
随机森林算法在干旱区土地利用遥感分类中的应用研究
2017-03-29 14:09韩燕王玲罗冲
石河子大学学报(自然科学版) 2017年1期
韩燕,王玲,罗冲
(石河子大学理学院地理系,新疆 石河子 832003)
随机森林算法在干旱区土地利用遥感分类中的应用研究
韩燕,王玲*,罗冲
(石河子大学理学院地理系,新疆 石河子 832003)
为了验证随机森林算法在干旱区土地利用遥感分类中的效果,本文采用随机森林算法,结合Landsat8遥感影像以及DEM、NDVI等辅助数据,解译了干旱区典型流域玛纳斯河流域的土地利用图。分析结果表明:(1)分析决策树数量(k)和分类变量数量(m)对分类精度具有很大影响。通过优化2个参数得到最优随机森林模型,当k取103、m取6时,模型分类精度可达95%;(2)通过土地利用分类精度的影响因子分析发现,海拔高程和归一化植被指数对土地利用分类的影响程度比坡向的影响更大。(3)通过分类结果对比分析发现,应用随机森林算法分类的精度比用最大似然法的分类精度高9%,利用变量重要性筛选出的遥感波段构建优化随机森林模型,能有效降低遥感数据源数据量,而Kappa系数保持在0.97不变。随机森林算法可以在干旱区土地利用分类中广泛应用。
遥感,土地利用分类,随机森林,干旱区
土地利用遥感分类是目前进行土地利用变化成因、现状、趋势以及相关研究的主要技术手段[1]。利用遥感影像解译出的土地利用资料克服了传统的土地调查需要大量的人力和财力投入和不能胜任区域土地变更的实时快速更新等诸多问题[2,3]。遥感数据分类与其他学科的分类研究相比具有数据量大、变量多、地表环境复杂等特点。如何利用这些数据高精度提取地表专题信息一直是该领域的研究重点[4-6]。
随机森林算法被誉为目前分类精度最高、最为稳定的分类算法,近十年来在多光谱、高光谱、雷达遥感数据遥感土地覆盖利用分类中表现出优越的性能[7-8]。
Chan等[9]研究了随机森林算法和提升算法在生境分类差异性问题,结果表明这2种集成学习算法在分类精度上差异不大(1%左右),均优于人工神经网络算法的分类结果;在分类时间和分类稳定性方面,随机森林算法则表现较为优越。Vrgaliano等[10-11]在研究区范围较大、生态环境异质性强的区域时,结果显示随机森林在处理数据维度高、类间异质性小、分类类别复杂遥感解译方面表现优良;雷震[12]在国内对随机森林在遥感分类方面的研究缺乏的情况下,对其发展历史和应用前景进行了探讨,指出随机森林作为新兴的分类算法可提高遥感分类的精度;王书玉等[13]运用随机森林算法对洪河湿地影像进行分类,分类总精度和Kappa系数分别为88.31%和0.82,较常用的MLC和CART算法分类的精度有显著提高。
国内对随机机森林算法的分类研究广泛分布于生态、医学、经济等领域内,并表现出良好的性能[14-15]。而在遥感分类领域内随机森林算法对遥感影像土地利用分类的研究并未见完整的报道[16]。
本研究针对随机森林算法在土地利用遥感分类过程中的具体应用进行研究,分析算法参数对分类精度的影响和遥感光谱波段与光谱指数在土地利用分类中的重要程度,以保证分类精度的基础上达到降维的效果,评价随机森林在分类精度上效率,以期利用随机森林算法为干旱区的土地利用分类提供依据。
1 材料与方法
1.1 研究区概况
玛纳斯河流域地处天山北麓中段,准葛尔盆地南缘,是天山北坡最大的绿洲(E85°01′-86°32′,N43°27′-45°21′)。流域内地势从北向南逐渐降低,地貌呈典型的山盆系统结构,依次为山地—山前倾斜平原—沙漠,区域年降水量110-200 mm,年潜在蒸发量1500-2000 mm,雨量稀少,蒸发量大,属于典型的温带大陆性干旱半干旱气候[17]。
受海拔和水资源的影响,流域内林地、草地主要位于山地低山区;大量来自山区的融水流入山前平原区,适宜耕种,在此地区分布有耕地、水库、城市等大量人造景观;距离山区水源较远的古冲积平原,土地利用则主要以沙漠为主[18]。

图1 玛纳斯河流域位置Fig.1 Location of Manasi River Basin
1.2 方法
1.2.1 样本数据获取
利用中国科学院土地利用遥感监测分类系统对研究区的土地利用类型进行划分。从2000年土地利用图中共导出不同土地类型2050个样本数据点,所有样本点经过Google Earth 2013年影像目视验证(表1)。不同地类样本数据按2∶1的比例随机分为2部分,2/3的数据作为实验数据,1/3的数据作为验证数据,用于对比分析中分类精度的计算。
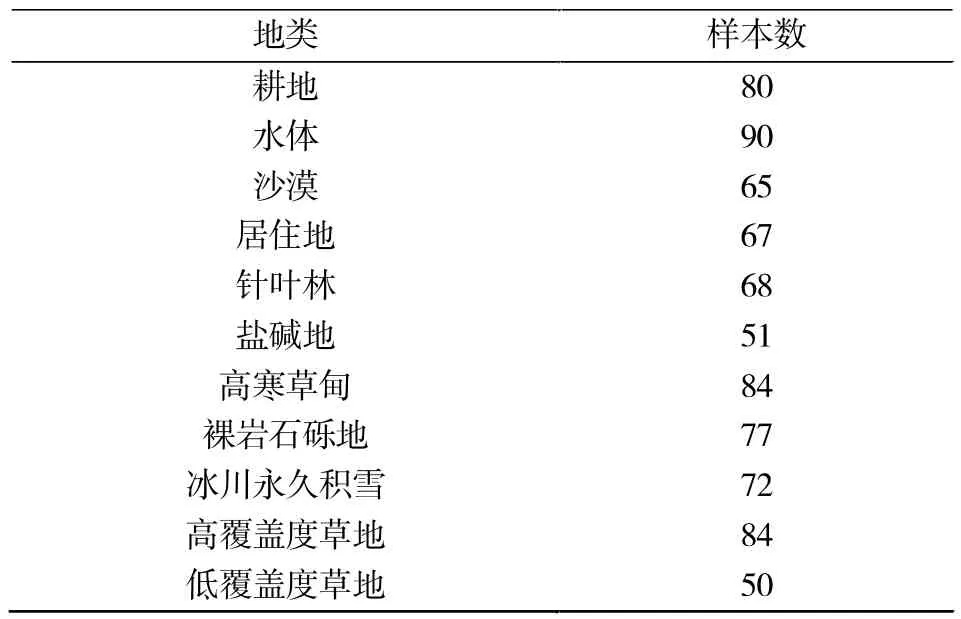
表1 用于随机森林算法的土地覆盖利用类别与样点数目Tab.1 Land-use type and number of sampling points for random forest algorithm
1.2.2 遥感数据的获取与预处理
选择研究区中作物生长旺盛的2013年8月19号的Landsat 8 OLI遥感影像(wrs2条带号144028、144029、144030)为基准影像(来源USGS,http://glovis. usgs.gov/),获取的影像经过辐射校正和基于MODTRAN4+模型的大气校正,裁剪导出玛纳斯河流域影像数据。
1.2.3 遥感指数选取
归一化植被指数(NDVI)作为反映植被信息最重要的指数,被广泛应用于遥感分类领域,尤其是干旱半干旱区因人类活动的影响,不同土地利用下的植被覆盖程度差异很大,故将预处理后的OLI近红外和红外波段求得的NDVI数据作为预测变量加入到研究区的土地利用分类中。
玛纳斯河流域是典型的山盆结构区域,地势起伏大,土地利用大都因地制宜,地形数据的加入可以有效提高海拔和坡度等地形差异明显的地类。地形数据包括30分辨率的SRTM-DEM数据和由其导出地形描述数据——坡度、坡向指数。至此,本研究使用 Landsat 8多光谱波段(7个波段:b1-b7)、NDVI、DEM、坡度(aspect)和坡向(slope)共计 11个波段(以下称作变量)来反演研究区的土地利用状况。本文对遥感影像的所有处理均在软件ENVI5.1中完成。
1.2.4 随机森林算法
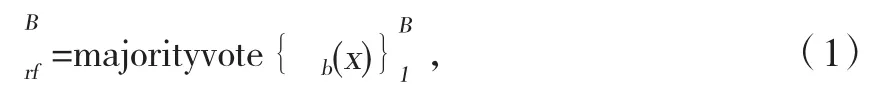
其中,b(x)是第 b个随机分类树的预测值。
随机森林采用基尼指数(GINI Index)来选择最佳分裂属性,对于给定的训练集,基尼指数算法如下:

随机森林的随机性主要体现在两方面[19-20]:
(1)随机选择子样本时,在面对轻微数据变动时其稳定性较高,从而提高分类精度。
(2)算法从属性集中随机选择k个属性,每个树节点分裂时,从这随机的k个属性,选择最优的。这样虽然降低每棵树的强度,也使得树之间的相关性降低,减少了泛化误差。
随机森林算法自提出以来,已经很多的商业和开源软件中包含了该算法,本文使用开源软件R来实现随机森林算法和影像分类,其中的Random Forest程序包可以方便的建立随机森模型,raster程序包可以利用存在的RandomForest模型进行影像分类。
1.2.5 随机森林土地利用分类模型的构建方法
随机森林算法是以大量C&RT为基分类器的集合,其与其他树形分类器最明显的不同之处在于分类时每个节点处,使用给定数目的变量(本文取值范围为1-11)进行分割;该参数在单个数的构建过程中不变,但是具体分类变量是随机选取的。在构建随机森林模型时分类树数量(k)增多能够有效降低泛化误差和避免出现过拟合;变量数目(m)选择则有局限性,一方面过多会在增强单棵决策树能力但会增加决策树之间的相关性,而过少单棵树又会变得太弱。
在构建分类模型的过程中,随机森林利用建成单颗决策树时剩余的袋外数据对该模型分类精度进行评价,即袋外误差(OBB误差)。Rodriguez-Galiano证明使用OBB误差评价分类效果与使用测试数据评价等效,并且OBB误差评估具有无偏性的特点;在处理小数据量分类时,不必考虑验证数据,更具有优势。
考虑到本研究各个土地利用类型的样本容量普遍偏小,本文使用OBB误差作为评价不同分类节点变量数目和决策树数目组合的随机森林模型分类精度的影响的指标。
1.2.6 土地利用分类模型的优化
随机森林算法不仅能高精度的完成土地利用遥感分类,还能评价分类变量对总体和每一种土地利用类型分类的重要程度,一般的分类方法则不能完成关变量对分类结果的重要性计算。变量的重要性分析可以在变量过多的情况下对变量进行降维处理,如高光谱数据和多源数据的分类和信息提取研究中提取重要性较高的变量作为研究的数据来源。
随机森林可以通过2种指标来评价各个变量的重要性。(1)在随机森林树生成的过程中,计算OBB误差和分类投票正确的次数,然后对每个变量的OBB数据进行随机转换,计算此变量变换后的分类正确的次数,用无变换数据的投票次数减去变换后投票正确的次数,然后在除以随机森林总树数,得到变量初始的重要性,除以标准差,就是变量的重要性,用Mean decrease accuracy(MDA)表示;(2)随机森林算法在分类时使用Gini指数来作为分割方式,计算每个变量Gini指数在每个节点的异质性,累加所有树的减少值来表示变量的重要性,用Mean decrease gini(MDG)表示。
2 结果与分析
2.1 随机森林土地利用分类模型的构建
图2为决策树数量逐渐增加,不同m值(最小值、最大值和默认值,也就是1、11、3)下的OBB误差的变化趋势。

图2 决策树的数量(k)和分类节点变量的数量(m)对分类结果的影响Fig.2 Effect of the numbers of trees(k)and the number of variables(m)on OBB errors
对比3种分类节点变量模型下分类树数量(k)对分类精度的影响可以看出随机森林算法只有在决策树汇集成“森林”时,其分类精度才会提高,并且稳定。具体如下:k较小时,分类误差较大,随着k值不断变大,分类误差呈波动式降低,当k值大约到达100时,3个分类器的分类精度趋于稳定,其后的误差平均值分别为9%、6%和7%,之后决策树数量的增加不会对OBB误差造成明显影响,OBB误差趋于稳定。
随机森林模型中k值小时,分类效果不佳;k值大于一定值后,分类精度趋于稳定,较为理想。考虑到随着k值变大,分类器花费的计算时间也不断增多,在保证高分类精度的同时,k值不应过大。
图2中还可以看出在相同k值下,不同分类节点变量数目(m)的分类器的分类精度表现出明显的差异。m取最大值(11)和最小值(1)时,OBB误差均不是最小。可见m值得变化不仅影响单棵树的强度,而且改变了“森林”里树与树之间的相关性。平衡K、m对模型分类的影响是提高土地利用分类精度的关键所在。
分析分类节点变量数目与OBB误差在不同决策树数目组合下的相关性,可见m与分类精度之间的相关性逐渐降低(表2)。k值较小时,分类节点变量数目和分类精度具有高度的负相关性,表明当决策树数目较小时,分类节点变量个数的增加大大增强了单棵树的分类能力,优化了分类效果;随着k的增加,m值与分类精度的相关性很弱,而不同的k值间的相关性则很高。k值增加到分类稳定值(100)后,随机森林对分类节点变量的数量并不敏感,分类精度趋于稳定。

表2 不同决策树数目组合下的分类节点变量数目与OBB误差相关性Tab.2 The correlation between numbers of trees(k) and random spilt variables(m)on OBB errors
由表2可见,随机森林模型的分类精度由分类树数量和分类节点变量数量共同决定,因此最佳分类模型的确定是通过开展不同参数组合的分类精度实验求得。计算得出OBB误差最小值为0.04952,然而最小值所在的参数k小于100,并没有形成稳定的随机森林模型,而第二小值0.05142与0.04952差异很小,故取该位置的参数组合(k=106,m=6)随机森林模型经行探讨。图3是利用随机森林算法反演得到的玛纳斯河流域土地利用分布。

图3 玛纳斯河流域随机森林土地利用分类Fig.3 Random forest land use classification
2.2 土地利用分类模型的优化结果
Mean decrease accuracy是当把一个变量变成随机数时,随机森林预测准确度的降低程度,该值越大表示该变量的重要性就越大。MeanDecreaseGini通过基尼指数计算每个变量对分类树上每个节点的观测值的异质性影响。该值越大表示该变量的重要性越大。
利用2种变量重要性计算方法,根据前文生成的遥感分类模型分析 Landsat OLI多光谱波段、NDVI、和DEM、Slope、Aspect 3个地形数据对总体分类精度的影响(图4)。

图4 不同遥感波段对土地利用总体分类的重要性Fig.4 The importance of different romote sensing bands on the landuse classification
图4a和图4b分别表示基于Gini指数和OBB误差减少下的分类变量对总体分类精度的重要性。对比2幅图发现每个遥感波段在不同测定方法下的变量重要性排序是一致的,表明2种测量手段是等效的。
分析单个波段的变量重要性可以看出:DEM、NDVI和b5(近红外波段)对分类精度的影响最大,MDG指标分别为 141、70和48;MDA指数同样很高,0.43、0.25和0.12。可见受干旱区流域独特的地形结构和自然环境条件影响,地表海拔和植被生长状况对于划分土地利用类别具有很大的帮助。OLI b5-b7波段的变量重要性紧随其后,重要性大小排序为b5>b7>b6;该波段的波谱范围为近红外波段至短波红外波段,而可见光范围深蓝光波段至红波段(b1-b4)对土地利用遥感分类的重要性很低,具体原因仍需后续研究。
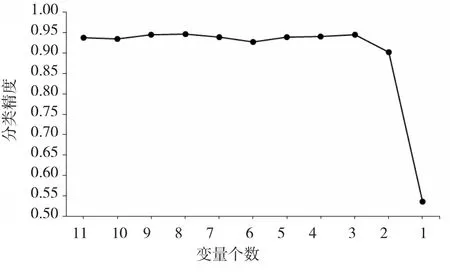
图5 变量减少对基于OBB测定分类精度的影响Fig 5.Effect of variable reduction on classification accuracy based on OBB
图5表示在逐步去除变量重要性最小的变量后,总体分类精度的变化情况。可见,当使用变量个数大于3个(总变量数的30%)时,总体分类精度在94%左右浮动变化,之后急速减少。当预测变量数为8个时,分类精度的最大值为94.67%,结合图4b发现,分类精度最大值是去除了变量重要性最小的3个变量。
2.3 随机森林与最大似然分类精度对比
结合节1.2.5与1.2.6,利用变量选取后分类精度最高的8个分类变量构建随机森林和最大似然分类模型。通过对比最大似然分类算法来判定分类精度的高低是否取决于分类算法的不同。本研究使用软件ENVI默认的ML分类模块完成最大似然算法的土地利用分类和精度评价部分(表3)。
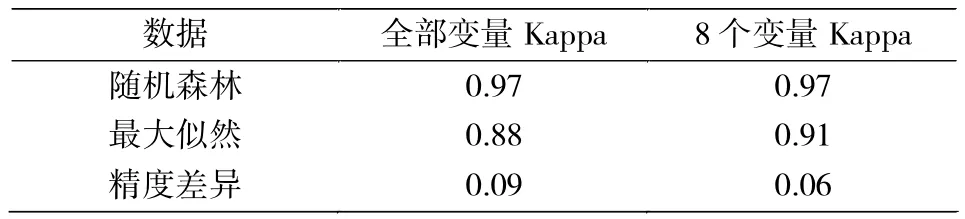
表3 分类精度总体评价Tab.3 Summary of classification accuracies by maximum likelihood and random forest classification
表3显示,利用最大似然算法和随机森林算法获取的全变量和DEM、NDVI等8个分类变量的分类精度的差异,Kappa系数使用验证数据计算。表3可见,随机森林算法的分类精度总是要高于最大似然分类,利用全部变量的分类结果的Kappa系数分别为0.97和0.88,随机森林算法的分类精度显著提高,较最大似然高出9%;考虑到分类精度均已高达85%以上,精度的每一点提升难度很大。当分类变量限于变量重要性最为重要的8个波段时,随机森林的精度保持不变,最大似然分类的精度却有所增加,Kappa系数从0.88变成0.91,提升了3%。最大似然分类精度的差异性大概在于它的参数特性,一些光谱和地形特征数据,例如坡向,在该区域可能并不是正态分布。
3 讨论与结论
本研究的主要目的是探析随机森林算法在干旱区流域尺度上的土地利用分类效用。对于融合了归一化植被指数、DEM、坡度、坡向和OLI遥感影像数据,该算法出色的完成了玛纳斯河流域的土地利用分类。
(1)随机森林算法的分类精度主要受2个参数的影响:决策树的数量(k)与分类变量的数量(m),分析表明,当k<100时,分类树的数量与分类精度有着明显的正相关性,之后分类精度趋于稳定,分类变量轻微的影响分类精度。本研究中,地形数据中的坡向(aspect)和坡度(slope)数据在2种测量方式下的重要性均很低,尤其是坡向数据,对分类精度无影响,因此在的土地利用分类中,可以剔除该变量,达到在分类精度不降低的情况下,减少数据量。
(2)利用随机森林算法可以根据Gini指数和OBB误差对土地利用分类变量(波段)的重要性进行分析,分析表明海拔高程和归一化植被指数对土地利用分类的影响程度较高,光谱波段内红光波段至短红外波段(b4-b7)的重要性要比可见光波段(b1-b4)高。
(3)对比最大似然算法分类结果表明,随机森林算法的分类效果和分类精度表现的均很优秀,两者总体kappa系数分别为0.97和0.88,相差了9个百分点。利用变量重要性筛选出的遥感波段构建优化随机森林模型,其分类精度保持不变,可以利用该方法对数据源降维处理。本研究显示,利用验证样本计算得出的分类精度要比基于袋外数据的分类精度高,其原因可能是验证样本的独立性不能完全确定。随机森林算法比传统的分类算法提供更高的分类精度,通过变量重要性筛选的遥感波段能够有效的剔除多余波段,精简数据源。
本研究只选择了归一化植被指数、DEM、坡度和坡向作为辅助OLI遥感数据分类的增强数据,因此在区分在此类光谱区分性小的类别时可能会有误分和漏分。选择更多的数据是否能提高分类效果,将是下一步工作的重点。本研究可为绘制流域尺度的土地利用分类提供了一个新的方法与参考。
[1]彭建,王仰麟,张源,等.土地利用分类对景观格局指数的影响[J].地理学报,2006,61(2):157-168. Peng J,Wang Y L,Zhang Y,et al.Research on the influence of land use classification on landscape metrics[J].Acta Geographica Sinica,2006,61(2):157-168.
[2]冉有华,李文君,陈贤章.TM图像土地利用分类精度验证与评估——以定西县为例 [J].遥感技术与应用,2003,18 (2):81-86. Ran Y H,Li W J,Chen X Z.Verification and assessment of land use classification by using TM image-taking dingxi County as an example[J].Remote Sensing Technology and Application,2003,18(2):81-86.
[3]赵庚星,李玉环,徐春达.遥感和GIS支持的土地利用动态监测研究——以黄河三角洲垦利县为例 [J].应用生态学报,2000,11(4):573-576. Zhao G X,Li Y H,Xu C D.Land use dynamic monitoring supported by remote sensing and GIS——a case study in Kenli County of Yellow River delta[J].Chinese Journal Ournal of Applied Ecology,2000,11(4):573-576.
[4]黎夏,叶嘉安,廖其芳.利用案例推理(CBR)方法对雷达图像进行土地利用分类[J].遥感学报,2004,8(3):246-253. Li X,Yeh Anthony Gar-On,Liao Q F.Case-based reasoning(CBR)for land use classification using radar images[J]. Journal of Remote Sensing,2004,8(3):246-253.
[5]李恒凯,吴立新,李发帅.面向土地利用分类的HJ-1CCD影像最佳分形波段选择[J].遥感学报,2013,17(6):1572-1586. Li H K,Wu L X,Li F S.Optimal fractal band selection on HJ-1 CCD image for land use classification[J].Journal of Remote Sensing,2013,17(6):1572-1586.
[6]李小文,刘素红.遥感原理与应用[M].北京:科学出版社,2008:104-105.
[7]张雷,王琳琳,张旭东,等.随机森林算法基本思想及其在生态学中的应用——以云南松分布模拟为例 [J].生态学报,2014,34(3):650-659. Zhang L,Wang L L,Zhang X D,et al.The basic principle of random forest and its applications in ecology:a case study ofPinus yunnanensis[J].Acta Ecologica Sinica,2014,34(3):650-659.
[8]Rodriguez-Galiano V F,Chimire B,Roganet J,et al.An assessment of the effectiveness of a random forest classifier for landcover classification[J].ISPRS Journal of Photogrammetry and Remote Sensing,2012,67:93-104.
[9]Chan J C W,Paelinckx D.Evaluation of random forest and adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airbornehyperspectral imagery[J].Remote Sensing of Environment,2008,112(06):2999-3011.
[10]Rodriguez-Galiano V F,Abarca-Hernand Z F,Ghimire B, et al.Incorporating spatial variability measures in landcover classification using random forest[J].Procedia Environmental Sciences,2011,3:44-49.
[11]Rodriguez-Galiano V F,Chica-Olmd M,Abarca-Hernandez F,et al.Random Forest classification of Mediterranean land coverusingmulti-seasonal imagery and multi-seasonal texture[J].Remote Sensing of Environment,2012,121:93-107.
[12]雷震.随机森林及其在遥感影像处理中应用研究[D].上海:上海交通大学,2012.
[13]王书玉,张羽威,于振华.基于随机森林的洪河湿地遥感影像分类研究[J].测绘与空间地理信息,2014,37(4):83-85, 93. Wang S Y,Zhang Y W,Yu Z H.Classification of Honghe Wetland remote sensing image based on random forests[J]. Geomatics& Spatial In for Mation Technology,2014,37 (4):83-85,93.
[14]李欣海.随机森林模型在分类与回归分析中的应用[J].应用昆虫学报,2013,50(4):1190-1197. Li X H.Using“random forest”for classification and regression[J].Chinese Journal of Applied Entomology,2013,50 (4):1190-1197.
[15]韩玉,施海龙,曲波,等.随机森林方法在医学中的应用[J].中国预防医学杂志,2014,15(1):79-81. Han Y,Shi H L,Qu B,et al.Random forests application in medicine[J].Chin Prev Med,2014,15(1):79-81.
[16]李旭青,刘湘南,刘美玲,等.水稻冠层氮素含量光谱反演的随机森林算法及区域应用[J].遥感学报,2014,18(4):923 -945. Li X Q,Liu X N,Liu M L,et al.Random forest algorithm and regional applications of spectral inversion model for estimating canopy nitrogen concentration in rice[J].Journal of Remote Sensing,2014,18(4):923-945.
[17]封玲.玛纳斯河流域农业开发与生态环境变迁研究[M].北京市:中国农业出版社,2006:1-3.
[18]程维明,周成虎,刘海江,等.玛纳斯河流域50年绿洲扩张及生态环境演变研究[J].中国科学(D辑:地球科学),2005,35(11):1074-1086. Chen W M,Zhou C H,Liu H J,et al.Manas river valley oasis expansion and ecological environment evolution research 50 years[J].Science in China(series D),2005,35(11): 1074-1086.
[19]Liaw A,Wiener M,Classification and regression by random Forest[J].R News,2002,2(3),18-22.
[20]Genuer,R.,et al.Variable selection using random forests[J]. Pattern Recognition Letters,2010,31(14):2225-2236.
Application of random forest algorithm in the remote sensing classification of land use in arid region
Han Yan,Wang Ling*,Luo Chong
(College of Science of Shihezi University,Shihezi,Xinjiang 832003,China)
The aim of this resesearch is to test the random forest algorithm in the remote sensing classification in arid area. The land use map of the Manasi River Basin,a typical watershed in arid area,had been interpreted using this method based on Landsat 8,DEM and NDVI data.The results show that:(1)both the number of decision trees(k)and the number of classification variables(m)have effect on the classification accuracy.When k,m are 103,6,respectively,the classification accuracy reaches 95%;(2)through the comparative analysis,DEM and NDVI have more influence on the classification accuracy than the slope;(3)Based on the results of classification,the random forest algorithm accuracy is higher than 9%with the maximum likelihood method..The random forest algorithm could reduce data redundancy and keep the accuracy with 0.97 of Kappa coefficient.The method could be applied in land use classification of remote sensing in the arid area.
Remote sensing,land use classification,random forests algorithm,arid areas
F323.211;TP301.6
A
10.13880/j.cnki.65-1174/n.2017.01.016
1007-7383(2017)01-0095-07
2016-10-17
国家自然科学基金项目(41361073)
韩燕(1981-),女,硕士研究生,专业方向为遥感影像信息提取和土壤盐渍化成因,e-mail:66720287@qq.com。
*通信作者:王玲(1974-),女,教授,从事遥感与地理信息系统应用方面研究,e-mail:rain_ling@163.com。
猜你喜欢
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
电子制作(2018年2期)2018-04-18
自然资源情报(2017年4期)2017-11-26
制导与引信(2017年3期)2017-11-02
高师理科学刊(2016年8期)2016-06-15
测绘科学与工程(2016年5期)2016-04-17
中国老区建设(2016年8期)2016-02-28
西藏科技(2015年4期)2015-09-26
电子设计工程(2015年3期)2015-02-27
