
基于自训练的回归算法
2017-03-21 01:29仝小敏
中国电子科学研究院学报 2017年5期
仝小敏, 吉 祥
(中国电子科学研究院,北京 100041)
0 引 言
回归算法是一种统计学上分析数据的方法,主要是研究数据之间是否存在一种特定关系,从而建立自变量和因变量之间关系的模型,然后利用该模型对测试样本的因变量进行预测。由于科学研究中经常涉及对历史数据样本的分析和对新数据进行预测,所以回归算法在机器学习[1]、计算机视觉[2]、大脑数据分析[3-4]等许多方面具有广泛的应用。
传统的回归算法主要是利用训练集中样本的自变量和因变量训练回归模型,然后利用训练好的回归模型和测试集中样本的自变量预测得到测试样本的因变量,如图1所示。但是该回归模型只利用训练集中样本的信息,没有充分利用测试集中样本的信息,特别是当训练集中样本数量较少时,回归模型不能得到充分的训练,无法预测得到满意的结果,因此,本文提出一种基于自训练(self training[5])的回归算法,将第一次回归预测得到的置信度较高的测试样本加入到训练集中重新训练回归模型,完成回归模型的自我训练,从而使得回归模型得到充分的训练,对测试样本的因变量预测更加准确。
1 基于自训练的回归算法
本文提出的自训练回归算法亮点是加入了自训练的过程,下面将针对这一自训练反馈过程进行阐述:
本文利用两个回归算法:双高斯过程回归和LS-SVM对训练样本同时进行训练,将训练好的回归模型分别用于测试样本的预测中,对预测得到的样本进行置信度计算,将两者预测得到的置信度都高的测试样本加入到训练集中重新进行回归模型的训练,然后用新得到的回归模型重新对测试样本进行预测。下面就双高斯过程回归、libSVM和置信度的确定方式进行说明。
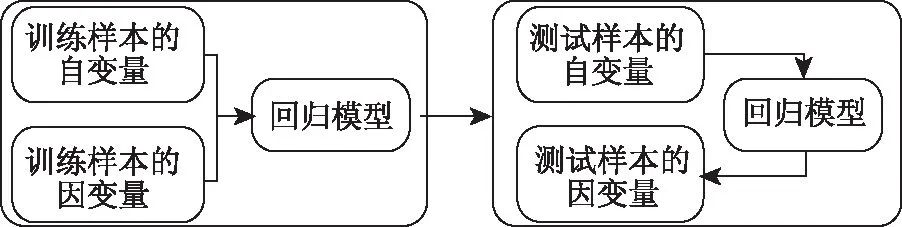
图1 传统的回归算法流程
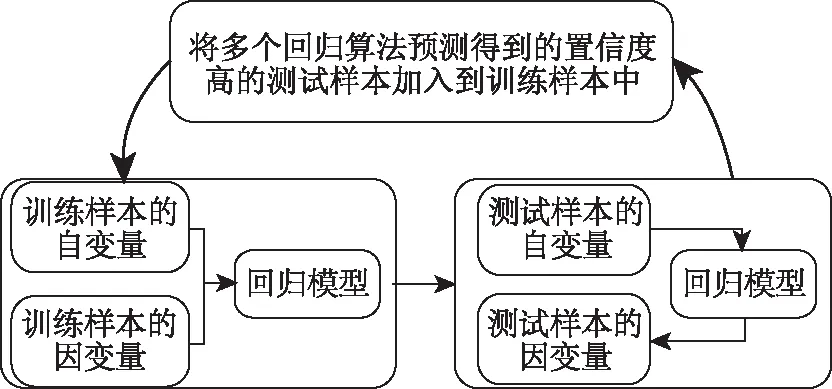
图2 本文的回归算法流程
1.1 双高斯过程回归
双高斯过程回归是对经典高斯过程回归的改进,传统的高斯过程回归算法由Rasmussen提出,高斯过程回归和贝叶斯线性回归类似,不同之处在于高斯过程回归用核函数替代了贝叶斯回归中的基函数,使得一些难以表示出基函数的模型仍可以用核函数继续进行回归过程,应用广泛。
高斯过程是一个随机变量的集合,这些随机变量服从联合高斯分布。在高斯过程回归中,这些随机变量表示自变量函数的值。高斯过程回归假设自变量函数分布的均值为0,他们之间的相关性则用协方差函数表示,常用的协方差函数如下:
Ki,j=K(Xi,Xj)=
(1)
式中:Xi为第i个自变量。i=1,2,…,N;Xj为第j个自变量。j=1,2,…,N;θ0、ηd,d=1,2,…,D1和θ1为高斯核函数中的超参数;xi,d为Xi中第d维上的数值;xj,d为Xj中第d维上的数值。
在上述的协方差函数中,若两个变量越接近或者越相似,则两者的相关性越大,否则,相关性越小。在定义了协方差函数后,我们的目的是利用训练集中的自变量和因变量,预测新来样本的自变量XN+1对应的因变量yN+1,这要求我们去预测响应的条件分布p(yN+1|y1,y2,…,yN),为了得到这一条件分布,我们先得到Y的联合分布:
p(y1,y2,…,yN+1)=N(y1,y2,…,yN+1|0,CN+1)
(2)
式中:CN+1为 (N+1)×(N+1)个自变量之间的协方差矩阵。该协方差矩阵可以分解为如下形式:
(3)
式中:K为元素为K(Xi,XN+1)的向量;c=K(XN+1,XN+1)+β。
由此,我们可以得到p(yN+1|y1,y2,…,yN)的均值和协方差函数:
m(XN+1)=KTC-1(y1,y2,…,yN)T
(4)
σ2(XN+1)=c-KTC-1K
(5)
上述两个公式是定义高斯过程回归算法的关键,从中我们可以看出,无论是均值还是协方差函数都依赖于XN+1,而且我们从中也可以得到想要预测的yN+1,即m(XN+1)。
1.2 LS-SVM
最小二乘支持向量机(Least Squares Support Vector Machines,LS-SVM)[6]是一种遵循结构风险最小化原则的机器学习方法。它是传统SVM在二次损失函数下的一种特殊形式,用一组等式约束代替了SVM的不等式约束,很大程度上方面了Lagrange乘子α的求解,提高了问题求解的效率,因而在分类、预测等领域得到了广泛应用。
1.3 置信度定义
预测样本置信度的定义是本文的核心和关键,直接影响着新回归模型的准确性,因此,本文采用皮尔森相关系数来定义置信度。对于YN+1,计算其与训练集中同类样本中每一个Yi的皮尔森相关系数,从计算得到的系数中选择值最高的系数作为YN+1对应的置信度,同理我们可以分别得到YN+2,…,YN+M的置信度。参照[7]中设置,我们设置两种回归算法的到的预测样本置信度都大于0.8的作为备选样本,然后选择备选样本中置信度最高的若干个样本加入到训练集中。
1.4 基于自训练的回归算法流程
综上,本文提出的基于自训练的回归算法归纳如下:
初始化:分别定义Xi={xi,1,xi,2,…,xi,D1}和Yi={yi,1,yi,2,…,yi,D2}为训练集中自变量和因变量,XN+1,XN+2,…,XN+M为测试集中自变量。
循环进行:
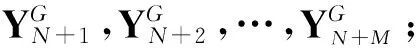

置信度采用皮尔森相关系数计算,对于YN+1,
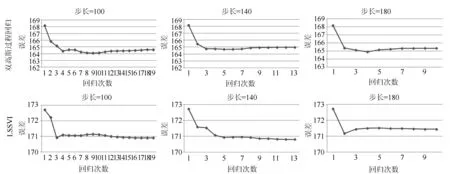
图3 本文算法实验结果
计算其与训练集中同类样本中每一个Yi的皮尔森相关系数,从计算得到的系数中选择值最高的系数作为YN+1对应的置信度,同理我们可以分别得到YN+2,…,YN+M的置信度。参照[7]中设置,我们设置两种回归算法的到的预测样本置信度都大于0.8的作为备选样本,然后选择备选样本中置信度最高的若干个样本加入到训练集中,利用新的训练集和测试集返回步骤1重新进行双高斯过程回归模型的计算;
结束上述循环。循环终止条件:直到没有符合要求的样本需要加入到训练集中或者测试集为空为止。
步骤4:用最后得到的回归模型分别对XN+1,XN+2,…,XN+M重新进行预测,将得到的准确率较高的YN+1,YN+2,…,YN+M作为最后的预测因变量。
2 实验结果和分析
2.1 实验数据
本文利用双高斯过程回归原文中[2]的数据集对本文算法进行验证。数据库包括1176个人体姿态图像的HOG特征和他们对应的人体姿态向量。对数据库,我们随机选取了100个样本作为训练集,包括他们的HOG特征和对应的人体姿态向量作为训练,其余的1076个样本作为测试集。
2.2 评价指标
(6)
式中:U为人体姿态中关节的数目;mu为用于提取人体姿态中关节对应的三维坐标的函数;‖·‖为欧氏距离。
2.3 实验结果
实验在matlab平台下进行,我们利用双高斯过程回归、LS-SVM以及本文算法进分别进行预测,预测结果图3所示。图中,我们对HOG数据集进行测试,初始训练样本为100,步长(每次新加入到训练集中的样本个数)分别设置为100、140和180,若双高斯过程回归和LS-SVM的重合步长小于以上设置,则步长按实际计算。图3中给出了实验结果,双高斯过程回归、LS-SVM的回归误差等于回归次数等于1时的误差。第一行为本文算法中双高斯过程回归算法结果,从图中可见,采用了自训练方法的双高斯过程回归模型经过置信度高的样本的重新训练,误差比原始的双高斯过程回归算法要小,直到没有符合要求的样本或者训练集为空为止,原始的双高斯过程回归算法误差即回归次数为1时的误差。图3第二行为本文算法中LS-SVM的结果,从图中可知,由于加入了置信度高的样本的充分训练,LS-SVM模型的误差也比原始的LS-SVM算法结果小,原始的LS-SVM误差即即回归次数为1时的误差。说明了本文算法的有效性。
为了阐述利用两个回归算法的必要性,我们对两种算法单独进行自训练回归,即将前一次高斯过程回归预测中得到置信度高的样本加入到高斯过程回归算法的训练集中,重新训练高斯过程回归模型,利用新得到的模型对测试样本进行预测;SVM同理,将两种算法在不同步长下的平均误差进行统计,实验结果如表1所示。
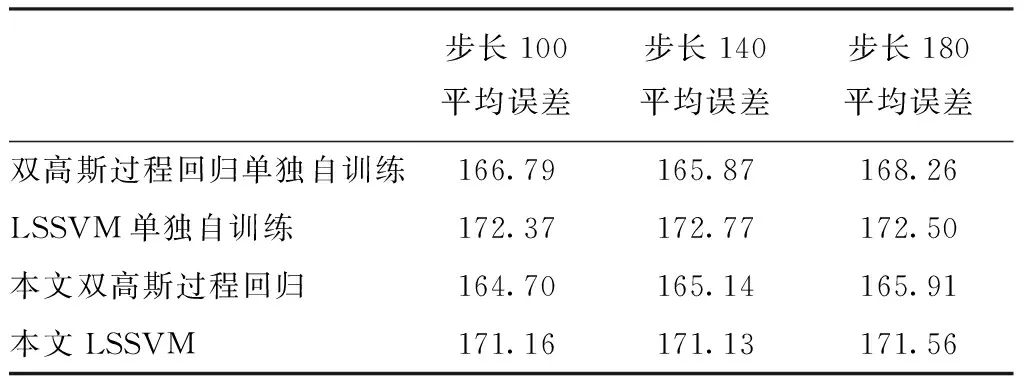
表1 采用两个回归算法的必要性实验结果
从实验结果中看到,单独使用某个回归算法进行自训练的误差高于同时使用两种回归算法,原因是本文算法从两种回归算法得到的预测结果中筛选出置信度都高的样本,而单独使用某种回归算法只能在本算法的预测结果中进行筛选,本文算法相当于对预测结果的筛选进行了优中选优,从而优于只使用一种算法。
为了进一步论证0.8的参数选择是否充分,我们分别将参数设置为0.7、0.9、0.97进行试验,这三个参数的平均误差分别是双高斯过程回归(164.51,164.51,164.51,170.87),LSSVM(171.07,171.07,171.07,172.12)。从实验结果可以看出,参数0.8是可以达到最优的误差的,实验中误差在0.95左右才开始增大,说明了参照文献[7]参数选择的较为合适。
文献[5]给出了两种相互训练的标注算法:naive co-training和agreement-based co-training。前者的流程是:分别利用两个分类器对训练样本进行训练,然后利用训练好的分类器分别对部分测试样本进行测试,将一个分类器的测试结果作为新训练样本加入到另一个分类器的训练集中,重新进行分类器的训练,直到测试样本集为空为止。后者的流程是:分别利用两个分类器对训练样本进行训练,然后利用训练好的分类器分别对部分测试样本进行测试,从测试结果中选择一个一致性高的子集作为新的训练样本加入到训练集中,该一致性为两个分类器利对测试样本的分类一致性,若两个分类器对测试集分类结果一致性越高,则说明该子集的一致性高。文献[5]中的第一种方法与本文的方法相比,并没有进行新训练样本的筛选,而是将一个分类器的测试结果不加筛选的加入另一个分类器的训练集中,最后的准确率会受到坏样本的影响,导致准确率下降。为了进一步对比,我们对文献[5]中方法1进行了实验,实验中将两种回归算法的新样本不加筛选的添加到对方的训练集中,实验结果如表2所示。
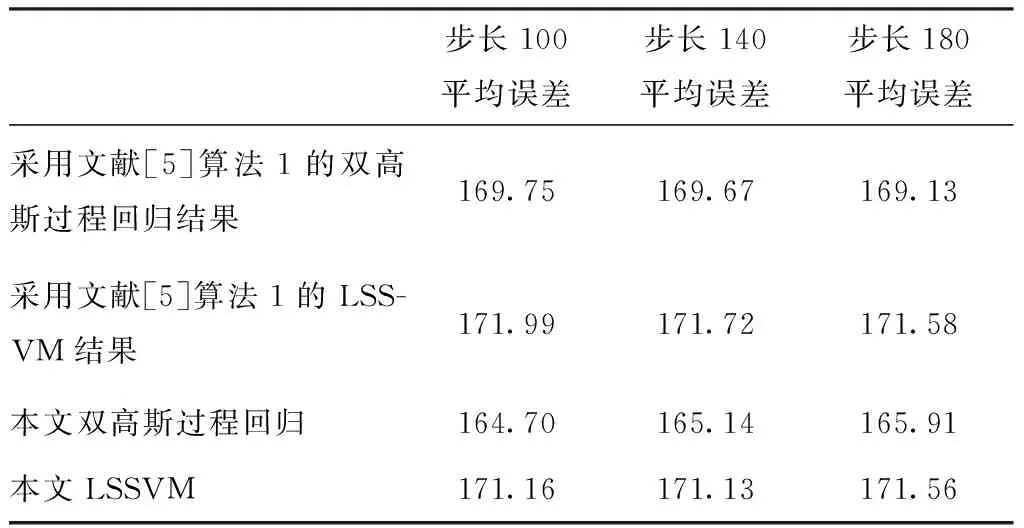
表2 本文算法与文献[5]算法1实验结果对比
从实验中可以看出,本文的算法进行了新加入样本的筛选,误差较小,而文献[5]的方法1并未进行样本筛选,误差高于本文算法。
文献[5]中的第二种方法与本文的方法相比,挑选新样本的方法有所不同,文献[5]中的第二种方法为:若两个分类器利用新训练集对测试样本的分类一致性高,则这样的新样本集作为新的训练样本加入到训练集中。本文是将测试结果中与训练样本相关性高的样本作为新的训练样本。文献[5]侧重两个分类器对测试样本的分类一致性,本文侧重两个回归算法与训练样本的一致性,相比而言,关注测试样本的分类一致性有时并不是完全有效,因为两个分类器可能同时分错,而训练样本中具有人工标注的真值,并且因为测试样本的结果由训练样本训练得到,所以关注训练样本比关注测试样本更直接,此外,文献[5]中的方法需要重复多次测试,才能选出一致性高的新训练样本,本文只需计算一次与训练样本的置信度即可得出新训练样本。由于文献[5]中为标注分类方法,在选择新训练样本时采用的是多次统计两种标注方法对测试样本相同标注的数量,该策略无法直接应用在回归算法上(回归得到的结果为连续的,不像标注分类为+1或者-1),若要应用在回归算法上,需改变文献[5]中的一致性策略,因此无法将文献[5]中第二种方法与本文方法进行实验对比,只从理论上对两种方法进行了分析。
3 结 语
本文提出了一种基于自训练的回归算法,针对传统回归算法中测试样本信息无法得到充分的利用,特别是训练样本较少时回归模型无法得到充分的训练的问题,我们将两个回归算法第一次得到的预测结果进行置信度的计算,将两种算法得到的置信度都较高的预测样本加入到训练集中,重新训练回归模型,用新得到的回归模型对测试样本的因变量进行预测,得到了比两种回归算法单独使用都要高的预测准确率。
[1] C. M. Bishop, Pattern recognition and machine learning, vol. 1. springer New York, 2006.
[2] L. Bo and C. Sminchisescu, Twin gaussian processes for structured prediction, Int. J. Comput. Vis., 2010, 87(1-2):28-52.
[3] X. Ji, J. Han, X. Hu, et al. Retrieving video shots in semantic brain imaging space using manifold-ranking. 18th IEEE International Conference on Image Processing (ICIP), 2011. Brussels, Belgium, 3633-3636.
[4] J. Han, X. Ji, Xintao Hu, et al. Representing and retrieving video shots in human-centric brain imaging space[J]. IEEE Transactions on Image Processing. 2013,22(7): 2723-2736.
[5] S. Clark, J. R. Curran, and M. Osborne, “Bootstrapping POS Taggers Using Unlabelled Data,” in Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, 4: 49-55.
[6] J. Suykens, T. Gestel, J. D. Brabanter, B. Moor, et al. Least squares support vector machines. World Scientific. 2002.
[7] M. Chen, K. Q. Weinberger, J. Blitzer. Co-training for domain adaptation.[C]. NIPS. 2011: 2456-2464.
[8] L. Sigal, M. Black,. HumanEva: synchronized video and motion capture dataset for evaluation of articulated human motion (Technical Report CS-06-08). Brown University.2006.
猜你喜欢
计算机工程与应用(2022年15期)2022-08-09
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
科技创新与应用(2020年6期)2020-02-29
小天使·二年级语数英综合(2019年4期)2019-10-06
小学生学习指导(低年级)(2019年6期)2019-07-22
计算机应用(2018年5期)2018-07-25
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
电影故事(2015年16期)2015-07-14
