
基于K近邻非参数回归的短时交通流预测模型研究
2017-06-02 13:49程山英
数字技术与应用 2017年4期
程山英

摘要:本文主要是对K近邻非参数的回归方法进行短时交通流量的预测,分析模型中相关的重要因素,给预测效果带来的影响。本文将会对不同状态的向量和预测算法等相关的试验算法进行比较,将每四个相连时间的间隔流量,以及占用率等数据当做状态向量,通过具有权重的预测算法来获得更好的结果。
关键词:K近邻;非参数回归;短时交通流预测;预测区间
中图分类号:TP311 文献标识码:A 文章编号:1007-9416(2017)04-0130-03
对于短时交通流进行预测是建立智能交通体系的重要内容。交通预测越准确、越及时,就会对交通的控制就越有利,对于一些交通问题也能及时的进行服务。而K近邻是属于参数回归中使用最多的方法,本文将会对K近邻方法进行模拟使用,对城市道路的短时交通情况进行预测分析。
1 K临近预测的模型
建立K近邻在短时交通流中进行预测的模型流程是:首先,要建立一个具有历史代表性的大容量数据库;其次,对模型相关的要素进行设置,主要包含距离度量的方式、预测算法、状态向量、K近邻的个数等内容,其中局力度量的方式、K近邻的个数和状态向量之间可以构成模型的搜索模块;最后,根据搜索机制和目前观测值的输入,在历史的数据库中,找出与观测数据相对应的近邻,然后通过预测算法得出下一个时间内的交通流速度。想要提高预测的精确度,首次要对一下四个方面进行分析:
1.1 距离度量的方式
距离度量方式主要是指历史数据库中每个样本数据和目前的数据之间的近似度,主要使用欧式距离来进行度量指标的计算:
该式中表示目前的数据和历史数据库中处于第i组数据之间的距离;表示在目前的数据中,处于第j项的权重;表示处于第j个子项的数值;表示处于i历史数据中第j项的数值。
1.2 状态向量
状态向量是目前数据和历史数据相比较的标准,它是根据预测对象来选择对应因素,以此来对预测精度与运行时间之间的需求进行平衡的。
1.3 近邻个数
K近邻个数是指在历史数据库中提取与目前数据类似的数据组数。对K值的选择直接关系到样本数据,K值的大小都会对预测精度具有一定的影响。
1.4 预测算法
预测算法主要是通过获取的K組近邻预测结果,对下一时间的交通流情况进行预测,相关的计算公式是:
该式中,表示的是在m路段的t+1时间里,行车的平均速度;表示目前的数据和第k个近邻之间的距离;表示的是在历史数据中获得第k个近邻相对应的t+1时段的行车平均速度。
2 改进K临近的模型
本文模拟的某个时空参数模型进行改善,主要表现在一下两个方面:首先是在进行状态向量设置时,充分的考虑了空间和时间两个纬度;其次,使用具有权重的距离度量方法,通过不同的分量对预测时间内的交通情况之间差异进行分析。
2.1 时空参数中的状态向量
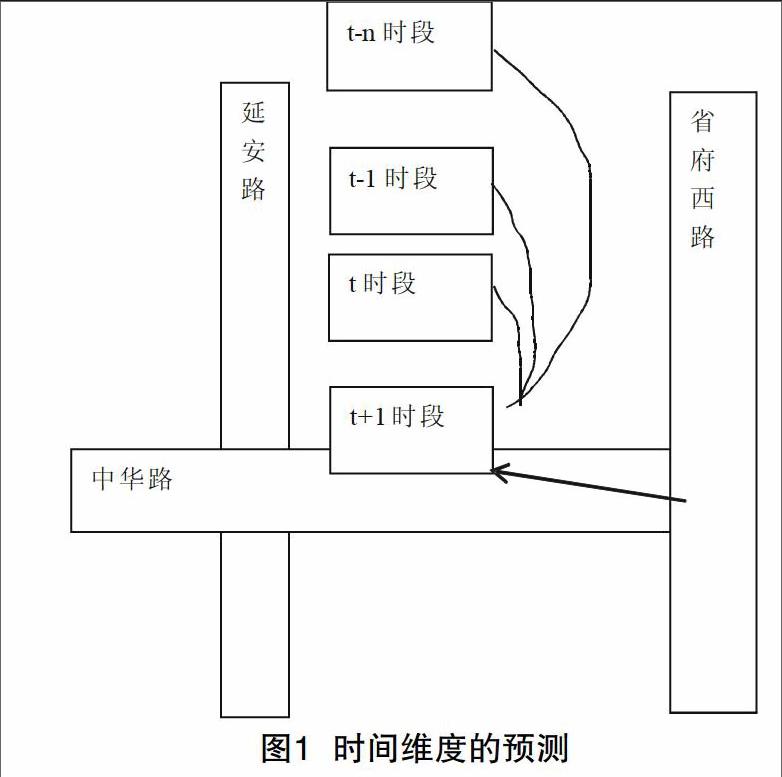
处于城市中道路,没有一个是独立存在的。不管是在上游还是在下游路段出现交通拥堵,都会直接影响到整个路段的交融情况。从理论上进行分析,将空间和时间纬度进行结合分析,可以提高K近邻模型相关的预测精度。所以,本文根据这理论对K近邻时空参数模型进行改善,相关的预测机理可以见图1和图2。
根据图1和图2进行分析,先假设目标路段是m,预测时间是t+1.那么从时间维度分析,在m路段的t+1时段中,平均车速和前n+1个时间里的平均车速(t)、(t-1)、……(t-n)之间是密切相关的。从空间纬度的角度来说,和上下路段中t时间内的平均车速、之间也存在着关系。因此可以通过这两个因素预测出,其他的路段情况以此类推。
只考虑时间纬度方面的状态向量,和将时间维度与空间纬度之间的状态向量进行结合分析,还是后者更能提高预测的精确度,因为后者的方法能够获得更高质量的与当前数据类似的近邻。
2.2 模拟的时间维度
时间维度上的模型:在m路段上,t+1时间内的平均车速,只进行该路段的历史时间车速。以此模型形成的状态向量:((t),(t-1),(t),(t-1)),其中(t),(t-1)是历史数据中前一路段与目标路段中车辆运行的速度。
时空参数的模型。这个模型是将时间维度和空间维度进行一同分析的,它所获得数据是更加接近实时的数据。根据这个预测模型进行状态向量的建设:((t),(t-1),(t),(t),(t),(t-1),、)。
2.3 权重距离的度量方式
因为交通路段的情况变化性比较强,在同一路段中也会出现不同的交通状况,在进行未来路段的预测时,其重要度也是不相同的。如果对近邻的相似度使用距离度量的方式进行权重计算,可能会获得与当前时段相似的近邻数据。所以,本文将会通过系数相关权重法与指数权重方法,对状态向量中的关系到时间维度的分量进行计算。
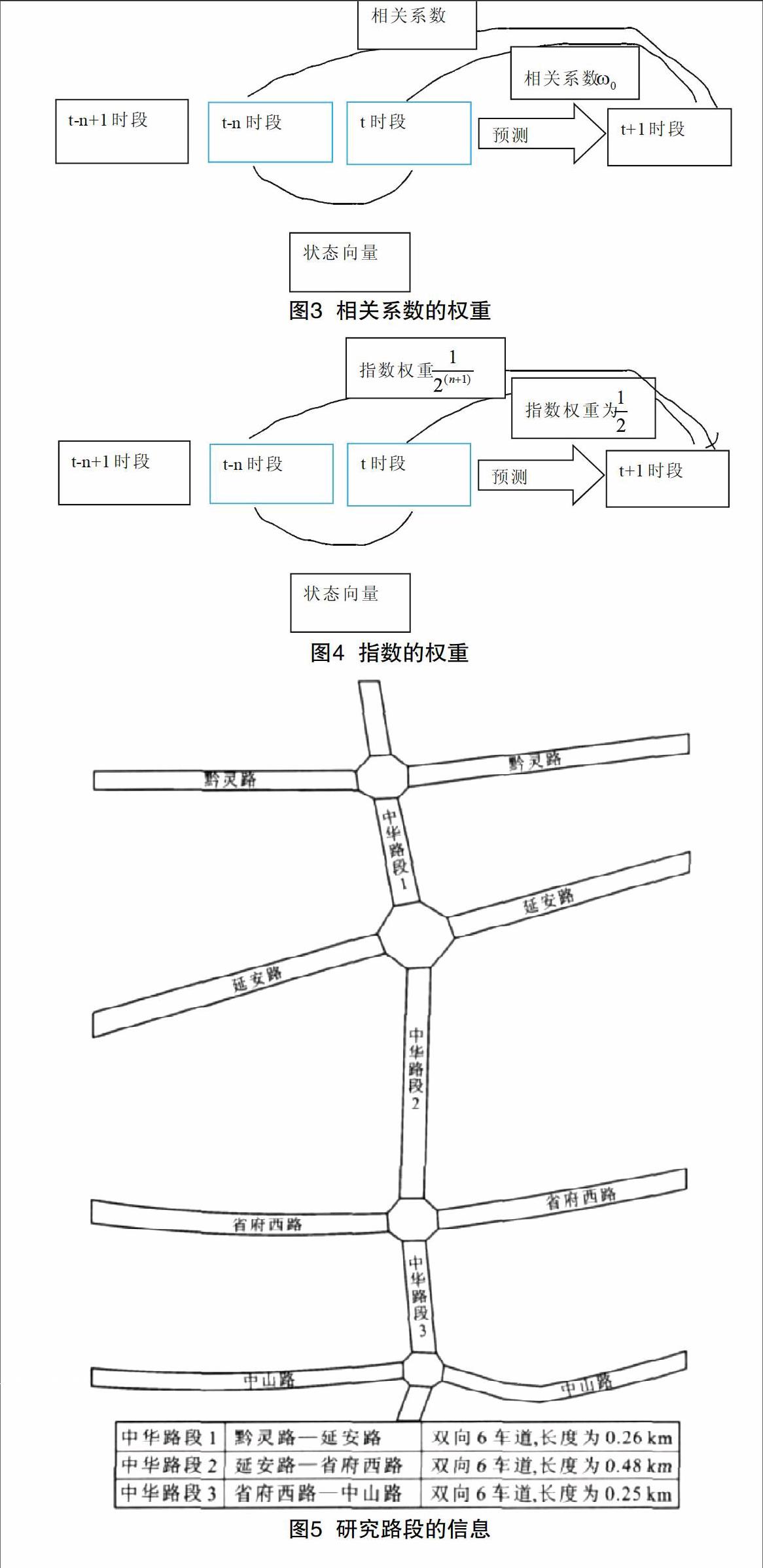
2.3.1 相关系数的权重方法
相关系数的权重方法是指在不同的历史时段和预测时段之间的数据相关系数,计算出该时段对于未来时段交通情况的影响。可见图3关于相关系数的权重利用距离度量的方式进行分析的情况。把t+1路段当做目标时段,其中是在t时段中的历史数据和t+1时段的数据之间的相关系数,而则是t-n时间内的历史数据和t+1时段的数据之间的相关系数。
2.3.2 指数权重
指数权重的方法就是确定每个时段和预测时段之间的间隔来得出每个分量的权重,进行权重的选择标准是。见图4可以查看指数权重相关的距离度量的方式。该方法的分析是:与目标时段(t+1)越近的时间范围,与它相关的历史数据就会给目标时段带来更大的影响,那么所被赋予的权重就会越高(比如:图4中的t时段相关的权重,它的最大权重则是1/2),其他时段的权重都是依次降低的。
3 分析计算的结果
3.1 数据的处理和获取
本文主要选择在贵阳市的某3段路段作为分析对象,详细路段情况可以见图5,图中有4个相加叉的信号,它们的周期平均是130s。本文主要选取在16:30~18:00这个时间范围,选择的工作日是2011-04-11到2011-4-23,在该时段收集了10veh出租车相关的GPS信息(主要包含司机工号、经纬度、车牌号、运行的方向和速度以及时间等)。之后通过GPS相关的异常数据处理,获取了217564个组的有效数据。想要获取每个路段的出租车相关的运行速度,首先就是对这些数据实施定位。关于GPS定位的出租车信息和卫星地图数据相匹配的情况见图6。
根据路段的平均车速来判断交通的状况,预测的时间相隔5min。首先就是对GPS原始的数据进行处理,然后获取每隔5min的道路交通情况。之后把某个时段经过某个路段的车辆求出,还有每辆车在该路段花费的时间,最后把每个路段某个时段的车速平均值求出来: (3)
在该式中是m路段的长度;其中表示在t时段在m路段中出现的出租车量;而表示第r辆出租车在m路段行驶的时间。
3.2 比较不同的模型
首先定义4个不同的模型和3个路段的交通情况研究,对不同的状态向量K近邻的标准进行分析。详细结果见图7。
根据图7分析,这4中模型在3个路段中的情况研究结果都不相同。在第一种模型中检验的结果比较差,它在3个路段中出现的平均误差是比较大的,也就是只考虑时间纬度上的K邻近模型,是无法达到最好的预测结果的。
4 结语
根据上文的分析,可以看出只要同时考虑时间和空间纬度上的某路段行车情况,才能得到更加准确的预测数据。
参考文献
[1]林川.基于K近邻非参数回归的短時交通流预测算法研究[D].电子科技大学,2015.
[2]于滨,邬珊华,王明华,赵志宏.K近邻短时交通流预测模型[J].交通运输工程学报,2012,(02):105-111.
[3]张涛,陈先,谢美萍,张玥杰.基于K近邻非参数回归的短时交通流预测方法[J].系统工程理论与实践,2010,(02):376-384.
[4]李振龙,张利国,钱海峰.基于非参数回归的短时交通流预测研究综述[J].交通运输工程与信息学报,2008,(04):34-39.
