
轻量级大数据运算系统Helius
2017-04-20 03:38丁梦苏陈世敏
计算机应用 2017年2期
丁梦苏,陈世敏
(计算机体系结构国家重点实验室(中国科学院计算技术研究所),北京 100190)
(*通信作者电子邮箱chensm@ict.ac.cn)
轻量级大数据运算系统Helius
丁梦苏,陈世敏*
(计算机体系结构国家重点实验室(中国科学院计算技术研究所),北京 100190)
(*通信作者电子邮箱chensm@ict.ac.cn)
针对Spark数据集不可变,以及Java虚拟机(JVM)依赖环境引起的代码执行、内存管理、数据序列化/反序列化等开销过多的不足,采用C/C++语言,设计并实现了一种轻量级的大数据运算系统——Helius。Helius支持Spark的基本操作,同时允许数据集整体修改;同时,Helius利用C/C++优化内存管理和网络传输,并采用stateless worker机制简化分布式计算平台的容错恢复过程。实验结果显示:5次迭代中,Helius运行PageRank算法的时间仅为Spark的25.12%~53.14%,运行TPCH Q6的时间仅为Spark的57.37%;在PageRank迭代1次的基础上,运行在Helius系统下时,master节点IP接收和发送数据量约为运行于Spark系统的40%和15%,而且200 s的运行过程中,Helius占用的总内存约为Spark的25%。实验结果与分析表明,与Spark相比,Helius具有节约内存、不需要序列化和反序列化、减少网络交互以及容错简单等优点。
内存计算;大数据运算;分布式计算;有向无环图调度;容错恢复
0 引言
在科学研究和产业实践中,MapReduce[1]集群编程模型已经广泛应用于大规模数据处理。MapReduce系统把用户编制的串行Map和Reduce程序自动地分布并行执行,在每次运算前,系统需要从分布式文件系统中读取输入数据,运算完成后,系统要将计算结果写入分布式文件系统中。如此一来,多个MapReduce运算之间只能通过分布式文件系统才能共享数据,这不仅产生了大量的中间文件,而且反复读写磁盘大幅降低了运算性能。随着内存容量指数级增长和单位内存价格不断下降,大容量内存正成为服务器的标准配置,于是内存计算逐渐被主流商用系统和开源工具所接受。以内存计算为核心思想的Spark[2-4]在性能上远超基于MapReduce的Hadoop[5]:迭代计算性能和数据分析性能分别可以提高20倍和40倍。Spark在保持MapReduce自动容错、位置感知调度、可扩展性等优点的同时,高效地支持多个运算通过内存重用中间结果,从而避免了外存访问的开销。Spark的基本数据模型是弹性分布式数据集(Resilient Distributed Dataset, RDD)[3]。一个RDD是一个只读的数据集合,生成之后不能修改。RDD支持粗粒度的运算,即集合中的每个数据元素都进行统一的运算。RDD可以划分为分区分布在多个机器节点上,所以一个运算可以在多个节点上分布式地执行。Spark通过记录计算间的沿袭(Lineage)以支持容错,当出现故障导致RDD分区丢失时,Spark根据记录的计算沿袭,重新计算并重建丢失的分区。
然而,Spark的设计和实现存在着一定的局限性。首先, RDD被设计成只读的数据集,既不支持重写,也不支持数据追加。于是,Spark需要为每个新创建的RDD分配内存空间,尤其在迭代计算时,每个循环都产生一组新的RDD,这加大了内存开销。其次,Spark采用Scala程序设计语言实现,在Java虚拟机(Java Virtual Machine, JVM)[6]上运行,继承了Java的一系列问题。程序编译后生成字节码,执行时再由JVM解释执行或进行即时(Just-In-Time, JIT)编译成为机器码。内存管理无法主动释放内存,必须由JVM的垃圾回收机制才能释放内存。数据传输时,需要经历数据的序列化和反序列化,不仅增加了转换的计算代价,而且序列化的数据通常增加了类型等信息,引起网络传输数据量的增加。这些问题在一定程度上限制了系统的性能。
为此,用C/C++语言设计并实现了一种轻量级的大数据运算系统——Helius。Helius采用了一种类似于RDD的数据模型,称为BPD(Bulk Parallel Dataset)。BPD与RDD的区别在于BPD可写,RDD只可读。用户可以选择重写BPD,系统无须重新分配内存,而是直接覆盖原来的区域。这样不仅节省了内存开销,而且提高了运算性能。BPD在多个计算间提供了一种高效的共享方式,计算结果存入内存,其他计算通过直接访问内存快速地获取输入。
与Spark相同,Helius也采用master-worker分布式架构,通过记录各个BPD操作之间的计算沿袭构建依赖关系,动态生成计算的有向无环图(Directed Acyclic Graph, DAG)[7],划分计算阶段,在每个阶段中多个计算任务并行执行。Helius支持Spark的各项计算、自动容错、感知调度和可扩展性。相对Spark而言,Helius的优势具体如下:
1)降低内存开销。Helius采用C/C++实现,程序运行时能够实时回收内存;此外,BPD的可变性支持系统在计算过程中充分利用已有的内存空间,减少了不必要的内存开销。
2)不需要序列化和反序列化。数据在系统中以二进制字节的方式存储,当集群节点都是x86机器时,网络传输时可以直接发送二进制数据,不需要进行Endian转换和序列化/反序列化。
3)减少网络交互。Helius使用一种类似于push的方式传递数据,master直接操控数据的传输,worker之间不需要互相发送请求,从而减少了网络请求的交互。
4)简化容错恢复。Helius应用了一种stateless worker的思想,worker遵循网络请求进行工作,请求包含计算所需的状态信息,而worker除BPD数据分区外,不保存计算状态。这样,系统将多点故障集中到了对单点master的故障处理。
1 基于BPD的编程模型
1.1 BPD数据模型
类似于Spark系统中的RDD,BPD是一种分布式的数据集合,可以划分为多个数据分区,存放在多个worker节点上。BPD支持粗粒度的运算,集合中的每个数据元素都进行统一的操作。这样,不同worker节点上的BPD分区可以并行执行相同的运算。
与RDD不同,BPD是可变数据集。考虑一个简单的例子,对所有数据元素自增,因RDD只读性的限制,Spark需要分配内存空间,为这个操作创建一个新的RDD;而Helius避免了额外的空间开销,新的结果可以直接填充覆盖原始的数据集。
BPD遵循一套严格且灵活的可变机制。严格性是系统层考虑的问题,体现在只有用户计算产生的BPD可变,并且要求计算过程中新产生的数据元素占用的内存空间维持不变。Helius针对少部分遵循可变机制的用户计算函数(UDFListCombine函数)实现更新接口,其他函数不提供BPD更新支持。灵活性针对用户层而言,用户调用支持BPD更新的函数(如UDFListCombine)时,可以通过设置函数参数(真或假)指示该BPD是否在该运算中更新。若不更新,系统将新创建一个BPD;若更新,新结果将覆盖待计算的BPD,无需重新分配空间。对于一系列不改变数据结构的操作而言,系统只需覆盖相应数值,在处理大量的数据时节省了时空开销。
RDD的只读性简化了数据一致性的实现。在Helius中则需要考虑如何保持BPD的一致性。与Spark相似,在Helius中,用户提供一个主驱动程序,BPD体现为程序中的特殊变量,变量之间的运算对应于BPD分布式运算。Helius的master节点加载主驱动程序,按照执行步骤,执行相应的分布式运算。从概念上看,虽然BPD运算是分布并行的,但是这个主驱动程序实际上是一个串行程序(当然可以包含循环、分支等控制流语句),它描述了BPD运算步骤之间的串行执行顺序和依赖关系。所以,单一的主驱动程序可以保证BPD数据的一致性。对于多个并发执行的主驱动程序,Helius禁止发生修改的BPD在多个并发程序之间共享,只有当进行修改操作的程序执行完毕后,被修改的BPD才可以被其他程序所使用。
具体实现时,master记录BPD的元数据,主要包含依赖关系、分区数据、分区划分信息和存储方式。依赖关系记录了父子BPD之间的转换关系,分区数据记录了子分区与一个或多个父分区之间的生成规则。一个BPD的多个分区大小可以不等,存储在worker节点上。worker把内存划分为等长的数据块,一个BPD分区由一个或多个数据块组成,这些数据块分布在内存或文件中,具体的存储位置由BPD的存储方式决定。用户可调用系统接口选择数据的存储方式。BPD可以按照用户指定的划分方式重新哈希散列成指定个数的分区。
1.2 BPD记录数据类型
Helius系统将BPD按二进制数据进行存储和处理。一个BPD数据集中的所有记录都具有相同的结构,可以是键值对Key-Value元组,也可以是无key或是无value的单个元素。对于key或是value,它的结构可以是定长或变长的数据,可以表达C/C++中的原子类型(数值类型、字符串类型等)、struct和class数据(内部不允许指针、没有虚函数)。key或value也可以进一步有内部嵌套结构,可以嵌套包含两个值或是多个值。嵌套主要发生在Join等操作的结果BPD上。系统提供方法获取BPD记录的key或value的二进制数据,二进制数据与正确的数值类型的转换依赖于用户的代码。通常在C/C++程序中,只需要对相应类型的指针变量赋值即可,不需要额外的转换和拷贝。
1.3 编程模型
用户将C/C++的主驱动程序编译成动态库后提交给master,与此同时指定master的运行入口函数。master解析库文件,依次执行函数体内的语句。在主驱动程序中,一个BPD表现为一个可操作的C++对象。各种计算通过调用该对象相应的方法而实现,计算可以生成新的BPD对象,或者修改已有的BPD对象。而这些BPD对象上的操作,就被Helius对应为对BPD多个分区上的分布式运算。
Helius提供两大类计算,用以处理BPD数据集:系统计算和用户计算。
1)系统计算:完全由系统实现的计算,包括union、cartesianProduct、partitionBy、join、groupBy等,用户可以直接调用系统计算函数处理BPD数据集,这些计算都不改变输入的BPD数据集。
union(A,B) →A∪BcartesianProduct({
2)用户计算:系统提供应用程序编程接口(ApplicationProgrammingInterface,API),由用户实现具体操作功能。用户在处理数据集之前需要根据API实现函数接口。在用户计算中,用户可以选择是否改变待计算的BPD数据集。
A=udfCompute(B,udf)
A=udfComputeMulti(B,C, …,udf)
A=udfListCombine(B,udf)
系统计算函数的语义很清晰。例如:join操作把两组输入BPD的Key-Value记录,按照key进行等值连接,输出记录的value部分是嵌套结构,由两个匹配记录的value部分组合形成;groupBy操作按照key进行分组,把同一组的所有value表示成一个list,即一个包含多值的嵌套结构。而用户计算接口主要包括三类,都要求用户提供一个根据相应接口实现的函数(在表中以udf表示)。首先,udfCompute方法针对单个BPD数据集的每条Key-Value记录进行处理,例如可以实现WordCount中单词的拆分。udfComputeMulti方法对多个BPD数据集的Key-Value记录进行某种运算。实际上,多个输入的BPD数据集进行了一次join操作,系统对每个join的结果调用一次用户实现的udfComputeMulti函数。这两类操作对数据集的结构没有要求,可为1.2节提及的任意一种存在形式。udfListCombine与udfCompute的处理对象类似,不同的是数据集key、value必须同时存在,并且value为包含多值的嵌套结构。它实现对每个key的多个value值进行聚合的操作,类似MapReduce系统中的Reduce操作。
1.4 实例介绍
以WordCount为例,统计文本中所有单词出现的次数,用户的主驱动程序如下:
BPD*lines=sc.loadFile(file);BPD*words=udfCompute(lines,newmySplit());BPD*wordgroup=words->groupBy();BPD*wordcount=udfListCombine(wordgroup,newmyCombine());
loadFile函数用于从文本生成一个BPD对象——lines,它的每个记录是一行文本。udfCompute函数调用用户自定义的mySplit函数对每行文本记录进行处理,在该示例中表现为将字符串拆分成多个单词,产生的words结果记录中key为单词,value为数值1。groupBy函数将Key-Value数据集按key进行分组。在这里,每个不同的单词为一组。最后,udfListCombine函数调用用户自定义的myCombine函数对同一key的所有value进行某种运算(在该示例中为求和)。
下面以udfListCombine函数为例,介绍udf函数的实现。用户自定义实现的函数如下:
classmyCombine:publicUDFListCombine{voidcall(ValueIterator*it,Value*out){intsum=0;while(it->hasNext()){int*val=(int*)(it->next());sum+=*val;
}
out->put(&sum,sizeof(int));
}};
用户实现了一个myCombine类,它继承了UDFListCombine类,实现UDFListCombine中的虚函数call()。call()的第一个输入参数是一个定义在输入BPD记录value列表上的Iterator迭代器。上述实现在while循环中通过这个Iterator依次访问列表中的每个value,把value的地址赋值给相应类型的指针,就可以直接操作。call()的第二个参数用于输出结果的BPD的value部分。在这里,把求和的结果写入out。
从上面的示例可见,用户可以使用C/C++程序简洁地表达大数据的运算。
2 分布式运行
Helius分布式运行的基础是表达BPD运算关系的DAG。用户的主驱动程序提交给master执行时,系统通过BPD变量获取具体运算及依赖关系,形成运算DAG。然后,Helius把一个DAG划分成多个阶段,每个阶段内部的运算可以在一起执行,从而减少中间结果的生成。一个阶段的输出结果为另一个阶段的输入。其中,最后一个阶段的输入来自原始数据源(例如文件),第一个阶段的计算结果是程序最终的输出结果。按照这种层次依赖关系,系统自上而下检查各个阶段(首先检查第一个阶段),当前阶段运行时将自动检测其依赖的其他阶段,若其他阶段准备就绪,则提交该阶段的任务;否则,迭代检查依赖的所有阶段,直至所有依赖阶段准备就绪后提交。每个阶段包含了一系列任务,系统将这些任务分配到最佳节点位置,并确保所有数据就绪。
2.1 DAG的生成及阶段的创建
在Helius系统中,DAG的生成过程以及阶段的创建过程与Spark系统类似,都是根据用户的主驱动程序进行的。用户主驱动程序执行时,系统先记录BPD的运算和依赖关系,并不立即执行所对应的分布式运算,只有当遇到lookup、collect和程序结束时,才执行之前记录的所有BPD运算。
与Spark不同的是,Helius将数据的shuffle操作单独抽取出来,显示地表达在DAG中,而非表示在其他的操作里。这样,DAG可以记录shuffle的状态信息,而不需要每个worker在实现BPD运算(例如groupBy)时,记录shuffle的状态信息。
记录的BPD形成了一个运算有向无环图(DAG),如图1所示。图的每个顶点是一个BPD或者BPD的版本(若被修改),顶点之间的有向边代表BPD运算的生成关系。有向边从输入BPD指向结果BPD。
图1中每个顶点代表一个BPD,其中BPD1和BPD2的union操作生成BPD3,BPD3的groupBy操作产生BPD4,BPD4是最终的计算目标。系统在执行用户主驱动程序时,记录BPD的运算和依赖关系。在这个例子中,当程序结束时,才生成DAG开始分布式计算。需要注意,图1中BPD3和BPD4之间的边是虚线,实际上DAG中删除了这条边。这也正体现了Helius与Spark的不同点。因为groupBy操作隐含地需要shuffle数据,系统自动生成了BPD5(图中深色填充表示),并修改了图,使BPD3的输出指向BPD5,BPD5的输出指向BPD4。

图1 DAG生成过程
阶段的创建由目标顶点和shuffle操作确定。在图1所示的DAG基础上,master开始自下而上创建阶段,如图2所示。master首先为目标顶点BPD4创建一个阶段(记为阶段0),并从该位置开始迭代遍历其父BPD。检测发现BPD4依赖于shuffle的结果,而shuffle必然需要网络传输,所以master以shuffle对应的BPD5为目的创建一个新的阶段(记为阶段1)。依此类推,master将DAG以shuffle为边界分为多个阶段,每个阶段内的BPD运算可以整合在一起执行,以提高运算的性能。

图2 阶段创建过程
所有阶段创建完毕后,master从上向下依次递归提交阶段:在尝试提交阶段0,master检测到该阶段依赖于阶段1,于是master挂起阶段0重新提交阶段1;由于阶段1无依赖阶段,因此阶段1顺利被提交;master开始提交阶段1对应的所有任务,阶段1完成后递归提交阶段0;目标阶段完成后,结束调度。
2.2 任务提交
当一个阶段成功提交后,master将为该阶段的目标BPD创建并提交任务。BPD的每个分区作为一个任务,各个分区独立地执行相同的计算,这使得多个任务可以在多个worker节点上并行执行。
在分布式运算环境下,基于位置感知分配任务到存储数据的节点会大幅提高运算的性能,减小网络传输的带宽。Helius提供位置感知调度。在DAG的基础上,master进一步确定父子BPD每个分区之间的映射关系(shuffle过程除外)。在分配任务时,递归计算该任务所在的分区依赖的父分区的位置,直到找到已经缓存的父分区后,将该任务发送到该父分区所在的worker节点,完成位置感知调度。
如果一个任务同时依赖两个父分区,并且两个父分区均已缓存时,那么默认将该任务分配到第一个依赖的父分区上。当两个父分区的数据在不同节点上,并且第二个父分区的数据量远大于第一个父分区时,将任务分发给第一个父分区所处的工作节点会增加网络开销,降低系统性能。一种优化方法是根据多个依赖的父分区的数据量确定最佳分配节点。
2.3 数据传输
当一个任务依赖多个数据源(多个父BPD分区),并且多个数据源不在同一工作节点时,worker节点需要获得所有的输入数据,才能开始计算任务。
Spark提供一种类似pull的获取方式,如图3所示。workerA向master请求数据,master定位数据所在的workerB,由workerB将数据发送给workerA。workerA完成任务后回答master。

图3 Spark 数据传输机制
值得注意的是,在Spark系统中,对依赖数据的获取是计算任务的一部分,worker在运行提交的任务时,可能需要远程获取数据。在发送消息1和消息4之间,workerA需要保持相应的状态信息,使worker的工作和故障处理变得相对复杂。
Helius提出一种statelessworker的机制,对数据的获取过程类似于push。在该机制下,worker不负责获取数据,而是由master指示其进行操作。worker对于每个网络请求,只完成相应的操作,而在网络请求之间,不记录额外的状态。如果一个任务所需数据在本节点不存在时,向master报错。
将提交任务分成两个步骤:传输数据和提交作业。数据传输的过程如图4所示:master告诉workerB传输数据给workerA,workerB传输指定的数据,workerA接收完数据后回复master传输完成;master接收到传输完毕信号后,紧接着提交作业。这样一来,系统保证了在分配工作之前,工作节点有需要的数据支持工作的进行,同时worker不需要保持额外的状态。这种statelessworker的机制简化了系统的容错处理,由于worker严格地按照master的指示工作,worker的工作机制相对来说简单了许多,在该点的故障及故障处理随之简化。系统将故障处理主要集中在master执行。

图4 Helius数据传输机制
2.4 数据重组
不同于数据传输(transfer)操作,数据重组(shuffle)操作需要将数组重组分发到所有的工作节点,可能会占用大量的内存空间和网络带宽。
为了减少shuffle对系统性能的影响,采用一种基于双缓冲的边计算边发送的策略。worker为每个shuffle目标worker节点都维持着一个缓冲区,包含2个数据块空间(分区数据由多个等长数据块组成)。在处理shuffle时,将数据写入相应worker的缓冲区的数据块中。当缓冲区中一个数据块已满,可以发送这个数据块,同时将数据写入另一个数据块。
图5呈现的是针对workerA单方面shuffle产生的数据发送的过程。图中的连线表示worker之间的连接状态,填充灰色部分代表该部分内存已满。

图5 数据shuffle过程
3 实验评估与分析
3.1 实验环境
集群环境由5台服务器组成,其中1台master,4台worker,服务器的处理器为IntelXeonCPUES- 2650v2 @2.60GHz×8, 内存128GB, 硬盘1TB,操作系统为Ubuntu14.04 64位。集群中的工作节点均单线程运行。Helius和Spark的实验版本分别为0.0.1 和1.6.1。Helius编译器为G++ 4.8.1, -o2选项优化,Spark编译器为Sbt0.13.12。
实验以PageRank[8-9]算法和TPCH[10]基准为例,从时间、网络、内存三方面开销比较Helius和Spark的性能,并在最后对BPD的更新性能以及Helius的可扩展性进行评估。
3.2 PageRank
实验输入文本为1.1GB, 包含网页4 847 570个,链接记录68 993 773条。Spark集群运行PageRank算法的配置选项为:spark.driver.memory=16g,spark.executor.memory=16g。
3.2.1 时间开销
运行PageRank算法时,分别记录迭代1、2、3、4、5次的时间开销。表1呈现的实现结果表明,在迭代5次的过程中,Helius运行PageRank算法的时间仅为Spark的25.12%~53.14%。因为Helius在实现PageRank算法时,采用的是一种建立在数据块内有序、块间无序的基础上优化join操作的策略,在每次更新rank值时直接重写旧值,而非重新创建新的BPD。
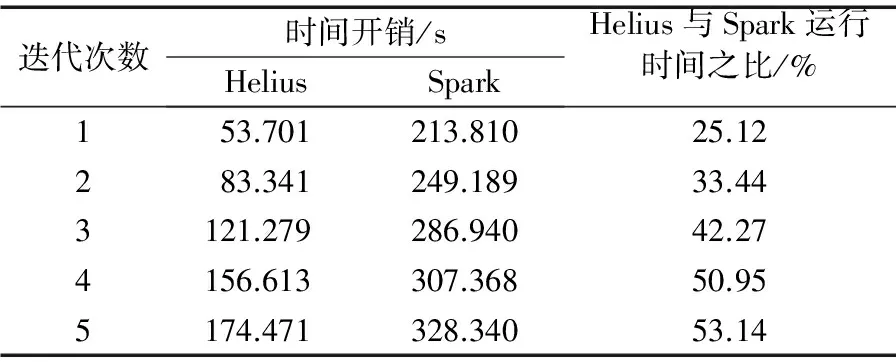
表1 Helius和Spark迭代时间对比
3.2.2 网络开销
在PageRank迭代1次的基础上,记录master节点在程序运行过程中接收到的字节数和发送的字节数,结果如表2所示。在分布式环境中,运行在Helius系统下时,master节点IP接收和发送数据量约为运行于Spark系统的40%和15%。
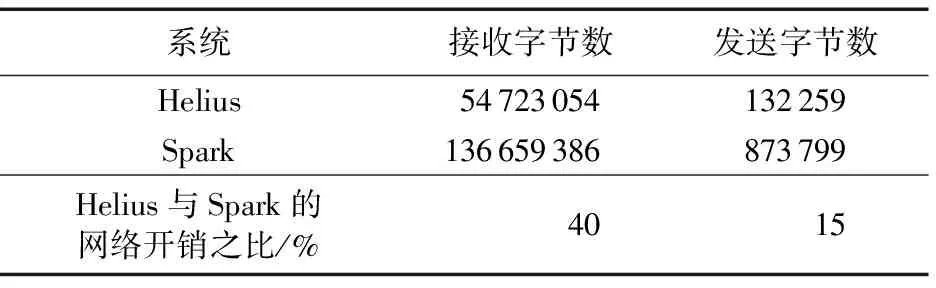
表2 Helius和Spark网络开销对比
3.2.3 内存开销
在PageRank迭代1次的基础上, 每隔5s记录worker节点内存剩余情况。表3呈现的是以20s为间隔记录的worker节点使用的内存量(单位:MB)。Helius在50s左右运行结束,逐渐回收内存;此时,Spark仍处于工作状态,直到210s左右结束。在worker运行的过程中,Helius占用内存6 758MB,Spark占用内存26 648MB,Helius约为Spark的25%。
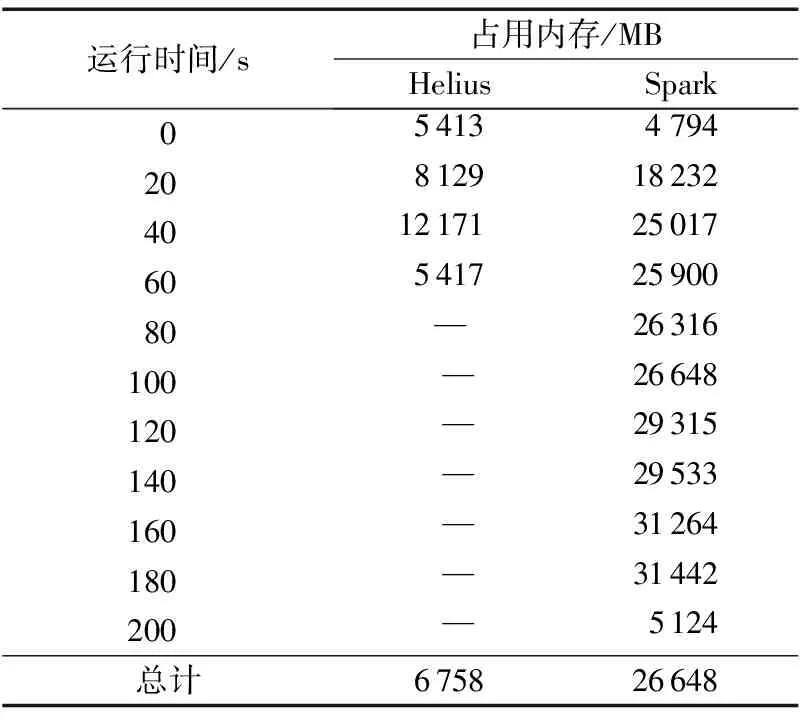
表3 Helius和Spark内存开销对比
3.3 TPCH Q6性能
以TPCH的ForecastingRevenueChangeQuery(Q6)为例,取ScaleFactor为100(文本79.8GB),测试Helius和Spark的运行时间。Spark在该例中为默认配置。实验结果为Helius花费271.595s,Spark花费473.382s,Helius消耗时间仅为Spark的57.37%。
Helius从文本获取输入数据是一种筛选-丢弃的过程,根据用户提供的查询字段的列值,在读取文本记录时选取相应的字段值构成数据集,后续所有操作都建立在已筛选字段的数据集的基础上;而Spark程序在加载文件时没有对字段进行筛选,运行过程中,所有的数据集中的每条记录都保持了输入文本的所有字段。
3.4 BPD更新性能
在PageRank迭代1次的基础上,测试在BPD更新与不更新的情况下,worker运行UDFListCombine函数的开销时间,以及master运行用户提交的驱动程序所用的总时间。PageRank在迭代1次的基础上会运行1次UDFListCombine函数。
从表4可以看出,在BPD更新的情况下,worker运行UDFListCombine的速度比不更新稍快;master运行整个程序也稍快。就表4的结果而言,BPD更新在运行时间方面的性能提升不大,这种结果很大程度上受到Helius实现的限制,我们将在后续的工作中进一步研究BPD的更新。

表4 有否BPD更新时运行时间对比
3.5 可扩展性
以3.3节中的TPCHQ6为例,测试Helius集群分别搭建在2、4、6、8台worker的运行时间,结果如表5所示。在当前实验条件考虑的扩展情况下,当worker节点数增加1倍时,Helius运行任务所需的时间减少50%左右。

表5 Helius可扩展性性能
4 结语
本文介绍了一种轻量级的基于内存计算的大数据运算系统Helius。Helius由C/C++语言实现,避免了Spark因JVM运行环境引起的开销,利用数据集整体修改这一特性实现高效计算,采用一种statelessworker的机制简化容错处理,并通过维持一套严格的修改机制确保了数据一致性。Helius在时间、网络、内存三方面性能相对Spark均有所提升。就数据集更新性能而言,Helius存在很大的提升空间。此外,目前Helius还未实现节点故障恢复,故障处理以及深层次的一致性管理问题有待后续深入研究。
)
[1]DEANJ,GHEMAWATS.MapReduce:simplifieddataprocessingonlargecluster[J].CommunicationoftheACM— 50thAnniversaryIssue: 1958-2008, 2008, 51(1): 107-113.
[2]ZAHARIAM.Anarchitectureforfastandgeneraldataprocessingonlargeclusters,UCB/EECS- 2014- 12 [R].Berkeley:UniversityofCaliforniaatBerkeley, 2014.
[3]ZAHARIAM,CHOWDHURYM,DAST,etal.Resilientdistributeddatasets:afault-tolerantabstractionforin-memoryclustercomputing[C]//NSDI’12:Proceedingsofthe9thUSENIXConferenceonNetworkedSystemsDesignandImplementation.Berkeley,CA:USENIXAssociation, 2012: 15-28.
[4]TheApacheSoftwareFoundation.ApacheSpark[EB/OL].[2016- 05- 30].http://spark.apache.org/.
[5]TheApacheSoftwareFoundation.ApacheHadoop[EB/OL].[2016- 05- 30].http://hadoop.apache.org/.
[6]SARIMBEKOVA,STADLERL,BULEJL,etal.WorkloadcharacterizationofJVMlanguages[J].Software:PracticeandExperience, 2016, 46(8): 1053-1089.
[7]ISARDM,BUDIUM,YUY,etal.Dryad:distributeddata-parallelprogramsforsequentialbuildingblocks[C]//EuroSys’07:Proceedingsofthe2ndACMSIGOPS/EuroSysEuropeanConferenceonComputerSystems2007.NewYork:ACM, 2007: 59-72.
[8]BERKHIUTJ.Google’sPageRankalgorithmforrankingnodesingeneralnetworks[C]//Proceedingsofthe2016 13thInternationalWorkshoponDiscreteEventSystems.Piscataway,NJ:IEEE, 2016: 163-172.
[9]PAGEL,BRINS,MOTWANIR,etal.ThePageRankcitationranking:bringingordertotheWeb,TechnicalReport1999- 66 [R/OL].California:StanfordUniversity, 1999 [2016- 04- 11].http://ilpubs.stanford.edu:8090/422/1/1999- 66.pdf.
[10]TransactionProcessingPerformanceCouncil.TPCBenchmarkTMHStandardSpecificationRevision2.17.1 [S/OL].[2016- 05- 30].http://www.tpc.org/tpc_documents_current_versions/pdf/tpc-h_v2.17.1.pdf.
[11]MALEWIEZG,AUSTEMMH,BIKAJC,etal.Pregel:asystemforlarge-scalegraphprocessing[C]//SIGMOD’10:Proceedingsofthe2010ACMSIGMODInternationalConferenceonManagementofData.NewYork:ACM, 2010: 135-146.
[12]CARSTOIUD,LEPADATUE,GASPARM.Hbase-non-SQLdatabase,performancesevaluation[J].InternationalJournalofAdvancementsinComputingTechnology, 2010: 2(5): 42-52.
ThisworkispartiallysupportedbytheCASHundredTalentsProgram,theGeneralProjectoftheNationalNaturalScienceFoundationofChina(61572468),theInnovativeCommunityProjectoftheNationalNaturalScienceFoundationofChina(61521092).
DING Mengsu, born in 1993, M.S.candidate.Her research interests include big data processing, parallel distributed computing.
CHEN Shimin, born in 1973, Ph.D., professor.His research interests include data management system, big data processing, computer architecture.
Helius: a lightweight big data processing system
DING Mengsu, CHEN Shimin*
(KeyLaboratoryofComputerSystemandArchitecture(InstituteofComputingTechnology,ChineseAcademyofSciences),Beijing100190,China)
Concerning the limitations of Spark, including immutable datasets and significant costs of code execution, memory management and data serialization/deserialization caused by running environment of Java Virtual Machine (JVM), a light-weight big data processing system, named Helius, was implemented in C/C++.Helius supports the basic operations of Spark, while allowing the data set to be modified as a whole.In Helius, the C/C++ is utilized to optimize the memory management and network communication, and a stateless worker mechanism is utilized to simplify the fault tolerance and recovery process of the distributed computing platform.The experimental results showed that in 5 iterations, the running time in Helius was only 25.12% to 53.14% of that in Spark when running PageRank iterative jobs, and the running time in Helius was only 57.37% of that in Spark when processing TPCH Q6.On the basis of one iteration of PageRank, the IP incoming and outcoming data sizes of master node in Helius were about 40% and 15% of those in Sparks, and the total memory consumed in the worker node in Helius was only 25% of that in Spark.Compared with Spark, Helius has the advantages of saving memory, eliminating the need for serialization and deserialization, reducing network interaction and simplifying fault tolerance.
in-memory computation; big data processing; distributed computation; Directed Acyclic Graph (DAG) scheduling; fault tolerance and recovery
2016- 08- 12;
2016- 10- 22。
中国科学院“百人计划”项目;国家自然科学基金面上项目(61572468);国家自然科学基金创新群体项目(61521092)。
丁梦苏(1993—),女,江西吉安人,硕士研究生,主要研究方向:大数据处理、并行分布式计算; 陈世敏(1973—),男,北京人,研究员,博士,主要研究方向:数据管理系统、大数据处理、计算机体系结构。
1001- 9081(2017)02- 0305- 06
10.11772/j.issn.1001- 9081.2017.02.0305
TP311.133.1
A
猜你喜欢
大众科学(2022年5期)2022-05-18
环球时报(2022-03-29)2022-03-29
电脑报(2019年31期)2019-09-10
电脑报(2019年10期)2019-09-10
当代陕西(2019年13期)2019-08-20
电子制作(2018年17期)2018-09-28
中国新通信(2016年11期)2016-08-09
人间(2015年11期)2016-01-09
电脑爱好者(2015年21期)2015-09-10
电脑爱好者(2009年13期)2009-07-07
