
基于非稳定过程的岩土体非饱和参数反演分析
2017-03-22 06:47马恒臻刘明明王旭辉
中国农村水利水电 2017年10期
马恒臻,刘明明,陈 君,王旭辉
(1. 武汉大学水资源与水电工程科学国家重点实验室,武汉 430072;2. 武汉大学水工岩石力学教育部重点实验室,武汉 430072)
0 引 言
非饱和渗流问题一直是水利工程、岩土工程、环境工程研究的热点,其在坝体渗流、降雨入渗、浅层地下水污染治理等领域有着广泛的应用[1]。过去几十年中,大量关于非饱和渗流的研究[2-4]主要集中于各种非饱和土体,并且对于非饱和土的持水特征曲线有相对成熟的试验测定技术[6,7]。但对于岩体,由于其结构特征、孔隙和裂隙发育程度不均一,天然性质极其复杂,导致岩体的非饱和水力特性的确定及其非饱和参数的试验测定非常困难。因此,研究岩体非饱和水力参数的确定方法具有重要意义。孙树林等[8]基于岩体微观结构和毛细管理论得到了裂隙孔隙岩体持水特征曲线。王恩志等[9]对裂隙岩体非饱和渗流中应用V-G模型和B-C模型进行评价并建立了改进的本构关系。根据现阶段研究成果,压汞试验可以确定孔隙性岩体的持水特征曲线,但试验过程困难。另外,天然岩体中孔隙、裂隙的发育存在极大的不均匀性和复杂性,小尺度测定技术难以反映现场条件下岩体的非饱和水力特性。
另一方面,在实际工程中,以实测水位为已知信息来确定现场尺度下岩土体渗透特性的反馈分析方法已经有了广泛应用。张乾飞等[10]基于人工神经网络的非线性映射特性提出了大坝渗透系数的反演方法。刘杰等[11]利用水头实测资料,运用遗传算法反演了裂隙岩体渗透系数。上述方法多用于确定渗流场中各岩土介质的饱和渗透系数,而将实测水位信息反馈分析方法用于岩土体非饱和参数确定方面的研究报道较少。
本文在非饱和渗流的框架下,建立了正交设计、非饱和渗流正分析、BP神经网络和遗传算法优化相结合的反演分析方法,确定了基于V-G模型[4]的岩土体持水特征曲线参数。该方法首先以研究区域的水文地质条件为基础,确定待求的岩土体非饱和参数及其合理的变化范围;其次运用正交设计生成样本组,其中每个样本和一组参数组合相对应;然后对每个样本采用非饱和有限元渗流分析来模拟其渗流场的变化过程,得到相应监测点处的计算结果及其变化曲线;进而将各个样本对应的参数组合作为输入,监测点处的水头值作为输出,训练BP神经网络;最后通过训练得到的BP神经网络来预测任意参数组合下的计算值,并以接近监测资料为目标,采用遗传算法获得最佳非饱和参数取值。本文以一次降雨过程中岩质边坡非饱和渗流场的动态变化为例,论证了该方法的可行性和可靠性。
1 非饱和渗流理论及其反问题
1.1 饱和/非饱和渗流数学模型
根据质量守恒定律,可建立岩土体区域Ω内饱和/非饱和渗流的控制方程:
▽·v=0 (inΩ)
(1)
式中:φ=h+z为总水头,h为压力水头,z为垂直坐标;C=∂Se/∂h为容水度,在非饱和区可表示为压力水头h或基质吸力s的函数,在饱和区为零,Se为饱和度;Ss为单位贮存量,在非饱和区为0;β在饱和区等于1,非饱和区等于0。
岩土体中的饱和/非饱和渗流规律可用广义Darcy定律表示:
v=-kr(s)k▽φ
(2)
式中:k为岩土体的饱和渗透张量;kr为相对渗透率,可表示为饱和度Se或基质吸力s的函数。
式(1)的初始条件如下:
φ(x,y,z,t0)=φ0(x,y,z) (inΩ)
(3)
式中:φ0为初始水头场;t0为初始时刻;x和y为坐标分量。
式(1)还应满足如下边界条件:
(1)水头边界条件:

(4)

(2)流量边界条件:
(5)
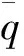
(3)饱和溢出边界条件:
qn=-v·n≤0 且φ=z(onΓs)
(6)
式中:Γs为溢出边界。
(4)非饱和流量边界条件:
且φ (7) 式中:Γuq为非饱和流量边界,包括溢出边界ΓE(如蒸发边界)和降雨入渗边界ΓR。 岩土体饱和度Se与基质吸力s之间的关系称为持水特性曲线。在众多描述持水特征曲线的模型中,V-G模型以其线型与实测数据吻合程度高而得到广泛应用[12],其表达式如下: (9) 式中:θ为岩土体体积含水率;θr、θs为岩土体残余含水率和饱和含水率;α为反映岩体进气值的参数,n为控制曲线斜率的参数,m=1-1/n。四个模型参数中,饱和含水率θs、残余含水率θr与岩土体本身的性质及类型有关,可通过室内或现场试验确定或根据岩土体孔隙率大致确定;而α和n则为经验拟合参数,对非饱和渗流运动有显著的影响[13]。因此,在非饱和渗流反演分析中,经验参数α、n可作为待反演参数,来确定非饱和水力特征参数取值,进而描述非饱和渗流运动规律。 (10) 式中:f1(·)为目标函数;G与R为待反演非饱和参数与降雨数据;φki与φi为监测点i的实测数据与计算数据;‖·‖2与dim(·)分别表示欧几里德范数与向量的维度。 由于采用试算方法确定待反演参数存在效率较低、耗时较长且容易陷入局部最优等问题,本文将正交设计、非饱和渗流正分析、BP神经网络和遗传算法相结合,以保证反演分析的可行性与有效性。反演分析流程图如图1所示。 图1 反演分析方法流程图Fig.1 Flow chart of back-analysis method 正交设计可以在众多的试验方案中安排少量有代表性的方案,采用正交设计科学安排神经网络的训练样本数,可使反演分析计算量大为减少[14]。在实际工程反演问题中,计算规模一般较大,如需进行5水平6因素试验时,若采用全面试验,则要进行56=15 625次有限元正算,计算量巨大,若采用正交设计仅需36次计算即可满足要求。 根据正交设计给出的一系列非饱和参数组合,采用前述非饱和渗流计算方法进行有限元计算,得到各个监测点的水头数据,并以此作为BP神经网络的训练样本。 BP神经网络是按误差逆传播算法训练的多层前馈网络的简称,可以建立输入数据与输出数据之间的隐式映射关系[15,16]。 图2 单隐含层BP网络结构图Fig.2 Structure of a typical single hidden-layer BPNN 图2为单隐含层BP网络结构图,包括一个输入层(Y),一个隐含层(Z)和一个输出层(K),神经网络的输入层参数为岩土体非饱和参数组合和降雨数据,输出层为监测点水头数据。由于样本数据量纲不同,在神经网络训练之前,需对根据下式对输入和输出数据进行归一化预处理。 (11) 式中:pn归一化后的值;p为样本原始值;pmax和pmin分别为样本原始的最大值和最小值。 BP神经网络训练步骤如下: (1)神经网络中给每个连接权值和阈值赋位于区间(-1, 1 )上的随机初始值。 (2)提供训练输入样本和目标输出样本。 (3)随机选取一个输入样本,计算BP神经网络隐含层和输出层各节点的输出值。 (4)根据目标值与输出值之间的偏差,计算反向误差,对权值进行修正。 (5)选取下一个训练样本提供给神经网络,返回步骤(3),直至整个训练样本训练完毕。 (6)重复样本学习,直至神经网络的全局误差E收敛至小于目标误差,此时神经网络训练结束。 遗传算法是一种仿生物全局优化算法,其灵感来自于自然选择和进化过程,可以达到解的优化最大化。该算法克服了传统方法易于陷入局部最优解的缺点,适用于目标函数具有多极值点的优化问题[17]。采用遗传算法能够找到一组监测点水位计算数据与实测数据最为吻合的参数组合,以此作为非饱和参数的最佳反演参数。遗传算法的实施步骤如下: (1)种群初始化。在岩土体非饱和参数的取值范围内,生成一系列随机解,形成初始种群N,并对其进行二进制编码。 (2)适应度函数的设定。本文把目标函数[式(10)]的导数值作为适应度函数,并把耗时的有限元计算用训练好的BP神经网络代替,进而使反演效率大为提高。 (3)选择、交叉和变异。选择操作采用随机遍历抽样的方式选择最优个体,交叉操作采用交叉概率pc对个体进行交叉操作,变异操作使用变异概率pm产生出另外新的变异个体。 (4)循环操作。循环调用选择、交叉和变异操作不断地产生新的种群个体,直至迭代过程收敛,此时的最优个体即为岩土体非饱和参数最佳取值。 以一次降雨过程中岩质边坡非饱和渗流场的动态变化为例,验证上述反演分析方法的有效性和可靠性。计算模型如图3所示,降雨量数据如图4所示,边坡三种岩土材料的饱和渗透系数k、岩土体的饱和含水率θs、残余含水率θr为已知,具体取值见表1。选取三种典型岩土体的α、n值作为材料非饱和参数的真实值。将多年平均降雨量(2 mm/d)对应的稳态渗流场作为初始条件进行非饱和渗流分析。以非饱和渗流正算获得的监测点水头值作为水位观测值。 图3 边坡计算模型(单位:m)Fig.3 Calculation model of the slope 图4 降雨量柱状图Fig.4 Rainfall histogram 编号材料渗透系数/(cm·s-1)θsθrα/m-1真实值取值范围反演值相对误差/%n真实值取值范围反演值相对误差/%Ⅰ覆盖层8.00×10-30.320.060.100.050~5.00.09970.302.31.1~5.02.29590.18Ⅱ强风化岩层2.00×10-40.120.030.050.005~0.50.05000.001.61.1~3.01.59780.14Ⅲ弱风化岩层2.00×10-50.090.020.020.005~0.50.02094.501.41.1~3.01.40930.47 根据典型岩土的α、n真实值确定其可能的取值范围,每个参数选取7个水平,如表2所示,采用正交设计方法安排49种参数组合。对每组方案进行有限元计算,得到各监测点的水位计算值数据。 表2 正交设计和均匀设计水平与因素表Tab.2 Factors and levels of orthogonal and even design 以上述49种非饱和参数组合方案和降雨数据为BP神经网络的输入,以每组方案下监测点的水位变动数据为BP神经网络的输出,得到BP神经网络的学习样本。然后采用均匀设计表U*10(108)[18]构造10组参数组合方案,得到BP神经网络的测试样本。 本文神经网络的训练在MATLAB平台上实现。本文采用的trainlm函数作为神经网络训练函数,采用tansig函数作为神经网络隐含层传递函数,采用purelin函数作为输出层传递函数,以均方误差函数mse作为网络性能函数。神经网络最大训练次数为1 000次,目标误差为0.001。初始的连接权值和阈值设置为默认值,学习率μ= 0.05,动量项系数η= 0.9。输入层设为7个节点,输出层设为4个节点。隐含层神经元根据试凑法确定[19],常用的经验公式为: (12) 式中:z为隐含层节点数;y为输入层节点数;k为输出层节点数,p为1~10之间的整数。上式求得隐含层神经元个数为4~13个。通过试算,最终选用7-12-4神经网络结构,此时测试样本的均方误差最小。图5给出了7-12-4神经网络结构下的误差曲线,由图可知,BP神经网络在第27步达到目标误差,此时的收敛误差为0.000 435 6。 图5 神经网络训练误差曲线Fig.5 Neural network training error curve 根据2.2节所建立的目标函数[式(10)],采用遗传优化算法寻找目标函数的最优解。本例的初始种群N的大小设置为50个,交叉pc和变异pm操作的概率分别为0.9和0.1,进化迭代过程见表3。由表3可见,随迭代次数增加目标函数值不断减小,且反演迭代过程稳定,在迭代步数达到16步时目标函数值仅为4.01 ×10-5,此时反演值与理论值已非常接近,说明本文方法是可行的。 监测点水位与反演计算值对比如图6所示。由图6可知,P1、P2测点位于强风化岩层,水位计算值与观测值几乎吻合,P3、P4测点位于弱风化岩层,监测点水位计算值与观测值之间的误差在0.2 m范围内,表明本文方法是可靠的。 由表1可知,通过上述方法反演得到的三种材料的反演值与真实值极为相近,两者相对误差在5%以内。其中,覆盖层和强风化岩层的反演结果尤为准确,这是由于覆盖层、强风化岩层结构松散,降雨过程中非饱和带水水分运动较快,因此该层的水位变动较大,非饱和参数α、n对降雨量及测点水位信息较为敏感;而弱风化岩层结构相对完整,该层地下水水位相对稳定,受上部降雨影响较小,反演结果有一定误差。 表3 进化迭代过程Tab.3 Evolution iterating process 图6 监测点水位与反演计算值对比图Fig.6 Comparison of the measured and calculated water heads 本文根据监测点水位数据,将正交设计、非饱和渗流正分析、BP神经网络、遗传算法结合,提出了基于非稳定过程的岩土体非饱和参数反演分析方法,并通过算例验证了该反演分析方法的有效性和可靠性,为现场条件下岩土体非饱和参数的确定提供了一种可行方案。 □ [1] 陈佩佩, 白 冰. 非饱和岩土介质渗流问题的光滑粒子法模拟[J]. 岩石力学与工程学报, 2016,35(10):2 124-2 130. [2] Fredlund D G,Xing A Q. Equations for the soil-water characteristic curve[J]. Canadian Geotechnical Journal, 1994,31:521-532. [3] Fredlund D G,Huang X. Prediction the permeability functions for unsaturated soils using the soil-water characteristic curve[J]. Canadian Geotechnical Journal, 1994,31:533-546. [4] Millington R J, Quirk J R. Permeability of porous solids[J]. Trans. Faraday Soc.,196157,(10):1 200-1 207 [5] Van Genuchten M T. A closed equation for predicting the hydraulic conductivity of unsaturated soils[J]. Soil Science Society of America Journal, 1980,44:892-198. [6] 谢定义, 陈正汉. 非饱和土力学特性的理论与测试[C]∥ 土力学及基础工程学会. 非饱和土理论与实践学术研讨会文集. 北京:1992:227-229. [7] 程金茹, 郭择德, 郭大波. 非饱和土壤特性参数获取方法[J]. 水文地质工程地质, 1996,(2):9-13. [8] 孙树林, 王利丰. 非饱和裂隙孔隙岩体持水曲线的预测研究[J].岩石力学与工程学报, 2006,25:3 830-3 834. [9] 王恩志. 裂隙岩体非饱和渗流本构关系[J].岩石力学与工程学报, 2003,22(12):2 037-2 041. [10] 张乾飞, 王 建, 吴中如. 基于人工神经网络的大坝渗透系数分区反演分析[J]. 水电能源科学, 2001,19(4):4-7. [11] 刘 杰, 王 媛. 改进的遗传算法及其在渗流参数反演中的应用[J]. 岩土力学, 2003,24(2):237-241. [12] 徐绍辉, 张佳宝, 刘建立, 等. 表征土壤水分持留曲线的几种模型的适应性研究[J]. 土壤学报, 2002,39(4):498-504. [13] 吴礼舟, 黄润秋. 非饱和土渗流及其参数影响的数值分析[J]. 水文地质工程地质, 2011,38(1):94-98. [14] 陈益峰, 周创兵. 基于正交设计的复杂坝基弹塑性力学参数反演[J]. 岩土力学, 2002,23(4):450-454. [15] 周 喻, 吴顺川, 焦建津,等. 基于BP神经网络的岩土体细观力学参数研究[J]. 岩土力学, 2011,32(12):3 821-3 826. [16] 吴云星, 王士军, 谷艳昌, 等. 基于GA-LMBP神经网络模型的大坝渗流压力预报分析[J].水电能源科学, 2016,34(10):55-59. [17] GOLDBERG D E. Genetic algorithms in search, optimization and machine learning[M]. New York: Addison-Wesley, 1989:1-21. [18] 方开泰. 均匀设计与均匀设计表[M]. 北京: 科学出版社, 1994:69-97. [19] 韩力群. 人工神经网络理论、设计及应用[M]. 北京: 化学出版社, 2007.1.2 非饱和渗流反问题

2 岩土体非饱和参数反演分析方法

2.1 正交设计
2.2 非饱和渗流正分析
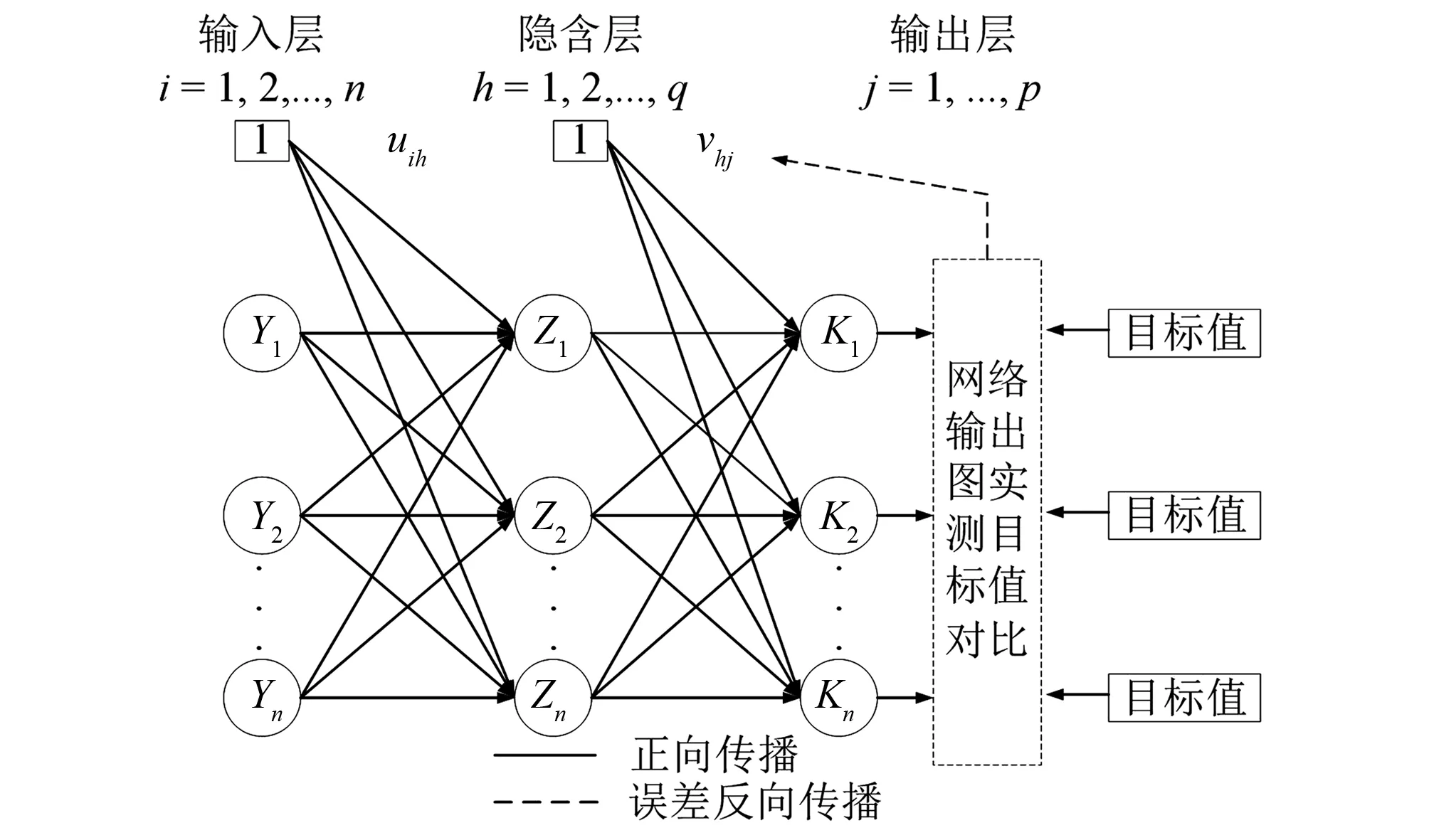
2.3 BP神经网络
2.4 遗传算法
3 算例验证



3.1 正交设计与正分析

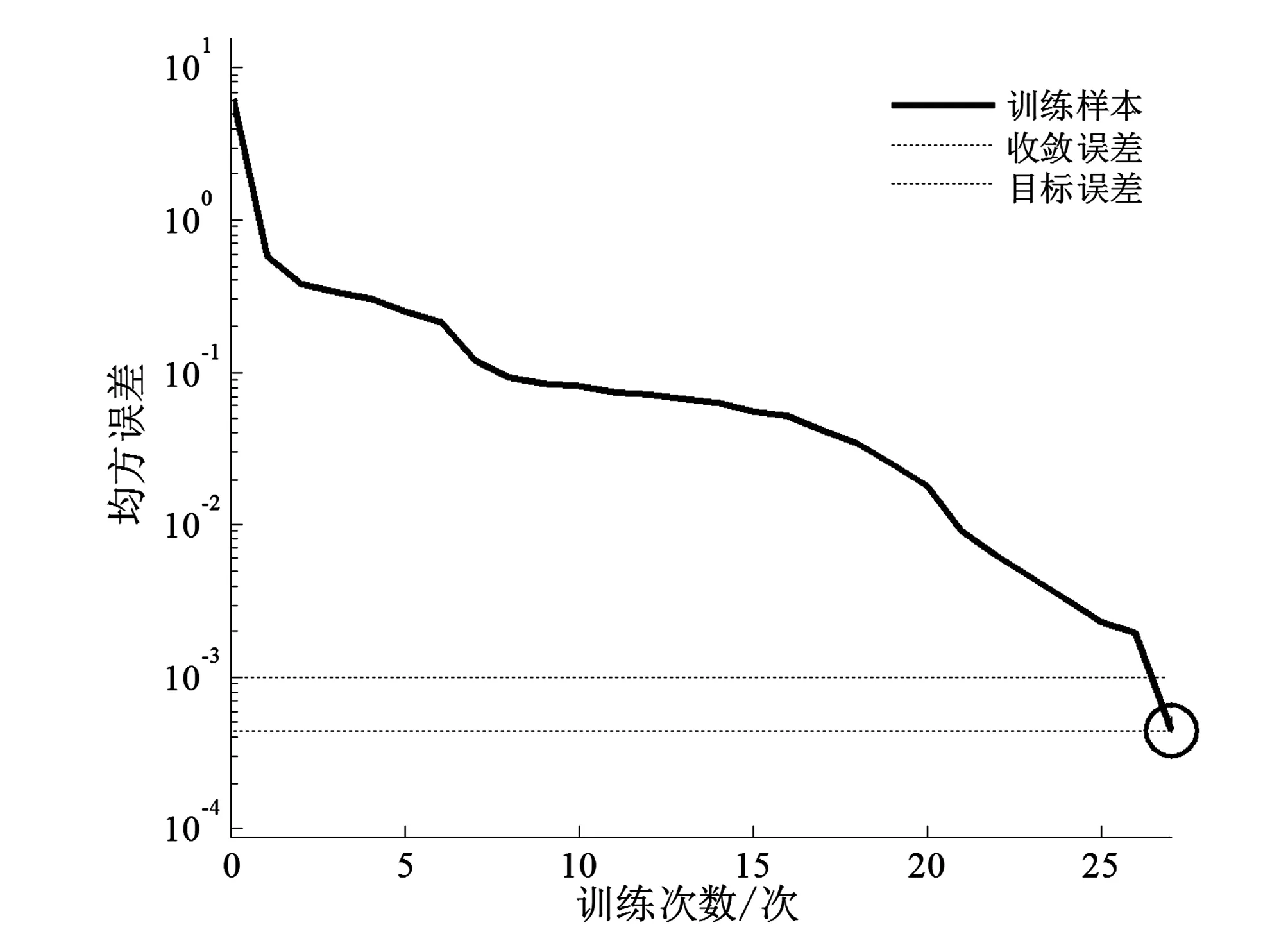
3.2 BP神经网络模型构建
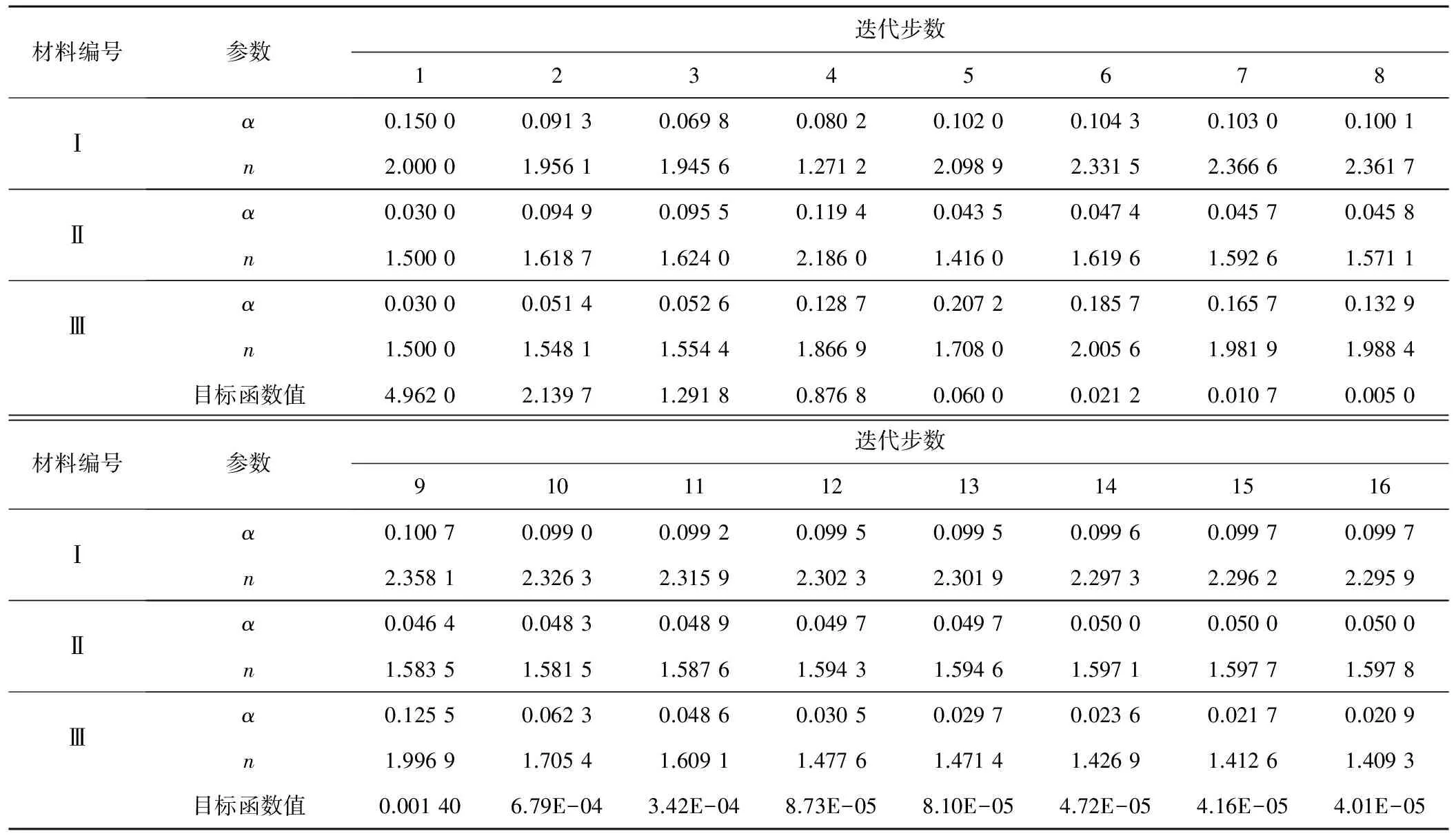
3.3 遗传算法寻优
3.4 反演分析结果

4 结 论
猜你喜欢
中等数学(2022年5期)2022-08-29
特种结构(2022年2期)2022-05-06
成都信息工程大学学报(2021年5期)2021-12-30
空间科学学报(2021年4期)2021-08-30
魅力中国(2020年11期)2020-12-07
中等数学(2020年2期)2020-08-24
水电站设计(2020年4期)2020-07-16
水利规划与设计(2020年1期)2020-05-25
黄河水利职业技术学院学报(2020年1期)2020-04-14
中南大学学报(自然科学版)(2016年2期)2017-01-19
