
一种混合入侵检测模型
2017-05-10 07:03梁本来杨忠明蔡昭权
计算机测量与控制 2017年4期
梁本来,杨忠明,蔡昭权
(1.中山职业技术学院 信息工程学院,广东 中山 528404; 2.广东科学技术职业学院 计算机工程技术学院,广东 珠海 519090; 3.惠州学院 科研处,广东 惠州 516007)
一种混合入侵检测模型
梁本来1,杨忠明2,蔡昭权3
(1.中山职业技术学院 信息工程学院,广东 中山 528404; 2.广东科学技术职业学院 计算机工程技术学院,广东 珠海 519090; 3.惠州学院 科研处,广东 惠州 516007)
为了提高入侵检测模型的准确率,提出一种基于K-均值算法、朴素贝叶斯分类算法和反向传播神经网络的混合入侵检测模型;首先,采用基于分区、无监督式聚类分析的K-均值算法进行数据的聚类处理,得到易于被机器处理和学习的数据集;为了进一步获取必要的数据属性,将聚类处理的结果输入到贝叶斯分类器进行分类;然后,具有较短学习周期的反向传播神经网络负责训练数据分类样本;最后,基于KDDCUP99数据集,对混合入侵检测模型进行了仿真实验,实验结果表明,通过混合入侵检测模型,DoS、U2R、R2L和Probe等入侵数据被精准地检测出;相比其它入侵检测模型,混合入侵检测模型取得了较高的准确率和召回率,以及较低的误报率,具有一定的实用价值。
入侵检测模型;混合方法;K-均值;朴素贝叶斯;反向传播神经网络
0 引言
入侵检测系统(intrusion detection systems,IDS)的核心是入侵检测模型(intrusion detection model,IDM),如何降低IDM的误报率,提高IDM的准确率是当今IDS的研究热点,也是本文的研究重点。
IDM主要采用误用检测和异常检测两类方法[1],误用检测采用已知的入侵方法进行入侵行为的检测,能够高准确率地检测出传统的入侵行为,但对于较新的入侵行为,漏检率较高。异常检测是利用统计学对网络行为进行特征描述,根据网络行为的特征进行入侵检测,适应性较强,能够检测出未知的攻击行为,但该方法需要海量数据进行建模,这在复杂的网络环境中是不实用的[2]。
为了解决异常检测方法的局限性,许多研究将数据挖掘方法引入到IDM。学习海量数据会影响分类器的表现性能,包括准确率。因此,使用基本方法时要求在数据分析和学习过程中保持较好的性能。现有的研究中,基于决策树(decision tree, DT)[3]和朴素贝叶斯(naive bayes, NB)[4]的模型分类精度较高且算法模型较简单,但由于单一的分类器技术已经很难取得突破,近年来的研究倾向于使用混合分类方法[5]。王辉等提出一种改进朴素贝叶斯分类算法(Improved NB)[6],该算法在朴素贝叶斯模型的基础上引入属性加值算法,通过对分类参数的调控来简化分类数据的复杂度。该算法的准确率得到了一定提升,但该算法的仿真实验环境较为简单,面对复杂多变的网络数据,如何更合理的分类是该算法改进的目标。
姚潍等人在C4.5-NB算法的基础[7]上提出基于决策树与朴素贝叶斯分类的入侵检测模型H-C4.5-NB[8],该模型以混合混分类为前提,综合考虑决策树和朴素贝叶斯算法的优势并进行了改进,实验结果显示H-C4.5-NB算法能够在一定程度上降低误报率,但该方法还有待通过有效的属性子集提取方法进行进一步完善。
王辉提出一种IKMNB分类模型[9],该模型采用改进的K-均值(K-means)算法对数据进行聚类,然后运用贝叶斯分类器再次分类。通过仿真实验验证了该算法相比朴素贝叶斯提高了检测率,降低了误检率,但该模型缺少同其他分类算法的对比分析。
基于人工神经网络的模糊聚类方法是采用模糊聚类生成不同的训练子集,人工神经网络模型训练后制定不同的基础模型[10]。基于改进的反向传播人工神经网络(back propagation neural network, BPNN)的入侵检测系统主要用多层感知器训练增强弹性反向传播训练算法来检测入侵[11]。实验结果表明系统的准确率、存储和时间都比较好,已经实现的系统具备检测率高达94.7%的分类记录。
目前国内基于神经网络的综合分类IDM的研究并不是太多,其中邬斌亮提出一种融合K-均值聚类、FNN、SVM的网络入侵检测模型(后面简称为KFS模型)[12],该模型利用K均值聚类将原始训练集分类,然后采用模糊神经网络训练对各训练子集进行训练,最后采用径向向量机检测是否有入侵行为。通过KDD CUP99数据集的实验验证,该模型取得了更高的准确率。
本文基于K-均值算法、朴素贝叶斯分类算法和反向传播神经网络,提出一种混合入侵检测模型K-NB-BP(K-means,Naive Bayes and Back-Propagation neural network)。首先,采用基于分区、无监督式聚类分析的K-均值算法进行数据的聚类处理,得到易于被机器算法处理的数据集。同时,为了获取必要的数据属性,将聚类处理的结果输入到贝叶斯分类器进行分类,得到分类后的数据样本。然后,具有较短学习周期的反向传播神经网络负责训练样本集。基于KDD CUP99数据集的仿真实验结果表明,通过贝叶斯分类器,DoS、U2R、R2L和Probe等入侵数据被精准地检测出。相比Improved NB、H-C4.5-NB、K-NB-BP和KFS模型,K-NB-BP模型取得了较高的准确率和较低的错误率,且实验样本的召回率较高,具有一定的实际应用价值。
1 K-NB-BP模型的流程
本文提出的混合入侵检测模型K-NB-BP由3个主要的分类器和聚类方法实现。聚类是基于目标的相似度将目标进行分组。K-均值聚类是一种分区的非监督学习的方法。它将数据视为在空间中有一个位置的物体,且是一个迭代算法,这一步用于聚类或者组合大数据集中的数据。因K-均值聚类的结果比较粗超,采用Naive Bayes分类器获取必要的数据属性,这实际上是一种监督策略。在学习阶段,采用BPNN训练分类后的数据样本集,生成特征向量。
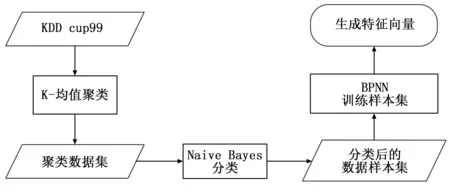
图1 K-NB-BP模型的流程
Step1:采用KDD CUP99数据集作为数据样本,系统分析了数据集,并从数据集中重新获得一些关于训练数据集的信息,例如训练集的实际数量、种类的数量、属性列表和种类分布。
Step2:数据集由无监督分类分析的K-均值算法进行聚类处理,K均值聚类算法是根据种类的数量使输入数据集聚类。之所以采用K均值聚类算法,是因为在整体的学习方法中,分组的数据比较容易被机器学习算法处理,不参与识别目标类的数据属性将被去除。
Step3:为了识别出理想类,采用Naive Bayes作为分类器,获取必要的数据属性,去除重复的数据属性,生成分类后的数据样本。
Step4:因BPNN具有较短的学习周期,被用于训练Naive Bayes分类器输出的分类数据样本集,生成特征向量。
2 K-NB-BP模型的理论分析
2.1 K-均值聚类阶段
K-NB-BP模型首先采用基于分区、无监督式聚类分析的K-均值算法进行数据的聚类处理。假设入侵行为的类型数为k,则将包含x个数据的数据集划分为k个簇,K-均值算法的处理结果是使得同一簇内数据元素相似,而不同簇间数据元素相异,K-均值算法的详细执行过程参见算法1。
本文使用平方误差作为目标函数,用以表达聚类效果,选择欧几里德距离作为距离的度量,目标函数定义如下:
(1)
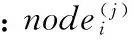
因本文仿真实验采用KDDCUP99的数据集,该数据集包含正常数据和DoS,U2R,R2L和Probe四种类型的攻击数据,因此通过K-均值聚类处理,训练集将被划分为五个数据子集,其中四个入侵数据子集,一个正常数据子集。
2.2 贝叶斯分类阶段
K-均值算法的聚类较为简单高效,但聚类结果较为粗糙,容易造成数据分类的缺损,利用朴素贝叶斯分类可以进行修补。
假设X={X1,X2,...,Xk},其中Xi是K-均值聚类处理后的数据集,C={C1,C2,...,Ch}为类别属性。则有如下贝叶斯公式:
(2)

局部贝叶斯网络的概率公式为:

(3)
令P(Ci|xij)=max{P(Ci|xij)},其中i=(1,2,...,h),xij为Xi数据集中的第j个数据。修复xij,将数据xij重新分类到Ci中。
2.3 反向传播神经网络阶段
在K-均值聚类和NaiveBayes分类后,输入数据使用BPNN训练生成必要的特征向量S={Y1,Y2,...,Yk},其中Yi表示经过朴素贝叶斯修正后第i个数据集,假设经过BPNN算法训练之后,数据的属性数目减少到l,Yi={a1,a2,...,al},在经过第i次BPNN处理之后将会得到数值ai。
为了产生更好的结果,在属性列表中添加友元参数μij,其公式定义如下:
(4)
3 K-NB-BP方法的仿真描述
实验采用Matlab 2014b进行仿真,实验数据采用KDD CUP99数据集,在预处理阶段,用到以下变量:
实例的个数In;
属性的个数An;
分类标签的个数Cn;
数据集Dm,n;
3.1 K-均值聚类阶段
输入:In,An,Cn,Dm,n;
输出:新的数据集NewDm,n
方法步骤如下:
从Dm,n中读取所有实例
For 每个实例In
[索引,标签]=K-均值(Dm,n,Cn, 欧式距离)
End for
用新索引号创建新的数组和标签类
NewDm,n
3.2 贝叶斯分类阶段
该过程提供了聚类数据的提取结果。
输入:NewDm,n,迭代次数N
输出:分类后的数据集Pm,n
方法步骤如下:
Forj= 0 toAn
A[j] =unique (NewDm,n)//去除类似的数据
End for
Fori=0 toN
Fork=0 toAn
If A[k].length( )=1
Pm,n= removecolumn[k] //去除重复的数据属性
End if
End for
End for
Model=NaiveBayes.fit(Dm,n, NewDm,n[:,N])/创建一个朴素贝叶斯分类器对象
Pm,n= Model. predict(NewDm,n)//对待判样本进行分类
返回Pm,n
3.3 反向传播神经网络阶段
BPNN被用于训练Naive Bayes分类器输出的数据样本集,生成特征向量。
输入:分类后的数据集Pm,n,仿真时间周期Tm,n
输出:ClassList[.]
方法步骤如下:
P’n,m= transpose(Pm,n)//倒置数据集
Net = Newff (P’n,m)//建立网络对象,初始化神经网络
Net = train (net,I,O)//进行网络训练
ClassList [ ]= sim(net,Tm,n)//网络预测输出
4 仿真实验结果分析
4.1 仿真实验环境及数据
实验采用Matlab 2014b进行仿真,服务器采用HP ProLiant ML10,内存8 G,3 100 MHz主频四核CPU,WIN 7操作系统。
实验数据采用KDD CUP99数据集,该数据集是对MIT Lincoln实验室1998年提出的DARPA入侵检测评估数据集的扩充。本实验使用约20%的kddcup.data.gz数据子集用作训练集,测试数据使用corrected.gz。数据集中连接记录包含22种攻击类型,所有攻击行为基本上被分为4大类:DoS,U2R,R2L和Probe,具体实验数据集描述如表1所示。

表1 实验所用数据集
4.2 实验评估公式
AN:输入样本的总数
DN:入侵样本的总数
RDN:正确检测到的入侵样本总数
RAN:正确检测到的样本总数(包含入侵样本和非入侵样本)
EN:被误报为入侵样本的总数
ZN:正常样本的总数
定义如下实验评估公式:
召回率=(RDN/DN)*100%
(5)
准确率=(RAN/AN) *100%
(6)
误报率= (EN/ ZN) *100%
(7)
4.3 准确率与误报率的实验对比
将本文提出的混合入侵检测模型K-NB-BP与Improved NB、H-C4.5-NB、 IKMNB和KFS四种入侵检测模型的准确率和误报率进行了详细实验对比,具体结果如图2、图3所示。
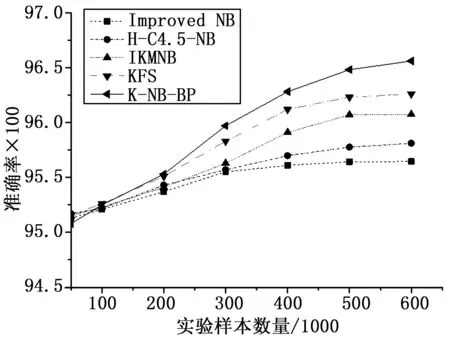
图2 准确率的对比
准确率的对比如图2所示,X轴数值为以实验样本数量的千分之一,Y轴数值为准确率的一百倍。总体上,随着数据样本数量的增加,5种入侵检测模型的准确率均呈上升趋势。具体分析实验结果如下:
1)实验样本数量从50×103增加到到100×103时,5种入侵检测模型的准确率相差不大。
2)实验样本数量从100×103增加到200×103时,K-NB-BP和KFS模型的准确率几乎相同,但相比其余模型已经有了较为明显的优势。
3)数据样本数量从200×103增加到500×103时,K-NB-BP、KFS和 IKMNB模型的准确率上升趋势较为明显,但K-NB-BP模型的准确率一直都是最高的。
4)实验样本数量从500×103增加到600×103时,5种模型的准确率都趋于稳定,但K-NB-BP模型的准确率相比其余4种模型优势明显。

图3 误报率的对比
误报率的对比如图3所示,X轴数值为实验样本的数量的千分之一,Y轴数值为误报率的一百倍。总体上,随着数据样本数量的增加,5种入侵检测模型的误报率均呈下降趋势,但K-NB-BP模型的误报率一直处于相对较低的位置。具体分析实验结果如下:
1)实验样本数量从50×103增加到到100×103时,5种模型的误报率相差不大,但K-NB-BP模型的误报率相对较低。
2)实验样本数量从100×103增加到400×103时,K-NB-BP模型误报率较低的优势逐渐明显。
3)实验样本数量从400×103增加到600×103时,5种入侵检测模型的误报率都趋于稳定,但K-NB-BP模型的误报率一直处于最低的位置。
4.4 不同攻击类型样本的召回率的对比
为了更全面地进行评估K-NB-BP模型的性能,同Improved NB、H-C4.5-NB、 IKMNB和KFS 4种入侵检测模型进行数据样本召回率的实验对比,实验结果如图4所示。

图4 不同攻击类型数据召回率的对比
图4中X轴表示不同的攻击类型,Y轴数值为样本召回率的一百倍。具体分析实验结果如下:
1)对于DoS和Probe攻击类型,5种入侵检测模型的样本召回率都比较高,且相差不大,但K-NB-BP模型的样本召回率稍占优势。
2)对于R2L和U2R攻击类型,IKMNB、KFS和K-NB-BP模型的召回率相比其余两种入侵检测模型优势明显。其中,对于R2L攻击类型数据,IKMNB模型的召回率提升约30%,KFS和K-NB-BP模型的召回率提升约40%。对于U2R攻击类型数据,IKMNB模型的召回率提升20%,KFS和K-NB-BP模型的召回率提升约30%。但K-NB-BP模型的召回率相比IKMNB模型优势不明显,而且对R2L攻击类型数据的召回率只有50%左右,对U2R攻击类型数据的召回率也只有近40%。主要原因是在KDD CUP99数据集中,R2L和U2R类别的数据样本本身就少,且这类入侵在行为模式上与正常数据较为接近,这也间接反映了数据样本的质量对入侵检测模型性能的影响。
5 结论
本文通过研究及改进常见的入侵检测模型,提出一种基于K-均值聚类算法、贝叶斯分类算法和反向传播神经网络混合入侵检测模型K-NB-BP。为了评估所提出入侵检测模型的性能,采用KDD CUP99数据集作为测试数据,利用MATLAB 2014b进行仿真,实验结果表明,K-NB-BP模型相比Improved NB、H-C4.5-NB、 IKMNB和KFS模型,可以取得相对较高的准确率和较低的误报率,而且不同攻击类型数据样本的召回率相对较高。因此,K-NB-BP模型对于改进现有的入侵检测模型有一定的实际应用价值。
但K-NB-BP模型仍需要从海量的数据样本中进行模式检测和实时识别,这是一个很耗时的问题。作者今后的研究重点是提高入侵检测模型准确率和召回率的同时降低算法的复杂度。
[1] 刘长骞. K均值算法改进及在网络入侵检测中的应用[J].计算机仿真,2011,28(3):190-193.
[2] Om H, Kundu A, A Hybrid system for reducing the false alarm rate of anomaly intrusion detection system[A]. International Conference on Recent Advances in Information Technology[C]. 2012:131-136.
[3] Shabtai A, Fiedel Y, Kanonov U, et al. Google Android:a comprehensive security assessment[J]. IEEE Security & Privacy, 2010, 8(2):35-44.
[4] Deshmukh D H, Ghorpade T, Padiya P. Intrusion detection system by improved preprocessing methods and Naive Bayes classifier using NSL-KDD99 Dataset[A].Proceedings of the 2014 International Conference on Electronics and Communication Systems[C].Piscataway: IEEE Press, 2014:1-7.
[5] Tsai C F, Hsu Y F, Lin C Y, et al.Intrusion detection by machine learning[R]. Expert Systems with Applications,2009, 36(10): 11994-12000.
[6] 王 辉,陈泓予,刘淑芬.基于改进朴素贝叶斯算法的入侵检测系统[J]. 计算机科学, 2014,41(4):111-119.
[7] Jiang L, Li C, Wu J, et al.A combined classification algorithm based on C4.5 and NB[A]. ISICA 2008:Proceedings of the third International Symposium on Advances in Computation and Intelligence[C]. LNCV 5370.Berlin: Springer-Verlag, 2008, 5370:350-359.
[8] 姚 潍,王 娟,张胜利.基于决策树与朴素贝叶斯分类的入侵检测模型[J]. 计算机应用, 2015, 35(10):2883-2885.
[9] 王 辉,崔静静,刘淑芬.基于IKMNB分类算法在入侵检测中的应用[J].计算机应用研究,2014,31(12):3673-3681.
[10] Wang G, Hao J X, Ma J, et al. A new approach to intrusion detection using Artificial Neural Networks and fuzzy clustering[J]. Expert Systems with Applications, 2010, 37(9): 6225-6232.
[11] Naoum R S, Abid N A, AlSultani Z N. An enhanced resilient backpropagation artificial neural network for intrusion detection system[J]. International Journal of Computer Science and Network Security, 2012,12(3):11-16.
[12] 邬斌亮,熊 琭.融合K-均值聚类、FNN、SVM的网络入侵检测模型[J].计算机应用与软件,2014,31(5):312-315.
OneMixedIntrusionDetectionModel
LiangBenlai1,YangZhongming2,CaiZhaoquan3
(1.College of Information Engineering , Zhongshan Polytechnic, Zhongshan 528404, China; 2.Computer Engineering Technical College, Guangdong Institute of Science and Technology, Zhuhai 519090, China; 3.Research Department, Huizhou University, Huizhou 516007, China)
One mixed intrusion detection model which combined with K-means algorithm, Naive Bayes algorithm and Back-Propagation neural network, was proposed to improve the accuracy of intrusion detection model. In this model, as a partition-based, unsupervised cluster analysis method, K-means method was firstly used to obtain the data sets that can be easily processed and learned by machine learning algorithm. Then, the outcomes of clustering were processed by Bayes classifier to get the essentical data attributes.. Next, filter data samples learning was implemented by Back Propagation Neural Network, which was able to learn the patterns with less number of training cycles. Finally, the mixed intrusion detection model was validated by experiments on KDD CUP99’s datasets. Attacks as DoS, U2R, R2L and Probe were detected via the mixed intrusion detection model. The simulation experiments results show that the higher accuracy rate, recall rate and lower error rate were obtained by the mixed intrusion detection model compared with other models. Furthermore, this mixed intrusion detection model also demonstrates some value of practical application.
intrusion detection model; mixed method; K-means; naive Bayes; back-propagation neural network
2017-01-24;
2017-02-19。
国家自然科学基金项目(61170193);广东省自然科学基金项目(S2013010013432);中山市社会公益科技研究项目(2016B2142)。
梁本来(1983-),男,山东济宁人,硕士,讲师,CCF会员(66132M),主要从事信息安全,网络路由方向的研究。
杨忠明(1980-),男,广东茂名人,硕士,副教授,CCF会员(16038M),主要从事信息安全方向的研究。
1671-4598(2017)04-0225-04DOI:10.16526/j.cnki.11-4762/tp
TP
A
蔡昭权(1970-),男,广东省陆丰人,硕士,教授,CCF会员(E2006137S),主要从事计算机网络方向的研究。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
法律方法(2021年4期)2021-03-16
法律方法(2021年4期)2021-03-16
健康体检与管理(2021年10期)2021-01-03
软件导刊(2018年11期)2018-11-19
现代计算机(2018年27期)2018-10-25
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
