
适应冷热数据存储的多编码架构的设计与实证
2017-02-27 10:58魏学才宫庆媛沈佳杰周扬帆
计算机应用与软件 2017年2期
魏学才 宫庆媛 沈佳杰 周扬帆 王 新
(复旦大学计算机科学技术学院 上海 201203) (综合业务网理论及关键技术国家重点实验室 陕西 西安 710071) (网络信息安全审计与监控教育部工程研究中心 上海 200433)
适应冷热数据存储的多编码架构的设计与实证
魏学才 宫庆媛 沈佳杰 周扬帆*王 新
(复旦大学计算机科学技术学院 上海 201203) (综合业务网理论及关键技术国家重点实验室 陕西 西安 710071) (网络信息安全审计与监控教育部工程研究中心 上海 200433)
随着互联网技术的发展,数据爆炸性增长,互联网的实际应用也已广泛依赖于海量数据的存储。实际的互联网应用往往需要存储多种类型数据,根据数据被访问频率差异可以将数据划分为冷热数据。然而,现有的编码存储机制往往只能采用固化的实现机制,无法适应多种数据类型的编码存储,导致存储系统性能(如数据访问时间)恶化。考虑到冷热存储数据的不同,提出一种基于多数据编码机制的存储系统框架。对于冷数据,该框架可以采用冗余度较低的编码,从而提高空间利用率;对于热数据,该框架可以采用解码速度较快的编码,从而提高数据访问速度。基于HDFS-RAID设计了这一框架并将之实现为真实系统,实际部署在一个Hadoop集群中。另外基于一个实际系统的用户数据轨迹,在搭建的集群中进行了试验,实验结果表明该框架可以满足不同类型数据同时高效存取的需求,并对编码机制具备高扩展性。
分布式数据存储 HDFS 编码存储
0 引 言
随着互联网应用的兴起及移动智能时代的到来,数据增长的速度越来越快。根据IDC的统计,到2020年全球的数据总量将超过44 ZB[1]。数据量的急剧增加,使得数据存储方式逐渐偏向分布式存储,专用的存储服务器也逐渐被低成本存储设备替代。然而,廉价的存储设备常常因硬件故障、软件升级等导致存储节点宕机、失效,带来了数据存储可靠性的问题。为保证系统中数据的可靠性及可用性,分布式存储系统引入了相应的冗余机制。
目前实际系统中常见的产生数据冗余的方法有副本、纠删码两种。副本方式下,实现副本冗余存储的分布式系统主要有HDFS、GFS、Ceph等[2-4]。
纠删码方式与副本不同,通过对原文件进行分块、编码引入冗余,可在保证同样的存储可靠性的前提下,引入更小的存储空间开销,因而得到了学术界和工业界的广泛关注。纠删码因其在存储效率上的巨大优势,已经应用到了不少实际的分布式存储系统中,例如微软的WAS(Windows Azure Storage)系统[5]、社交网站Facebook的数据存储系统[6,21]、NCCloud系统[7,22]、TFS阿里云[8]等。编码存储的性能、失效数据修复等问题也存在很多的研究工作,针对编码存储的学术研究领域也常常在实际的分布式存储系统上来做性能测试,进行系统级验证,例如NCFS[9]、NCCloud[7]、文献[10]中设计的Raid6文件系统,以及文献[11]中设计的分布式文件系统。
在“互联网+”时代,越来越多的企业需要依赖互联网技术,如云计算,大数据,物联网等来创造更大的企业价值及社会价值。企业的业务运营产生了大量数据,而数据内部往往隐藏着价值,对这些数据的存储及处理便成为了一项基本的任务。针对此任务,在企业内部部署实际的分布式系统便是一个行之有效的应对方案。当前主流的分布式系统,包括实际使用、以及学术研究之用,通常采用一种固定的编码存储方式,便于设计和管理。然而,我们发现,在同一数据中心中通常有多种不同类型的数据,例如,在之前的统计中发现,存储系统中存在有90%的数据为冷数据,通常情况下被访问的频率小于10%;而只有10%的数据为热数据,其被访问的频率大于90%[12]。如何在具有显著差别的冷热数据的情况下,优化存储系统的性能成为了当前研究的热点问题。目前存储系统设计中所采用的单一固定编码模式,造成了无法针对于不同类型的数据进行优化。因此如何设计一个存储系统可以同时支持不同类型的编码(包括副本方式)就成为了一个值得研究的问题。
冷热数据共存是不同存储系统都需要考虑的问题。如Windows Azure Storage采用LRC算法编码不再被更改的数据,不但降低了存储开销,在能耗方面也带来了很多益处[5]。有研究工作尝试使用一种HoVer编码来优化当前系统中编码的更新效率[13]。然而,在一些应用场景中,数据的读取是更频繁的操作,并且存在大量用户同时访问系统的情况。因此如何在大量用户同时访问的情况下,提高分布式存储系统的性能意义重大。
为提高系统的整体性能,应该把不同的数据区别看待,如分类为冷数据和热数据,采用不同的存储机制进行实际存储。本文设计并实现了一种支持多种编码并且允许共存的混合存储框架。通过对于不同类型数据进行不同的处理,本文实现了在保证数据存储效率的前提下提升存储系统的数据读取效率。针对冷热数据存取的问题,本文提出了多重编码混合存储机制,并通过具体的系统试验验证了该存储框架的有效性。
1 分布式存储系统与编码
在存储以及处理PB甚至ZB级别的数据时,现在主流的方式是将数据放在分布式存储系统中,如GFS、Ceph、HDFS等。GFS是由谷歌公司研发的一款可扩展的分布式文件系统,可运行在大量廉价的机器上,专门用于存储海量搜索数据。Ceph是一个PB级的分布式文件系统,可同时支持文件存储,对象存储以及块存储,并具有高并发及高可靠特点。HDFS是Hadoop默认的分布式文件系统,在进行文件访问时具有很高的数据吞吐率。作为一款优秀的开源系统,HDFS在业界得到广泛的部署;在进行分布式存储相关的研究时,Hadoop以及HDFS越来越被广泛地用作研究支撑平台。我们的系统也是基于HDFS进行的设计实现。
1.1 HDFS
HDFS是集成在Hadoop内部的分布式文件系统,目前采用副本的方式来保证数据的可靠性,并且可以达到很高的数据吞吐率。但随着数据规模的扩大,副本方式造成的存储效率问题逐渐引起人们的担忧。所以,可以在HDFS中引入纠删码等编码算法,达到同副本同样可靠性的情况下,可极大减小数据的存储成本。但在目前的HDFS中引入纠删码机制相当困难,因为当初HDFS在设计之初并没有引入纠删码的考虑,这意味着要么重构整个系统框架,要么舍弃部分性能,从HDFS上层入手解决。目前的可用方案有两种:
1) HDFS-RAID
HDFS-RAID[14]本身没有对HDFS做任何修改,只是在HDFS上层设计实现了一套框架,作为中间件,间接地引入纠删码机制。下图是在引入HDFS-RAID以后,用户读取异常数据时的一个详细流程。其中DRFS用来替代原来的用户接口,以便利用纠删码进行数据的恢复。图1中的RaidNode是最主要模块,用来管理文件的编码及修复。

图1 用户读取数据流程
1. Client向DRFS请求读取文件数据;
2. DRFS将读取请求转发给下层的HDFS;
3. HDFS检测到用户读取的数据丢失或出错,抛出异常;
4. DRFS捕获HDFS抛出的异常,并向RaidNode请求对用户正在读取的文件进行临时修复;
5 6 7 8. RaidNode向NameNode请求出错文件的元信息,并从DataNode中读取其他数据进行出错数据的修复;
9. RaidNode将生成的临时文件句柄返回给DRFS;
10. Client继续读取数据,并将数据返回给用户。
目前HDFS-RAID只在内部集成了有限的一种或两种纠删码算法,主要的是RS码。RS码的参数选择很灵活,但在进行数据恢复时会产生较大的带宽开销。用户若想加入新的编码算法,不仅需要修改原有的代码本身,用户承担的工作量也是相当大的,因为要求用户深入了解HDFS-RAID核心部件的内部原理,这对一般研究人员来说尤其困难。另外,HDFS-RAID对于再生码是完全不支持的。
2) HDFS-7285
由于HDFS-RAID本身的一些缺点,如数据的编码以及恢复需要依赖MapReduce,主要适用于冷数据处理等,HDFS-7285[15]方案被提出来。HDFS-7285的作用类似于HDFS-RAID,不过其是从内部修改HDFS原有的结构,使得HDFS内置纠删码的支持。比如原有的NameNode,DataNode等结构都得到扩充,以支持纠删码。但目前还在测试中,部分功能尚未完善;另外,其也没有提供对再生码的支持。
在本文中,为了能够更灵活地支持数据的差异性对待,即支持更多种类的存储机制,我们设计了一套系统框架。该框架基于HDFS-RAID,使得HDFS-RAID不仅能够支持多种编码,并且允许多种编码算法的共存。
1.2 纠删码及再生码
纠删码可以有效减少集群的存储成本,比如系统采用RS(10,4)编码机制后,不仅可以容忍任意4个数据块的丢失,带来的冗余开销也仅为40%(4/10×100%)。目前主流的分布式存储系统中,几乎都引入了纠删码机制。如Google的ColossusFs[23]中引入了RS(Reed-Solomon Code)[16]编码、Microsoft的Azure系统引入了LRC(Local Reconstruction Codes)[5]编码等。
但在数据修复过程中,纠删码会造成较大的带宽开销。比如对于RS(10,4)编码,为了修复一个受损的数据块X,需要在网络中传输10倍于数据块X的数据量。虽然一些编码如LRC对此作了很好的优化,但能够实现修复带宽最小的方法是采用再生码算法。
再生码[17,18]由网路编码启发而来,在数据修复过程中,通过从更多的存活节点中读取数据,来减少需要在网络中传输的数据,从而降低带宽开销。在分布式系统中,带宽是极为珍贵的资源,因此再生码的意义也显得尤为重要。
2 轨迹数据分析及冷热数据
在提出相应系统设计之前,先分析实际系统中数据使用的一些特点。
2.1 轨迹数据
我们分析了由Harvard大学发布的来取自NFS系统的轨迹数据集[19]。此数据集涵盖了多种数据流,如邮件通信、研究交流等,具体包括用户请求及服务器响应等详细信息。整个轨迹数据集历时41天,开始于2003年1月29日,到2003年3月10日结束。每个用户请求信息中,包括时间戳、源、宿IP地址以及RPC方法等信息。根据不同的RPC方法,请求中还可能包括文件句柄,文件偏移位置及长度信息。
2.2 轨迹数据分析
以一周作为粒度(这也是原始数据的存在形式),对每周的数据进行分析。把用户请求中的读请求及写请求作为对文件的一次访问,统计每个文件的一周访问量。由于在原始的数据中,有些时间段并没有达到一周的时间,所以最终我们是以单位小时内文件的访问量来度量文件的热度。结果发现,在一周的时间内,只有不到10%的文件访问量达到热度级别,其中我们定义热数据(文件)为单位小时内的访问量大于100次/小时。
随后分析了热数据以及冷数据在每周的变化趋势。结果如图2、图3所示,我们可以看到在实际系统中数据的冷热往往具有连续性,即热数据往往可以在很长的一段时间内保持较高的被访问频率,而冷数据访问的频率也会长时间保持在较低状态。从图中还可以看出,每周的数据访问频率会有较小幅度的波动,因此可以推断,过去一周的热数据会有较小一部分比例可能转换为冷数据,反之也应成立,但转换比例较前者降低许多。

图2 热数据每周变化趋势

图3 冷数据每周变化趋势
通过轨迹数据的分析可知,在一个分布式存储系统中,冷热数据的比例往往差异很大,如果单单使用一种存储机制,往往会限制系统某方面的表现,如系统的存储空间占用,整体的数据访问吞吐量等。另外,由于冷热数据的变化趋势是连续的,且变化幅度不明显,使得系统可以将过去的文件热度作为参照,预测未来的文件访问热度,以便使用合理的存储方案。
2.3 混合存储机制
在目前的多数分布式存储系统中,一般采用单一的纠删码算法,或者优化修复时间,或者优化存储开销。例如,在Google的ColossusFs,Facebook自身使用的HDFS中,以及一些其他的存储系统[24-25]都选择RS码作为内部的冗余算法。ColossusFs使用的RS码带来的存储成本为1.5X,同时为了修复一个失效数据块,需要读取6个数据块的数据,即需要6倍数据的磁盘I/O及网络传输。在Facebook的HDFS中存储成本为1.4X,但是需要读取10倍的数据来修复一个失效块。其他存储系统中使用的还有LRC码[5-6],但在存储成本与修复代价之间与ColossusFs等系统有类似的一个权衡关系。
如果可以在存储系统中采用两种或多种纠删码算法(包括副本机制),则我们就可以在数据读取时间、修复时间与存储成本以及其他因素之间做一个更好的权衡,提高系统的整体性能。例如,系统可以选择解码时间较快的算法来存储热数据,存储代价较低的算法来存储冷数据,这样就可以在存储成本、数据修复、数据访问时间的等多种因素之间都达到一个较好的效果。
3 系统框架设计
在系统设计上,我们借用了HDFS-RAID的框架结构。HDFS-RAID是基于HDFS的一套框架,在没有修改HDFS的前提下,使用户可以在HDFS中引入纠删码机制。但正如前文所述,HDFS-RAID在编码支持方面存在许多限制,对研究带来了阻碍。我们为了解决这一问题,基于HDFS-RAID设计并实现了一套新的编解码框架,并对HDFS-RAID本身的核心模块做了部分修改,使其不但支持更多种类的编码,包括再生码,并允许多种编码的共存,为不同数据的差异化存储提供了可能性。HDFS-RAID的内部架构如图4所示。在图4中,RaidNode负责文件编码以及恢复的管理工作,具体的操作交由TriggerMonitor及BlockFixer负责。无论编码还是恢复文件,都需要调用框架内部的一个编解码模块Encoder/Decoder。另外,RaidNode还负责编码产生的校验数据的简单维护,如寻址,删除不再被使用的校验数据等,并负责与HDFS通信(实际上是跟NameNode通信),获取文件的相关信息,比如扫描当前的受损文件以便进行修复。

图4 HDFS-RAID架构图
系统设计的框架结构如图5所示。

图5 框架结构图
从图中可以看出,沿用了HDFS-RAID的基本结构。但是为了支持多种编码,对其中的编解码模块做了替换,加入了我们自己设计的编解码模块。图中的Replication代表副本编码方式,用户可以随意设置副本系数;ErasureCodes代表纠删码对应的编解码器,RegeneratingCodes代表再生码对应的编解码器,用户只需实现对应的接口,就可以把自身感兴趣的相关算法集成进系统之中。另外,为了便于用户改变存储机制,对RaidNode和BlockFixer都做了相应的改善及扩充,具体的细节可查看对应的源码及系统文档。
需要指出的是,我们加入了对再生码的支持。因为再生码本身的优势,在存储系统中加入对再生码的支持意义重大。就我们所知,在HDFS中加入对再生码的支持是目前鲜有研究人员涉及的工作。再生码如前文所述,极大优化了数据修复过程,相比于纠删码,引入了更多的幸存节点向替代节点传输数据,实现修复带宽最小化。这也导致再生码数据的存储方式、修复时需要传输的数据生成方式更为复杂。在具体实现的过程中,甚至对底层的HDFS做了相应的扩充,来实现再生码的向量化存储,以及修复时对节点内部数据的预编码。
再生码的编解码模块组成如图6所示,从图6中可以看出,恢复工作是最复杂的一个部分。因为在再生码中,往往存在需要节点内部数据预编码的需求(也是再生码优越的一个所在),而在目前的HDFS以及HDFS-RAID架构中并没有提供这种支持。AdaptiveBlockSreamReader负责如何对失效的文件进行修复,比如从哪些存活节点中读取数据,读取怎样的数据,节点内部的数据是否需要预编码等;NodeReader代表一个参与数据修复的存活节点,在其内部可能维护着数个数据块;EncodedSender负责发送预编码后的数据,这也是对HDFS做的一个扩充。
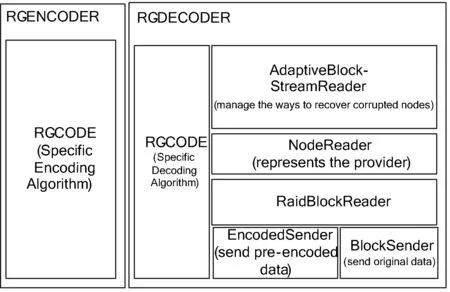
图6 再生码编解码框架图
集成本框架的Hadoop系统支持多种编码的共存,比如对长期访问频率低的数据采用存储码率比较高的编码算法进行编码;对于访问热度很高的文件采用恢复速度较快的编码算法进行编码,或者直接采用副本方式进行存储。为实现这一功能,在框架内对TriggerMonitor及BlockFixer都做了相应程度的修改,改变了其处理文件时的部分流程,方便用户使用。更为主要的是,修改了相关配置文件的格式,使其适用多种编码共存的需求。
总而言之,系统框架主要有三个优点:
1) 多种编码的支持
不仅包括传统的纠删码,我们同时加入了对再生码的支持,另外,我们把副本也作为一种编码方式。
2) 多种编码的共存
本框架允许在系统中同时集成多种编码算法,为差别地处理不同类型的数据建立了基础。
3) 框架的易用性
本框架在设计过程中,考虑到了用户的易用性。在原来的HDFS-RAID中,用户为了在HDFS上研究感兴趣的某种算法,必须对HDFS-RAID做相应的修改,包括核心模块,如RaidNode,BlockFixer等,并且需要重新编译HDFS-RAID。在本框架中,用户只要在相关配置文件中指明使用的编解码器,系统在运行过程中就可以动态加载进来,不需对当前的框架做任何修改。
4 实验结果与分析
我们搭建了一个实际的Hadoop[20]系统,并将本文中设计并实现的框架集成到了系统中。通过相应的实验,来验证混合存储方案对解决冷热数据问题带来哪些性能上的提升。
4.1 系统环境
整个集群共有12台虚拟机器,其中10台作为DataNode。每台机器配置Intel Xeon CPU,单核,主频2.13 GHz;1 GB内存;30 GB硬盘。
每台机器装载Ubuntu 14.04LTS操作系统;Hadoop中附带HDFS-RAID模块,不过被集成进本文实现的框架。实验中,我们同时采用副本和纠删码两种存储机制,其中采用的副本方案为3-副本,纠删码方案为RS(5,3)。之所以采用RS码,在于RS是目前在存储系统中最为广泛使用的一种编码算法;将编码参数设置为(5,3)主要是由于目前集群机器数量的限制。
4.2 实验说明
在具体实验中,将第一周的所有文件按访问热度进行排序,其中前10%的文件定义为热数据,后10%的文件定义为冷数据。在所有的热数据中,访问频度至少可以达到100次/小时;在所有的冷数据中,访问频度平均小于20次/小时。随后我们抽取轨迹数据中每周对应于热数据以及冷数据的访问模式(即访问次数,读取位置及每次的平均访问量),在实际的Hadoop系统中再重现,测得每周的总体访问时间。
将热数据用副本方式进行存储,将冷数据用RS编码进行存储。在访问副本存储的文件时,我们通过调用底层的block相关接口将用户请求均匀地分布到3个副本上,以发挥副本并行读取的优势。在访问RS码存储的文件时,使用同副本方式同样的接口,以避免带来不确定因素,当然,RS编码的文件只有一个原始文件。
根据第2节对轨迹数据的分析,了解到热数据及冷数据在每周的变化趋势并不明显,但会有较小比例的浮动。在实验中我们简单假设上一周的热数据中会有10%转化为冷数据;上一周冷数据中的10%会转化为热数据。之后我们会使用每周的访问模式访问冷热数据得出每周的平均访问时间。
设定HDFS的block大小为64 MB,每个文件大小为320 MB,这主要是为了适应RS码的编码系数;另外,集群总的存储空间限制也是如此设定的一个原因。
由于轨迹数据所在的实际系统的规模可能大于本文实验所使用的集群,为了实验结果的可用性,对轨迹数据中的访问次数进行了相应比例的缩减,大约转化为原来的几十分之一。
在实验时,以轨迹数据中第一周的状态作为实验的初始状态,根据每周的访问模式统计出每周的所有文件平均访问时间以及所有文件的磁盘占用空间。在得出某一周的相关数据后,根据之前的策略将冷数据及热数据进行相应比例的转换,然后进行下一周的实验。对于每周的数据,进行3次实验,然后求取平均值。
4.3 对比实验设计
设定了两组对比实验,用来测定系统在使用单一的存储机制时会带来什么影响。一组将所有的文件看作冷数据,使用RS码进行编码并存储;另一组将所有的文件看作热数据,使用副本方式进行存储。
随后的实验过程与4.2节描述的相同,即利用同样的访问模式统计出每周的平均访问时间及磁盘占用空间。
4.4 实验结果与分析
通过一组原始实验及两组对比实验,我们得出了每周所有文件的平均访问时间,及所有文件的磁盘占用空间。如图7、图8所示。

图7 三组实验比较
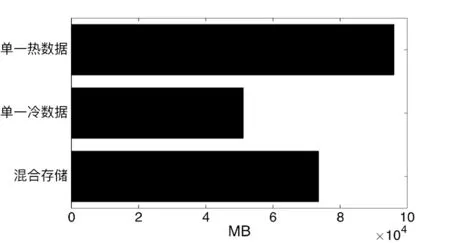
图8 存储空间对比
从图8可以看出,单一热数据机制虽然总体访问时间较低,但所占存储空间却是最大的,为96 000 MB;混合存储机制所占空间为73 600 MB,相对于前者降低了23.3%,由此也可以看出混合存储机制的优势。
由图可以看出以下几个特点:
1) 多数情况下,混合存储的平均访问时间是略大于单一热数据存储机制的。原因有两个,一个在当访问副本机制存储的文件时,可以同时访问多个副本,利用访问的并行性降低总体访问时间;另一个在全部数据中,冷数据占的比例虽然较大,但总的访问量却非常小,因此两种存储机制的差距并没有很明显,甚至有些接近。
2) 单一冷数据机制的访问时间虽然大于单一热数据机制的访问时间,但差别却不明显。我们知道单纯的读取操作是完全可以并发的,如果用户的请求规模没有超过节点的负载能力,那么一个节点无论是处理较多还是较少的用户请求,差别是不明显的。由于本实验中,无论是数据规模还是用户请求规模都没有达到一定的级别,所以出现了这种结果。不过,当用户请求规模达到一定程度,两种存储机制的差距会拉大。
3) 在一些情况下,数据出现了反常,比如第二周的数据。经分析,我们在下载轨迹数据时,对方服务器出现错误,导致若干天的数据丢失,造成一些结果比如访问模式出现误差。
5 结 语
本文通过对冷热数据在实际存储系统中的分析,指出在实际的系统中应该加入对混合存储机制的支持。混合存储机制能够对不同类型的数据差异性处理,比如选择不同的编码算法,适时地切换数据的存储机制等等,能够带来系统在存储效率、响应时间等指标上的显著提升。我们基于HDFS设计并实现了一套支持多种编码算法,并允许多编码共存的系统框架,通过实验验证了系统框架的可用性,及混合存储机制在存储效率、数据访问时间等方面对系统性能的提升。本文工作并没有对我们实现的系统框架做非常深入的使用,下一步计划中,准备基于本框架对混合存储机制在实际系统中的应用做更进一步的研究,比如编码算法的选择、不同编码之间切换的开销等等。
[1] Gantz J,Reinsel D.Extracting value from chaos state of the universe:an executive summary[R].IDC iView,2011:1-12.
[2] Shvachko K,Kuang H,Radia S,et al.The Hadoop distributed file system[C]//2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST).IEEE Computer Society,2010:1-10.
[3] Ghemawat S,Gobioff H,Leung S T.The Google file system[J].ACM SIGOPS Operating Systems Review,2003,37(5):29-43.
[4] Weil S A,Brandt S A,Miller E L,et al.Ceph:a scalable,high-performance distributed file system[C]//Proceedings of the 7th Symposium on Operating Systems Design and Implementation,Seattle,WA,USA.USENIX Association,2006:307-320.
[5] Huang C,Simitci H,Xu Y,et al.Erasure coding in Windows Azure storage[C]//2012 USENIX Annual Technical Conference,2012:15-26.
[6] Sathiamoorthy M,Asteris M,Papailiopoulos D,et al.XORing elephants: novel erasure codes for big data[J].Proceedings of the VLDB Endowment,2013,6(5):325-336.
[7] Hu Y,Chen H C H,Lee P P C,et al.NCCloud:applying network coding for the storage repair in a cloud-of-clouds[C]//Proceedings of the 10th USENIX Conference on File and Storage Technologies (FAST 12),2012:21.
[8] TFS Erasure code实现方案[EB/OL].(2014-04-16).[2015-12-09].http://blog.chinaunix.net/uid-20196318-id-4212712.html.
[9] Hu Y,Yu C M,Li Y K,et al.NCFS:on the practicality and extensibility of a network-coding-based distributed file system[C]//Network Coding (NetCod),2011 International Symposium on.IEEE,2011:1-6.
[10] 卫东升.一种修复优化的Raid6文件系统的设计与实现[D].上海:复旦大学,2015.
[11] 权恒星.基于SDN的分布式文件系统设计与实现[D].上海:复旦大学,2015.
[12] Hafner J L.HoVer erasure codes for disk arrays[C]//Dependable Systems and Networks,2006 International Conference on.IEEE,2006:217-226.
[13] Xia M,Saxena M,Blaum M,et al.A tale of two erasure codes in HDFS[C]//Proceedings of the 13th USENIX Conference on File and Storage Technologies (FAST 15),2015:213-226.
[14] Hadoop Wiki.HDFS RAID[OL].(2011-11-02).[2015-12-09].http://wiki.apache.org/hadoop/HDFS-RAID.
[15] The Apache Software Foundation.Erasure coding support inside HDFS[OL].(2015-09-30).[2015-12-09].https://issues.apache.org/jira/browse/HDFS-7285.
[16] Reed I S,Solomon G.Polynomial codes over certain finite fields[J].Journal of the Society for Industrial and Applied Mathematics,1960,8(2):300-304.
[17] Dimakis A G,Godfrey P B,Wu Y,et al.Network coding for distributed storage systems[J].IEEE Transactions on Information Theory,2010,56(9):4539-4551.
[18] Dimakis A G,Ramchandran K,Wu Y,et al.A survey on network codes for distributed storage[J].Proceedings of the IEEE,2011,99(3):476-489.
[19] Ellard D J.Trace-based analyses and optimizations for network storage servers[D].Cambridge,MA,USA:Harvard University,2004.
[20] The Apache Software Foundation.Welcome to Apache Hadoop[OL].(2015-10-30).[2015-12-09].http://hadoop.apache.org.
[21] Rashmi K V,Shah N B,Gu D,et al.A solution to the network challenges of data recovery in erasure-coded distributed storage systems:a study on the Facebook warehouse cluster[C]//Proceedings of the 5th USENIX Conference on Hot Topics in Storage and File Systems,2013:8.
[22] Hu Y,Lee P P C,Shum K W.Analysis and construction of functional regenerating codes with uncoded repair for distributed storage systems[C]//2013 IEEE International Conference on Computer Communications.IEEE,2013:2355-2363.
[23] Fikes A.Storage architecture and challenges[DB/OL].(2010-07-29).[2015-12-09].http://static.googlecontent.com/media/research.google.com/zh-CN//university/relations/facultysummit2010/storage_architecture_and_challenges.pdf.
[24] Khan O,Burns R,Plank J,et al.Rethinking erasure codes for cloud file systems:minimizing I/O for recovery and degraded reads[C]//Proceedings of the 10th USENIX Conference on File and Storage Technologies (FAST 12),2012:20.
[25] Rashmi K V,Shan N B,Gu D,et al.A “hitchhiker′s” guide to fast and efficient data reconstruction in erasure-coded data centers[J].ACM SIGCOMM Computer Communication Review,2014,44(4):331-342.
DESIGN AND DEMONSTRATION OF MULTI-CODES FRAMEWORK FOR COLD/HOT DATA STORAGE
Wei Xuecai Gong Qingyuan Shen Jiajie Zhou Yangfan*Wang Xin
(SchoolofComputerScience,FudanUniversity,Shanghai201203,China) (StateKeyLaboratoryofIntegratedServicesNetworks,Xi’an710071,Shaanxi,China) (EngineeringResearchCenterofCyberSecurityAuditingandMonitoring,MinistryofEducation,Shanghai200433,China)
With the rapid development of the Internet and the explosive growth of data, large-scale distributed storage systems are widely used in Internet application. Recent Internet applications usually involve different types of data, and data can be considered as hot data or cold data based on their access frequency. However, a storage system with erasure codes is generally implemented with a fixed coding mechanism, which cannot adapt well to the diverse types of data coexisting in the same system. As a result, the system performance may greatly degrade. Thus, a new storage system framework is suggested to improve the system performance based on multiple codes, considering the difference between hot and cold data. For cold data, it can adopt a low-redundancy coding mechanism to improve space efficiency. For hot data, in contrast, it can reduce the data access time by taking a code that can be rapidly decoded. Then, real-world implementations of such a framework based on HDFS-RAID are designed, which is deployed in a Hadoop tested cluster. Besides, based on a real-world data access trace, the effectiveness of our system in improving the system performance is verified. The results show that the system can adapt well to the diverse types of data.
Distributed data storage HDFS Encoding storage
2016-01-20。国家自然科学基金项目(61571136);上海市“科技创新行动计划”项目(14511101000);综合业务网理论及关键技术国家重点实验室开放研究课题(ISN15-08)。魏学才,硕士生,主研领域:分布式存储系统中的冗余修复。宫庆媛,博士生。沈佳杰,博士生。周扬帆,副研究员。王新,教授。
TP3
A
10.3969/j.issn.1000-386x.2017.02.006
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
小资CHIC!ELEGANCE(2022年1期)2022-01-11
数学物理学报(2021年1期)2021-03-29
哈尔滨轴承(2020年2期)2020-11-06
网络安全和信息化(2019年8期)2019-08-28
计算机系统应用(2019年2期)2019-04-10
发明与创新·大科技(2019年12期)2019-03-17
小型微型计算机系统(2018年3期)2018-03-27
燕山大学学报(2015年4期)2015-12-25
中国教育信息化(2015年12期)2015-08-24
