
基于数据挖掘的海关风险分类预测模型研究
2017-05-15 08:52张弛海
海关与经贸研究 2017年2期
周 欣 张弛海
基于数据挖掘的海关风险分类预测模型研究
周 欣 张弛海*
海关业务每日产生的海量记录中蕴藏着数据“金矿”有待进一步挖掘,为加强海关风险识别的准确性,让大数据的价值进一步得到显现,本文采用数据挖掘分类分析的方法,对历史报关单数据进行分析,根据其查获情况,将有查获与否作为分类标号,建立分类模型对历史报关单进行分类,提取相关的规则,揭示数据中隐藏的规律并运用其规律进行预测,为报关单的风险评估预测提供参考。
数据挖掘;海关风险管理;预测模型
一、引言
目前,无纸化通关已覆盖所有海关,海关电子数据信息量呈现了爆炸式增长,数量巨大、来源分散、格式多样的大数据对海关服务和监管能力提出了新的挑战,也带来了新的机遇。海关作为进出境监管机关,大数据的运用将成为提高海关管理能力的重要手段。为积极落实一体化通关管理,深入贯彻海关全面深化改革方案,风险防控中心和税收征管中心建设需要依托进出口大数据的批量聚集和监控分析,进而实现海关通关流程的前推后移和科学改造。*欧阳晨:《海关应用大数据的实践与思考》,《海关与经贸研究》2016第3期。
大数据的运用包括“数据分析”和“数据挖掘”两个层面,它们的目的都是发现数据的价值,但是过程和方法有所区别。传统的“数据分析”一般分析目标相对明确,主要运用统计的方法从数据得到一些信息,不涉及深层规律的探讨。“数据挖掘”是探查和分析大量数据以发现有意义的规则和模式的过程,是在没有明确假设的前提下去挖掘信息发现知识,发现的是那些不能靠直觉和经验发现的规律,需要通过一定的方法和工具来进行挖掘。
数据挖掘根据目标不同可以分为预测型任务和描述性任务。预测性任务是根据其他属性的值预测特定属性的值,如回归、分类、离群点检测。描述型任务是寻找数据中有潜在联系的模式,如聚类分析、关联分析、序列模式挖掘。*蒋盛益:《商务数据挖掘与应用案例分析》,电子工业出版社2014年版。目前已有研究者对海关数据挖掘进行了探索,如喻宇应用异常检测的方法对重庆海关进出口数据的风险点进行了探索,*喻宇:《重庆海关进出口数据挖掘与分析》,重庆大学2008年硕士论文。周博等研究了数据挖掘技术在海关旅检风险分析系统当中的应用,*周博、潘欣、何忠林等:《数据挖掘技术在海关旅检风险分析系统当中的应用》,《上海海关学院学报》2008年第4期。周欣从知识管理的角度对海关数据挖掘和文本挖掘方法进行了展望。*周欣:《知识管理在海关风险识别中的应用探索》,《海关与经贸研究》2014年第4期。
本文采用数据挖掘分类(Classification)分析的方法,对历史报关单数据进行分析,根据其查获情况,将有查获与否作为分类标号,建立分类模型对历史报关单进行分类,提取相关的规则,为现有报关单的风险评估预测提供参考。
二、基于CRISP-DM的数据挖掘流程
本文采用“跨行业数据挖掘过程标准”CRISP-DM(Cross-industry Standard Process for Data Mining)展开研究,CRISP-DM是标准的数据挖掘处理流程,将一个数据挖掘项目的生命周期分为六个阶段,包括业务理解、数据理解、数据准备、建模、评估和部署。
(1)业务理解。作为数据挖掘的第一阶段,从业务的角度了解项目的需要和最终需求,同时将需求转化为目标并制定初步的实现计划。
(2)数据理解。经过数据收集,经过特定的处理,使数据分析人员熟悉数据,发现数据的质量问题,理解数据的内部属性,提出关于数据所包含信息的相关假设。
(3)数据准备。从源数据中构造适合挖掘的数据集,便于将这些数据输入模型。这些工作包括选择表、记录和属性,同时转换和清洗数据。
(4)建模。对已经预处理的数据进行分析,选择和应用不同的建模技术,构建模型,调整参数。
(5)评估。对模型结果进行评估,回顾检测挖掘探索过程,保证模型可以满足业务需求。
(6)部署。根据业务需求,将数据挖掘结果制作分析报告,供决策人员参考。
在实际应用中,上述六个步骤不是一次性执行而是人机交互,反复迭代、不断完善的过程,在不同阶段之间来回反复以逐步完善,如图1所示。
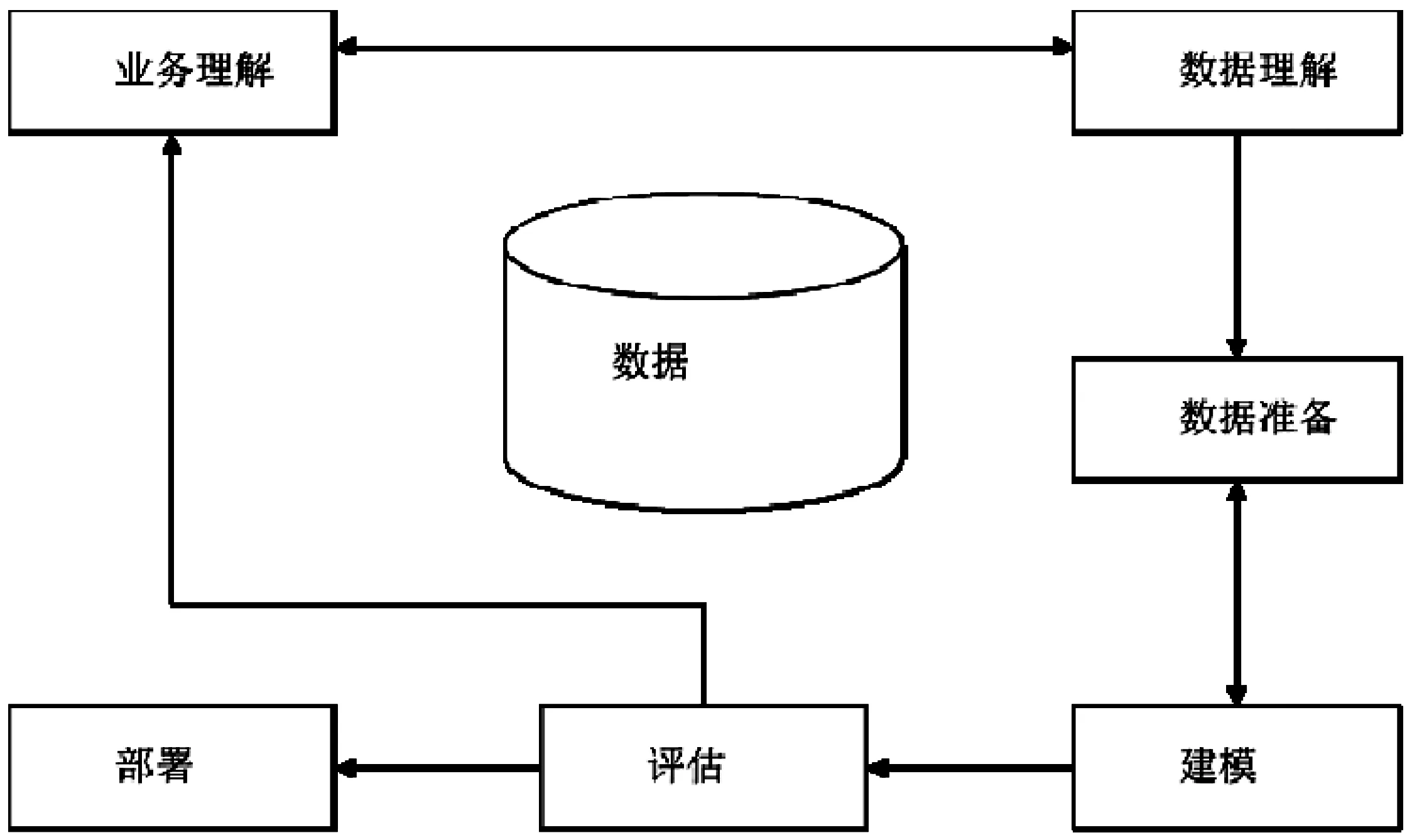
图1 CRISP-DM流程图
三、报关单分类预测模型
(一)业务理解
企业向海关进行申报后,海关需要对这些报关单进行风险分析,从而决定是否进行查验。因此,需建立一个具有较高的预测准确度的报关单分类预测模型,来进行报关单风险判断。本文数据挖掘目标是根据历史报关单数据中发现有查获的报关单的风险特征和规律,这样就可以利用这些特征和规律来判断报关单的风险程度,为今后海关报关单风险评价提供参考。
为此,本文根据企业的查验处理结果对数据进行分类标号,将表示查验处理结果的字段设为目标字段,其余字段作为训练模型的预测字段。
(二)数据理解
本文挖掘的数据为模拟进口报关单数据,分布在不同商品税号、不同企业、不同监管方式下,其中查验处理结果为未查获的报关单占82.73%,有查获的报关单占总量的17.27%。
数据集12共含25个报关单数据字段,具体包括单证号码、进出口标志、运输方式代码、经营单位注册关区、经营单位注册地区、经营单位性质、企业级别、监管方式、件数、毛重、查验处理结果(代码)、商品编号、商品名称、商品规格、产销国、第一(法定)数量、商品单位、申报单价、成交币制、成交总价、注册资本(万)、注册资金币制、行业种类、注册日期、商品序号。
(三)数据准备
查验处理结果(代码)中代码种类过多,为简化计算,根据该特征值生成新的标志特征值,“查验处理结果”为“02”的设置其“查验结果标志”为“0”,其余有查获的设置其“查验结果标志”为“1”。原“商品代码(HS编码)”与“产销国”特征值过多,不利于发现数据间的共性,且加大了挖掘的计算量。因此对其进行截位,得到商品代码第一和第二位(导出商品代码12)及产销大洲两个新属性。此外,为加快运算速度,“注册资本”、“毛重”、“成交总价”进行了连续变量离散化的区间分段处理。
在进行数据过滤后得到16个输出属性,部分属性的样本分布如图2所示,柱状图分为上下两个部分,上部查验结果标记为“0”为无查获报关单,下部位查验结果标记为“1”的有查获报关单。从样本图形分布说明查验结果标记在各个特征中分布比较均匀,针对单个特征的分析可能很难获得满意结果,应考虑使用更为全面、深入的模式识别算法进行挖掘。
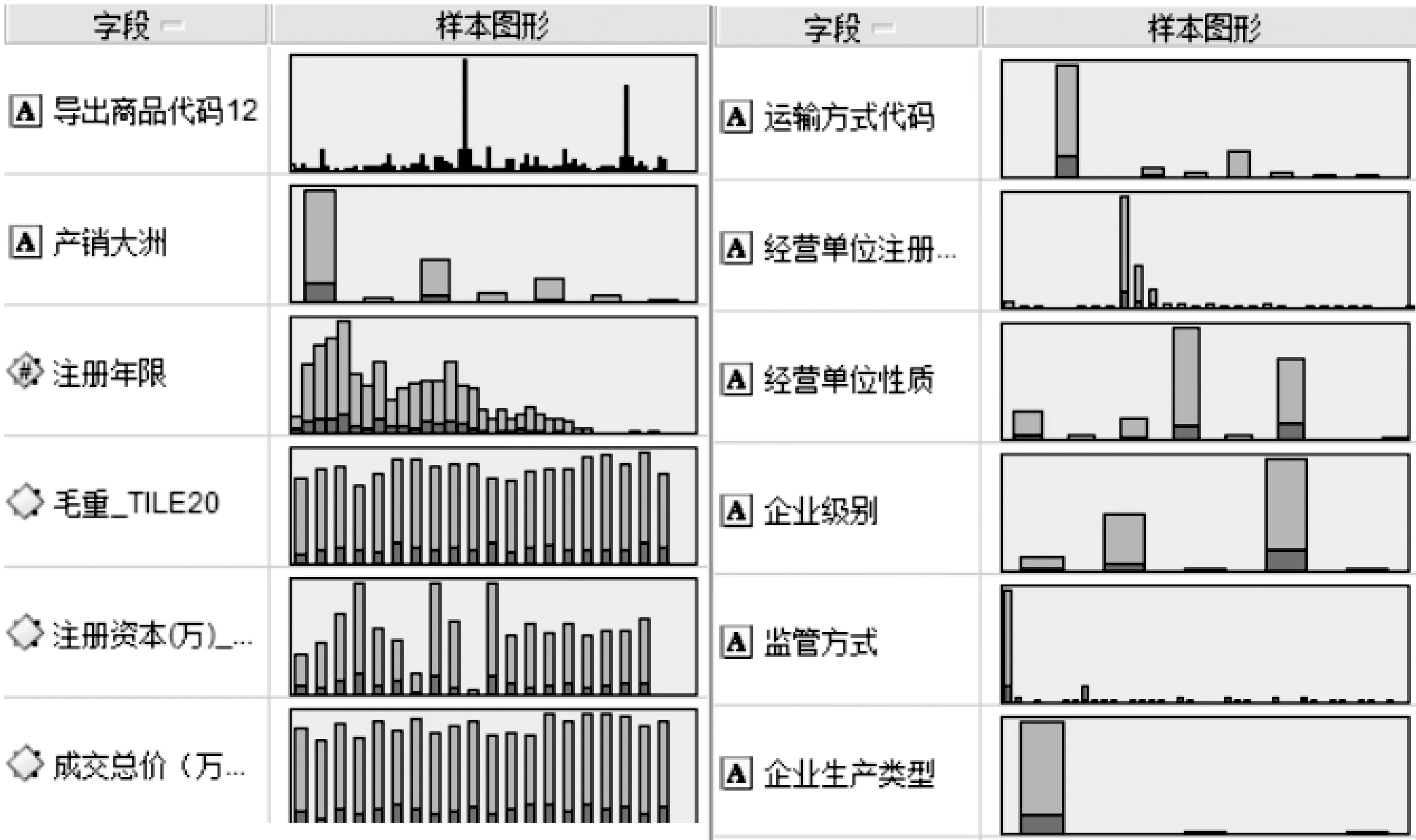
图2 主要属性的样本分布图
(四)建模——决策树模型
本次挖掘抽取70%的数据作为训练集,剩余30%数据作为测试集,在挖掘方法上选用决策树(Decision Tree)分类方法,决策树分类利用树形结构来表示决策集合,这些决策集合通过对数据集的分类产生规则。该方法分类速度快,决策树模型简单直观,易于理解,可以清晰显示哪些字段比较重要,及可以生成容易理解的规则,因此决策树分类以其特有的优点已得到了广泛的应用。
本次挖掘选择了软件内置的二元分类器进行训练和评估。其中涉及到的决策树算法有Quest和CHAID。
决策树是一种树形结构,一个典型的决策树包括决策节点、分支和叶节点三个部分,如图3所示。其中决策节点代表某个测试条件,通常对应于待分类对象的某个属性,在该属性上的不同测试结果对应一个分支。每个叶节点存放某个类标号值,表示一种可能的分类结果。决策树可以对未知样本进行分类,分类过程如下:从决策树的根节点开始,从上往下沿某个分支往下搜索,直到叶节点,以叶节点的类标号值作为该未知样本所属类标号。在生成决策树后,可以观察树的各级分支,找出目标特征较为集中的叶节点,发现其中的规律。
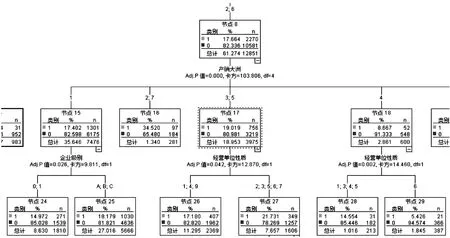
图3 CHAID决策树局部
对样本总体,有查获的报关单占总量的17.27%(标记为“1”),没有查获的报关单占82.73%(标记为“0”)。图3中几个叶节点中标记为“1”的报关单占比如图4所示。
其中节点16的标记为“1”的有查获报关单比例达34.52%,显著高于样本数据17.27%的查获率,说明该节点为高风险节点,读取决策树分类规则得出:监管方式为“0110、0845、1200、2700”,且运输方式代码为“2、6”,且产销大洲为“2、7”的风险比较高。
而节点29标记为“1”的有查获报关单比例为5.43%,显著低于样本比例,说明该节点为低风险节点。其分类规则为:运输方式代码为“2、5、8、9、Y”且监管方式为“0300、0444、0544、0700、0815、1741、2600、3100、5034、5335、9600、9900”的风险比较低。
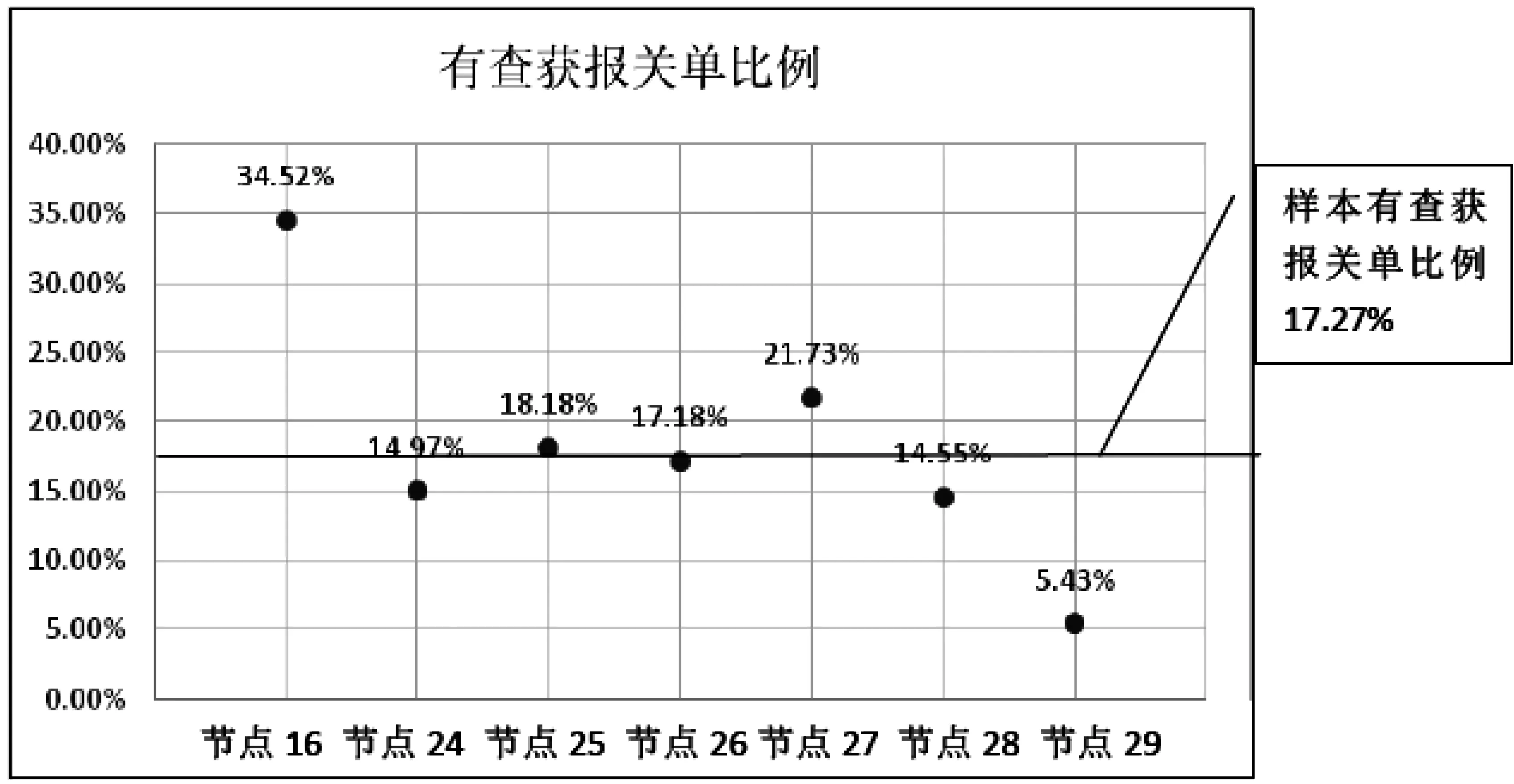
图4 决策树叶节点有查获报关单比例(标记为“1”)
类似的,如图5所示,在节点0(根节点)标记为“1”(即有查获)的报关单为17.427%,而在节点3中,该节点下目标特征为“1”的比例极大,说明符合该属性的项风险极大。
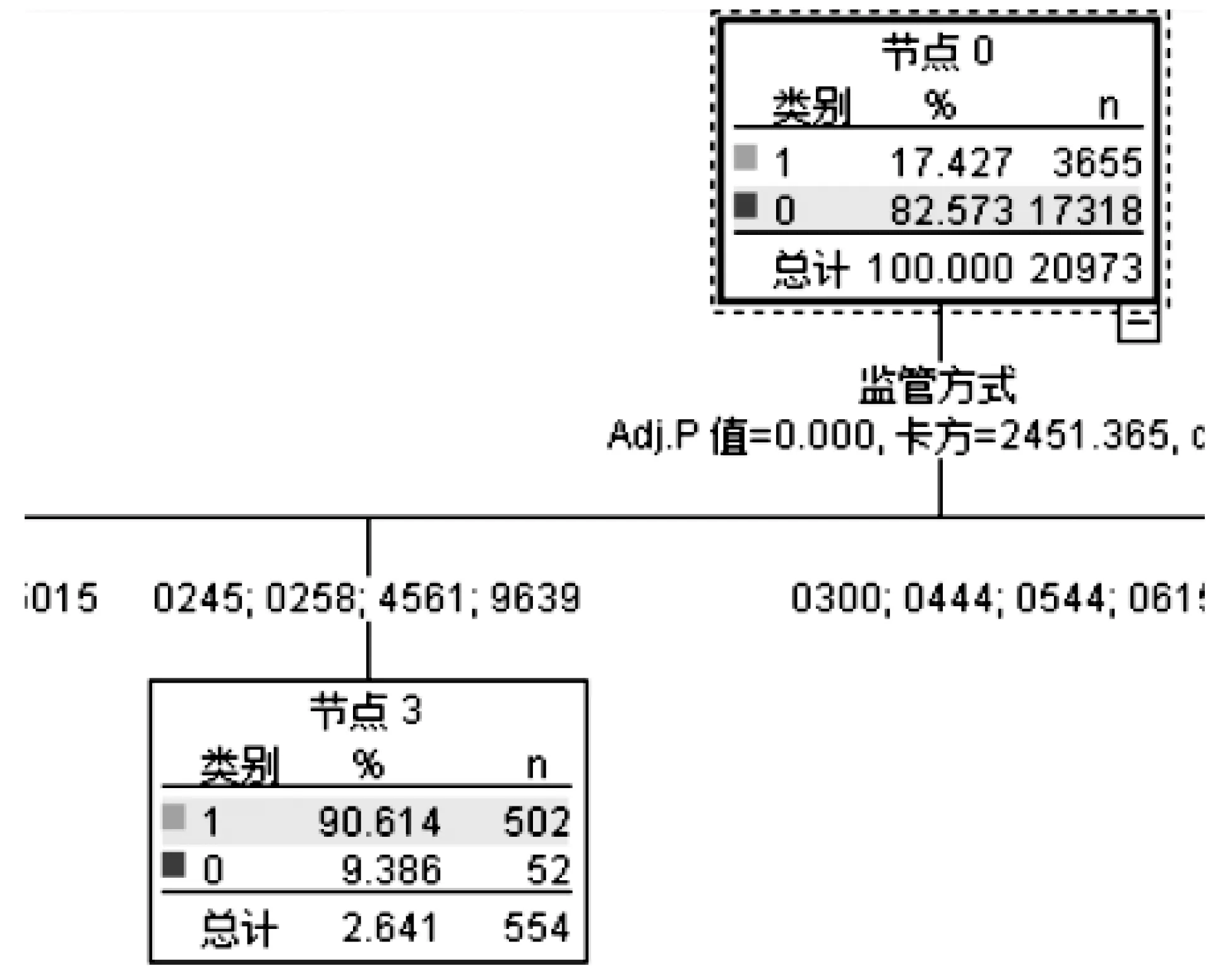
图5 决策树叶节点显示高风险区域
由此,决策树模型生成规则集,用判定规则来表示决策节点。在图6的规则集为:监管方式为“0245”、“0258”、“4561”、“9639”的数据集将被分类标注为“1”,是高风险报关单,其余则为标记为0,为低风险报关单。决策树生成的规则相比其他模型更容易理解,更具实践意义。

图6 决策树生成的分类规则
同时,决策树还可以对各输入属性对分类结果影响的重要性进行排序,在本例中,对查验结果影响最高的几个属性分别为“监管方式”、“运输方式代码”、“企业类别”、“产销大洲”“经营单位性质”、“注册年限”,其重要性具体数值如图7所示。
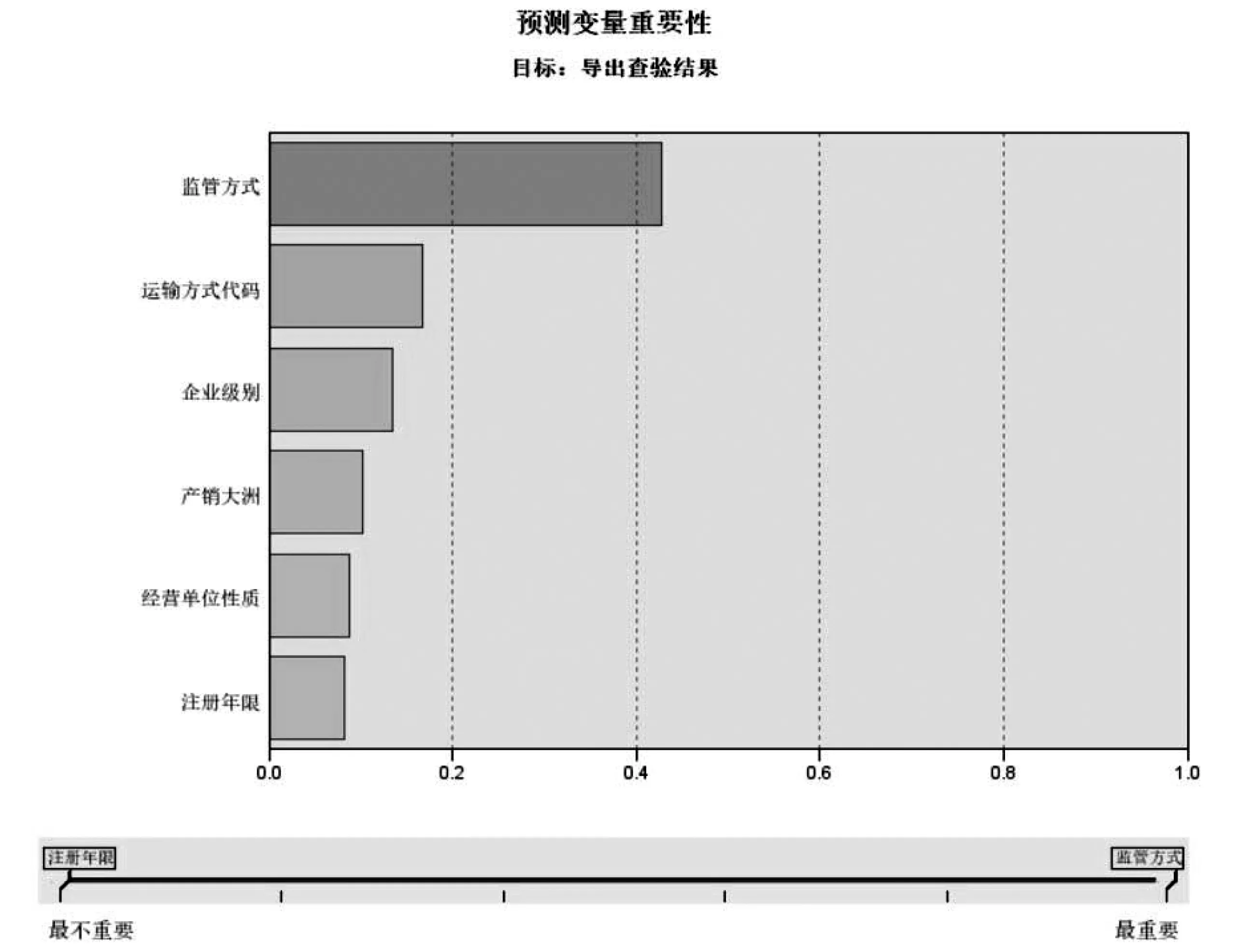
图7 输入属性的重要性比较
(五)模型评估
(1)模型筛选
各模型进行训练之后,就要利用测试集对各分类模型根据预测准确度进行分析评估,评估出预测准确度最高的模型。根据以上各模型的输出结果分布,以及二元分类器下的模型输出分布,筛选出最大利润较大、构建时间较短的模型进行下一步分析。如图8所示,二元分类器共生成三个模型,其中Quest和CHAID的总体精确性较高,予以采用,而决策列表的准确性相对较低,予以放弃。
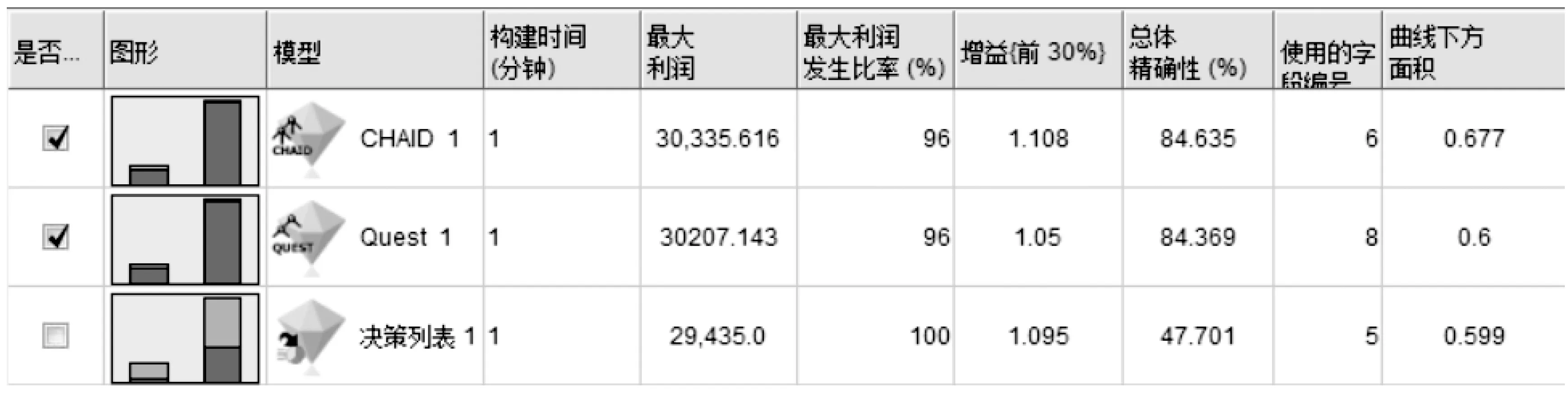
图8 二元分类器输出
在数据挖掘的过程中,往往会用到多种算法,如C5.0、Quest和CHAID等决策树分类算法、Logistic回归、贝叶斯分类、神经网络等,对于不同算法得出的预测结果,往往各有千秋,因此,可以采用集成学习法(EnsembleLearning),将多个学习方法聚集在一起来提高分类准确率和模型的稳定性。集成学习法由训练数据构建一组基分类器,然后对每个基分类器的预测进行投票来实现分类,然后在分类未知样本时以投票策略继承它们的预测结果,且通常一个继承分类器的分类性能会好于单个分类器。本文通过整体节点来构建继承分类器,利用Quest和CHAID算法产生基分类器后,利用整体节点进行集成。整体节点会根据各模型的置信度加权投票,对每一项预测确定最终的结果。
(2)预测结果评价
在采用集成分类后的测试集最终输出结果如图9和表1所示。其中,图9中标注为“0”的是测试集中实际没有查获的样本,标注“1”的是测试集中实际有查获的样本,分别占比“82.61”、“17.39”,而经计算机分类预测得到有查获的部分为左侧部分。具体数值详见表1测试集预测结果判错矩阵,命中报关单211票,未命中的报关单为1359票,命中率为13.4%,查验率为2.67%,查获率为87.9%,尽管命中率相对较低,但以较低的查验率获得了较高的查获率。

表1 测试集预测结果判错矩阵

图9 测试集预测结果
(3)误分类成本参数敏感性分析
由于把高风险申报归入低风险类,比把低风险类申报归入高风险类的损失更大,因此可以通过调节决策树的误分类损失参数,来指定不同类型预测错误之间的相对重要性,输入自定义的损失值后,当对决策树进行剪枝时,在计算误分类损失的过程中,将把这些自定义损失值作为权重来影响误分类损失的计算结果。
系统对误分类损失默认设置为1,将误分类损失提高至2至5后,其查验率和查获率如图10所示,可见调高误分类损失参数将使得模型提高查验率,但同时查获率有所降低,但将误分类损失提高至5以上时,查验率大幅上升,查获率明显降低。因此,可以得出这样的结论,通过调整误分类损失参数可以调节目标查验率,并需要选择合适的参数来实现投入最少资源获得最大风险甄别的目的。
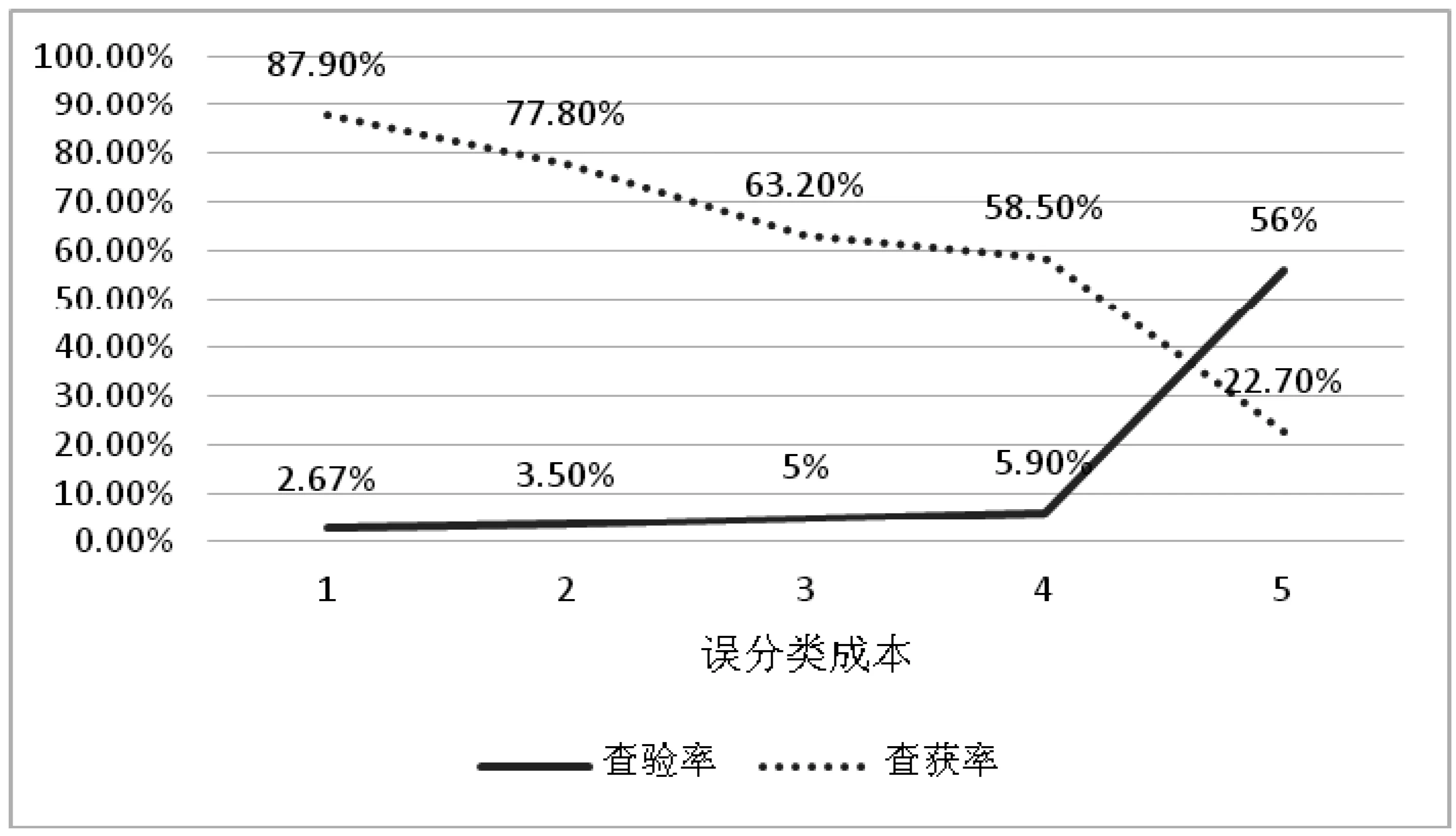
图10 不同误分类成本下的查验率与查获率比较
四、结论与展望
尽管预测模型仅覆盖了少部分风险,但其低查验率高查获率的结果体现了预测模型总体性能值得肯定。结合不同领域不同地区的实际需要,将会对模型性能产生不同的需求,因此,可以在高风险区域可运用较为严厉的模型,保证查获的风险数量;低风险区域可运用查获率较高的模型,兼顾效率。或者用较粗略的模型先提示风险程度,在选取风险较高的项利用复杂模型进一步判别,灵活运用不同的模型,发挥各模型的长处,回避其不足,将模型的效用最大化。
此次数据挖掘主要目标是探索数据挖掘模型处理海关数据的可行性,验证其是否能发现风险中的规律。从结果来看,确实发现了一些规律。但生成的模型依然比较简单,模型的预测性能还没得到完全的发挥。如果加强数据预处理,针对海关风险特点,按照不同商品、不同地区、不同贸易方式等对模型进行相应的优化,相信能构建出更加有效的模型,发挥出更大的风险识别功能,有待今后进一步研究探索。
(责任编辑 赵世璐)
Customs Risk Classification and Forecasting ModelBased on Data Mining
Zhou Xin,Zhang Chihai
The daily record of mass production of customs business contains the data “gold mine” to be further excavated. In order to strengthen the accuracy of customs risk identification and make full use of the value of big data, classification analysis of data mining is adopted to analyze the data of historical customs declaration. The records are tagged as hit or not hit according to its hit result. The classification model classifies the historical declarations, extracts the relevant rules, reveals the hidden rules in the data and uses the rules to predict. The result could be applied in the risk assessment and forecast of the declarations.
Data mining; Customs Risk Management; Forecasting Model
周欣,上海海关学院海关管理系讲师、管理学博士;张弛海,上海海关风险管理处。
猜你喜欢
艺术品鉴(2020年7期)2020-09-11
中国外汇(2019年19期)2019-11-26
中国外汇(2019年20期)2019-11-25
成都信息工程大学学报(2019年3期)2019-09-25
近代史学刊(2019年1期)2019-08-24
对外经贸实务(2018年9期)2018-10-20
现代营销(创富信息版)(2018年10期)2018-10-12
电子制作(2018年16期)2018-09-26
进出口经理人(2018年9期)2018-09-14
对外经贸实务(2017年6期)2017-06-19
