司NVIDIA对于GPGPU的完整解决方案。
1 在教学软件开发中使用CUDA的意义
CUDA的全称是Compute Unified Device Architecture(计算机统一设备架构),是NVIDIA公司在2007年推向市场的并行计算架构。CUDA是作为图形处理器的通用计算引擎,作为全套工具提供给用户利用NVIDIA产品进行GPGPU开发。CUDA提供了一种简便的方式编写应用于CUDA架构上的GPGPU代码,它含有NVIDIA扩展和限制的类C语言,支持大多数C语言指令和语法,并加入了使程序能在GPU上进行多线程计算的语言扩展,使用CUDA可以方便地编写在GPU上并行运行的程序[1]。
众所周知,学校、科研单位以及培训机构在资金、预算上受财政的限制,缺少高性能的计算机和服务器等硬件设备。同时,在高速发展的互联网时代,也需要各种教学软件的高效运行,以保证教学、科研活动的正常进行。在教学软件开发中使用CUDA技术有具有较大意义。一方面,带多处理器的显示图形卡越来越便宜,购置成本低,其计算性能却可以代替昂贵的高端CPU[2];另一方面,采用CUDA技术开发或改写教学软件,可以大大提高其运行效率,进而延长软件的使用寿命。
由此可见,CUDA技术可以减少硬件的购置成本,提高软件的运行效率,提高计算能力,并为学校或科研单位节约预算,值得推广。同时,CUDA的软件开发类似于C语言开发,易于被开发人员所学习掌握。下文将通过一个实例,介绍基于CUDA技术软件的开发方法,并对其运行性能进行对比分析。
2 开发实例
2.1 基础知识
在CUDA中,与一个线程组相关联的硬件实现称为一个流多处理器(Streaming Multiprocessor),或称多处理器;一个流多处理器包含若干个标量处理器(scalar processor),即单处理器,或称CUDA核(CUDA core)。单处理器是具体计算指令的执行单位,多处理器是一套完整的计算资源的最小单位。控制器将一个线程组分配给一个多处理器,多处理器中的核协同工作,并行处理所有的线程。一个支持CUDA的NVIDIA图形处理器中至少包含一个多处理器,如GeForce GTX 295,它有60个多处理器,线程组就被平均分配给这60个多处理器并行处理。而且在每个多处理器中,标量处理器也是并行工作的。通过线程组的方式,CUDA程序可以适应于不同的硬件规格[3],从高端显卡到普通显卡,这是一个具有高度可扩展性的编程模型。
CUDA的程序将函数根据调用和执行地方的不同分为不同的类型:在CPU上调用、CPU上执行的的函数称为主机函数;在CPU上调用、在GPU上执行的函数称为全局函数,常称为内核,简称核,它是GPU函数执行时的基本单位。在调用此类函数时,它将由 N 个不同的 CUDA 线程并行执行 N 次,这与普通的C语言函数只执行一次的方式不同,所以,虽然这里没有看到循环的语法,却类似执行了循环语句。主机函数在声明时带限定符__host__,全局函数在声明时必须带限定符__global__。
CUDA将一个线程组称为一个block,每个block由若干线程组成,完成一次函数调用的所有block组成了一个grid。block和grid的尺寸都可以用三元向量表示。线程索引(thread index)是线程在每个block里的索引。由于block的尺寸是三维的,线程索引也是一个三元向量threadIdx。访问它的每个分量需要加上分量名称如threadIdx.x,threadIdx.y和threadIdx.z。执行内核的每个线程都会被分配一个独特的线程 ID,可通过内置的 threadIdx 变量在内核中访问此ID。
2.2 具体实例
本次实例中的显卡是NVIDIA 的NVS 4200M,计算能力是2.1,只有一个多处理器,有48个核,GPU时钟频率为1.62GHz,现在只能算是运算能力一般的GPU。CPU是INTEL的Core i5-2410M,主频2.3GHz,属于性能中等的CPU。
先通过计算分析一下GPU和CPU的计算能力。NVS 4200M显卡的计算能力是48×1.62= 77.76 GFLOPS,Core i5-2410M CPU的计算能力是2.4×4=9.6GFLOPS。因此得出前者的浮点数计算性能是后者的8.1倍,下面再通过具体实例的计算结果来验证它们的计算能力。
程序开始处根据GPU的硬件参数定义数据常量DATA_SIZE为1048576,线程常量THREAD_NUM为256,线程组常量BLOCK_NUM为32,GPU主频FREQUENCY是 1620000kHz。
首先通过子函数GenerateNumbers( )随机产生DATA_SIZE个整数,保存在整型数组pnData中,用来分别提供给CPU和GPU计算求和。因为使用同样的数据和同样的计算公式,所以计算结果应该一致。
CPU计算的函数利用循环来实现,通过一个自定义记时类CTimer来记时,单位是ms,直接用printf语句输出时间,代码分析如下:
void sumOfCpu(int *pnData)
{ CTimer cc; long nSum=0; //nSum用来保存计算的和
long tt=cc.getTime (); //tt用来保存时间,先获取当前的时间
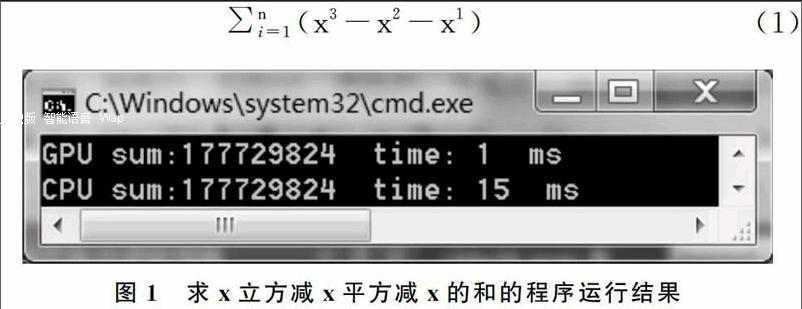
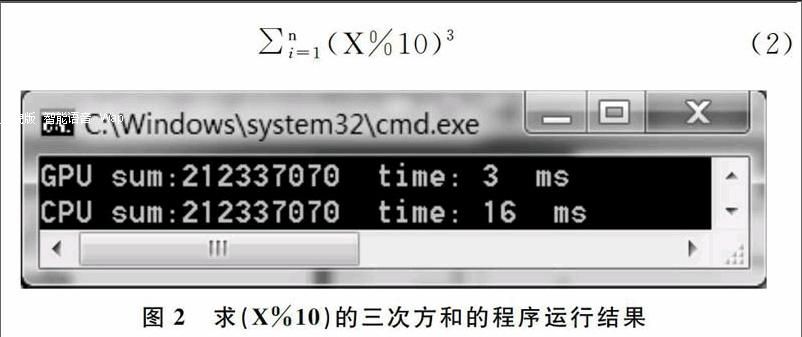
for (int i=0;i { nSum+=(pnData[i]*pnData[i]*pnData[i]-pnData[i]*pnData[i]-pnData[i]; } tt=cc.getTime ()-tt; //计算后的时间减去计算前的时间,得到CPU计算耗时 printf("CPU sum:%d time: %d ms\\n",nSum,tt); } GPU计算的核函数名为sumOfGpu,采用缩减树算法来提高存储器的访问效率。具体代码及分析如下,注意除了循环语句,执行 SumOfGpu( )的每个线程都会执行一次加法运算。 __global__ static void sumOfGpu(int *pnNumber,int * pnResult,clock_t* pclock_tTime) { extern __shared__ int nShared[]; //声明一个动态分配的共享存储器 const int tid=threadIdx.x; //tid中保存线程号 const int bid=blockIdx.x; //bid中保存线程组号 int i; int nOffset=1; //nOffset记录缩减树算法中每轮增倍的步距 if (tid==0) pclock_tTime[bid]=clock(); //获取当前时间并按线程组保存 nShared[tid]=0; //每一个线程组的和都存储在对应下标的共享存储器中 for (i=bid*THREAD_NUM+tid;i __syncthreads(); //线程同步 nOffset=THREAD_NUM/2; //下面用缩减树算法计算共享存储器中元素的和 while (nOffset>0){ if (tid nOffset>>=1; __syncthreads(); } if (tid==0){ //最后用一个线程来相加共享存储器nShared中的数据 pnResult[bid]=nShared[0]; pclock_tTime[bid+BLOCK_NUM]=clock(); }} 主函数main()在CPU中运行,主要完成数据的初始化,调用子函数,并输出结果。CUDA在运行前要分配内存空间,运行结束后要释放这些空间。 int main() { …… //声明变量,分配内存 GenerateNumbers(pnData,DATA_SIZE); //生成原始数据 …… sumOfGpu<< (pnGpuData,pnResult,pclock_tTime); //调用GPU核函数 ……//整理汇总GPU的计算时间pclock_tTime并输出 sumOfCpu(pnData); //调用CPU函数求和并输出 ……//释放内存 } 首先计算一个比较复杂的公式求和,即x的立方减x的平方减x的和,如式(1),其中有立方有平方有减法,代码如上所示。程序运行结果如图1所示,GPU只需要1ms,而CPU需要15ms。 接着将程序进行少量修改,计算第二个公式,即(X%10)的三次方和,即式(2),这里有求模和立方,是比较耗时的计算。程序运行结果如图2所示,GPU的计算时间需要3ms,CPU计算时间则需要16ms。 从上述实例来看,计算同样的公式,NVS 4200M的计算时间都比Core i5-2410M大大减少,其计算能力远超这颗主流的CPU。因此,将CUDA技术用于教学和科研软件的开发,从而提高其计算能力的建议是可行的。 3 应用分析 GPU特别为计算密集、高并行度计算(如图像渲染)而设计,将更多的晶体管用于数据处理而不是数据缓存和流控,因此浮点计算能力很强。具有以下特点的算法能够在GPU上达到很高的执行效率:①每个数据或数据包都需要经过相同的流程来处理;②数据之间没有相干性,即某些数据的计算不依赖于另外一些数据的计算结果;③数据量庞大。 然而,对于程序中逻辑分支较多、数据计算中需要大量缓存,以及并行程度较低、线程较少的计算,并不能体现出GPGPU的优势,不适合用CUDA技术。 4 结语 在3D领域,GPU的用途很简单,就是为了更好地渲染3D场景,减轻CPU在图形运算方面的负担,而GPGPU则将GPU的应用范围扩展到了图形之外。采用CUDA技术编程,利用显示图形卡的GPU运行教学科研软件,可以大大提高软件的计算能力和运行效率。在CPU价格昂贵、大规模并行计算需求旺盛的今天,CUDA是一种好的解决方案,特别适合于投入有限、资金紧张的学校和科研单位。 参考文献: [1] 仇德元. GPGPU编程技术——从GLSL、CUDA到OpenCL[M].北京: 机械工业出版社,2012. [2] 续士强,祝永志. 基于GPU加速的快速字符串匹配算法[J].软件导刊,2015(2):51-53. [3] 郭转转,尹延庆,王佩璐.浅谈CUP并行技术CUDA[J].信息通信,2014(5):103. (责任编辑:孙 娟)
