
基于RS-IA数据挖掘的配电网故障定位模型
2017-05-22 02:44车延博郁舒雁葛磊蛟
电力自动化设备 2017年5期
车延博,郁舒雁,葛磊蛟
(天津大学 电气自动化与信息工程学院,天津 300072)
0 引言
配电网故障定位是配电自动化的重要功能之一。当配电网实际出现故障后,通过故障定位功能可快速找出故障发生的区域,为隔离故障和尽快恢复用户供电提供有效指导,对提高供电可靠性具有重要意义。配电网故障定位一般包括故障告警、故障相关性分析和故障精确定位3个步骤。
目前,基于馈线终端单元(FTU)上报故障信息进行配电网故障定位的分析方法主要有2类:一类是配电网故障区段判断和隔离的统一矩阵算法,这种诊断方式基于健全信息进行故障定位,较为传统,可靠性高,但对计算内存要求较高且诊断能力有限[1-4];另一类是近些年兴起的人工智能化故障诊断方案,这类方案能够基于非健全的故障信息进行诊断定位,主流的方法有专家系统、人工神经、模糊理论、遗传算法GA(Genetic Algorithm)和免疫算法IA(Immune Algorithm)等[5-9]。由于FTU大多位于室外,受自然环境影响较大,故使用矩阵算法得到错误故障信息的可能性偏高。在人工智能故障诊断方面,国内外一些学者进行了研究,文献[10-11]将改进的GA用于配电网故障区段定位,虽然该算法能够处理配电网信息畸变而造成故障定位误判的情况,但其在运算过程中进行随机的迭代搜索,结果容易产生局部最优;文献[12]针对IA能够进行全局搜索的优点,将IA应用于配电网故障定位,效果优于GA。近些年,也有学者采用数据挖掘DM(Data Mining)技术,通过对已有数据库进行分析,挖掘出相关性数据特征,为发现问题规律、寻找解决方案提供参考信息[13]。文献[14]应用基于粗糙集 RS(Rough Sets)理论和 GA相结合的数据挖掘模型来进行信息发生丢失或畸变情况下的配电网故障定位分析。比较发现,该方案定位诊断的正确率远高于常规人工神经网络ANN(Artificial Neural Network)模型。
大体而言,IA与GA都运用群体搜索策略,算法结构基本一致,但GA更容易陷入局部最优。针对户外FTU获取的配电网故障信息存在不确定性的情况,本文借鉴基于RS和GA相结合的数据挖掘模型,提出基于RS和IA相结合的数据挖掘技术,构建配电网故障定位模型。首先,通过RS理论获取故障信息,将已有的变异故障模式集转化成RS理论中的决策表,并利用IA理论进行决策表的属性约简,挖掘出该问题中输入矢量(条件属性)与输出矢量(决策属性)的关联性规则;然后,利用此数据挖掘方法处理FTU实时输入信息的畸变,根据各分段开关的电流越限信息序列,判断各段线路故障状态,实现配电网的故障定位;最后,与基于RS-GA数据挖掘模型进行对比,仿真结果表明利用IA能够较好地求得RS决策表中的最佳属性约简,所提模型在故障定位分析过程中能有效地克服信息畸变的情况,具有较高的容错性和有效性。
1 基于RS-IA数据挖掘模型的故障定位原理
1.1 概述
数据挖掘通常与计算机科学有关,并利用人工智能、统计学、数据库技术、情报检索和模式识别等诸多方法。它通过分析每个数据,从大量数据中寻找规律,并尽可能以人们可理解的形式将数据表示出来[13,15-16]。RS 理论是一种处理模糊与不确定性知识的数学理论,是信息科学的研究热点之一,已经在医学、材料学、机械、管理科学等领域得到了广泛应用。IA是一种通用的随机搜索优化算法,它借鉴、利用生物免疫系统的原理和机制,具有免疫记忆特性、抗体的自我识别能力和免疫的多样性特点,拥有高效的全局优化搜索能力[17-18,26-27]。基于 RS-IA 数据挖掘技术构造故障定位模型,能够快速实现故障信息畸变或丢失情况下的故障诊断,具有较高的正确率和容错性。
1.2 RS理论
RS理论能够有效地分析不准确、非一致、不完全的各种模糊信息,对数据进行推理和总结,从中发现深层的知识,揭示预测规律[17,19]。
RS 中的一个信息系统由 S=(U,A,{VT},T)表示,其中,论域U、属性集合A均为非空有限集合;VT为属性TϵA的值域;映射T用来为U中每个对象赋予相应的属性值,为单值映射。若C∪D=A且C∩D=,则称该信息系统为决策表(DS)。其中,C中的属性称为条件属性,D中的属性称为决策属性,通常用(U,C∪{D})表示决策表。决策表为一张二维表格,行表征对象,列表征对象属性。根据决策表可以产生相应的决策规则,且由于决策表的属性并不是同等重要的,因此删除其中某些不重要的属性不会影响决策表的决策和分类判断能力[20]。
属性约简作为RS理论的核心内容,指以保证信息系统分类能力一致为前提,删除对决策影响较小的冗余属性,得到待求问题的最优解,即使得根据约简后的条件属性和全部条件属性对决策属性D所形成的分类相同[21]。对于给定的决策表S=(U,C∪{D}),条件属性集合C的约简是指C的一个非空子集C′,满足:IND(C′,{d})=IND(C,{d});不存在 C″⊂C′,使得 IND(C″,{d})=IND(C,{d})。其中 IND()表示不分辨关系。
所有条件属性C的约简的交称为C的核Core(C)。对于核,有 Core(C)={aϵC|KC-a≠KC}成立。
1.3 IA
约简可以理解为以最简单的条件属性的组合形式表示决策表中的决策属性。但随着属性表的变大,约简的计算难度将增加。一个决策表的属性约简并不是唯一的,得到决策表的最佳属性约简已被证明是NP完全问题[22],在大数据量、高维数的决策表上进行最佳约简的求解至今还没有公认、通用、高效的解决方法。许多学者应用启发式搜索算法来进行属性约简,虽计算速度快,但得到的不一定是最佳约简[23]。文献[24]提出了运用基于GA的属性约简方法,在约简过程中相对缩小了搜索空间,取得较好的效果,但易于出现“早熟”现象。为了避免进行盲目的随机搜索或穷举搜索,能快速获得最佳属性约简并提取规则,可利用IA的全局寻优能力对领域知识进行智能式搜索。文献[22]将RS与IA结合,进一步提高了寻找最佳约简的效率,提高了算法全局搜索能力,较好地求解出了最佳属性约简集合。
IA是模拟生物免疫系统行为的一种仿生算法,其将优化问题的求解过程模拟成免疫系统发现抗原并进行抗体进化的过程,通过不断选择、交叉和变异找到最优抗体来求解问题,抗原和抗体分别对应于待优化问题和问题的最优解[22]。该算法主要包括问题识别、产生抗体群、计算亲和力、生成免疫记忆库、抗体的促进与抑制、抗体群更新6个过程,其流程如图1所示。
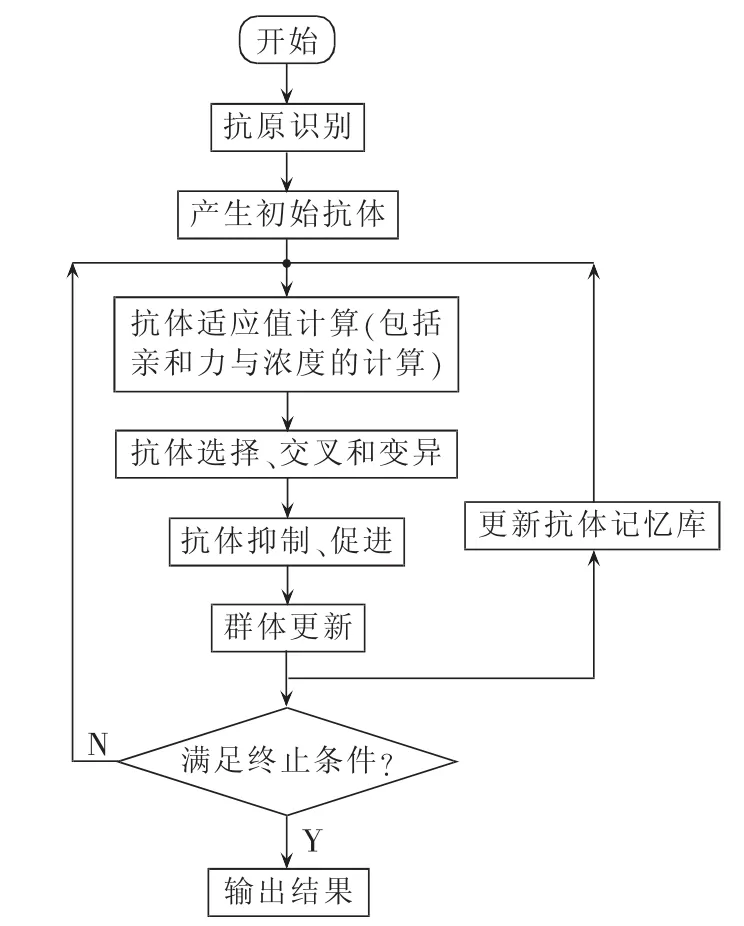
图1 IA流程图Fig.1 Flowchart of immune algorithm
2 基于RS-IA数据挖掘模型的故障定位
基于RS-IA数据挖掘模型的故障定位主要是利用RS来提取领域知识,获取待求问题的输入矢量与输出矢量的相关性规则[14]。为了减少对故障模式空间进行盲目的随机或穷举搜索,避免陷入局部最优的情况,采用IA对故障模式信息进行智能式搜索,在保证信息系统分类能力不变的前提下,删除冗余属性,寻求最佳属性约简。
基于RS-IA数据挖掘模型进行故障定位的具体步骤如下:
a.根据信息系统相关知识,构造故障挖掘数据库;
b.提取故障特征,确定相应对象的条件属性和决策属性;
c.依据已定的条件属性与决策属性,将故障模式集合转换成RS决策表;
d.把从决策表中求取约简的问题转化为在区分矩阵中求取组合数最小的约简,借助IA求得最佳属性约简;
e.从最佳属性约简集中提取规则;
f.依照生成的故障定位规则进行故障区段定位。
借助IA求解最佳属性约简的算法流程如下。
a.计算决策属性D对条件属性C的依赖程度KC。令 Core(C)=,依次去掉某单个属性 a ϵ C,若KC-a≠KC,则 Core(C)=Core(C)∪a,即核为Core(C)。若KCore=KC,则Core为最佳属性约简,否则实行步骤b。
b.产生初始抗体群及其编码。本文采用二进制编码方式,抗体的长度即条件属性C的个数,抗体的每一位基因代表对应条件属性的取舍状态,1表示约简时选择该条件属性,0表示舍去该条件属性。初始化时,核中的条件属性对应位取1,其余位随机取0 或 1。抗体的表现形式为[0,1,1,…,0,1],由此产生规模为N的初始抗体群。
c.计算亲和力。抗原与抗体之间的亲和力表示可行解对问题的满足程度,亲和力越高,说明解越好。本文选取的亲和力函数为适应度函数的倒数,适应度函数为:
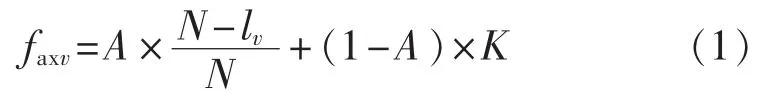
其中,N为条件属性的个数;lv为抗体v中“1”的个数,即约简后的条件属性个数;A为调节因子;K为依赖程度。
d.计算抗体浓度。首先计算两抗体间的亲和力:

其中,differvw为2个抗体间的结合强度,即相同位置基因编码值不同的个数。
大部分学生还在单纯依靠背诵的方式学习文化这部分的知识,而不会选择理解、合作讨论、自主探究的方式进行学习,充满被动性,他们更加倾向于把课后所有学习时间放在背诵之前所画的知识点上,出现了本末倒置的错误。这导致学生死记硬背,不能灵活运用知识点,在课后习题和日常考试中,在面对源于知识却又高于知识且变化多端的选择题、材料题时感到无从下手,成绩下降。有一些高中生普遍缺乏文化参与的热情,故而难以在实践中运用、检验所学知识。
则抗体v在种群中的浓度为:

其中,Tac1为免疫选择设定阈值。
e.抗体的促进与抑制。为了保证抗体的多样性,提高亲和力大的抗体的浓度,但抗体浓度过高就会被抑制,反之相应提高低浓度抗体的产生和选择概率。
f.更新记忆库。将各抗体群中高亲和力、低浓度的s个抗体存储在记忆库中并不断更新。
g.进行选择、交叉和变异操作,形成下一代父代抗体群。
h.满足终止条件则结束,输出结果;否则转步骤c。
根据得到的最佳属性约简可导出决策规则。配电网故障发生时,可利用已知的故障诊断决策规则快速进行故障定位。
3 基于RS-IA数据挖掘模型的配电网故障定位
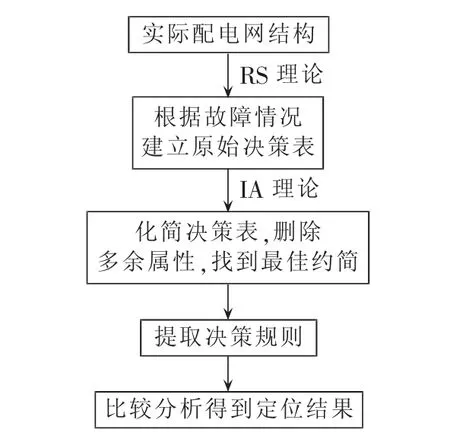
图2 故障定位模型Fig.2 Model of fault location
由于配电网大多都采取开环运行,其可等效解耦成若干个单一树干网的形式,因此可将对复杂网络的故障诊断简化为对某一单树干网的故障区段定位。考虑到来自FTU的故障信息极易丢失或变异,本文按获取信息中出现一位畸变信息来构造故障模式集,预先构建好线路元件数目不等的单畸变信息树干网故障定位模型,作为决策规则数据库。故障模式信息组成为:输入为各开关(包括断路器、分段开关、联络开关等)的电流越限信息序列,将各开关从进线开关(断路器)开始依次排列,在故障元件线路之前的开关有故障电流流过,“1”表示有电流越限信号,之后的开关无电流越限信号以“0”表示;输出为线路元件的状态序列,线路处故障状态用“1”表示,正常状态用“0”表示。
将构造的故障模式数据库转化为RS中的决策表,其中输入矢量集合为条件属性集合,而输出矢量集合形成决策属性集合。利用IA理论进行属性约简,去掉决策表中的冗余属性,求得最小条件属性组合,即最佳属性约简。依据最佳属性约简,提取出隐含其中的相关决策规则,可形成决策规则数据库。
配电网发生故障后,安装于各开关处的FTU检测到故障电流,与预定的故障电流定值比较后形成离散的故障信息。当FTU收集到的故障报警信息被上传到控制主站后,可根据基于RS-IA数据挖掘模型得到的决策规则,分析分段开关电流越限信息与故障线路位置间的关系,找出该分段开关电流越限信息所对应的线路故障状态,从而对配电网故障线路进行正确定位。
本文所构建的故障定位模型与基于RS-GA的数据挖掘模型结构大致相同,但是RS-GA仅根据亲和力评价、选择个体,而本文模型在评价、选择个体时是根据个体的亲和力和浓度进行的,这就增加了群体的多样性,避免算法陷入局部收敛,而且增加记忆单元,保留部分最优群体,避免交叉、变异过程使群体退化。所提模型的构建将配电网的故障定位问题转化成了一个化简RS决策表、提取决策规则的问题,并采用IA来求取最佳约简,实现了配电网故障区段的准确定位,具有高度的容错性。同时,该模型将复杂的配电网故障定位问题化简为简单的单个树干网故障定位,所建立的决策规则库具有通用性,基本适用于大部分配电网的网络拓扑结构。
4 算例分析
实际工程运行经验表明,配电线路故障中单一故障的发生概率占故障总数的70%~80%,所以本文以假定的单一故障来进行仿真。以一个典型的三电源环网开环运行配电网为例,其网络拓扑如图3所示。图中有 3 个断路器(Z1—Z3)、2 个联络开关(SL1、SL2)、16 个分段开关(S1—S16),19 条馈线对应 19 个定位区段。以断路器为标志,以联络开关为界限可以分为3个独立配电区域。
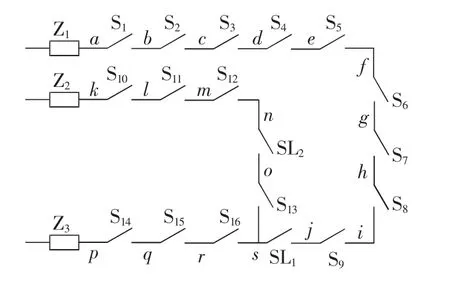
图3 三电源环网开环运行配电网Fig.3 Distribution network with three power sources in open-loop operation
4.1 计及信息畸变的故障定位分析
基于RS-IA数据挖掘的配电网故障定位模型对配电网进行全面仿真。根据数据挖掘故障模式的构造原则,该线路的基本故障模式应为11个(10条线路故障和无线路故障模式),故障样本输入矢量由10个元素构成。考虑可能出现一位元素畸变的原则,每个基本故障模式可衍生出10个变异模式,共有110个模式。
用IA在广义故障模式集中进行全局优化搜索,求取RS的最佳属性约简。本文记忆库容量取30,种群规模为60,交叉概率pc为0.5,变异概率pm为0.05,浓度阈值取0.7,算法迭代次数的最大值设为150。挖掘所得到的故障定位最佳属性约简见表1。
为了能清晰地说明研究问题的实质,从全部仿真中提取一个具有10条线路、9个分段开关的树干网,用有一条线路发生故障时的具体实例来描述。树干网如图4 所示,其中 a、b、…、 j为线路,S1—S9为分段开关。
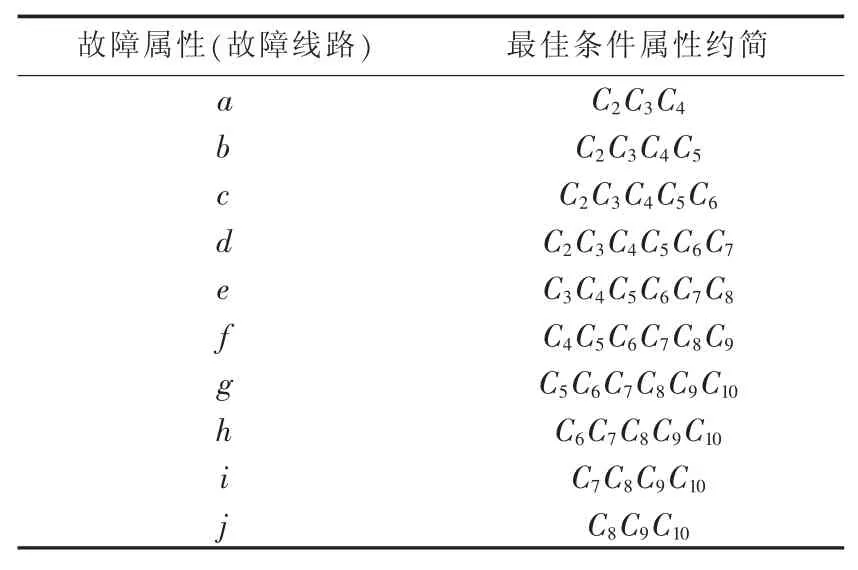
表1 故障定位最佳属性约简Table 1 Optimal attribute reduction for fault location
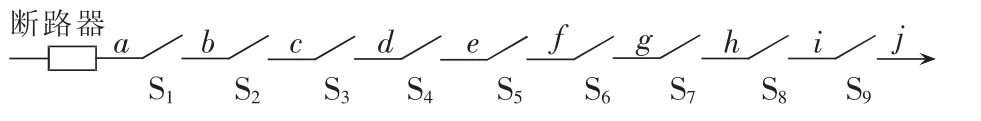
图4 树干网Fig.4 Trunk network
以线路b发生故障为例,利用IA求取RS最佳约简的收敛曲线如图5所示。
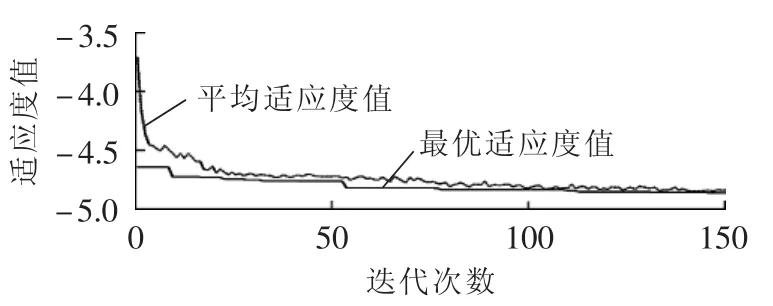
图5 IA收敛曲线Fig.5 Convergence curves of immune algorithm
基于RS-IA数据挖掘故障定位模型得到的配电网故障模式及形成的诊断结果如表2所示。其中,输入元素中标注*的为畸变信息位,输出元素中标注#的为错判的元件。
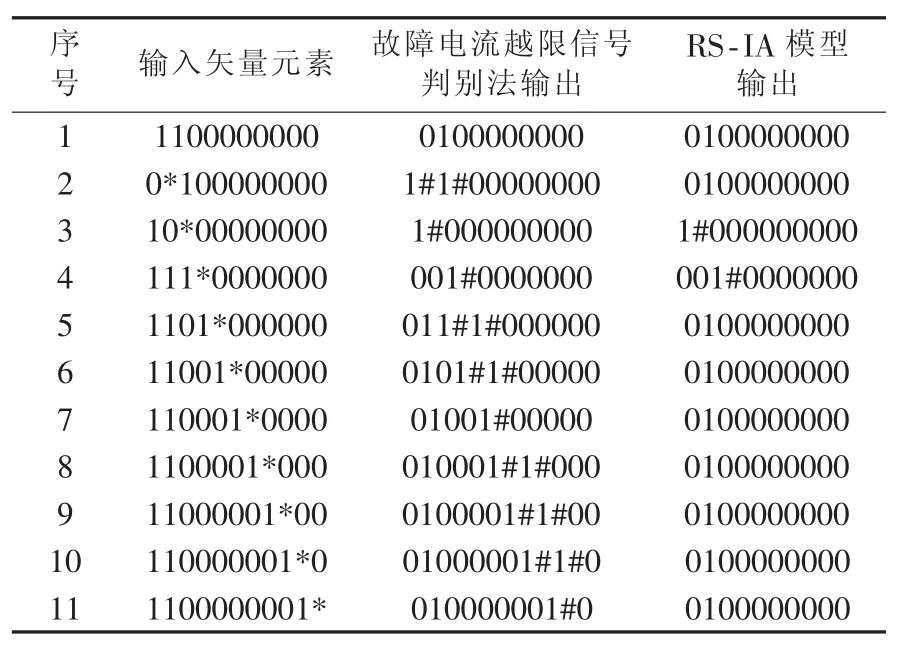
表2 配电网故障模式和诊断结果Table 2 Fault patterns and diagnosis results
由表2可知,常规的故障电流越限信号判别法对信息的畸变非常敏感,无容错能力,极易导致故障的误判、错判。本文提出的基于RS-IA数据挖掘的配电网故障定位模型具有较高的容错能力,在绝大多数情况下能够准确实现配电网的故障定位。
4.2 RS-IA与RS-GA模型性能对比
为了验证本文所提模型的优越性,将RS-IA模型与文献[14]所提的基于RS-GA数据挖掘模型的方法进行对比,用MATLAB编制了基于2种模型的配电网故障定位程序,对图3所示树干网进行仿真实现其故障定位。2种算法基本设置相同,算法的最大迭代次数均取150次,测试结果如表3所示。
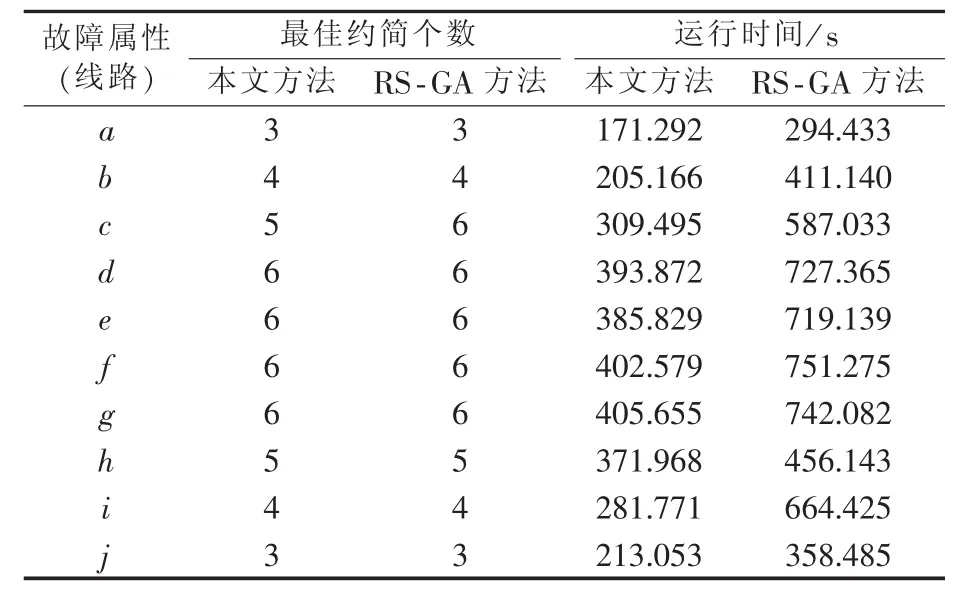
表3 2种方法测试结果比较Table 3 Comparison of test results between two methods
由表3可知,在相同设置的情况下,RS-IA模型能较好地求得最佳属性约简,而且收敛速度较快。且引入浓度机制,能够抑制IA中较高浓度的解的产生,防止算法过早地收敛于局部最优,有效地克服了GA“早熟”的缺点,既提高了效率,又使准确率有所提升。
4.3 实例验证
为了验证本文方法的实际可操作性,参考文献[25]所述,对某市配电网改造区域线路采取故障重现方式(已知开关24之后配电线路段发生故障),基于本文模型对其进行故障定位,该线路化简后如图6所示,其中虚线为一个环网柜。
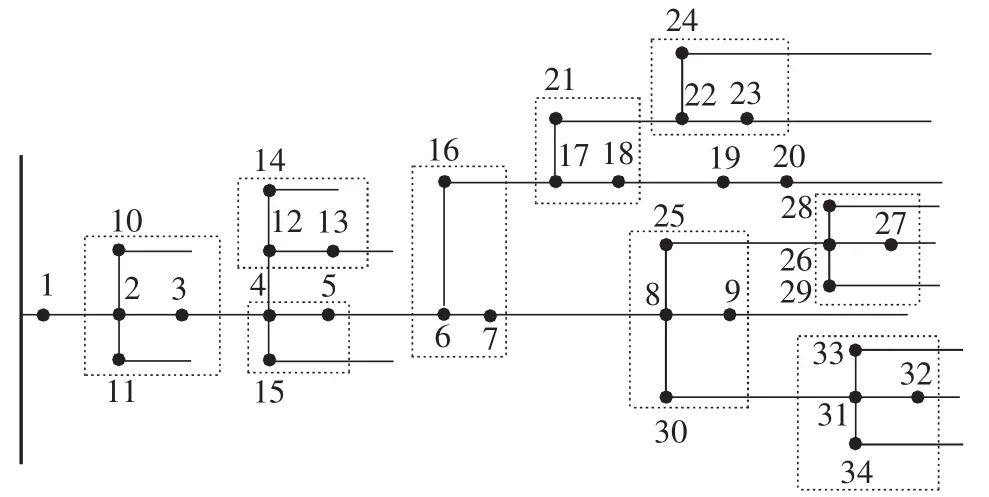
图6 某配电网改造区域简化线路图Fig.6 Simplified line diagram of a reconstructed distribution network
现开关4终端不在线(信息丢失),配电主站系统实时接收的过电流上传信息,即经过开关的电流越限信息为[1 1 1?0 1 0 0 0 0 0 0 0 0 1 1 1 0 0 0 1 1 0 1 0 0 0 0 0 0 0 0 0 0]。该线路可等效解耦为15个单一树干网,图7是其中某单一树干网,其开关过电流信息为[1 1 1?0 1 1 1 1 1 1]。
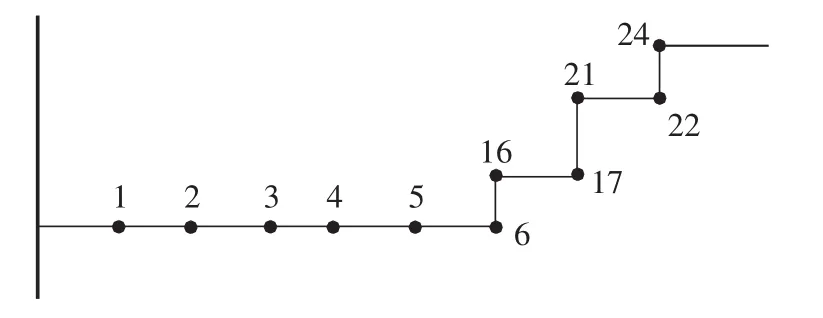
图7 开关24所在单一树干网Fig.7 Single trunk network containing switch-24
对得到的开关电流越限信号进行分析,可以发现开关6有电流越限信号,而开关6位于开关5之后,因此可判断出开关5处获得的信号发生畸变。从基于本文模型形成的决策规则数据库中提取相应规则,对其进行故障定位。经查找匹配后发现,故障区段可能为开关15之后的配电线路段或开关24之后的配电线路段。由于开关4、5、15处于同一环网柜,开关4信息丢失,开关5信息畸变,因此判断该环网柜出现故障,认为开关15信息也发生了畸变,配电线路故障区段位于开关24以后,与实际情况相符。
5 结论
a.利用IA能够较好地求得决策表中的最佳属性约简。相同设置的情况下,IA的性能优于GA。
b.本文将RS理论处理模糊、不确定问题的能力与IA全局最优解搜索功能相结合,构造了基于RSIA数据挖掘的配电网故障定位模型。仿真结果表明该模型简单、快速、有效、可行,且具有良好的容错性能,适应配电网的网络拓扑结构,很好地解决了因配电网获取信息的畸变而造成的故障定位误判问题。以人工智能方法为基础的配电网故障定位方法的发展有重要作用,具有良好的应用前景。
参考文献:
[1]罗梅,杨洪耕.配电网故障定位的一种改进通用矩阵算法[J].电力系统保护与控制,2012,40(5):64-68.LUO Mei,YANG Honggeng.An improved general matrix algorithm for fault locating in distribution system[J].Power System Protection and Control,2012,40(5):64-68.
[2]梅念,石东源,杨增力,等.一种实用的复杂配电网故障定位的矩阵算法[J].电力系统自动化,2007,31(10):66-70.MEI Nian,SHI Dongyuan,YANG Zengli,et al.A practica matrix based fault location algorithm for complex distribution network[J].Automation of Electric Power Systems,2007,31(10):66-70.
[3]刘健,张小庆,同向前,等.含分布式电源配电网的故障定位[J].电力系统自动化,2013,37(2):36-42,48.LIU Jian,ZHANG Xiaoqing,TONG Xiangqian,et al.Fault location for distribution systems with distributed generations[J].Automation of Electric Power Systems,2013,37(2):36-42,48.
[4]卫志农,何桦,郑玉平.配电网故障定位的一种新算法[J].电力系统自动化,2001,25(14):48-50.WEI Zhinong,HE Hua,ZHENG Yuping.A novel algorithm for fault location in power distribution network[J].Automation of Electric Power Systems,2001,25(14):48-50.
[5]武娜,焦彦军.基于模拟植物生长算法的配电网故障定位[J].电力系统保护与控制,2009,37(4):23-28.WU Na,JIAO Yanjun.Fault location of distribution network based on plant growth simulation algorithm [J].Power System Protection and Control,2009,37(4):23-28.
[6]李超文,何正友,张海平,等.基于二进制粒子群算法的辐射状配电网故障定位[J].电力系统保护与控制,2009,37(7):35-39.LI Chaowen,HE Zhengyou,ZHANG Haiping,et al.Fault location for radialized distribution networks based on BPSO algorithm[J].Power System Protection and Control,2009,37(7):35-39.
[7]周湶,郑柏林,廖瑞金,等.基于粒子群和差分进化算法的含分布式电源配电网故障区段定位[J].电力系统保护与控制,2013,41(4):33-37.ZHOU Quan,ZHENG Bolin,LIAO Ruijin,etal.Fault-section location for distribution networks with DG based on a hybrid algorithm of particle swarm optimization and differential evolution[J].Power System Protection and Control,2013,41(4):33-37.
[8]翁蓝天,刘开培,刘晓莉,等.复杂配电网故障定位的链表法[J].电工技术学报,2009,24(5):190-196.WENG Lantian,LIU Kaipei,LIU Xiaoli,et al.Chain table algorithm for fault location of complicated distribution network [J].Transactions of China Electrotechnical Society,2009,24(5):190-196.
[9]ZHANG J N,ZHOU R,ZHONG K.Application of improved ant colony algorithm in fault-section location of complex distribution network[C]∥2011 4th International Conference on Electric Utility Deregulation and Restructuring and Power Technologies(DRPT).Weihai,China:IEEE,2011:1067-1071.
[10]刘鹏程,李新利.基于多种群遗传算法的含分布式电源的配电网故障区段定位算法[J].电力系统保护与控制,2016,44(2):36-41.LIU Pengcheng,LI Xinli.Fault-section location of distribution network containing distributed generation based on the multiplepopulation genetic algorithm[J].Power System Protection and Control,2016,44(2):36-41.
[11]卫志农,何桦,郑玉平.配电网故障区间定位的高级遗传算法[J].中国电机工程学报,2002,22(4):127-130.WEIZhinong,HE Hua,ZHENG Yuping.A refined genetic algorithm for the fault sections location[J].Proceedings of the CSEE,2002,22(4):127-130.
[12]郑涛,潘玉美,郭昆亚,等.基于免疫算法的配电网故障定位方法研究[J].电力系统保护与控制,2014,42(1):77-83.ZHENG Tao,PAN Yumei,GUO Kunya,et al.Fault location of distribution network based on immune algorithm[J].Power System Protection and Control,2014,42(1):77-83.
[13]廖志伟,孙雅明.数据挖掘技术及其在电力系统中的应用[J].电力系统自动化,2001,25(11):62-66.LIAO Zhiwei,SUN Yaming.Data mining technology and its application on power system[J].Automation of Electric Power Systems,2001,25(11):62-66.
[14]廖志伟,孙雅明,杜红卫.基于数据挖掘模型的配电网故障定位诊断[J].天津大学学报(自然科学与工程技术版),2002,35(3):322-326.LIAO Zhiwei,SUN Yaming,DU Hongwei.A new approach for fault section diagnosis of distribution system based on data mining model[J].Journal of Tianjin University(Science and Technology),2002,35(3):322-326.
[15]REFONAA J,LAKSHMI M,VIVEK V.Analysis and prediction of natural disaster using spatial data mining technique[C]∥International Conference on Circuit,Power and Computing Technologies.[S.l.]:IEEE,2015:1-6.
[16]AN H G,KOH J J.A study on the selection of bitmap join index using data mining techniques[C]∥International Forum on Strategic Technology.Tomsk,Russia:IEEE,2012:1-5.
[17]束洪春,孙向飞,司大军.基于故障投诉电话信息的配电网故障定位粗糙集方法[J].电网技术,2004,28(1):64-66.SHU Hongchun,SUN Xiangfei,SI Dajun.A rough set approach to distribution network fault location based on fault complain call information[J].Power System Technology,2004,28(1):64-66.
[18]ZHU Z,SUN Y.Application of quantum immune algorithm for fault-section estimation[C]∥2009 2nd International Conference on Power Electronics and Intelligent Transportation System(PEITS).Shenzhen,China:IEEE,2009:317-320.
[19]ZHAI J,WAN B,ZHANG S.Probabilistic tolerance rough set model[C]∥2015 International Conference on Wavelet Analysis and Pattern Recognition(ICWAPR).Guangzhou,China:IEEE,2015:214-219.
[20]HEDAR A R,OMAR M A,SEWISY A A.Rough sets attribute reduction using an accelerated genetic algorithm[C]∥2015 IEEE /ACIS 16th International Conference on Software Engineering,Artificial Intelligence,Networking and Parallel/Distributed Computing(SNPD).Takamatsu,Japan:IEEE,2015:1-7.
[21]田思庆,王越男,张艳丽,等.基于粗糙集配电网故障定位系统[J].佳木斯大学学报(自然科学版),2010,28(3):337-339.TIAN Siqing,WANG Yuenan,ZHANG Yanli,et al.Fault location of distribution network based on rough set[J].Journal of Jiamusi University(Natural Science Edition),2010,28(3):337-339.
[22]朱志勇,林睦纲,徐长梅.基于免疫算法的属性约简方法[J].计算机工程与科学,2012,34(1):174-177.ZHU Zhiyong,LIN Mugang,XU Changmei.Attribute reduction approach based on immune algorithm[J].Computer Engineering&Science,2012,34(1):174-177.
[23]SKOWRON A.Extracting laws from decision tables:a rough set approach[J].Computational Intelligence,1995,11(2):371-388.
[24]叶玉玲,伞冶.基于遗传算法的粗糙集混合数据属性约简[J].哈尔滨工业大学学报,2008,40(5):683-687.YE Yuling,SAN Zhi.Rough set reduction for hybrid data based on genetic algorithm[J].Journal of Harbin Institute of Technology,2008,40(5):683-687.
[25]苏译,彭敏放,朱亮,等.基于信息还原与膜计算的配电网故障定位[J].仪器仪表学报,2014(12):2700-2708.SU Yi,PENG Minfang,ZHU Liang,et al.Fault section location for distribution networks based on information restoration and membrane computing[J].Chinese Journal of Scientific Instrument,2014(12):2700-2708.
[26]葛磊蛟,王守相,瞿海妮.智能配用电大数据存储架构设计[J].电力自动化设备,2016,36(6):194-202.GE Leijiao,WANG Shouxiang,QU Haini.Design of storage framework for big data of SPDU[J].Electric Power Automation Equipment,2016,36(6):194-202.
[27]徐青山,王文帝,林章岁,等.面向行业大数据特征挖掘的电力经理指数指标体系的建立与应用[J].电力自动化设备,2015,35(7):15-21.XU Qingshan,WANG Wendi,LIN Zhangsui,et al.Establishment and application of EMI indicator system orienting to massive industrial data mining[J].Electric Power Automation Equipment,2015,35(7):15-21.
猜你喜欢
舰船电子工程(2022年4期)2022-05-11
大众投资指南(2021年35期)2021-02-16
成都信息工程大学学报(2019年2期)2019-08-28
自动化学报(2018年2期)2018-04-12
成都信息工程大学学报(2017年1期)2017-07-21
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
电测与仪表(2015年13期)2015-04-09
河南科技(2014年7期)2014-02-27
电子设计工程(2014年18期)2014-02-27
