
调序规则表的深度过滤研究*
2017-06-05 15:05孔金英杨雅婷罗延根
计算机与生活 2017年5期
孔金英,李 晓,王 磊,杨雅婷+,罗延根
1.中国科学院 新疆理化技术研究所,乌鲁木齐 830011
2.新疆民族语音语言信息处理重点实验室,乌鲁木齐 830011
3.中国科学院大学,北京 100049
调序规则表的深度过滤研究*
孔金英1,2,3,李 晓1,2,王 磊1,2,杨雅婷1,2+,罗延根1,3
1.中国科学院 新疆理化技术研究所,乌鲁木齐 830011
2.新疆民族语音语言信息处理重点实验室,乌鲁木齐 830011
3.中国科学院大学,北京 100049
机器翻译系统中调序规则表和翻译表一般规模都很大,对翻译表进行优化过滤一直都是研究热点,而过滤调序规则表的研究却近乎空白。将调序规则表的过滤当成短文本分类问题,提出了一种基于自动编码机(Autoencoder)的调序规则表过滤模型。该模型首先使用一种基于自动编码机的分类器对调序规则进行打分评价,然后对调序规则表进行基于最小差异策略的过滤,最后使用过滤得到的调序规则表重新计算调序规则得分表用于机器翻译的解码过程。实验表明,在公开的英汉语料和维汉语料上使用该模型,可以在调序规则表减少40%的基础上分别将BLEU(bilingual evaluation understudy)值提高0.19和0.26。
自动编码机;过滤模型;调序规则表;机器翻译
1 引言
在基于短语的统计机器翻译系统中,人们都是从词对齐的结果中抽取短语对齐表和调序规则表[1],然后在此基础上可以得到用于解码的短语对齐得分表和调序规则得分表,前者可以称为翻译模型,后者可以称为调序模型。加之训练好的语言模型[2],一个完备的机器翻译系统就可以进行解码输出了。
对于语言模型的研究,应该来说是十分广泛的。这是因为语言模型不仅可以应用于机器翻译中,同时也可以应用于自然语言处理的其他领域。同样的,翻译模型作为机器翻译的基本组成部分,对其研究一直以来都是热点问题。从最初的基于词的翻译模型[3],到现在最新提出的基于神经网络的翻译模型[4],机器翻译系统的性能也是越来越好。本文研究的对象是调序模型,其用于保证译文的正确顺序。总结统计机器翻译的发展历程,可以明显地发现其与机器学习的发展是紧密联系的。
近几年,基于深度神经网络的机器学习模型在其应用的很多领域,都有很大的突破。无论是在图像识别领域,还是语音识别领域,基于深度神经网络的机器学习模型已经占据了主导地位。这自然吸引了广大学者将深度神经网络应用于自然语言处理领域。但是语言文字作为人脑形成的高级符号,在应用深度学习方面的成就还不如语音和图像。目前在自然语言处理领域应用的比较广泛的有自动编码机(Autoencoder)[5]、长短时记忆(long short term memory,LSTM)神经网络[6]、卷积神经网络(convolutional neural network,CNN)[7]等。其中,自动编码机因其计算量相对较小,在自然语言处理方面也有着不错的表现,已经吸引了越来越多的研究者的注意。
本文利用自动编码机模型良好的特征抽象性,对机器翻译中的调序规则表(如图1所示)进行学习,然后添加Softmax层。使用该模型对调序规则表进行重新得分评估,最后过滤掉错误的和含噪音的调序规则。使用本方法过滤后的调序规则表重新计算调序规则得分表,可以加快机器翻译最终的解码速度和提升最终的翻译结果。

Fig.1 Reordering table in Moses图1 Moses系统中的调序规则表
本文组织结构如下:第1章主要介绍研究背景;第2章是与本文相关的工作情况,描述目前的一些代表性调序模型研究工作;第3章讲解基于自动编码机的调序规则过滤模型;第4章是实验部分;第5章对本文工作进行总结和对未来工作进行展望。
2 相关工作
对机器翻译系统自动生成的短语表进行优化过滤,是机器翻译的研究者们经常关注的问题。北京交通大学的殷乐等人[8]提出了一种基于虚拟上下文的短语表过滤方法;苏州大学的狄萍等人[9]提出了C-value以及短语粘结度两种短语表过滤方法;谷歌的Zens等人[10]提出了一种基于声学理论基础的短语表剪枝方法。调序模型相比较翻译模型更为简单、独立,调序规则表的过滤方法鲜有学者们提出。
统计机器翻译中的调序模型从最简单的长度惩罚模型,到各种复杂的基于调序定向和神经网络的模型,总体来说可以分为3种类型:第一种类型奉行的是简单至上,他们相信语言模型和翻译模型可以很好地完成机器翻译中的调序任务,而不愿意使用复杂调序模型。该类方法的代表工作是Och等人[11]提出的简单的基于调序长度惩罚的模型,该模型实现简单,目前Moses系统中的默认调序操作仍是基于此类方法。第二种类型是目前主流的方法,他们往往具有复杂的调序定向类型和判定调序定向的方法。关于判定调序定向的方法也从简单最大似然方法[12]到基于最大熵的机器学习模型[13],清华大学的李鹏等人[14]在2013年提出了一种利用深度神经网络的方法判定调序定向。第三种调序模型则是针对各个不同语种间机器翻译的基于语法和句法规则的调序模型。这种方法一般是在解码阶段,利用语法规则对译文的输出顺序加以限制,有点类似于基于规则的机器翻译方法。比如中科院计算所的肖欣延等人[15]和MIT的王超等人[16]都利用了汉语的句法信息进行调序指导。
本文提出用过滤调序规则表的方法来提高机器翻译最终的调序能力。本文的研究对象属于第二种类型,也是现在使用和研究得最为广泛的调序模型。这种调序模型包含两个要素:调序定向和调序定向概率得分。调序定向指的是给定两个相邻的双语句对,对双语句对操作顺序进行判定。较为常用的调序定向有单调操作(monotone)和交换操作(swap)以及非连续(discontinuous),而非连续也可以被细分为交换的非连续操作(discontinuous swap)和单调的非连续操作(discontinuous monotone)。如图2给出的是当前短语与前一个短语的调序定向图,比如图中“minister”与其前面短语的调序定向操作是单调操作。式(1)为规定了4种定向的调序模型,分别是monotone、swap、discontinuous monotone、discontinuous swap。其中M操作是因为b2短语的首个单词r1在源语言中的顺序比b1短语在源语言的末尾单词rl大1,其他几个式子类似。式(1)的第三条准则和第四条准则合并起来就是非连续操作。调序定向概率得分经历了从最初简单的累加平滑后以规则的计数来计算概率,到后来利用朴素贝叶斯或者最大熵等机器学习模型,再到最近的利用深度神经网络。
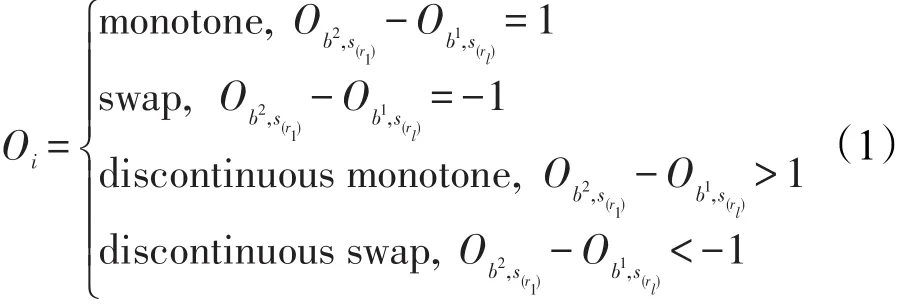
因为没有模型依赖性,本文提出的基于自动编码机的调序规则过滤模型有效地屏蔽了各个调序模型差异化的问题。本文在各个调序模型抽取调序规则实例的基础上,对调序实例这一机器学习模型进行训练的对象加以优化,从而在减少解码时间的同时可以提高最后的翻译性能。
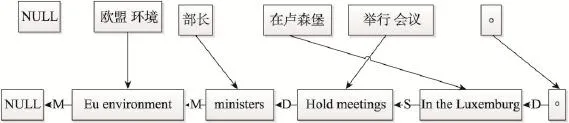
Fig.2 An example of reordering图2 一个调序定向的例子
3 基于自动编码机的调序规则过滤模型
基于自动编码机的调序规则过滤模型的工作流程如图3所示。首先,对调序规则表进行文本预处理,得到用于适合训练的数据集。接下来使用基于自动编码机的分类器对原始的调序规则进行调序定向得分的分配,最后执行基于最小差异的过滤策略,选出最终的调序规则。以下首先介绍针对调序规则表的文本预处理,然后描述基于噪音稀疏自动编码机的分类器的构造过程,最后阐述基于最小差异的过滤策略。

Fig.3 Work flow of reordering table filtering model based onAutoencoder图3 基于自动编码机的调序规则表过滤模型工作流程
3.1 文本预处理
如图1所示,以Moses系统为例,打开该系统的调序规则表,这些规则都是从质量不一的语料上抽取得到的,因此这是一个十分冗余和庞大的文本数据。另外,自动编码机的计算量相对一般的机器学习方法较大,过大的训练集很容易导致计算量爆炸的问题,因此在训练自动编码机模型之前,需要对调序规则表做一些预处理。观察各个模型得到的调序规则表,本文总结出一般的调序规则表有以下特点:
(1)相同的规则很多,约占到总数量的10%。
(2)短规则多,很多可以归并到相应的长规则中,短语长度在5以下的规则占了总量的近八成(短语长度限制为7的情况)。
(3)存在大量的噪音数据和无效数据。
(4)存在调序规则定向错误的情况。
根据以上(1)到(3)条描述,本文对调序规则表做如下的处理:
(1)在每条调序规则的基础上增加一个字段,用以记录该规则的数量。
(2)删除多余的调序规则,仅保留一条,并记录下该规则被删前的总数量。
(3)将短规则归并到相应的长规则中,同时在长规则的总数量中加上归并的短规则数量。比如R1={A,B,O1,O2},R2={XA,XB,O3,O2},其中O1=M表示与前面短语对是单调顺序,则R1∈R2,删除R1,并将R2的总数量加1。之所以做这一步处理,是因为本文所使用的自动编码机模型将每个单词视为一个向量,在训练长句的时候也可以一并学习到其中包含的子句知识。表1是本文列出的可以进行归并的规则,其中O1表示当前短语对与前面短语对的顺序,而O2表示当前短语对与下一个短语对的顺序。

Table 1 Merging rules of reordering table表1 调序规则表合并准则
判断调序规则表中出现的调序规则定向的错误是本文研究的重点,接下来将详细描述利用基于噪音稀疏的自动编码机分类器对调序规则表进行打分重排序,选择出其中高质量的调序规则表重新计算调序规则得分表用以最终的解码。
3.2 基于自动编码机的调序规则分类模型
对调序规则表中的调序规则进行调序定向的判断,是一个典型的分类问题。在一个调序定向是swap和monotone两种顺序的调序模型中,调序规则表有4种顺序:“swap,monotone”、“monotone,swap”、“swap,swap”、“monotone,monotone”。此外,由于调序规则的文本大多在10个单词以内,对调序规则表进行定向概率得分的分配是一个短文本分类问题。短文本分类问题的难点在于其词频过低,用传统的文本向量作为特征往往是高维且稀疏的,导致最后的结果并不好。
自动编码机能够模仿人脑的机制,对高维的底层特征进行非线性组合得到低维的抽象特征,是一种先进的机器学习模型。本文首先使用Embedding技术对所有的词语进行词向量化;然后通过添加L1范式以避免算法的过度拟合,同时对输入的数据进行加噪声处理,这样可以提高自动编码机模型整体的鲁棒性以及对调序规则的分类准确性;最后在自动编码机的顶端添加Softmax层用于分类。对本文模型的描述主要分为三部分:文本Embedding,基于噪音稀疏的自动编码机,Softmax回归。
3.2.1 文本Embedding
调序规则由源语言短语、目标语言短语和调序定向组成。为了最大化地刻画所有单词对调序定向的影响,本文首先将所有的单词进行Embedding得到每个单词对应的向量表示。然后将所有的源语言单词和目标语言单词按照顺序合并成矩阵。最后加上该规则出现的次数t。这样,每条调序规则都可以由一个矩阵x表示。每条规则对应的调序定向本文用一个one-hot向量y进行表示。在y中,取调序定向的值为1,其余为0。一个完整的规则Ri由式(2)和式(3)组成。

式(2)中的ωi表示用向量表示的第i个单词;t表示规则出现的次数。式(3)表示Ri对应的调序定向是第一个规定的定向,y是维数根据调序模型规定的调序定向个数而调整的one-hot向量。
3.2.2 基于噪音稀疏的自动编码机
基于噪音稀疏的自动编码机在接受输入后的工作流程如图4所示,以下为详细的步骤。
(1)对输入的向量进行线性变化,本文选取logistic函数作为激活函数,在此函数的基础上可以得到编码结果y。这一步称为编码,操作如式(4)所示。

(2)编码结果y在解码器的作用下得到重构的向量z。W是权重矩阵,WT是W的转置,b和b′都是偏移向量。这一步称为解码,操作如式(5)所示。

(3)利用正则化的损失函数评价z和x之间的相似度,这一步称为评价,如式(6)。

Fig.4 Work flow of denoising sparseAutoencoder图4 基于噪音稀疏的自动编码机工作流程图
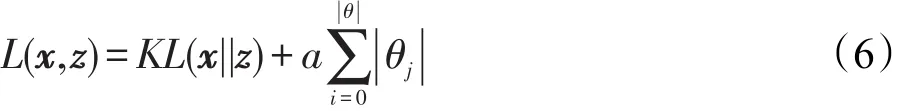
(4)加入随机噪音,同时循环迭代使用随机梯度下降法优化参数,使z和x的损失函数L(x,z)最小,这一步称为优化,如式(8)所示,一般的迭代次数是50~80次。

(5)经过上述4个步骤得到的y就是抽取出来的特征向量。再将y加噪音作为输入向量进行编码,循环进行上述4个步骤的操作就是深度编码机,深层网络具有更好的降维和抽象特性。
3.2.3 Softmax回归
在自动编码机得到抽象向量后,本文添加了常用的Softmax函数作为分类层用于调序规则的分类,该层的神经元个数就是调序模型中的调序定向个数。Softmax回归是logistic回归的多类推广,其定义如式(9)所示:
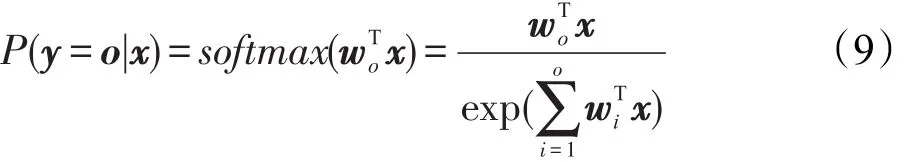
该函数输出的每一个分量表示输入数据对应的一个调序定向类别概率值,取最大值为该实例的类标。添加分类层后,本文用预先训练好的各层之间的权重作为初始权重,用最小化输出概率和调序定向类别之间的监督损耗来调整整个网络的参数,并通过反向传播算法进行网络整体的优化。图5是基于自动编码机的调序规则分类模型的整体流程示意图。
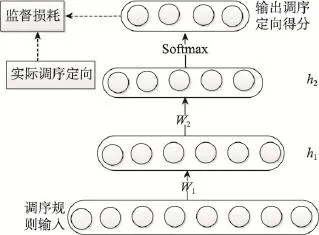
Fig.5 Classifier model for reordering rules based onAutoencode图5 基于自动编码机的调序规则分类模型
3.3 基于最小差异的过滤策略
经过上一节的训练,可以得到一个基于自动编码机的分类器。该分类器可以有效地给出双语短语对的调序定向得分。本文定义的“调序操作准确度”是一个衡量调序规则质量的标准,其定义如式(10)所示。式(10)中的max(scorei)表示分类器分配的最大得分,即分类器认为最合理的调序定向操作。式(10)中的scorei(Os)表示调序规则i在原始调序规则表上的调序定向在分类器中的得分。换言之,“调序操作准确度”指的是原始调序规则中的调序定向与分类器分配的调序定向的得分差值,当这个差值为0时表明该条调序规则为最优,即原始调序规则表中的定向和分类器分配的调序定向是相同的。
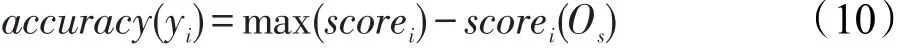
如规则R1在原始规则表中的顺序是“monotone,monotone”,而使用自动编码机分类器得到的最大得分的定向正好也是“monotone,monotone”,因此该规则的“调序操作准确度”就是0,表明该规则是一条很好的规则。
基于最小差异的过滤策略指的是使用基于自动编码机的分类器计算出每条原始规则的“调序操作准确度”,然后根据得分从小到大对调序规则进行排序。最后,参考原始训练语料的好坏,选择最后输出的调序规则表的大小。一般情况下,选择原始调序规则表大小的60%就可以达到或超过原始调序规则表的最终翻译性能。
4 实验
4.1 实验设置
把本文提出的调序规则表过滤方法应用于实际的机器翻译系统中,来验证该方法的有效性。本文实验中采用的语料全部来自于CWMT2015评测中的公开语料,选择了英汉新闻领域和维汉新闻领域的部分语料作为实验对象。因为本文过滤的调序规则是用于机器翻译解码的,所以将语料分为训练集、测试集和开发集。语料样本情况如表2所示。

Table 2 Size of corpus表2 语料大小情况
本文使用的是基于Python的Theano库开发的自动编码机。实验选择的自动编码机的网络结构是3000-1000-500-250-n,其包含两个隐藏层的深度学习网络,每个隐藏层由500个单元组成,最后的输出层单元数根据调序定向的类别而定。此外,在优化参数的随机梯度算法中,实验选择的学习速率是0.1,权值惩罚因子为0.000 2,最大迭代次数为50。
关于机器翻译实验平台,本文使用的是MOSES 2.1(http://www.statmt.org/moses/),操作系统是ubuntu 12.04。本文使用GIZA++(http://www.statmt.org/moses/ giza/GIZA++.html)开源工具包作为词对齐工具,然后采用“grow-diag-final-and”策略获得多对多的词语对齐。本文的短语抽取限制的长度是7,采用的调序模型是各组实验对比的变量。在调参过程中,使用的是最小错误训练方法优化模型的参数。另外,使用SRILM(http://www.speech.sri.com/projects/srilm/)工具分别对训练集里的汉语语料进行五元语言模型的训练,并用Kneser-Ney平滑估计参数。最后,采用了对大小写不敏感的BLEU[17]作为机器翻译最终结果的评测指标。
为了更清楚地对比各个方法的优劣,本文设置了英汉和维汉两大组实验进行对照,这两组实验的设置完全相同,分别设置了以下5小组实验。
(1)Baseline:使用系统中默认的基于距离的调序模型进行翻译系统的训练,该组实验因为没有调序规则表产生,所以作为基线系统用于对比。
(2)MSD:使用系统中的phrase-msd-bidirectionalfe选项作为调序模型进行翻译系统的训练。
(3)MSD_F:使用系统中的phrase-msd-bidirectionalf选项作为调序模型进行翻译系统的训练,然后在原有调序规则表的基础上分别使用本文方法过滤出原始规模80%、60%、40%的新调序规则表。最后分别利用这3个新调序规则表重新计算3个调序规则得分表用以解码。
(4)MSLR:使用系统中的phrase-mslr-bidirectionalf选项作为调序模型进行翻译系统的训练。
(5)MSLR_F:使用系统中的phrase-mslr-bidirectional-fe选项作为调序模型进行翻译系统的训练,在调序规则表的基础上分别使用本文方法过滤出原始规模80%、60%、40%的新调序规则表。最后分别利用这3个新调序规则表重新计算3个调序规则得分表用以解码。
4.2 结果分析
表3和表4分别是英汉机器翻译系统和维汉机器翻译系统中各组实验的BLEU得分。根据表3和表4的实验数据,本文可以得到这些结论。
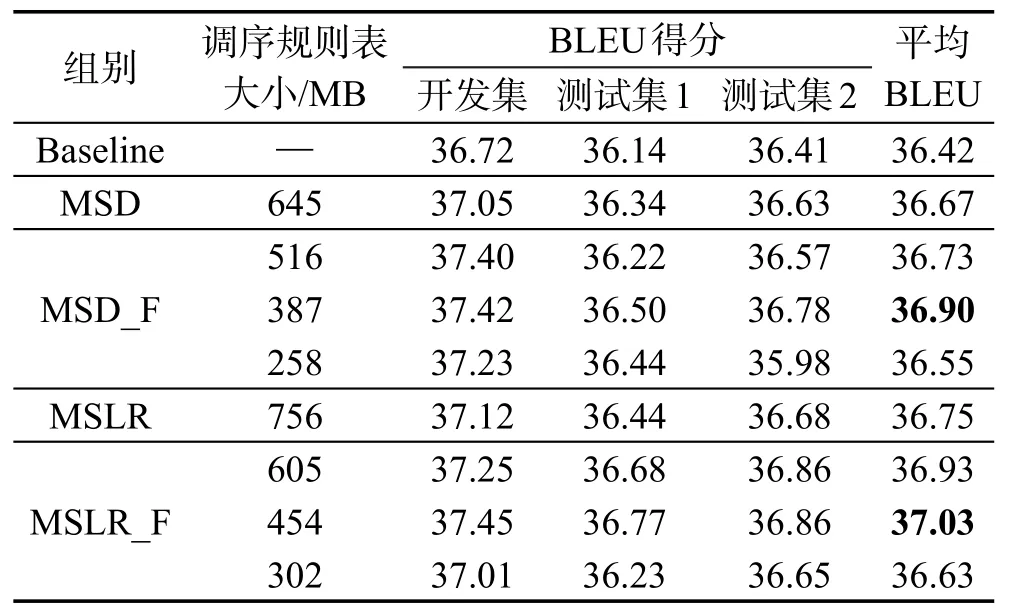
Table 3 Experimental result of English-Chinese machine translation system表3 英汉机器翻译系统的实验结果
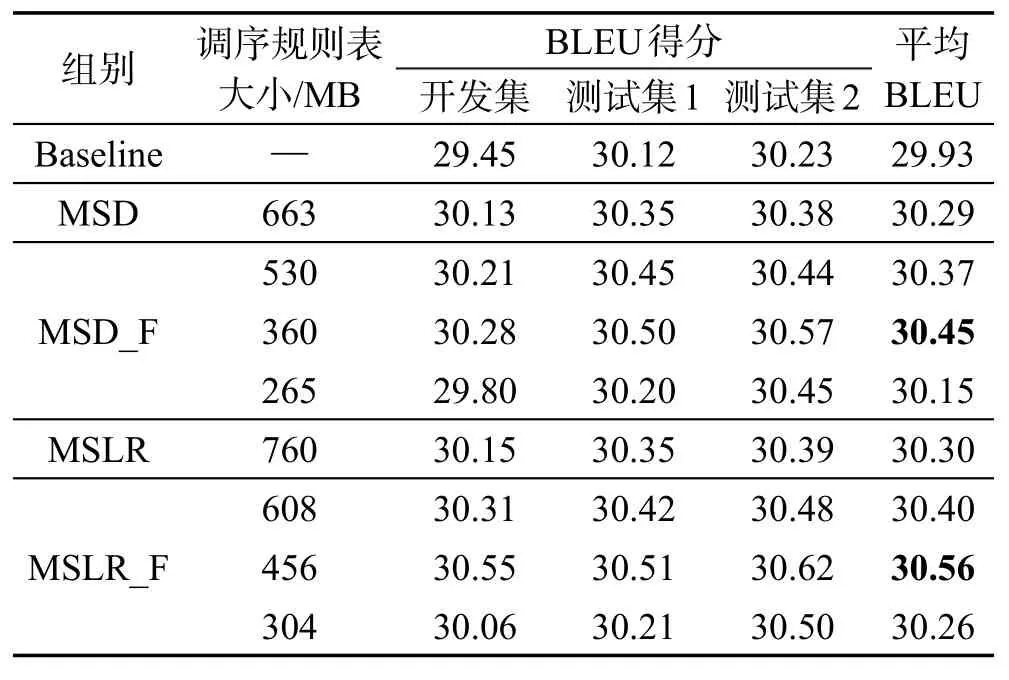
Table 4 Experimental result of Uyghur-Chinese machine translation system表4 维汉机器翻译系统的实验结果
机器翻译系统在使用了基于自动编码机的调序规则过滤模型后都能够在原有调序模型的基础上提升最终的译文质量。其中翻译规则表减少至原有的80%时BLEU值平均能提升0.10,翻译规则表减少至原有的60%时BLEU值平均提升0.26,翻译规则表减少至原有的40%时BLEU值平均降低0.11。其中维汉机器翻译系统最好的表现是将BLEU提升了0.26,英汉机器翻译系统是0.19。
不同的机器翻译系统,在使用本模型后的表现也是大相径庭的。比如英汉机器翻译系统BELU值提升就没有维汉机器翻译系统那么明显。造成这个现象的原因应该是维吾尔语和汉语的语法结构差异性大,导致了维汉机器翻译中调序问题相比较英汉机器翻译系统更为突出,而英汉机器翻译中更多的是翻译模型选择的译文不准确的问题,因此维汉机器翻译使用本模型的效果更为明显。此外,训练语料的好坏也在一定程度上影响了本模型的使用效果。观察两大组实验结果中的测试集1和测试集2,测试集2的平均BLEU值要高于测试集1。导致这个现象的原因应该是训练语料领域匹配度不同。最后,发现调序规则表在减少到原始规模的60%左右时性能是最好的,这是因为在此基础上可以覆盖原始的调序规则,并使其对定向概率的计算更为准确。当翻译模型减少到40%时,规则缺失的情况较多,而当翻译模型增加到80%时,过滤后的模型与之前的相差不大,因此效果不是很明显。
总的说来,本模型适用于各个语种间的机器翻译系统,同样适用于在训练机器翻译系统阶段会产生调序规则表的机器翻译系统。使用本模型,可以在减少调序规则得分表(加快解码速度)的基础上,提升机器翻译最后的译文质量。
5 结束语
本文针对统计机器翻译中普遍存在的调序问题,提出了一种基于自动编码机的调序规则表过滤模型,并分别应用于英汉和维汉机器翻译中。使用本文方法对原来生成的调序规则表进行过滤,得到新的调序规则表。然后使用新的调序规则表重新计算调序规则得分表。实验结果表明,英汉和维汉机器翻译系统在解码过程中使用新的调序规则得分表可以明显改善调序问题,还能够减少解码时间并提升最终的译文质量。
因为本文研究的对象是调序规则表,所以本文方法可以应用在任何翻译过程中会产生调序规则表的机器翻译系统。虽然目前大多数机器翻译系统都会产生调序规则表,但是也有些基于句法的翻译模型本身没有调序模型并不适用于本方法。此外,因为本模型是独立于调序模型的,调序性能的好坏对于前者的表现有依赖。基于以上,在下一阶段考虑将基于自动编码机的调序模型作为一个解码特征融入到翻译系统中。另外,也考虑在机器翻译中使用其他的深度学习方法。
[1]Koehn P,Hoang H,Birch A,et al.Moses:open source toolkit for statistical machine translation[C]//Proceedings of the 45th Annual Meeting of the ACL on Interactive Poster and Demonstration Sessions,Prague,Czech Republic,Jun 23-30,2007.Stroudsburg,USA:ACL,2007:177-180.
[2]Stolcke A.SRILM—an extensible language modeling toolkit[C]//Proceedings of the 2002 International Conference on Spoken Language Processing,Denver,USA,Sep 16-20, 2002:1409-1412.
[3]Brown P F,Pietra V J D,Pietra S A D,et al.The mathematics of statistical machine translation:parameter estimation[J]. Computational linguistics,1993,19(2):263-311.
[4]Bengio Y,Schwenk H,Senécal J S,et al.Neural probabilistic language models[M]//Innovations in Machine Learning. Berlin,Heidelberg:Springer,2006:137-186.
[5]Deng Li,Seltzer M L,Yu Dong,et al.Binary coding of speech spectrograms using a deep auto-encoder[C]//Proceedings of the 11th Annual Conference of the International Speech Communication Association,Makuhari,Chiba,Japan,Sep 26-30,2010:1692-1695.
[6]Graves A,Schmidhuber J.Framewise phoneme classification with bidirectional LSTM and other neural network architectures[J].Neural Networks,2005,18(5):602-610.
[7]Roska T,Chua L O.The CNN universal machine:an analogic array computer[J].IEEE Transactions on Circuits and Systems II:Analog and Digital Signal Processing,1993,40(3): 163-173.
[8]Yin Yue,Zhang Yujie,Xu Jin'an.Phrase table filtration based on virtual context in phrased-based statistical machine translation[J].Journal of Chinese Information Processing, 2013,27(6):139-144.
[9]Di Ping,Zhou Youliang,Gong Zhengxian,et al.Phrase table filtration in phrase-based statistical machine translation[J]. ComputerApplications and Software,2011,28(5):28-30.
[10]Zens R,Stanton D,Xu P.A systematic comparison of phrase table pruning techniques[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island,Korea,Jul 12-14,2012.Stroudsburg,USA:ACL, 2012:972-983.
[11]Koehn P,Och F J,Marcu D.Statistical phrase-based translation[C]//Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology-Volume 1,Edmonton,Canada,May 27-Jun 1,2003.Stroudsburg,USA: ACL,2003:48-54.
[12]Tillmann C,Zhang T.A localized prediction model for statistical machine translation[C]//Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics,Michigan,USA,Jun 25-30,2005.Stroudsburg,USA: ACL,2005:557-564.
[13]Xiong Deyi,Liu Qun,Lin Shouxun.Maximum entropy based phrase reordering model for statistical machine translation [C]//Proceedings of the 21st International Conference on Computational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics,Sydney, Australia,Jul 17-21,2006.Stroudsburg,USA:ACL,2006:521-528.
[14]Li Peng,Liu Yang,Sun M.Recursive autoencoders for ITG-based translation[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing,Seattle,USA,Oct 18-21,2013.Stroudsburg,USA:ACL,2013: 567-577.
[15]Xiao Xinyan,Liu Yang,Liu Qun,et al.Lexical reordering for hierarchical phrase-based translation[J].Journal of Chinese Information Processing,2012,26(1):37-41.
[16]Wang Chao,Collins M,Koehn P.Chinese syntactic reordering for statistical machine translation[C]//Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning,Prague,Czech Republic,Jun 28-30,2007.Stroudsburg,USA:ACL,2007:737-745.
[17]Papineni K,Roukos S,Ward T,et al.BLEU:a method for automatic evaluation of machine translation[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics,Philadelphia,USA,Jul 6-12,2002.Stroudsburg,USA:ACL,2002:311-318.
附中文参考文献:
[8]殷乐,张玉洁,徐金安.基于虚拟上下文的统计机器翻译短语表的过滤[J].中文信息学报,2013,27(6):139-144.
[9]狄萍,周宥良,贡正仙,等.基于短语的统计机器翻译中短语表的过滤[J].计算机应用与软件,2011,28(5):28-30.
[15]肖欣延,刘洋,刘群,等.面向层次短语翻译的词汇化调序方法研究[J].中文信息学报,2012,26(1):37-41.

KONG Jinying was born in 1988.He is a Ph.D.candidate at Xinjiang Technical Institute of Physics and Chemistry, ChineseAcademy of Sciences.His research interests include machine translation and natural language processing,etc.
孔金英(1988—),男,湖北武穴人,中国科学院新疆理化技术研究所博士研究生,主要研究领域为机器翻译,自然语言处理等。

LI Xiao was born in 1957.He is a professor and director at Xinjiang Technical Institute of Physics and Chemistry, Chinese Academy of Sciences.His research interests include multi-lingual information processing and artificial intelligence,etc.
李晓(1957—),男,新疆乌鲁木齐人,中国科学院新疆理化技术研究所所长、研究员,主要研究领域为多语种信息处理,人工智能等。发表学术论文60余篇,主持或承担多项国家863计划、中科院战略先导项目。

WANG Lei was born in 1974.He received the Ph.D.degree from Xinjiang Technical Institute of Physics and Chemistry,Chinese Academy of Sciences in 2012.Now he is a professor at Xinjiang Technical Institute of Physics and Chemistry,Chinese Academy of Sciences.His research interests include multi-lingual information processing and application software,etc.
王磊(1974—),男,新疆伊犁人,2012年于中国科学院新疆理化技术研究所获得博士学位,现为中国科学院新疆理化技术研究所研究员,多语种信息技术研究室副主任,主要研究领域为多语种信息处理,软件应用等。发表学术论文30余篇,承担过多项国家863计划、中科院战略先导项目。

YANG Yating was born in 1985.She received the Ph.D.degree from Xinjiang Technical Institute of Physics and Chemistry,Chinese Academy of Sciences in 2012.Now she is an associate professor at Xinjiang Technical Institute of Physics and Chemistry,Chinese Academy of Sciences.Her research interests include machine translation and natural language processing,etc.
杨雅婷(1985—),女,新疆奇台人,2012年于中国科学院新疆理化技术研究所获得博士学位,现为中国科学院新疆理化技术研究所副研究员,主要研究领域为机器翻译,自然语言处理等。发表学术论文30余篇,承担过多项国家863计划、中科院战略先导项目。

LUO Yangen was born in 1992.He is an M.S.candidate at Xinjiang Technical Institute of Physics and Chemistry, ChineseAcademy of Sciences.His research interests include machine translation and natural language processing,etc.
罗延根(1992—),男,江西吉水人,中国科学院新疆理化技术研究所硕士研究生,主要研究领域为机器翻译,自然语言处理等。
Research of Deep Filtering Lexical Reordering Table*
KONG Jinying1,2,3,LI Xiao1,2,WANG Lei1,2,YANG Yating1,2+,LUO Yangen1,3
1.Xinjiang Technical Institute of Physics and Chemistry,ChineseAcademy of Sciences,Urumqi 830011,China
2.Xinjiang Laboratory of Minority Speech and Language Information Processing,Urumqi 830011,China
3.University of ChineseAcademy of Sciences,Beijing 100049,China
+Corresponding author:E-mail:yangyt@ms.xjb.ac.cn
KONG Jinying,LI Xiao,WANG Lei,et al.Research of deep filtering lexical reordering table.Journal of Frontiers of Computer Science and Technology,2017,11(5):785-793.
In statistical machine translation system,lexical reordering table and phrase-table are always huge.Tuning and filtering the phrase-table has been research focus long time,while few researchers focus on filtering the lexical reordering table.This paper treats filtering lexical reordering table as the problem of short text classification,proposes a filtering model of lexical reordering table based on Autoencoder.This model uses the Autoencoder to score the reordering rules firstly,then filters the lexical reordering table by minimal difference strategy,finally recalculates lexical reordering score table used for machine translation decoding.The experimental results show that the size of lexical reordering table reduces 40%while the BLEU(bilingual evaluation understudy)increases 0.19 and 0.26 by using the proposed model on public English-Chinese corpus and Uyghur-Chinese corpus.
10.3778/j.issn.1673-9418.1603056
A
TP391.2
*The National High Technology Research and Development Program of China under Grant No.2013AA01A607(国家高技术研究发展计划(863计划));the Strategic Priority Research Program of Chinese Academy of Sciences under Grant No.XDA06030400(中国科学院战略性先导科技专项课题);the West Light Foundation of Chinese Academy of Sciences under Grant Nos.XBBS201216, LHXZ201301(中国科学院“西部之光“项目).
Received 2016-02,Accepted 2016-04.
CNKI网络优先出版:2016-04-28,http://www.cnki.net/kcms/detail/11.5602.TP.20160428.0914.002.html
Key words:Autoencoder;filtering model;lexical reordering table;machine translation
猜你喜欢
中国石油石化(2022年12期)2022-07-16
电子产品世界(2022年4期)2022-04-21
厦门大学学报(自然科学版)(2021年4期)2021-06-22
计算机系统应用(2021年2期)2021-02-23
中国外汇(2019年19期)2019-11-26
电子技术与软件工程(2019年18期)2019-11-18
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
计算机应用与软件(2018年9期)2018-09-26
电子技术与软件工程(2017年14期)2017-09-08
