
基于位向量的关联规则算法在教学评价中的应用研究
2017-04-12 01:10张永雄余丙军邓志虹
廊坊师范学院学报(自然科学版) 2017年1期
张永雄,余丙军,邓志虹
(1.广州工商学院,广东 广州 510850;2.华南理工大学,广东 广州 510641)
基于位向量的关联规则算法在教学评价中的应用研究
张永雄1,余丙军2,邓志虹1
(1.广州工商学院,广东 广州 510850;2.华南理工大学,广东 广州 510641)
在研究和分析Apriori关联规则算法缺陷的基础上,设计了一种效率更高的基于位向量的矩阵关联规则算法,通过实验验证了其可行性和有效性,并把该算法应用到教学评价中,挖掘出影响教学质量的相关因素,从而为学校改进教学管理工作提供客观有效的决策分析方法。
位向量;Apriori算法;关联规则;频繁集
0 引言
数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但有时潜在信息和知识的过程[1]。关联规则是数据挖掘重要方法的一种,它可以从给定的数据集中发现频繁出现的项集,以及数据之间的联系,可以找出满足一定支持度和置信度的多个数据项的联系。
本文提出一种基于位向量的关联规则数据挖掘算法,对某学校部分教师的教学评价结果进行关联分析,为教学管理部门对教学工作改进提出决策参考。
1 关联规则与Apriori算法
1.1 关联规则的描述
关联规则反映了一种特定数据对象之间的联系,它有支持度、置信度、提升度、影响度和改进度等等多个测量指标。本文选用支持度和置信度等两个常用的测量指标作为研究内容。
假设有m个不同数据项组成的一个集合I={I1,I2,I3,…,Im},在一个事务数据集T,其中每一个事务记录T是I的一个非空子集,即T⊆I。对于任意一个非空的项目X(X⊆I),如果记录T包含X的所有数据项(即T⊇X),则X的支持度可表示为:

关联规则如果是X=>Y的表达式,其中X,Y是非空项集(X,Y≠Ф,X,Y=>I),且X与Y不相交(X∩Y=Ф),则X=>Y的支持度为:
Dsupp(X=>Y)=Dsupp(X∪Y)。
X=>Y的置信度为:

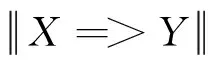
关联分析的目的是找出所有不少于指定的最小支持度和最小置信度为约束条件的强关联规则。
1.2 Apriori算法
由于所有项集的个数是2m-1(除去空集),而计算一个项集的支持度至少需要遍历扫描一次数据库,则计算的复杂性是O(2m),从中可知,这个过程是一个非常耗时并且效率低的方法。
但是,支持度有一个性质,即如果一个集合是频繁集,则其子集也是频繁集,因此,可以得出数学关系为:
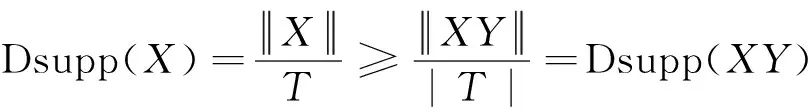
Apriori算法是基于以上思路建立的,由Agrawal等人建立的[2-4]。Apriori算法采用一种逐层搜索的迭代方法,从k-项集来生产(k+1)-项集。首先找出频繁1-项集,记为L1;然后利用频繁1-项集L1来生产频繁2-项集L2,不断地循环,直到无法找到更多的频繁k-项集为止。每生成一层Lk都需要扫描一次数据库,而且会产生大量的候选集,这就是Apriori算法的缺陷。
2 基于位向量的关联规则算法
2.1 算法思路及相关定义
在研究了传统Apriori算法的缺陷之后,本文提出了一种基于位向量的关联规则算法,其主要思路就是把事务数据库的多次扫描和支持度计算转化为0-1的位向量的计算,减少对数据库的I/O操作,提高了数据挖掘的效率[5,6]。
定义1 假设一个含有n个事务Ti(i=1,2,3,…,n),在项集I={I1,I2,I3,…,Im},Ik在事务数据集T所对应的布尔向量Ik=[t1k,t2k,t3k,…,tnk],其中,

定义2 项集Ij的支持度Dsupp(Ij)=
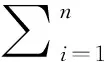
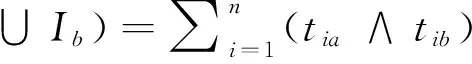
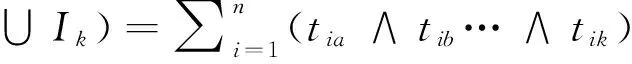
2.2 算法步骤
(1)构建矩阵,对含有m个不同数据项,n条事务的数据库D,进行扫描,生成位向量矩阵An×m,其中,
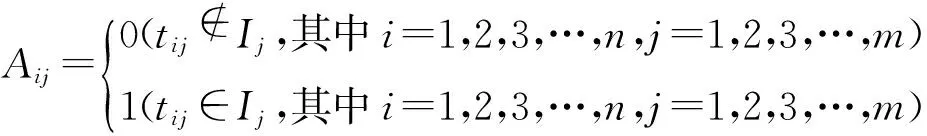
(2)产生频繁1-项集,统计结果中1的个数,记为count(Ij),若count(Ij)少于最小支持度阀值,则从矩阵中删除该列,否则保留,最后剩下的列就是频繁1-项集。
(3)产生频繁2-项集,对上一步产生的新矩阵中的列向量分别两两求内积,统计结果中1的个数,记为count(Iij),若count(Iij)少于最小支持度阀值,则从矩阵中删除该列,否则保留,最后剩下的列就是频繁2-项集。
(4)产生频繁k-项集,对求k-1-项集产生的新矩阵中列向量与频繁1-项集产生的新矩阵中列向量进行两两求内积,统计结果中1的个数,记为count(I1…k),若count(I1…k)少于最小支持度阀值,则从矩阵中删除该列,否则保留,最后剩下的列就是频繁k-项集。
(5)k=k+1,重复第(4)步,直到空矩阵为止。
2.3 算法的描述
算法:基于位向量逐层迭代的候选项集生成频繁集
输入:事务数据库T,最小支持度阀值min-support
输出:T中的频繁集L
处理流程:
(1)扫描数据库并转换向量矩阵A1
(3)for(k=2;Lk-1≠Ф;k++){
(4)Ck=matrix-gen(A1,Ak-1,min-support);
(5)foreachcandidate{
(7)}
(8)Ak={c∈Ck|count(Ck)≥min-support}
(9)}
(10)returnLk=A1A2…Ak//把1,2,…,k组合在一起,成为新的矩阵
该算法的优点在于k-频繁项集可以有1-频繁项集和k-1-频繁项集得到,无需再次扫描数据库,数据库只需访问一次,即在开始时对整个事务数据库进行访问,转化为布尔向量集。其次,计算机的逻辑与预算效率较高,节省了时间。
2.4 性能分析
本文提出的基于位向量的关联规则算法是采用一次扫描,把数据库转化为位向量矩阵表示,不仅可以使得后续的操作处理不需要扫描数据库,减少了I/O操作的时间,而且使用二进制位向量矩阵来计算列向量的内积求频繁集,提高了运算速度。
本文从教学评价数据库导出1000条事务数据记录作为测试,其中事务数据记录选取了性别、年龄、学历、职称、教学方法、教学能力、教学态度和教学效果作为数据项。选取支持度为0.05、0.1、0.15、0.2作为测试最小支持度阀值。测试结果如图1所示。
另外,本文在确定最小支持度为0.15时,分别选取100、200、500、1000条事务数据记录作为测试,测试结果如图2所示。
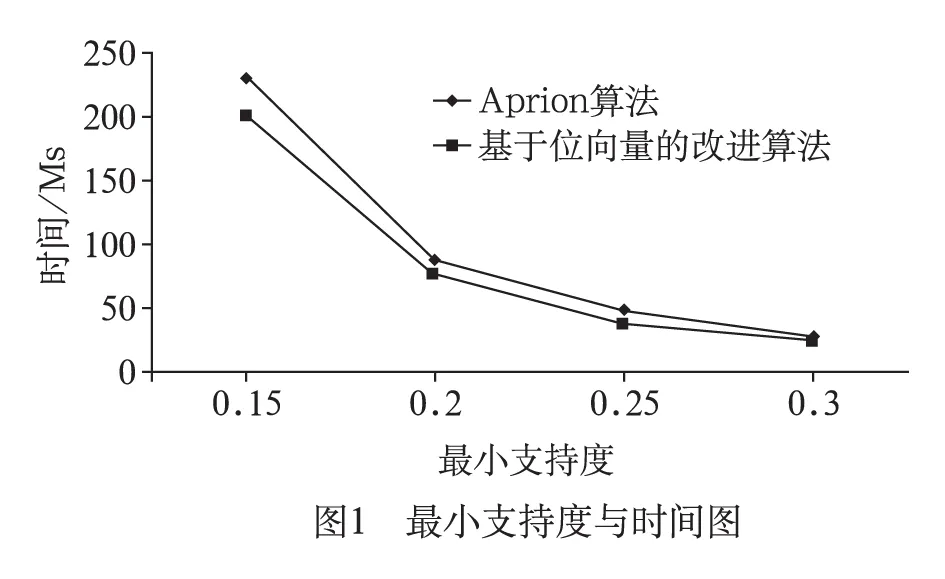
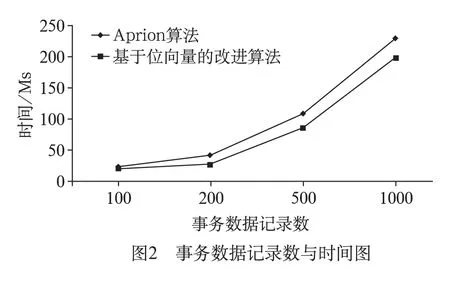
从实验结果分析,可以得到基于位向量的关联规则算法比Apriori算法在性能上优越,而且,在数据量越大或者最小支持度越小的时候,更能体现基于位向量的关联规则算法的性能。
3 位向量的关联规则在教学评价中的应用
教学管理部门为了做好教学管理工作,提出有效的决策,往往需要清楚影响教学质量的因素,本文通过从教务处导出的教学评价数据,选取认为影响因素比较重要的8个数据项作为研究内容,分别是性别、年龄、学历、职称、教学方法、教学能力、教学态度和教学效果。为了简化测试内容,仅随机选取了10条评教数据作为数据源,随机抽取分析数据如图3所示。
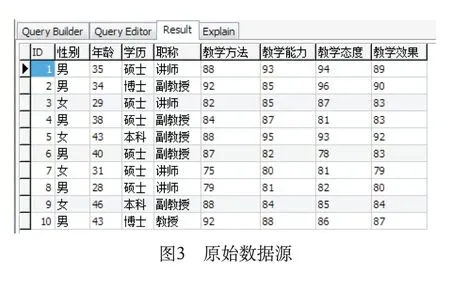
为了便于对原始数据进行数据挖掘分析,对以上数据进行指标系数转换,如表1所示。
对原始数据进行预处理,概化后的数据如表2所示。
运用位向量的关联规则算法对概化后的数据表进行关联规则挖掘,设最小支持度为50%,最小置信度为80%,最后得到的结果如表3所示。
分析表3的结果,可以知道具有硕士及以上学历的老师,通常都是男老师,年龄在30~40岁之间,并且教学能力和教学效果都很好;同时,也可以知道教学能力好的老师教学态度也很好,反之,教学态度好的老师,通常教学能力也不错。
本次案例应用仅仅选取了10条记录作为分析,如果需要实际的应用,还是需要对大量数据进行分析,并设置合理的最小支持度和最小置信度,这样才能较为准确地挖掘出有参考价值的信息。
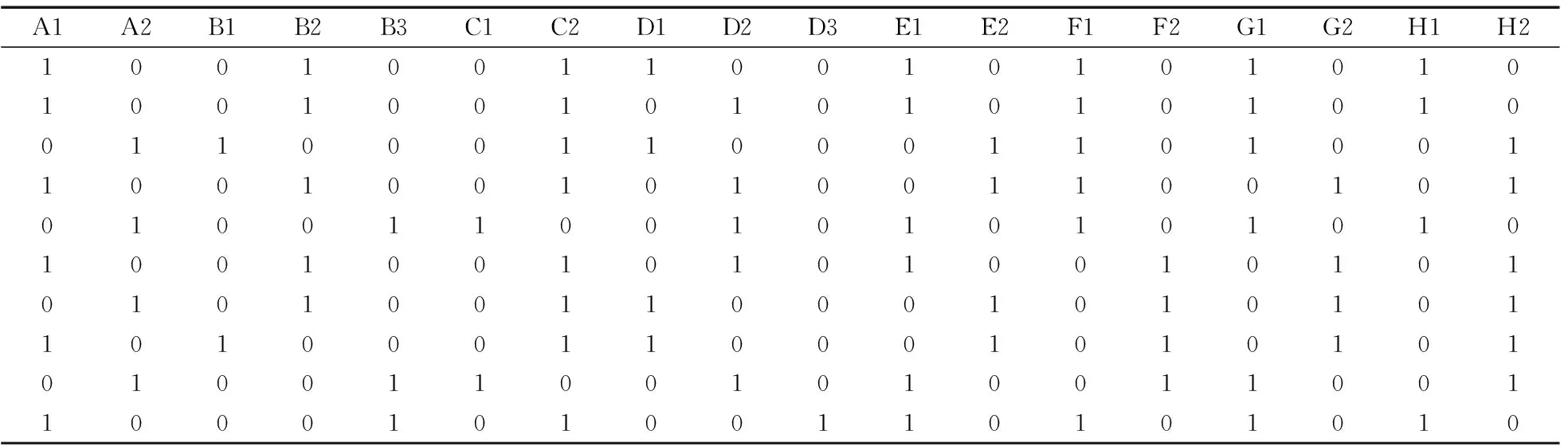
表2 概化后的数据

表3 关联规则挖掘结果
4 结语
本文介绍了关联规则的相关概念及Apriori算法,针对Apriori算法的缺陷,提出了基于位向量的关联规则改进算法,通过实验证明其有效性,并利用该算法对教学评价中的数据项进行关联挖掘,为学校部门对改进教学管理工作提供了一种可行有效的决策分析方法。
[1] Kamber M.数据挖掘:概念与技术[M].范明,孟小峰,译.北京:机械工业出版社,2007.
[2] Agrawal R,Imielinski T, Swarmi A.Mining Association Rules Between Sets of Items in Large Databases[J].Acm Sigmod Record,1993,22(2):207-216.
[3] Park JS,Chen MS,Yu PS.An Effective Hash-based algorithm for mining association rules[J].Acm Sigmod Record,1995,24(2):175-186.
[4] Agrawal R,Srikant R.Fast Algorithms for Mining Association Rules in large databases[J].Journal of Computer Science and Technology,2000,15(6):619-624.
[5] 刘以安,刘强,邹晓华,等.基于向量内积的关联规则挖掘算法研究[J].计算机工程与应用,2006,42(21):172-174,182.
[6] 严海兵,卞福荃.一种基于布尔向量的Apriori改进算法[J].苏州科技学院学报(自然科学版),2008,25(1):67-70.
Application Research of Association Rule Algorithm Based on Bit Vector in Teaching Quality Evaluation
ZHANGYong-xiong1,YUBing-jun2,DengZhi-hong1
(1.GuangzhouCollegeofTechnologyandBusiness,Guangzhou510850,China;2.SouthChinaUniversityofTechnology,Guangzhou510641,China)
This Paper studies and analyzes the defects of Apriori Association Rule Algorithm, proposing a higher efficiency matrix association rule algorithm based on bit vector. By verifying its feasibility and effectiveness, the algorithm is applied to the teaching quality evaluation, which help uncover the related factors that affect the quality of teaching, so as to provide an objective and effective method of decision analysis for improving the teaching management of the school.
Bit vector; Apriori algorithm; association rule; frequent sets
2016-12-22
2015广东省青年创新人才类项目(2015WQNCX160)
张永雄(1982-),男,硕士,广州工商学院经济贸易系讲师,研究方向:数据分析与云计算。
TP311
A
1674-3229(2017)01-0021-04
猜你喜欢
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
机电产品开发与创新(2020年2期)2020-05-07
甘肃科技(2020年19期)2020-03-11
计算机与生活(2019年11期)2019-11-12
科技与创新(2019年14期)2019-08-12
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
计算机应用(2018年5期)2018-07-25
计算机工程与设计(2011年7期)2011-09-07
