
面向医疗健康大数据的存储系统容错策略优化研究
2017-03-21 01:29杨东日刘姝祎
中国电子科学研究院学报 2017年5期
杨东日,陈 跃,刘姝祎,刘 超
(1. 工业和信息化部软件与集成电路促进中心,北京 100013;2. 西安交通大学,陕西 西安 710000)
0 引 言
近年来随着大数据行业的快速发展和医疗健康行业信息化水平的逐渐提高,自然产生了越来越多的医疗健康数据。从行业来讲,医疗健康大数据已初具规模,当前业内对医疗健康大数据的价值有了更深的认识,都希望充分利用好医疗健康大数据的价值,通过大数据分析,对一些病情、疫情、健康管理做出更加精确的预测,但当前医疗健康大数据的现状都面临一些问题,由于历史原因,数据分散存储在不同的硬件环境下和不同的文件系统和数据库中,容错性普遍较差,为了实现对医疗健康大数据的高效分析、挖掘与合理利用,在大数据场景下,提出合理的医疗健康大数据的云存储文件系统的容错优化策略就是一个很有现实意义和急需要解决的问题,这些问题解决的好坏程度会直接影响到医疗健康大数据的使用。
云存储的核心是分布式文件存储系统。目前分布式文件系统按照其系统技术架构来分,可以分为有中心的分布式文件系统架构和无中心的分布式文件系统架构[1]。本文主要研究的是在医疗健康大数据场景下有中心的分布式文件系统数据容错策略的优化问题,并针对性的提出了基于副本复制和纠错码融合的医疗健康大数据文件系统容错的优化策略。
1 相关工作
大数据带来了存储、管理、处理数据的挑战,也带来了发掘数据中新的价值的机遇[2],医疗健康大数据更是具有其特点和面临对应的挑战。
1.1 数据特殊性
相比其他行业的大数据,医疗健康大数据有其自身的一系列特点,主要有以下几个方面的特点:
1.1.1 多数据源
医疗健康大数据的数据来源包括医疗单位数据、个人健康数据和公共健康数据[2],如:美国联邦政府和其他公共利益相关者已经开辟了广泛的保健知识库,包括临床试验资料和公众覆盖患者资料保险计划。同时,最近的技术进步使得更容易收集并分析来自多个来源的信息[5]。
目前国内的医疗健康大数据主要来自医院、健康管理等机构各自的多个数据源,如:医院信息系统(hospital information system,HIS)、医疗设备、健康设备产生的多维数据。
1.1.2 多数据类型
医疗健康大数据包含了结构化数据、半结构化数据和非结构化数据,医疗大数据文件系统的容错优化策略必须充分考虑好对这三种类型数据的支持。
1.1.3 其他特殊性
医疗健康大数据除包含了大数据5个V的特点之外,还有多态性、时效性、不完整性、冗余性、隐私性等特点[3]。多态性指医师对病人的描述具有主观性而难以达到标准化;时效性指数据仅在一段时间内有用;不完整性指医疗分析对病人的状态描述有偏差和缺失;冗余性指医疗数据存在大量重复或无关的信息;隐私性指用户的医疗健康数据具有高度的隐私性,泄漏信息会造成严重后果[3]。这几个特殊性也都对医疗大数据文件系统的容错优化策略提出了更个性化和更高的要求。
1.2 遇到的问题及面临的挑战
以往的大数据云存储系统(如:典型的云存储系统Hadoop HDFS,Goole GFS)普遍采用三备份的策略,其设计初衷是由于通用商业PC在三副本的情况下可以基本保证不丢数据,但是Hadoop系统的这种三副本技术本身的容错能力不高(只能容错2个节点失效),存在效率也较低[4]。对具有多数据源,多数据类型,多态性、时效性、不完整性、冗余性、隐私性等特点的医疗大数据,如果直接采用类似的文件系统容错策略,则更是低效和稳定性差。很多问题挑战了医疗健康大数据的采用和成功[7],大量医疗健康数据的规模越来越大和可用性越来越多,需要好的数据管理策略[6],其中基础的文件系统容错优化策略更是有其重要性。
通过对医疗健康大数据文件系统的元数据的双机热备容错机制及块编解码容错机制的设计,使得系统的容错能力得以大大提升,从而提高了云存储文件系统的可靠性和高可用性[1],并基于此设计了管理节点容错功能模块和存储节点容错功能模块。
2 医疗大数据容错云存储系统
2.1 容错模型
对于有中心元数据管理节点的分布式文件系统来说,系统的容错主要体现在两个方面,即:管理节点容错和存储节点容错[1]。
2.2 体系结构
本文给出了一个典型的医疗健康大数据云存储系统的架构设计。该架构是云存储文件系统容错机制设计和实现的架构基础。如图1所示。
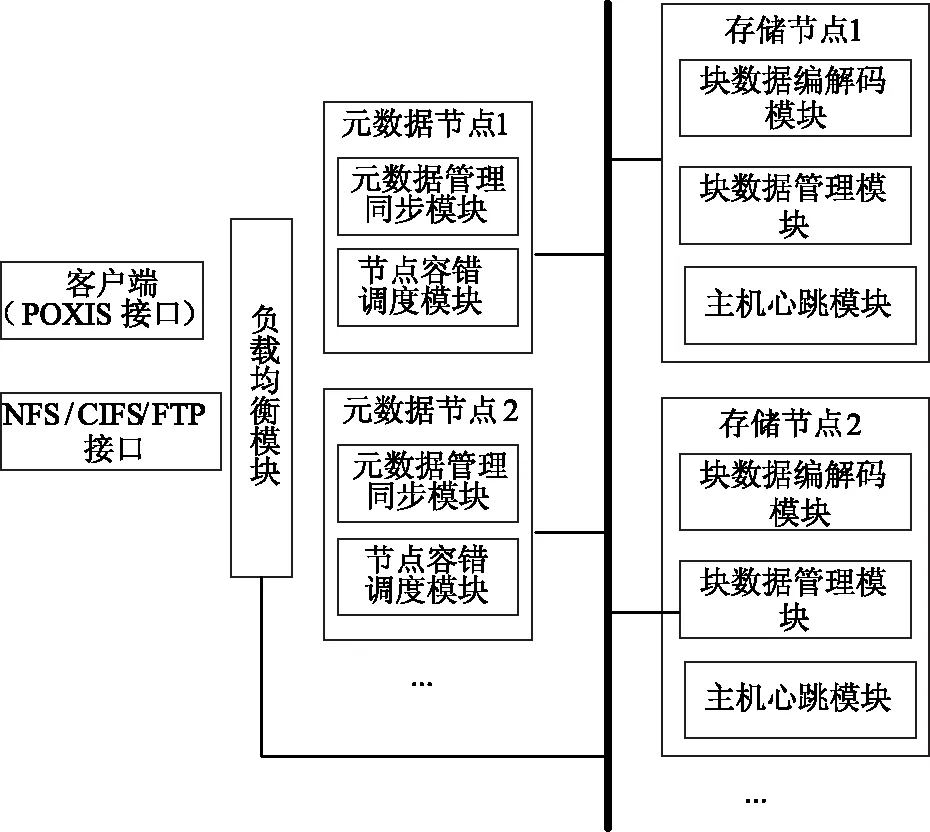
图1 容错系统的模块设计
整个系统根据节点功能整体上分为四部分:元数据节点、块数据存储节点、负载均衡模块以及应用访问接口。
2.2.1 元数据管理同步模块
主备双机模式下,所备元数据节点均处于待激活状态,其配置及运行状态均与主机相同,为维持备机与主机的镜像关系,备机需要通过一致性算法保持与主机元数据信息的同步。
2.2.2 节点容错调度模块
多机热备策略解决了中心节点的单点故障问题,同一时刻有多台管理节点同时运行,但只有一台主机节点对外提供服务,若主机节点失效,立即从备机节点中通过共识策略选举出新的主机节点继续提供服务。
共识策略借鉴了MongoDB的群首选举算法,即Bully算法,可安全地从备机节点中选出新的主机节点。
元数据节点监控模块是元数据节点容错调度模块的一部分,其主要用来监控元数据节点网络以及服务状态,同时也维持与其他元数据节点间心跳,在同一时刻,只有一台主机节点对外提供服务,其他备机节点均处于待激活状态。
2.2.3 存储节点容错模块
系统采用块副本和基于纠删编解码相结合的存储节点容错技术。对于存入系统的数据,其被访问频率满足zipf分布。因此,实时统计该数据的被访问频率,当数据被访问频率很高时,可判断为热点数据,则对其进行块副本存储,并生成多个临时热点副本;当数据被访问频率较低时,可判断为非热点数据,则对其进行基于RS编解码的冗余存储,并删除临时热点副本。
根据分布式文件系统的特点,本模块采用RS编解码技术构造块数据冗余策略,将一个文件划分为M块标准大小的文件数据(不足以0补充),通过巧妙的编码生成N个校验块,将M块原文件分块和N块校验块分别存放于M+N个存储节点上[1]。
%1.5具容错机制的数据访问流程
数据写入过程如图2所示:
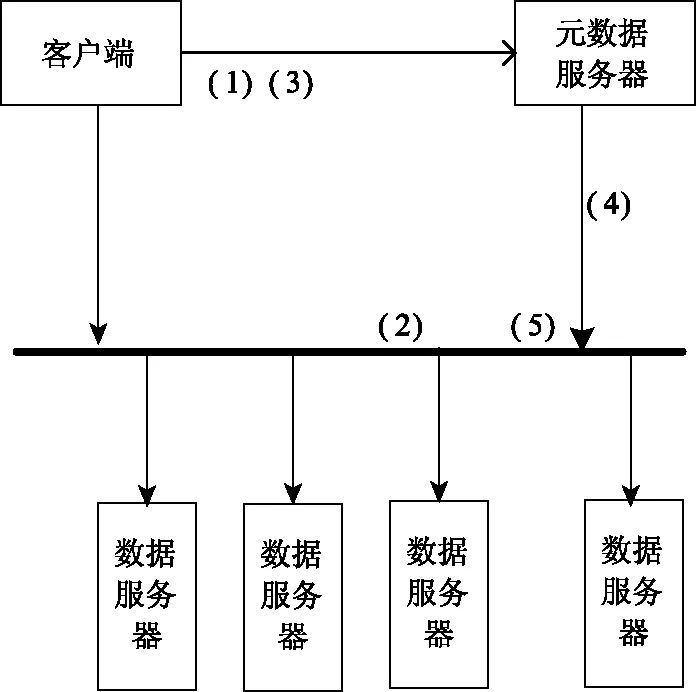
图2 数据写入过程示意图
(1)客户端向元数据服务器请求写入文件数据,元数据服务器返回写入服务器列表;
(2)客户端进行文件切块写入有块数据服务器;
(3)客户端每写入一定量的块数据后,通知元数据服务器,由元数据服务器启动一个编码任务,进行编码;而客户端继续写数据,真到写完成为止;
(4)元数据服务器调度一个或多个块数据服务器进行编码任务;
(5)被调度的块数据服务器,获取需要的原始信息块组进行编码,产生冗余数据块;
数据读出过程如图3所示:
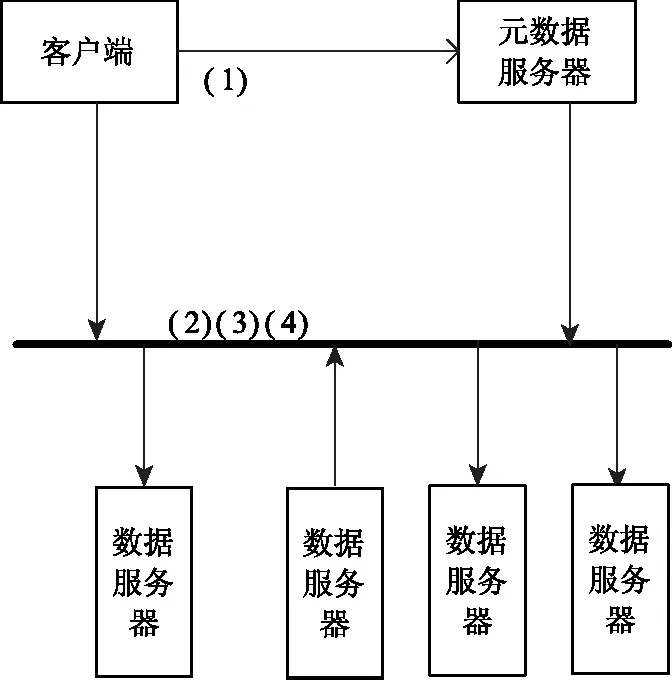
图3 数据读出过程示意图
(1)客户端向元数据服务器请求读出文件数据,元数据服务器返回数据块位置列表;
(2)客户端进行数据块读出;
(3)客户端进行数据块校验;
(4)对未能读出的数据块或无效块通过同编码组内其它数据块进行解码,获得完整正解的文件数据;
元数据自动检测数据块的正确性、完整性,确定数据块损坏无效或丢失后,自动指定相应的存储服务器进行编码或解码恢复相应的数据块,确保数据的冗余容错能够及时恢复重建[1]。
3 可靠性分析
3.1 管理节点容错机制可靠性分析
本文介绍的容错机制中,采用元数据节点多机热备实现管理节点容错,并用元数据自动同步保证主备管理节点能够提供的服务是同步的,我们称之为集中式元数据管理集群。
采用多机热备容错机制的集中式元数据管理集群的可靠性随管理节点的个数增加而增加:当管理节点为两个时,可靠性已达到0.996,;如果增加至三个管理节点,则可靠性几乎为1[1]。由于医疗健康数据的重要性、及时性,直接涉及到人的健康与生命,在实际应用中,建议配置三个管理节点,可在满足一定成本约束的情况下进一步提高可靠性。
3.2 存储节点容错机制可靠性分析
本文介绍的容错策略中,采用了副本容错技术和基于RS编解码算法的容错技术相结合的机制实现了存储节点的容错。
任何一种方式的容错,如果想要提高云存储站点的可靠性,都需要较高的冗余度,耗费很多存储资源。通过将两种容错机制相结合,对文件的编码数据分块进行块副本存储,即能提高云存储站点的可靠性,且不需要太多冗余,节省大量的存储资源[1]。
设云存储站点可靠性为Rstorage,存储节点的可靠性为Rchunk,数据冗余倍数为p。则由大量存储节点组成的云存储站点的可靠性模型为
Rstorage=1-(1-Rchunk)p
(1)
设采用基于RS编解码算法的容错技术的云存储站点的可靠性为RRS,存储节点的可靠性为Rchunk,文件分块数为k,文件编码数据分块数为n,冗余倍数为s(s=n/k)。则采用基于RS编解码算法的容错技术的云存储站点的可靠性模型为
(2)
设采用两种容错机制相结合的云存储站点的可靠性为RcStor,将(1)式带入(2)式,可以得到RcStor的可靠性模型为
(3)
同样,取单个存储节点的可靠性Rchunk=0.9,块副本数p=2,文件分块数k=1~20,文件编码数据分块按照编码冗余倍数s=1~4来编码。已知块副本存储的副本数为2,可以看出采用两种容错机制结合的云存储站点与编码冗余倍数及文件分块数之间的关系。当编码冗余倍数等于1时(即不编码),RcStor随文件分块数增加而降低;当编码冗余倍数大于或等于2时,RcStor随文件分块数增加而增加,当文件分块数达到5块以上时,RcStor大于0.999。但在实际应用中,编码冗余倍数大于1时,RcStor便会随文件分块数增加而增加,且随着编码冗余倍数的增加,RcStor随文件分块数增加而增加的效果越明显。因此综合云存储站点的可靠性和存储空间资源利用率等,块副本存储的副本数取2,编码冗余倍数取1.25,文件分块数为8,即文件编码数据分块为10块,此时云存储站点的可靠性可达到0.9999。
3.3 系统可靠性分析
在医疗健康大数据云存储文件系统中,管理节点和存储节点都非常重要,任何一方面产生数据丢失或数据灾难,都会导致文件系统中的文件丢失,因此云存储文件系统的可靠性,必须同时提高集中式元数据管理集群和云存储站点的可靠性。
本文介绍的容错策略从两个方面提高云存储文件系统的可靠性。一方面采用多机热备机制实现管理节点的数据容错,使集中式元数据管理集群的可靠性超过0.996;另一方面采用副本容错技术和基于RS编解码算法的容错技术相结合的机制实现存储节点的容错,使云存储站点的可靠性达到0.9999,且保证数据的低冗余度。
综上所述,本文介绍的医疗健康大数据云存储文件系统容错优化策略实现的可靠性超过0.996[1]。
4 结 语
医疗健康大数据的云存储文件系统的容错技术是保障医疗健康大数据平台安全可靠、高效运转的重要内容。本文分析了医疗健康大数据的特点,设计了面向医疗健康大数据领域的管理节点容错功能模块和存储节点容错功能模块。通过对元数据的多机热备容错机制及块编解码容错机制的设计,使得系统的容错能力得以大大提升,从而提高了医疗健康大数据容错系统的可靠性和高可用性。最后对其可靠性进行了较深入的分析。本文提出的面向医疗健康大数据文件系统容错策略的优化和实现,对医疗健康大数据存储相关系统的设计及开发提供了有益的参考。
[1] 杨东日,王颖,刘鹏,一种基于副本复制和纠错码融合的文件系统容错机制.《清华大学学报自然科学版》, 2014 (1): 137-144.
[2] 医疗健康大数据:应用实例与系统分析. 《大数据》, 2015, 1(2): 78-89.
[3] 颜延,秦兴彬,樊建平等. 医疗健康大数据研究综述. 科研信息化技术与应用, 2014,5(6): 3-16.
[4] 刘华庆,陈垦. 海峡科技与产业, 2016 (7): 68-69.
[5] Basel Kayyali, David Knott, Steve Van Kuiken. The big-data revolution in US health care: Accelerating value and innovation. McKinsey & Company. April 2013.
[6] F. Martin-Sanchez, K. Verspoor 2,1. Big Data in Medi-cine Is Driving Big Changes. IMIA Yearbook of Medical Informatics. 2014.
[7] Bonnie Feldman, Ellen M. Martin, Tobi Skotnes. Big Data in Healthcare Hype and Hope. Dr. Bonnie 360°. October 2012.
[8] 李国杰. 大数据研究的科学价值,中国计算机学会通讯,2012,8(9).
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
房地产导刊(2022年4期)2022-04-19
曲阜师范大学学报(自然科学版)(2021年3期)2021-08-26
微处理机(2020年5期)2020-10-20
空间科学学报(2020年4期)2020-04-22
传播与制作(2019年9期)2019-10-20
网络安全和信息化(2019年8期)2019-08-28
民用飞机设计与研究(2019年2期)2019-08-05
计算机系统应用(2019年2期)2019-04-10
中山大学学报(自然科学版)(中英文)(2018年4期)2018-08-08
