
面向健康问答社区的语义检索技术研究与分析
2017-03-15 12:30范桥青方钰
电子技术与软件工程 2017年2期
范桥青++方钰

摘 要 本文以Axiomatic检索模型为基础,利用Word2Vec在健康问答数据集上训练出的词向量来衡量词语语义相似度,来实现对问答数据的语义检索。此外,实验对比了不同的词义相似度计算方法在不同数据集下的检索效果,并分析了使用外部词典作为词义相似度计算方法时存在不足的原因,结果表明本文的检索方法能够有效地提升检索准确率。
【关键词】语义检索 Word2Vec 词向量 自动问答
1 概述
健康问答社区中存在大量重复冗余的数据,构建自动问答系统的第一步就是从这些众多的问题中检索出相关信息。目前工业中使用的基于词形的检索技术[1]在海量数据处理上存在诸多不足,尤其是在揭露信息的语义上存在局限性。比如在健康问答社区中,存在着许多义似而形不似的问题:“有什么减肥建议?”和“怎么瘦身?”,再加上用户在提问时大量使用口语化的词语,使得传统的基于词形的检索技术在这类信息的检索上略显无力;另外又由于健康问答领域中的信息专业性强,很多专业词语在语义词典[2-3]中并没有编录多少同义词,甚至没有被收录。因此,一般的语义检索技术使用在健康问答领域乏善可陈。
2 相关工作
目前,语义检索领域的研究主要集中在本体技术、语义词典和主题模型上:
本体概念源自于哲学中的本体论,是对事物原样及其自身的描述,而后被借鉴到计算机领域。Studer根据前人的研究将本体拆解成了四层含义:概念模型、明确、形式化和共享[2]。借此,诸多以本体技术为基础的检索技术出现[3-5]。然而本体知识库的建立需要多位领域专家的参与,面对海量的健康问答社区数据源构建一套知识库无疑是一件相当巨大的工程。
同义词词典为每一个被收录的词维护了相关的语义信息,代表有WordNet[6]和HowNet[7]。语义词词典对检索时关键词的拓展起到了重要的作用,同时刘群等人提出了以HowNet为基础的词语相似度计算方法[8],为中文词义相似度的计算填补了空白。但同义词词典存在一个巨大的缺陷:收录的词有限。对于不存在于词典中的词,无法衡量它们的相似度,如上述问句中的“瘦身”,因为没有被收录,所以就无法衡量“瘦身”和“减肥”之间的语义关系,从而两个语义上相似的问句也因核心词的不相似而变得不相关。
主题模型是一种潜在语义分析技术,利用统计学方法,可以识别出大规模文档集中的主题信息。主题模型会训练得到两个模型:文档-主题模型和主题-词模型,吕亚伟等人[9]就以此提出了利用主题信息作为特征的词语相似度计算方法。但是,主题模型在面对文本的动态增长时,找到合适的主题投射纬数也愈显困难。
Word2Vec是由谷歌公司以Mikolov等人[10-11]的工作为基础推出的词向量训练工具。对于给定的语料库,Word2Vec可以通过神经网络模型将文本中的词映射到一定维度的向量上,训练出的词向量由于捕获了文本的上下文信息不仅能够很好地反映词义信息,而且解决了一词多义的问题。所以,基于以分析本文将词向量作为衡量语义的主要手段并展开工作。
3 Word2Vec原理
词向量的概念源自于Hinton中的Distributed representation[12],被Bengio应用于其所提的神经概率语言模型中[13],是神经网络为了学习某个语言模型而得到的中间产物。最早的词向量one-hot representation不仅会因语料库的增大带来维数灾难的问题,而且也不能很好的刻画词语间的关系。
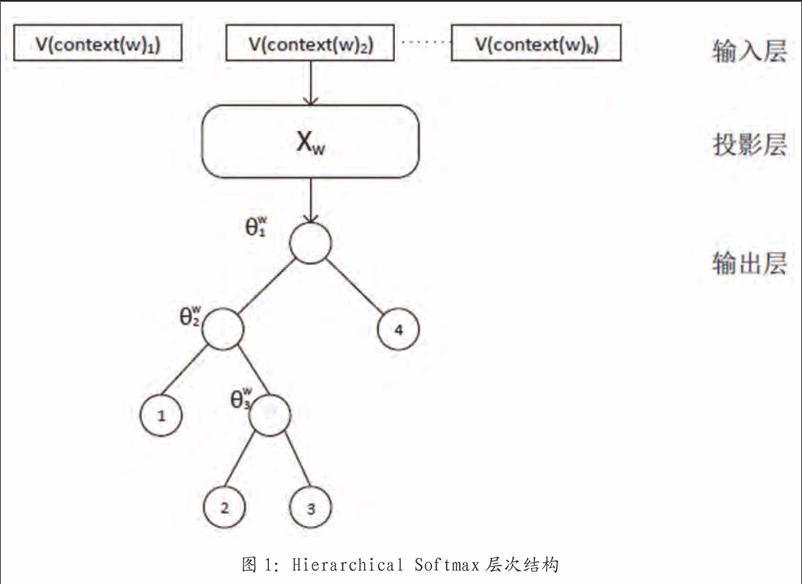
Word2Vec是一款词向量训练工具,它有两种训练模型:CBOW和Skip-gram。CBOW是通过上下文词预测当前词,Skip-gram则是通过当前词来预测上下文,另外还有Hierarchical Softmax和Negative Sampling两种训练方法。不同于Bengio的神经概率语言模型的处理方式,Mikolov在映射层是采用向量相加的方式,而且输出层采用了Huffman树形结构。以基于Hierarchical Softmax的CBOW为例,其结构图如图1所示。
Hierarchical Softmax的输出层采用了上述的树形结构,context(w)表示和词w前后紧邻的相关词,v(context(w)k)表示相关词k的词向量,θkw是词k的huffman树编码值1-0,如果Xw向量預测到词3,则需要经过三个分支,每次分支都是一次二分类。Word2Vec中编码1被定义成负类,编码0定义成正类,根据逻辑回归,一个节点被分到正类中的概率是:
Hierarchical Softmax算法对词典中的每一个词,算法输出层必然存在一条导向这个词的二分类路径,用J表示整个路径长度,则这个路径中所有节点的分类概率连乘积即为语言模型需要求解的p(w|context(w)):
映射层对所有的输入向量进行了合并,所以Word2Vec把向量的梯度变化贡献到了每个向量分量上。
所以从上述分析,可以看出Word2Vec在训练语言模型的过程中,是捕获词了语义信息的:通过周围单词预测目标词的训练方式很好地反应了目标词的语义环境,并且以数学向量的形式承载这种语义信息。
4 本文检索方法
文献[1]拆解了三种具有代表性的文本检索模型,并通过具体的实验数据诱导了若干检索模型的权重函数和查询增长函数,提出了一种名为Axiomatic的最优检索模型:
Q代表查询词集,D是候选文本词集,c(t,Q)表示t在Q中出现的次数,df(t)是包含词t的文本个数,N是文档总数,c(t,D)是t 在文档D中出现的次数,avdl是所有文本词集个数的平均值。
上述检索模型在实践中取得了很好的效果,但由于该公式并没有很好地刻画查询串和被检索文档的语义关系,于是黄承慧等人[14]基于以上公式提出了如下改进:
Sim(t,D)表示候选文本词集D中和目标词t相似的个数, Sim_df(t)表示语料库中包含和目标词t相似词的文本个数,黄承慧使用WordNet来衡量词之间的相似性,相似的阈值通过实验来确定。
WordNet和HowNet作为中英文领域的语义词典,需要人工不断完善和补充,在面向处理专业性很强的文本时,会因大量专业词汇没有被收录进词典而无法计算相似度,比如健康领域中的“alzheimer”和“dementia”、“阿尔茨海默病”和“痴呆”;此外,一词多义的问题也无法得到很好的解决,比如说“男性”和女性在按照论文[8]实现的计算方式中有0.86的相似程度,而“woman”和“man”在WordNet的开源实现WS4J 中也有0.9的相似程度。从物种的角度来说它们确实是高度相似的,但是从性别的角度来说它们完全代表不同的人种,在本文应用领域下只有“男性”有前列腺疾病,“女性”有妇科病,但按照上述计算模型,“男性”和包含“女性”关键词的妇科疾病相关文档也会得出很高的分数,这是不合理的。
如果使用词向量来衡量语义关系,那么在词向量的训练过程中,词向量捕获了上下文关系,其承载的数据不仅可以绑定“女性”和妇科疾病的关系,而且很好地解决了因词典收录不足带来的语义空白问题。
所以基于以上分析,本文提出使用Word2Vec训练出的词向量作为公式(7)衡量词义相似度的方法:用Vecw=[v1,v2,……,vk]表示词w的词向量,k是词向量的维度大小,那么两个词之间的语义距离可以通过余弦相似度计算得到:
5 实验结果及分析
5.1 实验结果
本节实验数据来自于Reuters-21578和120ask。
Ruters-21578是业界广泛使用的英文文本分类数据集,它有两种划分:ModApte和ModWiener。本文采用的是ModApte划分,训练集共9603篇文档,测试集3299篇文档,按主题信息对其进行分类,主题词总共135个,测试集中主题词共92个,实验是对测试集中的主题词进行检索。
120ask是中文健康问答平台,笔者从中医内科、肝病、胃肠炎等十个类别下均匀抽取了1000条问答对来构建测试文本集合,并针对每个类别人工构建了10个问题,共计100个测试问题,通过人工标注的方式为每个测试问题标注了相关文本集合。此外,为了保证分词的正确性,又从搜狗词库中搜集了132371条医学专有名词,涵盖药品名、疾病名、解剖学、药企名等方面。Word2Vec训练词向量使用的是基于Hierarchical Softmax的skip-gram模型,词向量维度为50,窗口大小设置为5。
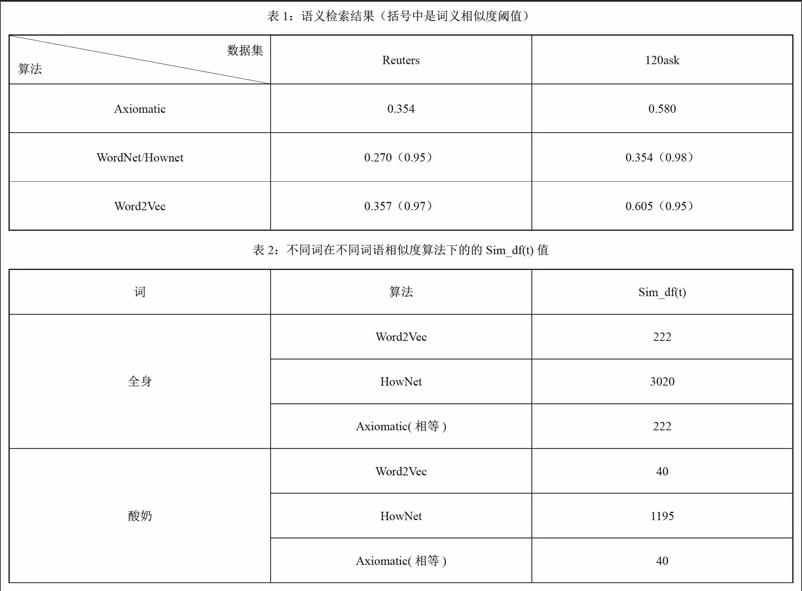
Reuters-21578用来验证算法的普适性,120ask用来验证算法在本文应用领域性下的有效性,分别对比公式(6)、公式(7)以及本文方法在搜索结果Top10下的准确率。WordNet用于Reuters数据集,使用的是其WS4J实现,Hownet用于120ask数据集,使用的是文献[8]的开源实现xsimilaity,实验结果如表1所示。
5.2 分析
由上述实验结果可知,本文方法在两个数据集上都取得比较好的效果。
其中,在Reuters数据集上提升了0.3%,这主要受数据集大小影响,训练出的词向量表述能力有限。另外从实验结果中得知,在“acq”这个关键词上Axiomatic准确率只有20%,而本文的方法的准确率则高达60%,而且“acq”这个词并没有wordnet收录,说明词向量确实对算法起到了一定优化作用。
在120ask数据集上,本文的算法提升效果明显,主要有以下两个原因:
(1)用于训练词向量的语料库丰富,训练出的词向量表述能力强。
(2)健康问答领域的数据集专业性强,领域明显,很多专业名词有多种口语化表述,比如“痤疮”和“青春痘”、“痘痘”等等,虽然“痤疮”没有被收录进语义词典,但是通过训练出的词向量,很容易找出和这些专业词上下文相关的其它词,这就大大提升检索结果。
此外,还可以注意到基于语义词典的效果提升不是很明显,甚至没有经典算法好。我们从公式(7)出发,深入分析其子项Sim_df(t)(包含和词t相似的词的文档数量),其结果如表2所示。
发现基于HowNet的词语相似度计算方式在本文的应用背景下存在不合理性,这主要有以下两个原因:
(1)文献[8]提出的词义相似度计算方式是以HowNet的概念和义原为基础,一个词可以由多个概念表征,即一词多义,而且最大的概念相似度值会作为词语相似度值返回。
(2)概念相似度计算依赖义原,所以义原的相似度值作为主要部分制约着整个词语的相似度值。以词“全身”和“胸腔”为例,概念中都有基本义原“部件”,按照上述方式在其它义原、关系义原和关系符号为空的情况计算得到的相似度值为1.0,这是不合理的。虽然HowNet对“全身”和“胸腔”标注了“部件”这一基本义原,但缺乏更细致的其它义原,即缺乏更细致的语义划分,导致了在本文应用背景下效果较差的原因,同样这种原因也存在于WordNet中。
所以综上所述在本文应用背景下,使用Word2Vec训练出的词向量作為衡量词语语义关系并融合进公式(7)在语义检索上是具有一定的可行性的。
6 总结和展望
本文一开始简单介绍了当前语义检索的研究现状,并以此引出本文的研究内容;而后以Axiomatic检索模型为基础,结合Word2Vec在健康问答数据集上训练出的词向量来衡量词语语义相似度,从而实现对问答数据的语义检索;最后在不同的实验数据集上对本文算法的可行性就行了验证,并对实验结果进行了详细分析,特别是在使用语义词典来计算词义相似度时所带来的问题。
为进一步提高实验结果,下一步将重点放在词向量的训练上,拟通过更广泛的数据集来训练得到一个更完备的词向量,同时对检索的时间进行优化。
参考文献
[1]Fang H,Zhai C X.An exploration of axiomatic approaches to information retrieval[C]//SIGIR 2005: Proceedings of the,International ACM SIGIR Conference on Research and Development in Information Retrieval,Salvador, Brazil, August. 2005:201-243.
[2]Studer R,Benjamins V R,Fensel D. Knowledge engineering:Principles and methods[J].Data & Knowledge Engineering,1998,25(1-2):161-197.
[3]刘超,李伟.基于本体语义检索技术研究[J].自动化技术与应用,2014,33(02):9-12.
[4]付苓,崔新春,乔鸿.基于本体的语义检索研究[J].情报科学,2010(09):1384-1387.
[5]陈泳,林世平.基于本体的语义检索技术[C]//全国智能信息网络学术会议,2006.
[6]Miller G A.WordNet:a lexical database for English[J].Communications of the Acm,1995,38(11):39-41.
[7]董振东,董强.知网和汉语研究[J].当代语言学,2001,3(01):33-44.
[8]刘群,李素建.基于《知网》的词汇语义相似度计算[J].中文计算语言学,2002.
[9]吕亚伟,李芳,戴龙龙.基于LDA的中文词语相似度计算[J].北京化工大学学报自然科学版,2016,43(05):79-83.
[10]Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
[11]Mikolov T,Sutskever I,Chen K,et al.Distributed representations of words and phrases and their compositionality[C]//Advances in neural information processing systems.2013:3111-3119.
[12]Rumelhart D E,Hinton G E,Williams R J.Learning representations by back-propagating errors[M]// Neurocomputing:foundations of research.MIT Press,1986:533-536.
[13]Bengio Y,Schwenk H,Senécal J,et al.Neural Probabilistic Language Models[J].Journal of Machine Learning Research,2003,3(06):1137-1155.
[14]黃承慧,印鉴,陆寄远.一种改进的Lucene语义相似度检索算法[J].中山大学学报(自然科学版),2011,50(02):11-15.
作者单位
同济大学电子与信息工程学院计算机科学与技术系 上海市 201804
