
基于Hadoop下利用Hive进行网络日志存储和分析
2017-03-15 11:51杨丕仁
电子技术与软件工程 2017年2期
关键词:大数据
摘 要 随着网络应用的普及和网络的深入发展,网络上传输的数据量越来越大,在网络安全管理方面要求越来越严格,如何有效的存储、查询、分析海量的网络日志就成了网络安全管理方面的新挑战。云计算技术的完善和普及,为解决这类问题提供了新的方法,云计算机就是通过网络系统将多台计算机组成一个分布式系统,从而完成海量数据的存储和计算。Hadoop是一个用于构建云计算机平台的开源系统,为了存储和分析这些海量的数据,可以利用Hadoop分布系统下对网络日志的存储、查询、分析,通过该系统的应用可以节约存储成本、提高查询效率,为网络的安全管理、网络优化提供数据支持。
【关键词】Hadoop 大数据 Hive
1 引言
随着网络应用的深度普及,人们在学习、工作、生活越来越离不开网络,所以在网络的运行过程中,会产生海量的网络日志,如何通过海量的日志,来分析用用户上网行的特点,为校园网络的优化、网络安全、提供科学决策的依据,我们首先要解决的问题是如何存存储、查询、分析这些大数,如果用传统的单一节点的计算机能力来处理这些海量的数据已经不能满足需求。利用云计算技术,通过一定的算法,可以把这些大数据进进行清洗、存储、分析,为校园网络安全运行提供数据支持,本文通过Hadoop系统,实现了基于Hive数据仓库的网络日志行为的存储和分析。
2 主要相关技术
2.1 hadoop系统
Hadoop是应用于大规模数据的开发和运行处理的软件平台,是Appach的一个用java语言实现开源软件框架,实现了在大量计算机组成的集群中对海量数据进行分布式计算,Hadoop框架中最核心设计就是:HDFS和MapReduce,HDFS提供了海量数据的存储,MapReduce提供了对数据的计算。
2.2 Hive数据仓库
Hive是运行于Hadoop下的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。Hive 的本质是将SQL转换为MapReduce程序,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行。并按照该计划生成MapReduce任务后交给Hadoop集群处理,Hive的体系结构可以分为以下部分:
(1)用户接口,Hive主要有三个用户接口,分别为:命令接品(CLI)、Jdbc/Odbc接口、WEB接口。
(2)Hive将元数据存储在数据库中,如mysql, Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
(3)解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
(4)Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成, Hive将元数据存储在RDBMS中。
3 存储和分析网络日志
3.1 利用hive存储网络日志
3.1.1 数据采集及格式
测试的数据来源于校园网络用户上网行为记录的日志,该日的特点是实时记录了认证用户访问网络的行为,记录数据量非常大,每天将近有30G,每条记录包含如下信息:流水号、访问时间、访问的目标url或IP、登录账号、源MAC、源IP、目标端口、访问类型、访问目标IP、源端口,其格式为TXT文件,日志记录的信息可以分析校园网络的运行情况、用户上网行为特点及网络舆情的监控。
3.1.2 数据的存储
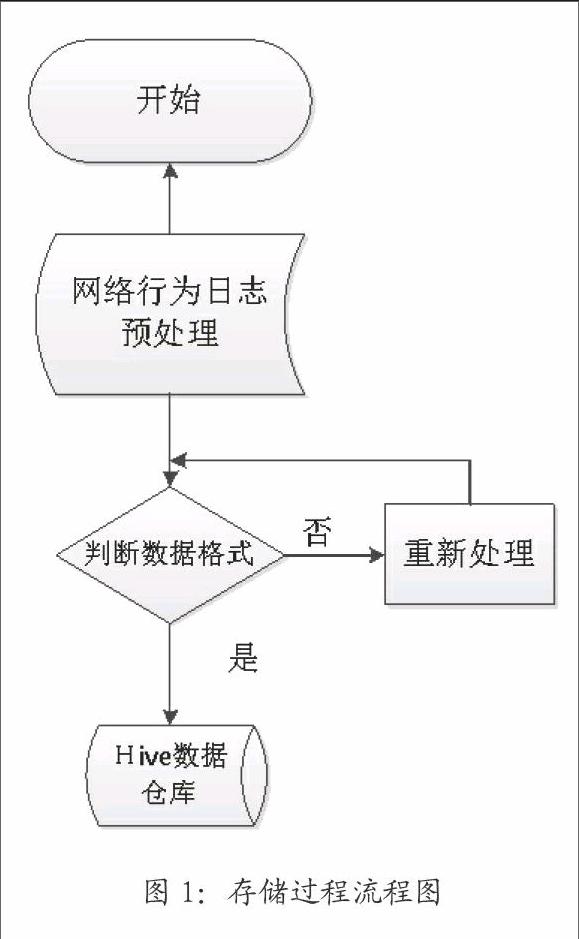
用户在校园网络上每一个动作都会产生一条记录,所以经过长时间的网络运行,这些海量的数据查詢存储就成为一个必须解决的问题,如果用传统的数据库如:MSsql、mysql、orc等,就显得力不从心.如果这些数据不加以分析利用,就失去了它的价值,根据Hive的特点,可以将网络日志存储在Hive数据仓库中,利用Hadoop分布式计算提高数据的运算速度,其存储的过程设计如图1所示。
整个流程的工作过程:
(1)原始记录获取,可以通过网关设备或认证服务器获取原始数据,在原始的数据中包含了许多干扰的数据,所以必须对数据进行处理。
(2)数据清洗,我们可以利简单的python脚本语言进行数据的清洗,提取对我们分析数据有用的信息,如用户账号、登时间、注销时间、在线时长、源IP地址、源MAC地址、目标IP、访问类型等,经过清洗的数据大小只是原来的二分之一,把原始数据分别存为两个hive能够导入的TXT文件,这两个文件分别存有用户登陆校园网络的信息和用户访问网络行为记录。
(3)建立hive数据仓库,可以使用hive提供的CLI接口,编写相应的shell脚本进行批量的导入,也可以使用hive提供的API接口,通过编写程序进行导入,其实现如下:
方法一、选择最简单的CLI接口,首选在Linux 创建如下脚本:
#!/bin/bash
hive< create external tableuserlog(id string) row format delimited fields terminated by'\t' lines terminated by'\n' stored as textfile; load data local inpath'/home/hadoop/hd/test*.txt' into table test_1; EOF 以上的shell脚本功能实现了在hive上创建用户登陆网络信息记录表,并把相应的记录文件导入到hive数据仓库中,我可以应用相同的方法在hive中创网络用户行为记录user_activit表。
方法二,可以用编写程序的方式实现,例如用python程序实现的操作。
以上两种方法的最终目的是把数据存储到hive数据仓库中,通过比较方法一操作简单执行效率高。
3.2 利用Hive数据仓库进行网络日志的分析
Hive数据仓库的特点是基于hadoop系统之上的数据库,并将SQL转换为MapReduce程序,hive不适合用于联机online事务处理,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业,所以可以用hive来分析大数据,在校园网络环境中,由于长时间的运行,产生了大量的日志,如果我们用传统的数据库工具只能存储部分数据,对于分析网络的运行情况及关键数据的查寻就会变得非常困难和耗时。所以我可以利用hive数据工具对网络行为的分析,在hive中提供了类似sql的操作。
3.2.1 在网络安全管理中查询
在网络安全分析中我们可以利用Hive的SQL语句进行查询,例如某个网址或IP地址是否被学生大量访问,我们要及时了解学生的思想状况及形为表现,就可以利用hive查询分析大量的网络日志并对其进行思想教育,或者我们查询非法IP地址在一个星期内被访问的情况,可以在hive的CL下输入语句:selecuserId,usertim,fromuserlog where ip=“a.b.c.d”and usetime=”x”就可以查询到我们想要的结果。
3.2.2 在网络带宽的优化
为了提高网络的服务质量,我们可以从网络日志中,通过hive的内置窗口函数进行分区排序、动态Group by、Top N 、累计计算、层次查询,可以统计和分析某段时间内被大量访问的目标地址和提供的服服类型,例如视频服务网站,我们就可通增加缓存服务器,提高访问速度,减轻出口带宽的压力。
3.2.3 为进一步数据挖掘提供数据
在hive中内置了大量的分析函数,可以根据需要的数据内容来选择相应的操作,为我们数据深度分析面提供有用的数据,例如可以通行列转的函数得到某个用户一分钟内访问网址的记录,为下一步运用mouht进行用户行为深度分析分析提供准确的数据。
3.3 实验环境搭建
为了验证Hive数据仓库的可行性,所搭建的实验环境为:
(1)硬件环境:CPU: 四个Intel 8核Xeon E7-4820处理器,内存128G,硬盘空间3T。
(2)虚拟机系统:基于VMWare ESXI5.0 创建5台虚拟,每台的配置为:2个双核CPU,8G内存,60G硬盘,ubuntu14.04操作系统。
(3)Hadoop/hive集群:5台虚拟机都安装Hadoop2.6.0,其中的一台用来作为HDFS的名称节点,并安装Hive-1.2.1,其余4台作为数据节点。
3.3.1 数据的存储验证
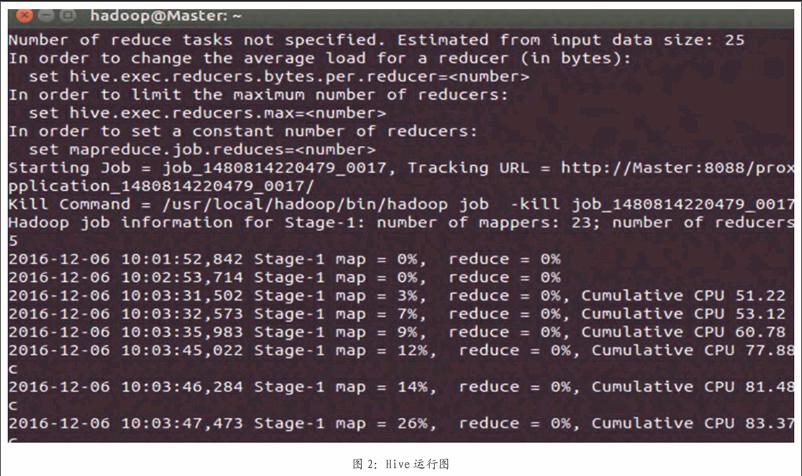
在Hadoop集群的主节点下利用Hive提供的CLI接口,将网络用户一个星期的日志导入到Hive数据仓库中,经过验证在hive 数据仓库中的数据匀可以正常操作,如图2运行。
通过图2所示,Hive 能在hadoop中把SQL命令解析为并生23个Map和25个Reduce任务后交给Hadoop集群处理,所以经过验证,利用Hive 存储网络用户日志的方案是可行的。
3.3.2 數据的分析验证
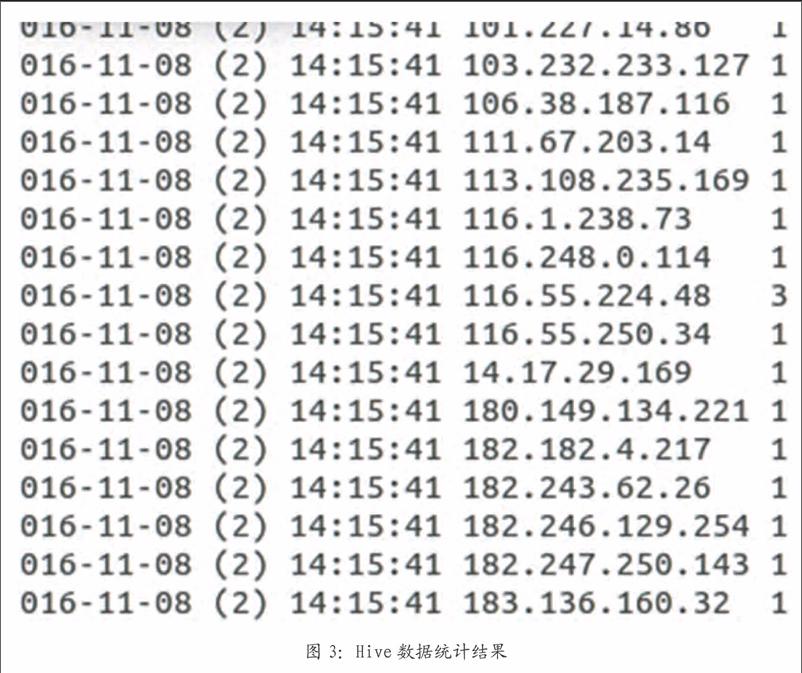
在hive中统计每天点击率最高的网站,可以在hive的命令接口中输入如下的命令:
Select usetime,usIP,count(*),C from userlog group by usetimeusIP>>dt.txt
以上命令执行后会生成一个结果文件,如图3所示。
用以上的分析方法分别对不同大小的数据进行验证,图4是运行时间对比。
从以上结果可以看出,hive 对小文件操作时,延时性比较大,但是对大文件的作操作时,他的优势就发挥出来。
4 结语
本文结合具体的实例,运用Hadoop系统下的Hive数据仓库进行存储校园网络用户上网行为的大量日志,通过验证Hive 数据仓库可以应用于校园网络数据非时实交互的应用环境,并且利用hive 分析数据,可以省设计程序代码的复杂的工作,提高我们分数据的效率,能够从大量的网络日志中取有用的数据,使其成为学校贵的数字资产。
参考文献
[1]林和,安王强.云计算与云计算[EB/OL]ttp://www.linkwan.com/gb/tech/htm/1490.htm,2011.
[2]吴朝晖,陈华钧.空间大数据信息基础设施[M].浙江:浙江大学出版社,2013(01):38.
[3]陆嘉恒.Hadoop实战[M].北京:机械工业出版社,2012(11):2.
[4]张良均,樊哲.Hadoop大数据分析与挖掘实战[M].北京:机械工业出版社,2015(12):34.
作者简介
杨丕仁(1979-),男,云南省云县人。现工作于大理大学现代教育技术中心,实验师、硕士。主要研究方向为网络安全与管理。
作者单位
大理大学现代教育技术中 心云南省大理白族自治州大理市 671003
