
海量数据机器单词中关键语义筛选方法研究
2017-04-10 20:38渠新峰
现代电子技术 2017年6期
渠新峰

摘 要: 为了提高机器单词翻译的准确性,需要进行关键语义筛选和特征提取,故提出一种基于主题词表自然语义信息抽取的海量数据机器单词中关键语义筛选方法。首先构建海量数据机器单词的文本语义主题词概念决策树模型,采用语义信息转换方式计算机器单词中关键语义的利用规则、聚类中心等信息参量;然后采用主题词表自然语义信息抽取方法进行语义评估和翻译可靠性测试,实现关键语义自动筛选控制;最后进行仿真测试。结果表明,采用该方法进行机器单词中关键语义筛选, 提高了文本机器翻译的自适应配准能力,翻译的准确性得到有效提高。
关键词: 海量数据; 机器翻译; 单词; 语义筛选
中图分类号: TN911?34; TP391.1 文献标识码: A 文章编号: 1004?373X(2017)06?0018?03
Abstract: In order to improve the accuracy of machine translation of words, the key semantic screening and feature extraction are needed. Because of this, a method of the key semantic screening of the massive data machine words based on thesaurus natural semantic information extraction is proposed. The thesaurus concept semantic decision tree model of the massive data machine words is build. The semantic information conversion mode is used to calculated the key semantic utilization rules of machine words and the information parameters of clustering center. The thesaurus natural semantic information extraction method is adopted to conduct semantic translation evaluation and reliability testing for realization of the automatic control of key semantic selection. The simulation test results show that the method has improved the adaptive ability of the text machine translation, and the accuracy of the translation effectively.
Keywords: massive data; machine translation; word; semantic screening
0 引 言
在大數据信息时代,需要采用机器翻译处理大量的文字数据信息,为了提高对海量文本数据的机器翻译的准确性,需要对机器单词的关键语义进行准确的特征筛选,把握机器单词的关键信息,提高对机器翻译的面向对象性和人机交互能力。机器翻译模型分为三个层次,分别为局部语义聚类[1?2]、语义情感分析[3]和表现模型。其中数据模型提供机器单词翻译的数据来源,作为原始语言的文本输入,通过与翻译对象的某个领域相关的数据集合分类,进行程序控制,实现领域本体模型构建;基于语义度量的RDF图近似查询[4],在语义模型中形成机器翻译的概念汇聚点,根据语义集合概念之间的上下层关系,进行语义转换和信息抽取实现语义筛选后的机器翻译输出。本文针对当前的关键语义筛选方法的控制性不好和准确性不好的问题,提出基于主题词表自然语义信息抽取的海量数据机器单词中关键语义筛选方法。
1 海量数据机器单词的文本语义主题词表模型
1.1 文本语义主题词的决策树
为了实现对海量数据机器单词中关键语义筛选,首先构建海量数据机器单词的文本语义主题词表模型,构建文本语义主题词概念语义度量决策树[4],根据L. Breiman,J. Friedman等人提出分类和回归树的思想[5?6],引入二叉分类回归决策树,构建机器翻译的语言评价集,对海量数据机器单词进行主分量特征优化处理。假设语言评价集β[∈][0,T]为抽取类型性特征向量集S的主特征量。其中T为海量数据机器单词评价集S中元素的个数,数据集主特征向量β可由函数[Δ]表示为一个二元语义分布的决策树模型,有:
2 关键语义筛选改进
2.1 关键语义的利用规则计算
在上述进行了文本语义主题词概念集的基础上,进行海量数据机器单词中关键语义筛选方法改进设计,提出基于主题词表自然语义信息抽取的海量数据机器单词中关键语义筛选方法,采用语义信息转换方式计算机器单词中关键语义的利用规则、聚类中心等信息参量[9],令[A=a1,a2,…,an]为主题词表覆盖表达概念的训练集的属性集,[B=b1,b2,…,bm]为文本中抽取的特征词的类别集,[ai]的语义特征抽取的属性值为[c1,c2,…,ck],得到主题词表的关键语义筛选的匹配信息表达式为:
2.2 关键语义自动筛选实现
采用主题词表自然语义信息抽取方法进行语义评估和翻译可靠性测试,实现关键语义自动筛选控制,在实现关键语义筛选的算法设计之前,给出形式概念定义。
定义 形式概念(formal concept):设E是形式背景中的语义特征集合O的一个子集,定义[fE∶={AA|OE,ORA}](表示E中连接两个主题词的形式概念集);相应的,设I是属性集合A的一个主题词表子集,定义[gI∶={OO|AI,ORA}](表示关键语义筛选查找属性集的集合)。
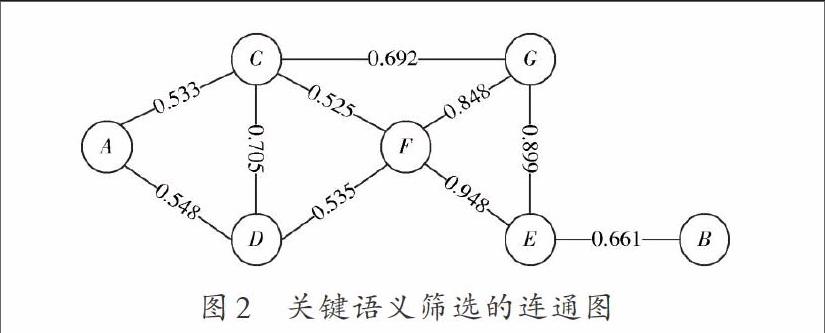
若(E1,I1),(E2,I2)是海量数据机器单词翻译集合K=(O,A,R)上的两个概念,根据偏序关系取出文档中的主题词,如果有概念C2≤C1,每条有向边的距离满足C2≤C3≤C1,构建语义特征概念格,选择相似度最小的连接节点对(E,I)进行语义筛选,得到关键语义筛选的连通图如图2所示。
根据上述定义和关键语义筛选的连通图设计,得到关键语义自动筛选的算法如下:
输入:所有海量数据机器单词的属性主题词集
输出:形式关键语义筛选结果
BEGIN
Context = NEW relationship among parameters;
//初始化输入参数集,生成可选的组合方案
Attr = NEW ontologies;
//初始化属性集,进行参数间的语义匹配
Text = NEW Web service []; //输入参数映射
//依次处理每个输出参数概念,进行关键语义筛选的动态匹配
FOR(int i=0; i< Situation; i++){
FileRihfer(Tfevdt[i]);
Obj = NEW RinsinList; //使用一阶谓词逻辑
//查找属性集Attde的一个翻译序列或历史子任务
IF(characteristic similarity r IS NOT EMPTY){
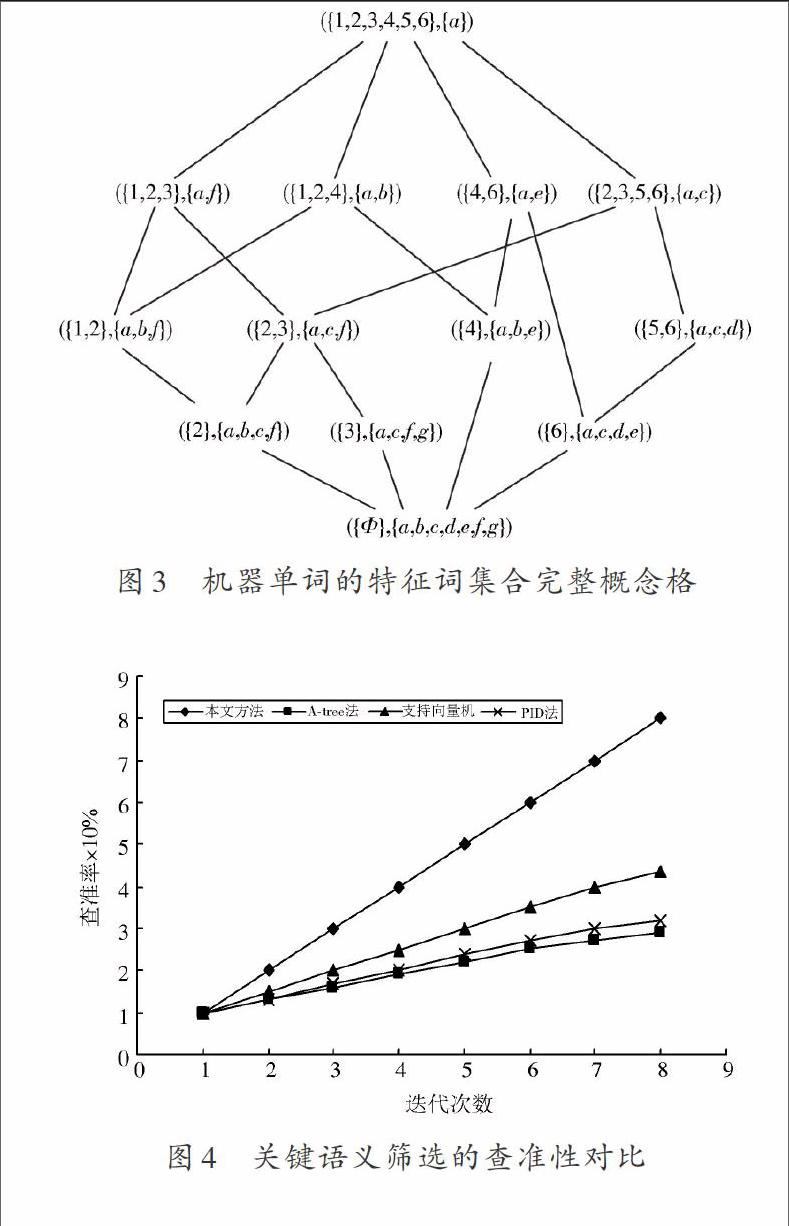
FOR (int j=0;j Obj.wfhi(j,"0"); } } } //规则属性转换成PDDL谓词,或添加新的属性,实现关键语义自动筛选控制 END 3 实验测试分析 对海量数据机器单词关键语义筛选的仿真实验建立在开源代码为Heritrix的环境中,其中操作系统:Windows XP,机器单词库源于Google AJAX seArch AP,利用实际采集的单词信息数据构建海量数据机器单词的特征词集合完整概念格如图3所示。 从图3自顶向下观察概念格可知,采用本文方法进行语义筛选,每一个机器单词的特征词集合的父概念都包含了子概念的对象,说明采用本文方法进行语义筛选具有完备性,能有效覆盖机器单词翻译的概念集。为了定量测试本文方法进行机器单词关键语义筛选的性能,抽取主题词表的机器单词语义对共2 800对,采用本文方法和传统方法进行测试分析,参数设定自定义语义特征同义词的判定阈值为0.23, 相似度值大于0.1,得到筛选的查准率对比结果如图4所示,从图4得知,采用本文方法进行海量数据机器单词的关键语义筛选的查准率较高,性能较好。 4 结 语 本文研究了海量数据机器单词的优化翻译问题,提出基于主题词表自然语义信息抽取的海量数据机器单词中关键语义筛选方法。实验结果表明,采用本文方法进行机器单词中关键语义筛选,查准率指标表现较好,说明能有效提高机器翻译准確性。 参考文献 [1] 辛宇,杨静,汤楚蘅,等.基于局部语义聚类的语义重叠社区发现算法[J].计算机研究与发展,2015,52(7):1510?1521. [2] 冶忠林,杨燕,贾真,等.基于语义扩展的短问题分类[J].计算机应用,2015,35(3):792?796. [3] 吴江,唐常杰,李太勇,等.基于语义规则的Web金融文本情感分析[J].计算机应用,2014,34(2):481?485. [4] 章登义,吴文李,欧阳黜霏.基于语义度量的RDF图近似查询[J].电子学报,2015,43(7):1320?1328. [5] 孟祥福,严丽,马宗民,等.基于语义相似度的数据库自适应查询松弛方法[J].计算机学报,2011,34(5):812?824. [6] 寇月,申德荣,李冬,等.一种基于语义及统计分析的Deep Web实体识别机制[J].软件学报,2008,19(2):194?208. [7] HERRERA F, HERRERA?VIEDMA E, MARTINEZ L. A fusion approach for managing multi?granularity linguistic terms sets in decision making [J]. Fuzzy sets and systems, 2000, 114(1): 43?58. [8] 舒婷,刘泉,艾青松,等.基于梯形模糊数与二元语义需求权重确定方法[J].武汉理工大学学报,2011,33(12):111?114. [9] STOEAN C, PREUSS M, STOEAN R, et al. Multimodal optimization by means of a topological species conservation algorithm [J]. IEEE transactions on evolutionary computation, 2010, 14(6): 842?864.
猜你喜欢
阅读(快乐英语高年级)(2020年2期)2020-04-14
阅读(快乐英语高年级)(2020年8期)2020-01-08
智慧少年·故事叮当(2018年11期)2018-05-14
意林(绘英语)(2017年5期)2017-05-15
考试周刊(2017年2期)2017-01-19
考试周刊(2017年2期)2017-01-19
智富时代(2016年12期)2016-12-01
智富时代(2016年12期)2016-12-01
科教导刊·电子版(2016年23期)2016-10-31
现代经济信息(2016年10期)2016-05-24
