
一种基于分组的混合查询防碰撞算法
2017-03-15 16:50董昌熊卫华
物联网技术 2017年2期
关键词:射频识别
董昌+熊卫华

摘 要:传统的射频识别防碰撞算法查询次数多、数据传输量大,而一般的混合查询树算法会产生大量的查询前缀和空闲时隙。因此,文中针对这些问题提出了基于分组的混合查询树法。该方法先对标签预处理组成一个新标签,然后将标签二次分组与改进的HQT算法结合使用,通过不断使用异或分组结合碰撞位前2位组合信息对标签进行处理。实验表明,此举减少了标签的查询前缀、空闲时隙和传输数据,从而提高了系统的工作效率。
关键词:射频识别;防碰撞;标签预处理;异或分组;改进HQT算法
中图分类号:TP301.6 文献标识码:A 文章编号:2095-1302(2017)02-00-04
0 引 言
无线射频识别技术(Radio Frequency Identification,RFID)[1]作为物联网应用系统的核心技术,对推动物联网的发展起着不可估量的作用。它利用射频信号的电磁(电感)耦合原理进行目标自动识别,已广泛应用于物流、资产管理、军事、交通以及医疗等领域[2]。RFID系统主要由电子阅读器、标签、RFID应用系统3部分组成。阅读器主要负责与电子标签的双向通信,同时还会受到主机系统的控制。电子标签是射频识别系统真正的数据载体。应用系统是RFID的系统软件或者服务程序,也是整个RFID系统的后台系统[3]。在RFID中,数据的完整性和正确性决定了整个系统是否可行。但应用上时常面临多个标签、多个阅读器相互干扰的问题,这使得阅读器不能正确或者完全识别阅读范围内的所有电子标签。因此可通过改进信道传输的数据算法来解决此问题,而防碰撞算法也由此而来。
如今最基本的4种通信防碰撞算法有空分多址(SDMA)法、频分多址(FDMA)法、码分多址(CDMA)法和时分多址(TDMA)法。在RFID中主流的防碰撞算法主要分为以下2大类:
(1)基于TDMA思想的非确定性ALOHA算法。该算法又分为纯ALOHA算法(存在严重的错判问题)、时隙ALOHA算法(将ALOHA算法中时间分成多个离散的时隙)、帧时隙ALOHA算法(将多个时隙组成一帧,标签在每个帧内随机选择一个时隙)等算法。
(2)基于轮询的按照树模型搜索确定性算法[4]。该方法包括二进制防碰撞算法、查询树(Query Tree,QT)算法[5-7]等多种基于树的图形算法。
当存在大量碰撞标签,并在碰撞位较多时直接使用QT算法,但该算法的查询前缀较多且存在大量的空闲时隙。而一般混合算法的查询次数过多[8]。本文采用分组思想结合HQT算法提出了一种基于分组的混合查询树算法,以减少大量的查询前缀并在一定程度上减少空闲时隙和数据的查询量,大大提高了工作效率。
1 基本的确定性算法
1.1 曼切斯特编码
编码即用不同形式的码型来表示“1”和“0”。RFID系统常用的编码方式有差分双相(DBP)码、密勒(Miller)码、曼切斯特(Manchester)码等。其中,曼切斯特码是最常用的编码方式,它采用电平的上升、下降沿来表示逻辑“0”和“1”。从低电平到高电平的上升沿跳变表示逻辑“0”,反之表示逻辑“1”。当阅读器同时接收到不同的逻辑“1”和“0”时,则无法识别该位置的信息产生碰撞,而曼切斯特码能够以此确定该位是碰撞位。因为需要准确检测出碰撞位,所以采用曼切斯特编码方式。分别有2个标签Tag1(10010)和Tag2(00111)处于阅读器的识别范围内,当Tag1、Tag2同时发送ID信息给阅读器时,阅读器接收到的信号是 “X0X1X”(X表示碰撞位)。图1所示为上述标签的曼切斯特编码响应过程。
1.2 查询树算法
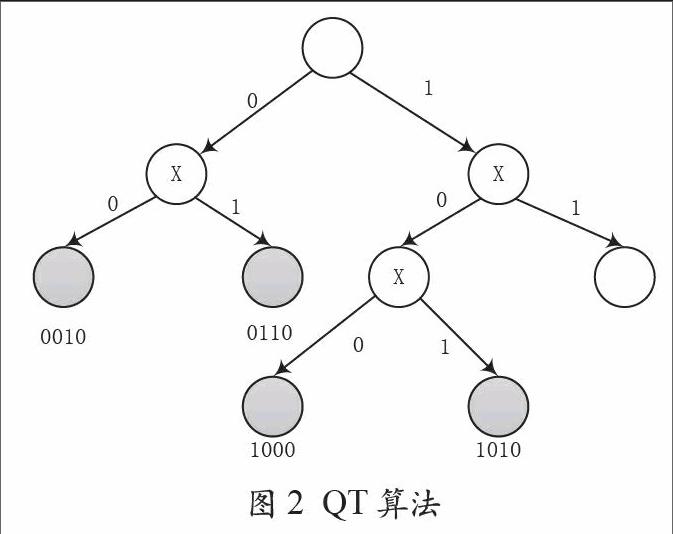
查询树(Query Tree,QT)算法是一种常见典型的树结构算法。在算法中需要开辟堆栈保存阅读器的数据。开辟一个栈data用来保存阅读器的查询前缀,每次阅读器都将长度为K的前缀数据发送给标签,n位标签的前K位与前缀相同则响应,标签将剩下的n-k位发送给阅读器。阅读器接收到的标签继续碰撞时后面用二进制搜索查询法进行识别。例如有四个标签分别为0010、1001、0101、0110,图2所示为QT算法的查询树结构。
1.3 HQT算法
由于QT算法是在二进制算法的基础上进行改进,而且还要扩展前缀,因此会产生一些没用的前缀信号,增加了系统的通信量,延长了通讯时间。为此提出了一种HQT算法,它由原来的扩展一位增加到三位,同时引入了时隙延长机制。当符合前缀的电子标签并不立即响应时,通过计算标签前缀后三位中“1”的个数来决定延长的时隙数[9,10]。先设电子标签的ID长度为n,用P表示首位碰撞位,K表示发送前缀的位数,用slotn表示时隙数。那么标签的计算思想为:
(1)先用QT算法判断阅读器发送的前缀与标签ID的前k位是否匹配,若不同不响应,相同则进行下一步:
(2)计算p到p+2位中“1”的个数;
(3)“1”的个数与slotn相同时电子标签才响应;
(4)将查询前缀后所有的n-p+1位信息发送给阅读器。
阅读器端口进行的算法如下:
(1)阅读器将查询前缀K发给标签并实时更新查询栈;
(2)通过接收标签发送的最高碰撞位的后三位判断slotn是否碰撞,若无则进行(4);
(3)上一步有碰撞则在上次查询前缀的基础上扩充一位 “0”或“1”添入查询栈data的末尾,返回(2);
(4)在同一个slotn内若无碰撞发生,则说明只有一個标签,可以直接识别。
2 改进算法的具体描述
2.1 算法改进思想
通过分析QT算法和HQT算法得出,在QT算法过程中会产生大量无用的前缀,HQT算法会产生大量的空闲时隙。
分组混合算法约定:
(1)在阅读器范围内每个电子标签的ID唯一。
(2) 每个电子标签应含有一个响应计数器C和2个寄存器,分别为R和G。C用来存储等待的时隙数,R和G用于保存分组标号。
(3)每个电子标签中都有一个静默计数器N,N=0时处于激活状态,接收阅读器的信号;N>0时为失活状态,对阅读器不反映;N<0时处于无声状态。
本文先将标签所有的碰撞位提取出来组成一个新的标签NEW ID,根据新标签中“1”的奇偶个数进行分组。定义标签的长度为n,任意连续的3个标签位为Wn、Wn+1、Wn+2,定义符号☉为异或运算符,如果符合式(1),则Wn、Wn+1、Wn+2为第0组,表示G=0;如果符合式(2),则Wn、Wn+1、Wn+2为第1组,表示G=1。若G=0,从Wn到Wn+2最多有000、011、101、110四种形式。此时若有两位碰撞位则可以直接识别出标签,若有3位碰撞位则将前2位用十进制表示,并分别存入延迟寄存器C中。
2.2 分组混合算法的基本步骤
2.2.1 标签端
(1)接收“#”,所有的电子标签都发送自己的ID;
(2)接收到阅读器识别出来的碰撞位,标签将碰撞位按顺序组成一个新的标签ID;
(3)接收前缀,根据阅读器第一次发送“0”与标签中R是否相等响应可知,若不等,则标签静默,此时N=1, 直到阅读器发送“1”才被激活,否则继续;
(4)对标签的前3位进行异或分组处理,将相应的标签计数器G置“0”或“1”;
(5)若没响应则为空时隙,查看堆栈Q是否为空,否则返回标签最高碰撞位之后的信息给阅读器。
(6)标签的最高碰撞位开始的2位用十进制表示,存入计数器C中。这里C=0、1、2、3、4;
(7)当C=slot时响应;
(8)将碰撞信息(K+1)到n位发送给阅读器。
2.2.2 阅读器端
在问询阶段,从查询队列Q中取队首元素,发送给所有的标签。查询队列Q的初始值为{#、0、1},且得出的数值都按次序置于“1”之前,直到发送“1”之后Q的值才添加到队尾,每次发送查询码后都将其删除。Request(Q,G)则表示Q为查询前缀,G为组号的标签处于激活状态。
阅读器端的具体工作流程如下:
(1)阅读器发送“#”,令所有标签都响应;
(2)阅读器的堆栈队列Q不为空时,读取并删除Q中的队首元素;
(3)发送队首前缀Prefix给标签;
(4)根据标签的前3位发送异或分组命令Request(G);
(5)阅读器发送Request(Q,G)令分组号相同的标签都响应,同时清空标签中G的值;
(6)若前3位中有两个碰撞位,则根据异或分组原理可以直接识别前3位,将识别出的前3位作为前缀Prefix放入Q中置于队尾。转向步骤(5);
(7)当前slot与收到的前2位信息是否有碰撞发生扩展,查询前缀Q,没有则跳转到(9),否则继续;
(8)查询阅读器是否发送“1”,有则下次将前缀Prefix放于队尾,否则置于“1”前;
(9)继续扫描收到的信息,没有发生碰撞则转移到(11),否则继续;
(10)对同个slot时隙的碰撞标签根据连续的前3位转到步骤(5);
(11)识别该标签。
标签识别最后只可能出现碰撞位为2或3的情况,2位则直接识别,3位则通过再次异或分组后识别。
假设有16个8位的待识别标签tag1~tag16,依次为10101010、00110100、10011110、00100010、10011100、00010010、00101100、10110110、10000010、00001000、10010110、10100110、00111110、00000100、00000010、00110010。
(1)阅读器发送Request(#),此时Q={0、1,G},阅读器统计碰撞位并向标签发送碰撞位信息,标签内部提取碰撞位,组成一个新的标签;
(2)阅读器返回的碰撞位信息为X0XXXXX0,则组成的新标签见表1所列。
(3)对将要识别的16个标签进行第一次分组,统计“1”的奇偶个数。奇数时R=1,偶数时R=0,计入标签内部计数器。标签的奇偶分组见表2所列;
(4)以第三步中R=0的标签前3位进行异或分组,相应的置内部存储器G为0、1,此时G={1,0}。标签的异或分组见表3所列;
(5)经分析R=0且G=0标签的前2位可知,C分别为3、2、2,可直接识别出110101;
(6)被识别标签静默,101110、101011标签发生碰撞,101作为前缀发送给阅读器;
(7)符合前缀的标签进行异或分组后在同一组且有2个碰撞位可以直接识别;
(8)同(5),对R=0,G=1的标签的前2位分析可直接识别出所有的标签;
(9)对R=1,G=0和R=1,G=1的组经(5)~(8)可以正确识别;
(10)堆栈队列Q为空,标签识别完后结束。
算法流程如图3所示。
3 算法仿真结果及分析
上述算法通过分组后发送组号作为每一轮的开始,在本次识别过程中,阅读器的次数为堆栈Q中的查询次数,传输数据量与查询次数及识别时间成正比。一般产生空闲时隙也会影响识别速度。就查询次数与识别效率进行对比。
使用Matlab軟件对其仿真。先假设标签均在可读取范围内,其ID长度为96 b且随机生成一定的标签。设系统的通信速率为100 b/s,标签响应时长和单一时隙为20 μs。我们在实验中对QT、HQT和分组混合算法进行比较。
分组混合算法在每次分组识别前,先对标签进行一次预处理,要求标签将自己的碰撞位提取组成一个新的ID。仅对此过程分析可知,会增加系统的数据传输,具体如下所示:
式中,K为增加的传输数据量,n为标签个数,l为标签长度。只有标签每位都发生碰撞时等号才会成立。但对整个识别过程来说可大大减少问询数目和碰撞数。
将由图4所示的本文算法与QT和HQT算法所产生的空闲时隙进行对比可得出,QT算法的空闲时隙为0;HQT算法在一般情况下引入的时隙数为4。而本文通过标签的处理可以减少空闲时隙,相比HQT算法,该算法不会随标签数的增加而急剧增加空闲时隙,起到了一定的改善作用。
图5所示为查询前缀的个数。可以看出相对于QT和HQT算法,本算法能够大大减少查询前缀。随着标签数的增多,因QT算法没有经过处理,因此前缀数目随着标签的增多,其长度变化迅速增加。本文算法可以明显看出前缀数增加的速度最为缓慢。
4 结 语
本文通过对QT算法标签、分组查询树算法的分析,经过大量实验并仿真后,在对比QT、HQT算法的基础上提出了二次分组的混合查询树法。本算法在最初情况下首先引入预处理以减少查询前缀。通过第一次的奇偶分组和第二次的异或分组并通过采用“时隙延迟机制”计算碰撞位前2位化为十进制的结果作为延时时隙。通过将异或分组和HQT算法结合可以有效减少空隙时隙。仿真结果表明,该算法在空闲时隙和查询前缀上有了一定的改进,提高了RFID系统的识别效率。
参考文献
[1] Shepard S.RFID:radio frequency identification[M].New York:McGraw Hill,2005:55-61.
[2]郭建华,杨海东,邓飞其.基于免疫网络的RFID入侵检测模型研究[J].计算机应用,2008,28(10):2481-2484.
[3]康东,石喜勤,李勇鹏,等.射频识别(RFID)核心技术與典型应用开发案例[M].北京:人民邮电出版社,2008.
[4]姜丽芬,卢桂章,辛运帷.射频识别系统中的防碰撞算法研究[J].计算机工程与应用,2007,43(15):29-32.
[5] Wang T.Enhanced binary search with cut-through operation for anti-collision in RFID systems[J].IEEE Communications Letters,2006,10(4):236-238.
[6]单承赣,张琦,焦宗东.RFID系统中的跳跃式类二进制搜索法[J].射频世界,2007,23(5):27-30.
[7]姜武,杨恒新,张昀.一种改进的查询树RFID标签防碰撞算法[J].计算机技术与发展,2015(2):86-89.
[8]付钰,钱志鸿,程超,等.基于分组机制的位仲裁查询树防碰撞算法[J].通信学报,2016,37(1):123-129.
[9]周清,蔡明.改进的RFID混合查询树防碰撞算法[J].计算机工程与设计,2012,33(1):209-213.
[10]曹洁,窦聪.一种改进的混合查询树防碰撞算法[J].小型微型计算机系统,2015,36(2):322-326.
猜你喜欢
