
并发业务系统的实现
2017-03-15 12:11夏雨朱信忠徐慧英顾雅丽卢
电子技术与软件工程 2017年2期
夏雨++朱信忠++徐慧英++顾雅丽++卢山富
摘 要 随着互联网技术突飞猛进的发展,网站规模的不断扩大,数据量的增加,大数据的时代已经真正到来,性能和安全的问题也日益突出,很多技术被提出,并且用来提升网络以及服务器的性能和安全,各种各样的架构也应运而生,如何在高并發,高性能之中寻找一个平衡点,已经成为亟需解决的问题,很多人可能知道应对高并发要用分布式缓存,要用分布式和负载均衡。但为什么要这么用,怎么用才能用好,怎样根据实际需求设计最适合的架构完全不懂。本文基于.net平台,提出了并设计了支持.Net平台的千万级规模分布式高性能高并发WEB软件开发架构设计方案。
【关键词】互联网技术 并发业务系统 方案设计
1 系统产生并发的业务节点
并发产生的原因:
(1)短时间大量请求竞争低速存储设备或者竞争处理器资源。
(2)不合理的程序处理逻辑导致请求无法尽快完成。
(3)其他瓶颈,如带宽、服务器资源等。
2 应对并发的解决方案
2.1 针对并发量不高的情况的方案——分库分表,实质上是分布式系统的一种模式
具体逻辑如下:
将原本属于同一台服务器的同一个数据库拆分到多台服务器中,甚至可以将原本同属于一张表的字段拆分到不同的服务器上。其目的为将一个大的读写请求分解到多台服务器中,从而在异步并行执行中减少请求执行时间,以达到并发周期中可承载更多的请求。
2.2 使用分布式处理,结合CDN负载均衡技术
2.2.1 镜像模式
将一台服务器的镜像副本复制到多台服务器中,通过windows的NLB或者第三方CDN方案如nginx实现分布式处理,请求均衡。此种分布式模式在windows下只能使用NBL,因为NBL仅支持镜像式分布式服务器集群,理论上NLB可以支持32台服务器。
NLB模式的分布式系统的优势在于通过负载均衡能够充分发挥分布式系统在读数据比较频繁的模式下发挥最大的效益,而且彼此之间互为备份。其缺点也是明显的,因为同一条数据的写入(更新或者删除等写操作)必须通过事务在集群内每台服务器上同步。
2.2.2 分段模式
多台服务器通过CDN来决定数据写入那一台或者多台服务器中,数据在读取时需要在多台服务器中轮询,增加了数据读取的复杂度。
2.3 使用分布式缓存技术
分布式缓存技术已经得到广泛应用,其实现算法为平衡树(红黑树),使用缓存的目的是要减少访问服务器低速存储设备以及I/O带来的性能损耗,从而提高系统单位时间内的响应能力,以达到提高并发能力的目的。
分布式缓存有很多典型应用,例如聊天室。早期的聊天室没有使用socket前,基本上使用的都是脉冲模式(服务器轮询),不断向低速存储设备轮询的成本是很可观的。所以写入内存当中能够更快速的使客户端访问到,一旦聊天结束,服务器并不持久化聊天数据。
投注业务具有短时间集中并发写入数据的特点,将数据写入内存,并在内存中操作并非复杂的事情。但如涉及到数据持久化,就存在数据一致性的问题。分布式缓存解决方案redis提供了数据持久化,能够保证数据的一致性。
实践证明,10万级别的并发场景中,向低速存储设备(关系数据库)写入数据如果以整形为主,使用缓存和不使用缓存的差别并不明显。
2.4 NOSQL的使用
NOSQL数据库的数据吞吐能力可以达到关系数据库的百倍以上,天然支持分布式模式。能够提供高速读写的优异性能,提供高I/O操作。谷歌、百度、淘宝等都使用了NOSQL。
但NOSQL也并非没有缺点,大多数应用都是关系型的,也就是要保证数据操作的原子性和唯一性,NOSQL无法保证这一点。因此多数NOSQL应用需要数据库中间件来保证关系数据的原子性。常用的NOSQL如MongoDB、Hadoop等。
3 并发解决方案的实现
分库分表的实现:
A:为什么要分库分表?
在只有一台服务器的情况下,大量的select会被同时执行的update和delete阻塞,导致并发数严重受限。当然,这种场景非常适合读远大于写的应用,当读写基本相当的情况下,单台服务器依旧存在读写互斥的情况,不适合并发量较大的应用。
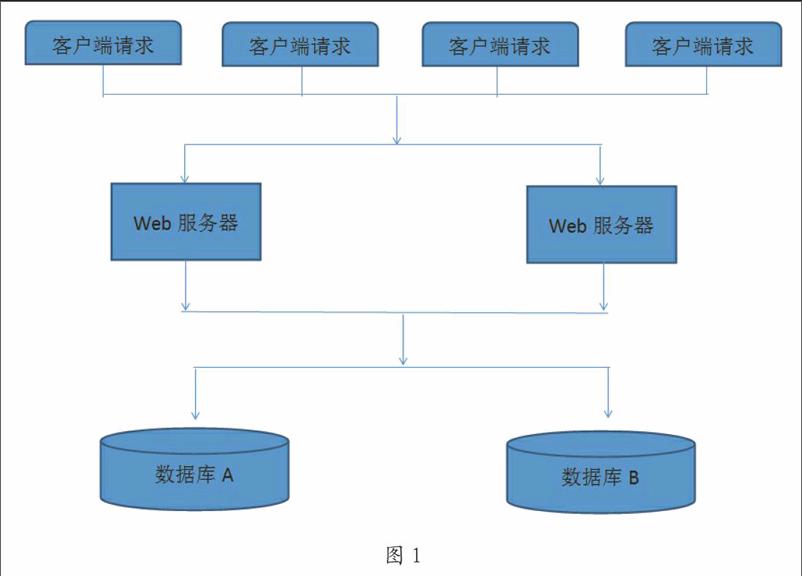
B:分库的作用在于多台服务器分担客户端的读写请求,大大降低了并发的可能性。
在web应用中,通常web服务器应与数据库服务分离,这在未来实现CDN的时候非常有意义,来自客户端的请求基本会在web服务器之间进行分配,由web服务器根据CDN决定访问哪些数据库服务器。
数据库服务器分离后,多台数据库服务器之间通过异步数据事务保持一致性,当然这种数据同步会有一些时间上的延迟,这种延迟基本上都是毫秒级别的。当然,低级别的分库可以直接由逻辑层通过事务保证数据一致性。
操作系统对磁盘的读写有控制机制,在只有一台服务器的情况下,各种请求竞争资源,包括对处理机及内存、磁盘等的控制权。因此,一台服务器的并发能力是非常有限的,这也是分库的原因所在。
3.1 关于读写分离
前文已提到读写互斥,这将给读取数据带来很大延迟,尤其是大量读写的情况下这种延迟是无法接受的。因此在读业务场景中,应保持数据随时处于可读取状态。
通过分库、分表以达到读写分离的目标,让一些(库)表专门用来写数据,而另一些表(库)用来读数据。而数据库与数据库之间通过数据一致性组件保持数据复制作业,如syncNavigator或者数据库自带的订阅发布功能。用于写操作的数据库一旦有新数据写入,则根据数据同步策略来同步数据到读服务器(数据库、表)中。
3.2 关于缓存
Memcached 是一个高性能的分布式内存 对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象 来减少读取数据库的次数,从而提供动态、数据库驱动网站的速度。
memcache会预先生成很多的内存块,比如有96byte,120byte,150byte,200byte,800byte。
预先生成一批slab的好处是什么?可以根据item的大小,放到合适的slab上面去。
原因:找内存所消耗的时间比远大于释放时间。
但是Memcached对内存资源的有效利用:
(1)重复利用已经分配的内存,也就是说不会去删除已有的数据而且释放,而是数据过期后,用户将数据不可见。
(2)Memcached 还是用了一种Lazy Expiration (延迟过期[姑且这样翻译]) 技术,就是Memcached不会去监视服务器上的数据是否过期,而是等待get的时候检查时间戳是否过期,减少Memcached在监控数据上所用到的时间。
(3) Memcached 不会去释放已經使用的内存空间,但是如果分配的内存空间已经满了,而Memcached 是如何去保证内存空间的重复使用呢!Memcached 是用了 Least Recently Used(LRU) 机制来协调内存空间的使用。LRU 意思就是最少最近使用,当此处内存空间数据最长时间没有使用,而且使用次数很少,在存储新的数据的同时就会覆盖此处空间。
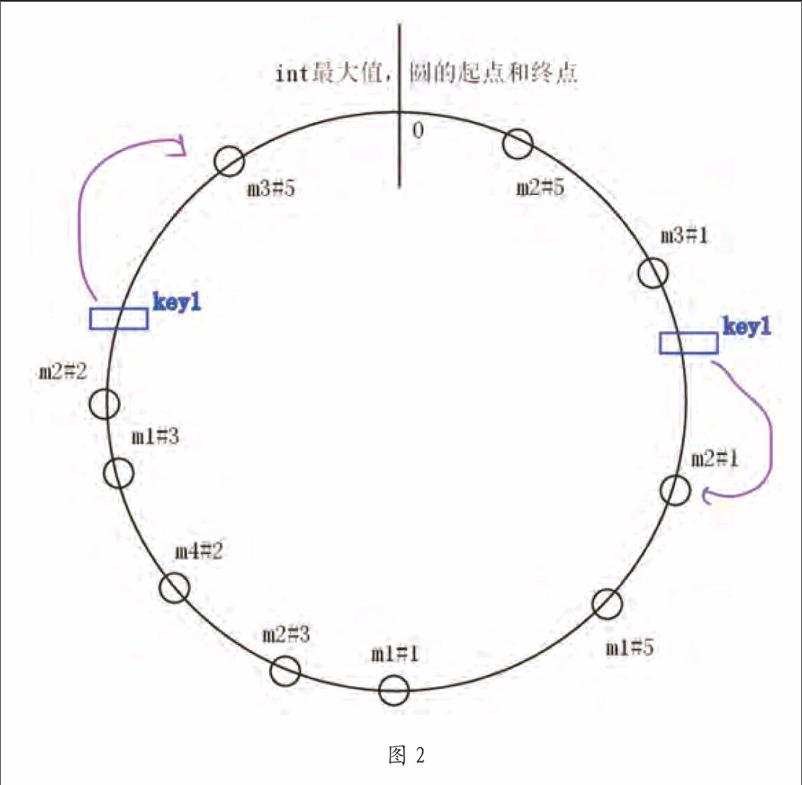
一致性哈希
当hash遇上分布式,单台机子的hashmap存储已经不能满足我们的key-value需求,怎么办,我们需要把存储内容分布到不同的实体机上,这时需要一种把key映射到不同机器的方法,我们想起了hash,可以把实体机当做是桶,采用和hashmap实现一样的思路,通过和实体机的数量取模,自然映射到不同的机器。
但是这就会导致一个问题:数据分布不均匀。大部分数据都分配到server1了,只有小部分数据分布在server2。在服务器数据很少的时候,数据不均 匀会表现的非常明显。
解决这个问题的方法是使用虚拟节点,一个真实服务器对应多个虚拟节点,所有虚拟节点按hash值分布在一致性哈希圆环上。具体实现方法可以这样做,为真实服务器设置副本数量,然后根据各真实服务器的IP和端口号再加上一个递增的索引数计算hash值。
如图2所示。
分布式缓存可以解决以下几种问题:
比如用来缓存Web 页面的内容片段,包括HTML、CSS 和图片等,多应用于社交网站等;
应用对象缓存:缓存系统作为ORM 框架的二级缓存对外提供服务,目的是减轻数据库的负载压力,加速应用访问;
状态缓存:缓存包括Session 会话状态及应用横向扩展时的状态数据等,这类数据一般是难以恢复的,对可用性要求较高,多应用于高可用集群;
并行处理:通常涉及大量中间计算结果需要共享;
事件处理:分布式缓存提供了针对事件流的连续查询(continuous query)处理技术,满足实时性需求;
极限事务处理:分布式缓存为事务型应用提供高吞吐率、低延时的解决方案,支持高并发事务请求处理,多应用于铁路、金融服务和电信等领域。
3.3 关于NOSQL
以SQL SERVER2012作为数据仓库存储逻辑数据,当关系型数据库无法满足并发要求的时候,后端增加使用非关系型数据库mongodb作为高吞吐数据库使用,为避免NOSQL数据库的非原子性操作带来的一些问题,架构使用SQL SERVER作为数据一致性中间件,以分布式缓存作为业务快速存储载体,提高整个系统的并发响应能力。
MongoDB一个文件存储片段最大2GB,所以随着数量的增加,MongoDB会一个又一个增加数据存储文件,正因为是多个文件,所以可以并行从多个文件中读取和写入数据,但是因为是多个文件的并行处理,带来了高IO,也带来了致命的缺陷,原因非常明显,那就是关系数据库为了保证数据的一致性,使用了原子性约束,也就是我们说的原子性操作,比如添加数据库记录时,不允许出现两条数据完全相同,比如主键都是2,这样的话就没办法唯一标识这条数据了,所以关系数据库普遍采用了原子性(唯一性)约束,非关系数据库和关系数据库在这一点上的区别非常鲜明,那就是无法保证原子性操作,非关系数据库不保证原子性,也就无法保证数据的唯一性,这样在连表查询时就无法获取正确的数据,所以一般情况下都是由中间件或者关系数据库来保证数据的唯一性,比如NOSQL数据库专门用来读操作,你不是I/O能力很强吗(是关系数据库的100倍),那你就专门用来读,数据通过各种手段先写入关系数据库,然后再同步到非关系数据库,你从关系数据库里读出来的数据都具有唯一性,再同步到NOSQL,写数据库时底层用的是socket,来监听多个异步操作是否返回了正确的结果。如果是则万事大吉,如果不是,则向缓存拿数据再次写入数据库,直到写入为止,除非有新的请求告诉你丢弃这个操作。最后再同步到NOSQL来读。
参考文献
[1]包立辉,黄彦飞.高并发网站的架构研究及解决力案[J].计算机科学,2012,39(10):184-187.
[2]薛质.电子商务平台的性能优化和高可靠性研究与实现[D].上海:上海交通大学,2007:41-45.
作者单位
浙江师范大学 浙江省金华市 321004
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
航空发动机(2020年3期)2020-07-24
军事运筹与系统工程(2019年2期)2019-11-16
初中生世界·九年级(2017年8期)2017-09-06
科学与财富(2016年18期)2016-12-22
新闻界(2016年15期)2016-12-20
中小企业管理与科技·上旬刊(2016年11期)2016-11-28
科学与财富(2016年15期)2016-11-24
