
基于Adaboost算法与规则匹配的垃圾评论识别
2017-04-07 01:30昝红英毕银龙石金铭
郑州大学学报(理学版) 2017年1期
昝红英, 毕银龙, 石金铭
(郑州大学 信息工程学院 河南 郑州 450001)
基于Adaboost算法与规则匹配的垃圾评论识别
昝红英, 毕银龙, 石金铭
(郑州大学 信息工程学院 河南 郑州 450001)
从评论的文本特征及元数据特征两个角度提取特征,避免特征向量过于稀疏.提出了基于随机森林的Adaboost算法,以减弱商品评论数据集不平衡性的影响.部分垃圾评论特征比较显著,采用规则匹配进一步提高垃圾评论识别的召回率.通过在COAE2015任务4提供的数据集上进行实验,取得较好的识别效果,验证了所提方法的有效性.
垃圾评论识别; 随机森林; Adaboost; 集成学习算法
0 引言
近年来,随着电子商务在我国的蓬勃发展,越来越多的人倾向于网上购买商品或服务,同时消费者还可以对所购买的商品或服务发表相关评论,供有购买意愿的顾客作为参考.然而,在这些大量的评论中,往往存在一些与商品无关的评论、不真实的评论或者广告等垃圾评论,这些垃圾评论不仅容易误导消费者的购买行为,损害消费者的利益,而且扰乱了网络环境的正常秩序,严重影响了网络市场的正常竞争.因此,识别出这些垃圾评论对正确引导消费者的购买行为及净化网络环境具有十分重要的意义.
目前关于垃圾评论的识别技术主要是使用分类算法对评论进行分类,将评论分为垃圾评论、正常评论.Liu等[1]从评论、评论人、商品3个角度提取特征项,使用逻辑回归模型对只涉及商品品牌的垃圾评论及非评论的无关文本进行识别.李霄等[2]从评论、评论者、被评论商品3个方面提取特征,并进行不同特征组合的优化,最终使用SVM分类模型取得较好的识别效果.游贵荣等[3]从产品评论的评价句数量、主题词、情感倾向、文本结构和作者属性5个方面提取特征项,使用SVM分类模型对评论进行二分类.何珑等[4]针对评论数据集的不平衡性,采用平衡随机森林和加权随机森林的算法来有效减弱不平衡数据集的影响,显著提高了产品垃圾评论的识别精度.
文献[1-3]虽从多角度提取特征项,但未考虑评论数据集的不平衡性对分类效果的影响.本文在参考文献[4-8]的基础上,从评论的文本特征及元数据特征[9]两个角度提取特征项,采用随机森林与Adaboost相结合方法,对评论进行初步分类.由于部分垃圾评论特征比较显著,本文在初步分类的基础上,对评论文本进行基于规则的过滤,进一步提高垃圾评论识别的召回率.
对于垃圾评论,本文主要考虑以下几种类型:1) 只涉及对商品品牌的评论;2) 错评类评论;3) 广告类评论;4) 非评论的无关文本.其中,非评论的无关文本主要包括:个人消费经历、涉及对他人的人身攻击及其他无关文本.
1 预处理
由于网络评论在文本内容上存在不规范,尤其是某些垃圾评论往往还包含有超链接、手机号、QQ号等.在对评论文本进行分词前,针对评论中存在的不规范问题,本文进行以下处理:1) 将评论中存在的繁体字均转为简体字;2) 大写字母转为小写字母;3) 将多余的空格去除,以免分词错误;4) 对于评论中存在的URL超链接、手机号、QQ号,使用正则表达式来匹配并进行去除.
2 特征项提取
垃圾评论识别的实质是对评论进行二分类,将评论分为垃圾评论、正常评论.因此,通过选取比较具有类别区分性的特征来向量化表示评论文本对识别垃圾评论至关重要.本文从评论文本的语义特征、非语义特征、及评论的元数据特征出发提取特征项:对于评论文本共提取8个特征项,包括主题词、评论词、网络低俗词、广告词、长度、是否为重复评论、是否错评、以及是否包含URL、电话号码、QQ号码、微信号等;对于评论的元数据特征,本文将评论人的打分及评论的有用性得票数作为特征项.
2.1 语义特征项
2.1.1 主题词
高质量的、有用的、好的评论定义为:能具体描述商品的特征、性能等信息,辅助潜在用户做出适当决策的评论[9].因此,一条正常评论中一般应该包括与评价主体相关的属性名词,例如一条有关宾馆的正常评论,“地理位置比较好,卫生质量不太行,周边环境也不错,卫生有待提高”就包括3个与宾馆相关的属性名词:“地理位置”、“卫生质量”、“周边环境”.
本文将数据集中的3个评价领域:手机(phone)、宾馆(hotel)、餐馆(restaurant)分别视为3个不同的主题,则与评价领域内所有评价主体相关的属性名词即为构成对应主题的主题词.这些主题词一般都具有较强的领域相关性,因此,本文通过从网络上抓取与评价主体相关的大量评论,通过分词、词性标注来筛选与评价主体相关的主题词,这些主题词主要是评论文本中的名词或名词短语,来构建相应的主题词集合.部分样例如表1所示.

表1 “主题词”样例
对于与评价主体无关或只涉及品牌的垃圾评论,一般则很少包含有对应领域的主题词,故本文通过计算一条评论中所包含的主题词的比例作为识别该类垃圾评论的特征项.
2.1.2 评价词
一条正常的评论除了要包括与评价对象相关的属性名词外,一般还应包含有针对该属性名词的评价词.例如一条有关手机的正常评论,“非常的划算,屏幕很大,速度也很快,配置不错”中的“大”、“快”、“不错”分别来修饰属性“屏幕”、“速度”、“配置”;而另一条针对手机的评论,“好用,实惠,给力,耐用”虽未明显指出所评价的属性,但不难理解,该评论实际上指的是手机的功能比较“好用”、价格“实惠”且手机的质量好,比较“耐用”.因此,通过计算一条评论中所包含的评价词比例,对于识别无关评论有重要意义.本文通过抽取所抓取评论语料中紧邻评价属性的形容词来构建对应主题的评价词集合.
2.1.3 网络低俗词
针对部分涉及人身攻击的垃圾评论通常具有比较显著的特征,即含有若干网络低俗用语,例如“以后谁他妈再评论这个是好的谁就是傻逼”中的“他妈”、“傻逼”.针对这类垃圾评论,本文收集并整理了共123个网络低俗词,部分样例如表2所示.
本文将该类词语加入分词工具的自定义词典中以避免分词错误.在本文中,如果一条评论包含低俗词,则在该属性上取值为1,否则为0.
2.1.4 广告词
对于广告类的垃圾评论一般都包含一些比较明显的关键词,例如一条广告类的垃圾评论:“红红火火,火锅城,开业大酬宾,满100返20,酒水半价”,其中就包含与商业广告非常相关的关键词:“大酬宾”、“满”、“返”,这些关键词对广告类垃圾评论的识别非常重要,故本文将一条评论中广告词的比例作为特征项.本文共提取整理广告词236个,部分样例如表3所示.

表2 “网络低俗词”样例

表3 “广告词”样例
2.1.5 评论重复度
由于一些网站中会限制评论的最短评论长度,所以一些用户为了满足该条件,会把评论重复复制粘贴.因此,通过计算单条评论的重复度可以有效识别该类垃圾评论,评论重复度=评论包含的字数/评论汉字集合的大小.
例如,对于垃圾评论“十五字十五字十五字十五字十五字”,评论包含字数为15,评论的汉字集合为{十,五,字},集合大小为3,故其评论重复度为5.
2.2 非语义特征项
2.2.1 超链接、电话、QQ、微信号
一般广告类的垃圾评论主要以获取商业利益为主要目的,所以该类评论中不仅含有比较明显关键词,而且在评论的最后一般还留有URL超链接、电话号码、QQ号、微信号.例如“[淘宝] QCY尖叫7款新意色终于来了,现0.01元订金火热预订中:http://t.cn/RZkZkqG”、“积分充值:只要给我提供您的7天会员帐号、姓名即可充值.2000积分60元.详情qq230658723”、“有意想提前入住的请联系132887247263”.本文通过构造正则表达式来检验一条评论中是否存在该类信息,如果一条评论存在该类信息则该属性取值为1,否则为0.
2.2.2 是否为重复评论
有些垃圾评论直接来自于上一条垃圾评论的复制粘贴,尤其是某些广告类评论为增加用户的见面率,通常被重复发表.故本文检验数据集中每条评论是否存在重复,如果数据集中存在相同评论,则该属性取值为1,否则为0.
2.2.3 是否存在错评
对于存在错评的一类垃圾评论,本文根据评价对象所属的不同领域,获取其评价对象所属领域的所有品牌,根据此判断评论中是否包含非当前品牌的品牌名称.包含时值为1,不包含时值为0.
2.2.4 评论长度
针对不同领域的评论,本文进一步考虑评论文本长度特征,将其作为分类时的特征项.本文在该特征项上的取值为当前评论经过预处理后不同词语的数量,这样在考察正常评论与垃圾评论的长度在整体上差异性的同时,还可以进一步结合“评论重复度”特征项来有效识别直接通过复制粘贴操作形成的垃圾评论,例如“很好,不错,很好,不错,很好,不错,很好”.
2.3 评论的元特征项
本文在提取特征项时,在考虑以上文本特征即语义特征、非语义特征的同时,进一步考虑评论的元数据特征,从评论者的角度考察垃圾评论、正常评论的差异性.
2.3.1 评论者的打分
评论者在购买商品或服务后,除了可以发表评论外,还可以根据自己的满意程度对商品或服务进行打分,取值从1到5.对于部分垃圾评论,尤其是涉及人身攻击类的垃圾评论,例如“今天吃饭真你妈憋屈旁边喝酒的真是傻逼”,评论者的打分通常较低,所以在提取特征项时,本文将评论者的打分考虑在内.
2.3.2 评论的有用性得票数
评论的有用性得票数即来自其他评论者对于该条评论是否有用的标记计数,一般的垃圾评论,由于其评论质量较低,一般很难得到其他评论者的认可,因此其有用性得票数较低,而正常评论则偏高.
3 基于随机森林的Adaboost算法
随机森林(RF,random forest)是由Breiman[10]于2001年提出的一种组合分类器算法.该算法采用bootstrap[11]重采样方法从原始样本中抽取多个样本,对每个bootstrap样本单独进行决策树建模,然后组合多棵决策树的预测,即让所有决策树参加投票,通过投票得出最终的预测结果.
Adaboost算法是1995年由Freund和Schapire提出的一种提升算法[12].该算法从弱分类算法出发,通过反复迭代,得到一系列的弱分类器,然后组合这些弱分类器构建一个最终的强分类器.在每次迭代过程中,不断更改训练样本的权值分布,使下一次迭代更关注被分错的样本,并根据分类效果,赋予每个基分类器权重.
在垃圾短信的识别过程中,本文采用随机森林与Adaboost算法相结合的方法.实验结果表明,该方法取得较好的识别效果.具体算法描述如下:
对于训练集D={(x1,y1),(x2,y2),…,(xi,yi),…,(xN,yN)},其中,xi∈Rn为短信实例,yi∈{1,0}为类标记,1表示垃圾短信,0表示正常短信.
步骤1:初始化训练样本的权值分布,w1=(w11,w12,…,w1i,…,w1N),其中,w1i=1/N.
步骤2:使用随机森林算法进行K次迭代,对k=1,2,3,…,K:
1) 采用bootstrap重采样方法,随机生成M个训练子集D1,D2,…,Dj,…,DM;
2) 根据每个训练子集Dj,生成对应的决策树预测模型Tj.其中,在每棵决策树的非叶子节点上进行分裂时,从当前子集的所有特征中随机选取部分特征作为候选特征集,然后根据基尼指数(GINI)从候选特征集中选出最佳分裂点;
3) 由于训练样本及特征选择的随机性,每棵树均完整生长,不进行剪枝;
4) 将本次迭代产生的M个决策树模型Tj组合生成随机森林预测模型Mk;
5) 根据Mk在当前训练集D上的分类效果,赋予Mk权重,并更新训练样本的权值分布.
步骤3:将K次迭代产生的预测模型序列M1,M2,…,Mk,…,MK进行线性组合,构成最终的预测模型M=α1M1+α2M2+…+αkMk+…+αKMK,其中:αk为基分类器Mk的权重.
4 实验结果及分析
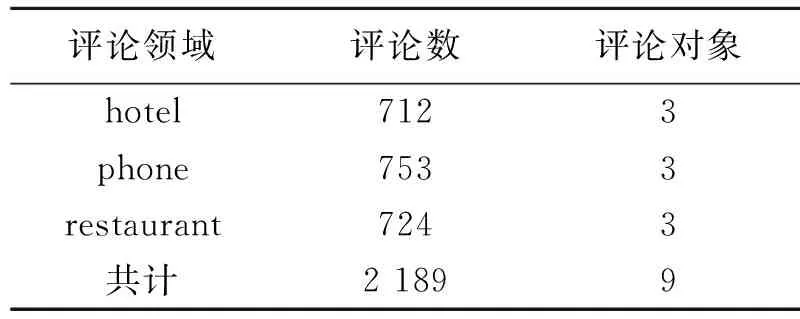
表4 实验数据集
本文使用COAE2015任务4提供的公开数据集作为实验数据,该数据集共包括3个评价领域:宾馆(hotel)、手机(phone)、餐馆(restaurant),每个评价领域包括3个评价对象,具体规模如表4所示.
本文使用weka作为实验平台,采用十折交叉验证的方法进行实验,以精确率、召回率、F值、准确率作为评价指标,整个评价领域采用微平均(Micro-average)作为评价指标.
本文共设计了两组实验,实验结果如表5所示,其中:Result_0是本文采用基于随机森林的Adaboost算法的实验结果,Result_1是在Result_0的基础上进一步使用规则过滤的结果.
由于部分垃圾评论的特征较为显著,故本文在使用基于随机森林的Adaboost算法的基础上,进一步使用规则进行过滤,将凡包含网络低俗词、广告词、URL、电话、QQ号等及存在重复、存在错评的评论均视为垃圾评论.实验结果如Result_1所示.
由Result_1可知,经过规则过滤,实验的各项指标得到进一步提高,尤其是整体的召回率、准确率得到较大提升,实验的整体识别效果在召回率、F值、准确率方面均高于result_0,由此证明本文提出规则的有效性.但是本文在识别垃圾评论的精确率方面偏低,且在phone类的识别效果不及hotel,restaurant.所以在未来的工作中,将考虑如何提高垃圾评论的识别精确度及改善phone类垃圾评论的识别效果.
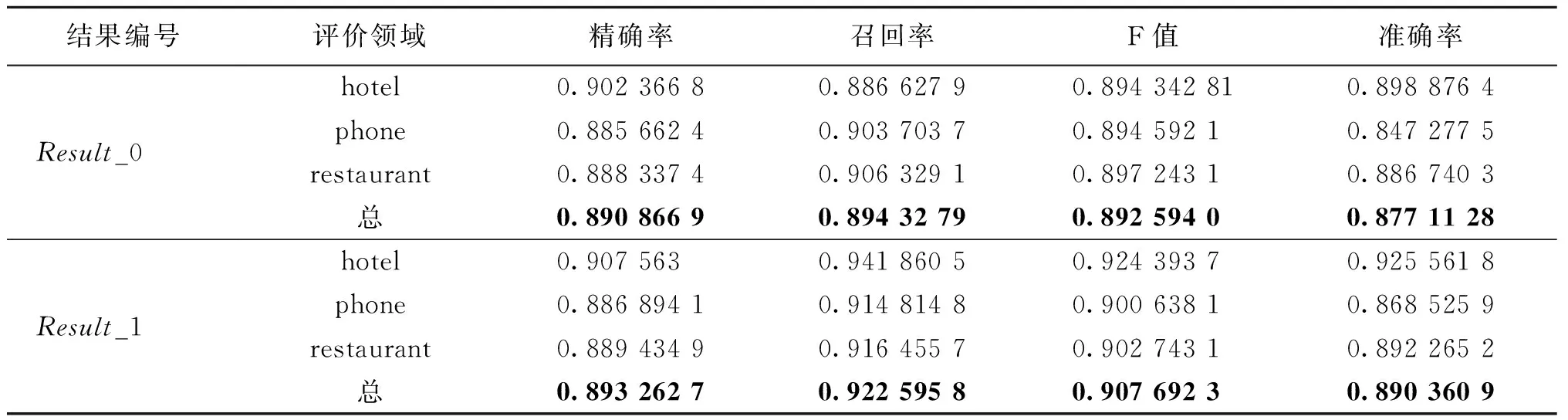
表5 垃圾评论识别的实验结果
[1] JINDAL N, LIU B. Opinion spam and analysis[C]//Proceedings of First ACM International Conference on Web Search and Data Mining. California:Stanford, 2008:219-230.
[2] 李霄,丁晟春.垃圾商品评论信息的识别研究[J]. 现代图书情报技术,2013,29(1):63-68.
[3] 游贵荣,吴为,钱沄涛. 电子商务中垃圾评论检测的特征提取方法[J]. 现代图书情报技术,2014, 30(10):93-100.
[4] 何珑. 基于随机森林的产品垃圾评论识别[J]. 中文信息学报, 2015, 29(3):150-154.
[5] 杨赫. 垃圾微博信息过滤技术的研究[D]. 哈尔滨:哈尔滨理工大学, 2015.
[6] 杨凯帆. 微博垃圾信息检测[D]. 安徽:中国科学技术大学, 2015.
[7] 黄铃,李学明. 基于AdaBoost的微博垃圾评论识别方法[J]. 计算机应用, 2013,33(12) :3563-3566.
[8] DEBARR D, WECHSLER H. Spam detection using random boost[J]. Pattern recognition letters, 2012, 33(10):1237-1244.
[9] 林煜明,王晓玲,朱涛,等. 用户评论的质量检测与控制研究综述[J]. 软件学报,2014,25(3):506-527.
[10]BREIMAN L. Random F [J]. Machine learning, 2001, 45(1):5-32.
[11]EFRON B, TIBSHIRANI R J. An introductin to the bootstrap[J]. Journal of great lakes research, 1993, 20(1):1-6.
[12]FREUND Y, SCHAPIRE R E. A decision-theoretic generalization of on-line learning and an application to boosting[C]// European Conference on Computational Learning Theory. Berlin, 1995:119-139.
(责任编辑:王海科)
Spam Review Identification Based on Adaboost Algorithm and Rules Matching
ZAN Hongying, BI Yinlong, SHI Jinming
(SchoolofInformationEngineering,ZhengzhouUniversity,Zhengzhou450001,China)
Features were extracted from both the text content and meta data of reviews to avoid feature vectors being sparse. Adaboost based on random forest was proposed to reduce the influence of unbalanced product review data set. Because of the very obvious characteristics of some spam reviews, rule matching was applied to further improve the recall rate. The experimental results on the data set provided by COAE2015 task 4 showed that the proposed method was effective.
identification of spam reviews; random forest; Adaboost; ensemble learning algorithm
2016-12-10
国家自然科学基金项目(61402419);国家社会科学基金项目(14BYY096);国家重点基础研究发展项目(973计划)(2014CB340504);河南科技厅基础研究项目(142300410231,142300410308);河南省高等学校重点科研项目(15A520098).
昝红英(1966—),女,河南焦作人,教授,主要从事自然语言处理研究,E-mail:iehyzan@zzu.edu.cn;通讯作者:毕银龙(1990—),男,河南周口人,硕士研究生,主要从事短文本分类算法研究,E-mail:zzubylong@gs.zzu.edu.cn.
TP391
A
1671-6841(2017)01-0024-05
10.13705/j.issn.1671-6841.2016310
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
科普童话·学霸日记(2021年2期)2021-09-05
实用医药杂志(2021年4期)2021-01-11
中国医学计算机成像杂志(2020年6期)2020-03-14
当代陕西(2019年24期)2020-01-18
当代陕西(2019年10期)2019-06-03
小太阳画报(2018年10期)2018-05-14
档案管理(2014年6期)2014-10-30
阅读(中年级)(2009年11期)2009-04-14
