
脱机手写数字识别技术研究
2017-04-27 11:41张玉叶王尚强王淑娟王春歆
电脑知识与技术 2016年29期
关键词:结构特征
张玉叶 王尚强 王淑娟 王春歆


摘要:针对目前常见的脱机手写数字识别技术进行分析比较,并模拟人工智能识别字符的过程,提出一种分层识别方法。对于结构差异较大的数字字符,根据数字字符图像的统计特征进行粗略识别;然后进一步利用结构特征细致区分形状相近的数字字符。通过自制样本库进行识别测试,结果表明该方法能够有效提高识别准确率。
关键词:脱机手写数字识别;统计特征;结构特征
中图分类号:TP391.41 文献标识码:A 文章编号:1009-3044(2016)29-0195-03
脱机手写数字识别,就是利用数字化设备将纸质或其他介质上手写的数字字符扫描为数字图像信息,然后利用计算机进行一系列的数字图像处理步骤进行数字识别处理的技术。相对于目前比较成熟的联机手写字符识别,由于缺少联机能够获取的字符笔顺等重要信息,其技术实现难度要大。另外,脱机手写数字识别在邮政、银行、交易等领域应用需求广泛,所以是近年来图像处理领域研究的热点。
本文在分析目前常见的脱机手写数字识别技术的基础上,提出一种分层次的识别方法。该方法模拟人类识别字符的一般规律,首先抽取数字字符样本的统计特征,通过对主分量重建模型的误差分析进行字符的粗略识别;然后加入宽高比结构特征进行字符比对,进行第二层次的细致识别。
1常见的脱机手写数字识别技术
脱机手写数字识别最重要的环节是字符的特征提取,根据采用的特征提取方法的不同,可以将目前常见的脱机手写数字识别大致分为两类:基于统计特征和基于结构特征的方法。
基于统计特征的识别方法主要有两个过程:分类器学习训练过程和利用分类器识别过程。学习训练是将获取的样本信息经过预处理和特征提取之后给分类器学习,以此为识别的基础,让分类器获得识别的能力。识别过程将待识别的信息经过同样的预处理与特征提取后让分类器分类识别。统计方法的优点是能较好地描述一类模式的本质特征,对干扰信息不敏感,对与训练样本一致的信息识别正确率很高,缺点是对一些不稳定的字符形态容易误判。所以该方法类似于人类识别字符的粗略宏观过程。
基于结构特征的方法是分析字符笔画的构造如圈、端点、交叉点、轮廓等识别特征,结合字符间互斥的特征进行识别。方法能够精确地描述字符的细节特征,比较直观,对字符图像畸变的抗干扰能力较强,可靠性较高;缺点对噪声、断线等干扰较敏感,另外字符骨架提取等过程实现复杂度高。该类方法类似于人类识别字符的细致区分过程。
由于不同人的书写习惯和书写风格不同,使手写数字字符的形态极不稳定。根据人工智能识别字符的规律,可以将两类方法结合起来,分层进行识别,从而克服各自的不足,提高字符识别的准确度。
2脱机手写数字的分层识别方法
脱机手写数字识别,首要任务就是利用扫描设备将纸质载体扫描为图像信息以便计算机处理。得到的数字图像在進行识别之前需要进行图像的预处理,以消除图像中无关的信息,增强有关信息的可检测性和最大限度地简化数据,从而改进特征抽取、图像分割、匹配和识别的可靠性。预处理过程一般有几何变换、平滑、复原和增强、提取边缘、细化等步骤。这些图像预处理技术比较成熟,可以直接应用。
2.1主分量分析法提取统计特征及识别
3.1主分量分析法识别数字实验
步骤一:学习阶段
利用主分量分析法对0到9十个数字的训练样本提取统计特征,得到0到9十个模式类的前d个主分量重建得到的数字模型。以数字“6”为例,给出前d个主分量的重建模型图如图l所示,主分量个数d分别取3、5、7、10。从图中可以看出d越大,模型图像中包含的信息越多。
图1样本“6”前d个主分量的重建模型图
步骤二:识别阶段
将测试样本分别在各模式的特征空间估计对应于各模式的重建模型,再与各模式的重建模型相减得到重建误差,比较误差大小,误差越小,与对应的数字模式类越相似。
任意给出测试样本中经过预处理的0-9十个数字的图像如图2所示。
0-9十个手写数字字符(下表中用“”中的数字代表),在数字6的特征空间,分别构建的重建模型图像如图3所示:
根据公式(2),对任意选取的这十个数(测试样本)的重建模型与训练样本的重建模型相减求模,得到模型误差值进行识别。
这里,我们只针对“6”的样本集进行分析。当d=10的时候,任意十个数的测试样本与“6”样本集的重建模型相减,得到如图4中所示的十个误差图像。
对图4中图像求模得到误差值,误差值越小,说明测试样本数字的形态与数字“6”越相似。发现测试样本数字“6”的重建模型误差值最低,说明本方法是合理的。
其次误差值最小的是“4”,然后是“5”,其余的数字的误差较大。究其原因,我们分析表2中测试样本的图像不难发现,书写的数字4和5有与数字6最相近的笔画弧度部分。
步骤三:分析结果
100个测试样本经过主分量分析识别,得到的实验结果如表1所示:
表1中反映出,各数字字符的识别率也不同,其中以取7个主分量时得到的实验结果为例,发现,数字“1”的识别率最低(η=70%),其次是数字“7”“9”(η=80%)。分析其中的原因,主要是因为字符“1”的笔画过于简单,只有一竖,因此它笔画结构的特征不明显,通过PCA能够提取的结构特征也就很有限。而“7”和“1”、“9”两个数字结构特征类似,也导致它的识别率比较低。为此,加入字符的宽高比结构特征进行识别。
3.2结合宽高比结构特征识别实验
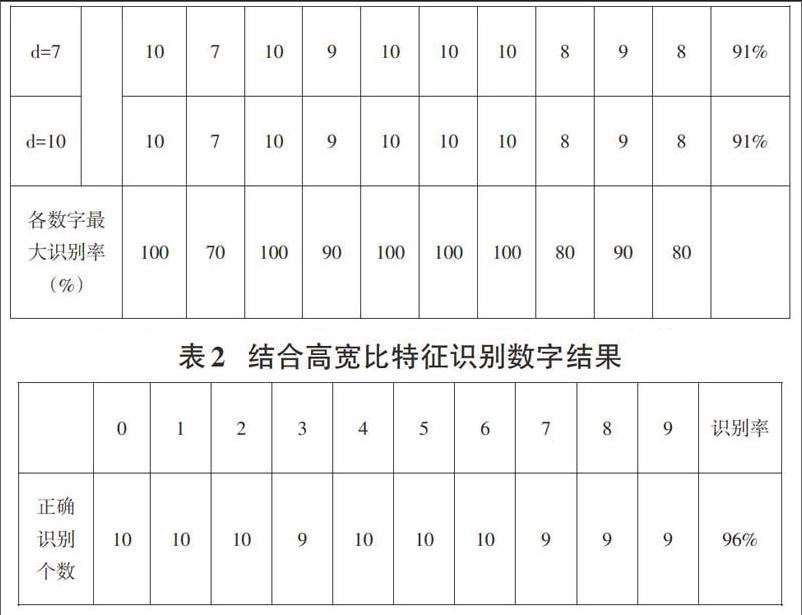
针对统计法识别数字出现的问题,提取宽高比特征进行数字识别,得到结果如表2。
发现数字识别率由91%提高到了96%,其中数字“1”被全数识别,原因在于它的高宽比特征最显著。“7”和“9”识别率也显著提高,这是因为其结构特征与“1”区别开来,另外,结构特征使“9”与“6”区别更显著了。
4结论
本文在分析现有脱机手写数字识别技术的基础上,根据人工智能识别字符的规律,结合统计特征和结构特征设计了分层识别步骤。自制训练样本及测试样本库,利用Matlab软件进行识别实验,分析实验结果发现本方法能够在一定程度上提高数字识别率,但是未对算法实时性作出要求,要形成工程实用的算法,还需要进一步的研究。
猜你喜欢
天中学刊(2022年4期)2022-11-08
天津医科大学学报(2021年3期)2021-07-21
大连民族大学学报(2020年2期)2020-06-16
天津音乐学院学报(2019年4期)2019-06-11
中国塑料(2016年2期)2016-06-15
兽医导刊(2016年12期)2016-05-17
应用海洋学学报(2015年3期)2015-11-22
中国塑料(2015年5期)2015-10-14
中国煤层气(2015年4期)2015-08-22
邵阳学院学报(自然科学版)(2015年2期)2015-06-05
