
蚁群算法在数据库存储过程中的应用
2017-06-05 13:40樊红珍
电脑知识与技术 2017年7期
樊红珍


摘要;通过分析数据库存储过程的特点,作者提出了基于蚁群算法的分布式数据库存储模型。此模型根据应用中心的海量数据的分布特性,以蚁群算法原理为基础,在充分考虑负载均衡的前提下,完成了基于蚁群算法的数据库存储模型的构建。同时,该文将存储容量均衡程度、吞吐量及响应延时作为评价指标。作者在Matlab仿真软件中进行数据库存储过程的仿真验证,进而对所设计的数据库存储模型进行性能验证。验证结果表明该文设计的基于蚁群算法的数据库存储模型较顺序数据库存储策略使数据库在吞吐量方面增加了19.1%,响应延时方面减少了12.9%,同时,能够实现各数据库的存储容量均衡分布。
关键词:蚁群算法;数据库;存储过程
中图分类号:TP311 文献标识码:A 文章编号;1009-3044(2017)07-0006-02
数据应用空间是通过互联网技术和数据库技术系统构建的,其数据来源是海量互联网应用及相关服务,涉及各个领域,渗透到各个物品中。数据应用空间可以划分为感知层、网络层以及数据应用层三个层次,其中,数据应用层负责对用户产生的海量数据进行传输和处理,因此,需要性能优越的存储模型对其性能进行提升。换言之,对数据库存储过程的优化即实现其分布式存储。
目前,分布式数据库存储系统已经逐渐被人们的所重视,其主要由各PC机及分布在云端的服务器资源系统配合完成的,通过研究发现,分布式数据库存储系统主要包含以下特点:
(1)扩展性强。分布式数据存储系统的容量范围较大,从几百台数据库系统到几千台都可以,而且可以根据具体的实际应用进行动态添加,表现出的扩展性极强,而且随着数据库规模的不断扩张,其性能也应该呈线性增加趋势。
(2)成本低。分布式数据库存储系统所具备的自动纠错和自动负载均衡功能可以使其部署在性能不必很突出的普通PC设备中。而且,且扩展性使其能够实现设备的线性数量扩张,不仅控制了硬件成本,而且控制了运行维护成本。
(3)性能优越。无论是针对整个分布式数据库系统集群还是单台数据库服务器,数据库的存储过程通过多个优化方法进行协同配合,使其性能较一般的数据库系统要强。
(4)易用性强。分布数据库系统提供了第三方应用的接口,方便管理员进行功能扩展,而且在运行维护的过程中,提供了可视化的运行维护、管理工具。
在本文中,作者提出了基于蚁群算法的分布式数据库存储模型。此模型根据应用中心的海量数据的分布特性,以蚁群算法原理为基础,在充分考虑负载均衡的前提下,完成了基于蚁群算法的數据库存储模型的构建。同时,本文将存储容量均衡程度、吞吐量及响应延时作为评价指标。作者在Matlab仿真软件中进行数据库存储过程的仿真验证,进而对所设计的数据库存储模型进行性能验证。
1蚁群算法模型的建立
1.1基于蚁群算法的数据库存储方法设计
1.1.1TSP蚊群算法模型
(1)
G=(C,L)表示某个有向图,TSP主要负责从有向图G中找出距离最小的Hamilton圈,此即一条对C={c1,c2,…,cn)中被n个元素同时通过且仅通过一次的最短封闭了曲线。
为了更加准确模拟蚂蚁的实际运动轨迹,在蚁群算法模型中定义如下记号;bi(t)描述了t时刻位于元素i处的蚂蚁的总体数量;n描述了TSP蚁群的规模,m描述了蚁群中蚂蚁的总数,d描述了节点i,j之间的距离,则以上参数满足下式,
(2)
Lk描述了蚂蚁k运动轨迹的总体长度;本算法模型中通过禁忌表tabuk(k=1,2,…,m)对蚂蚁k当前所走过的所有节点元素进行记录,蚂蚁集合属性随着tabuk的进化更新过程进行实时的动态调整。Г={ij(t)|ci,cj属于C)描述了t时刻蚂蚁集合C中任意元素两两连接链路lij中包含的残留信息素的集合;τij(t)描述了t时刻运动路径(i,j)中残留信息素的总体数量。在此模型中,假定在初始时刻所有路径中包含的信息素浓度相等,且均匀分布,设初始信息素浓度τij(0)一C(C为随机正常数),而且需要说明的是蚊群算法寻求最优解的过程主要是通过有向图g=(C,L,Г)完成的,有向图对蚂蚁的运动路径进行规划,同时对信息素进行调整。
1.1.2路径选择机制
在蚁群算法模型中放置的人工蚂蚁均处于离散状态,蚂蚁选择下一移动节点的依据是此路径上的信息素浓度,选取信息素浓度大的路径。蚂蚁在整个移动的过程中通过随机策略实现游程的遍历,而且在整个游程的遍历过程中总能找到满足要求的可行解。
首先,将m只蚂蚁根据随机分布原则将其分别安置在n个节点上,然后通过系统设定的状态转移规则在每个节点上循环实施。当蚂蚁处于节点i的位置,其通过执行随机转移策略对另一个尚未经过的节点j间的运动轨迹进行确定,该策略的判断依据主要包含两方面内容,一是节点i,j之间路径上分布信息素的含量τij(t),二是两个节点间的距离。Pkij(t)描述了在t时刻蚂蚁k从节点i向节点j移动的状态转移概率,计算过程如下式所示:
(3)
在公式中,allowdk={{1,2,…,n}-tabuk)描述了蚂蚁k在下一时刻能够选择的节点集合;ηβij描述了系统的启发函数,而且对于蚂蚁k来说,dij的取值越小,k则越大,转移概率Pkij(t)也就越大。
(4)
从数学的角度来看,启发函数能够准确描述蚂蚁从节点i向节点j移动的期望程度,即系统中路径(i,j)的期望程度;α,β分别负责描述τ,η因子对此的作用程度。其中,α作为系统的信息启发式因子,能够对轨迹的重要性进行描述,等价于其值能够描述此路径中包含的信息素的含量,信息素含量越大,α值越大,意味着蚂蚁选择其他蚂蚁已经运动过的路径的可能性就越大,但α值过大会给系统带来陷入局部最优解的困难之中;β是系统的期望启发式因子,描述了能见度的相对重要性,其取值的大小直接关系到启发式信息的重要程度。如果α=0,蚁群算法越接近于典型的贪婪算法。如果β=0,蚁群算法越接近于正反馈启发式算法。综上所述,算法的蚂蚁会选择路径相对较短、信息素含量相对较高的路径作为下一时刻的运行路径。
2应用测试
本文在Matlab软件中构建仿真实验场景,仿真场景主要由两台服务器组成,同时,每台服务器与五个存储单元连接,服务器之间以及存储单元之间均使用有线网络实现信息交互,同时配备了10个数据终端向服务器的存储单元进行写操作,即实现了存储过程。写操作的数据传输速率10 M/ms,将蚁群算法融入到该仿真场景中,使其能够根据读写操作的内容合理地选择目标存储器,仿真時间设置为20分钟,实验完成后,对未使用蚁群算法和使用过蚁群算法的使用结果进行分析对比。
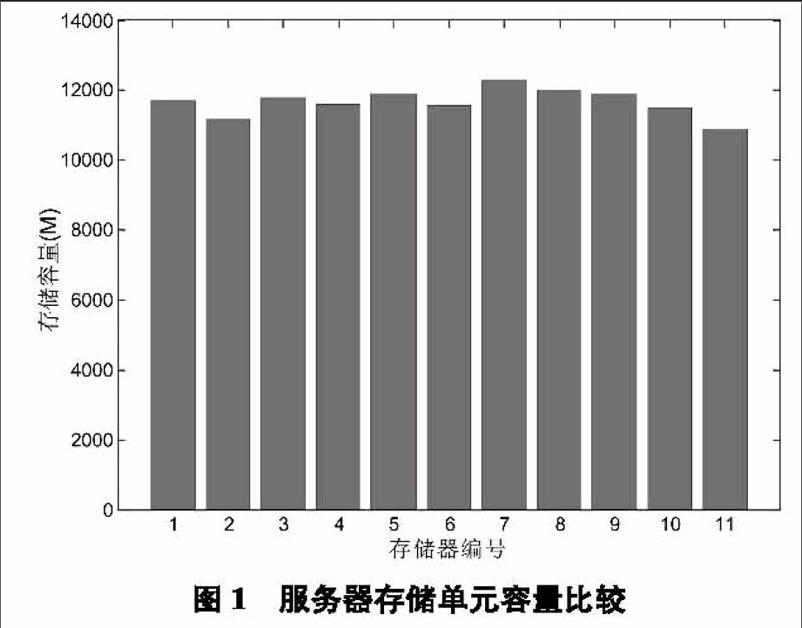
本实验的目的是实现数据存储的均衡分布,图1对10台数据库存储单元在完成了写操作后的存储容量结果,通过实验结果可以看到,使用了蚁群算法的数据库存储过程,各存储单元的容量基本维持在11 928 M左右,说明本文设计的基于蚁群算法的数据库存储方法能够有效地分布数据的存储压力,真正实现了分布式存储的思想,不会造成数据的拥堵。
而且在吞吐量及响应延时方面,与典型的顺序分布的存储器模型比较,性能也有所提升,据统计,本文设计的基于蚁群算法的数据库存储方法在吞吐量方面增加了19.1%,在响应延时方面,减少了大约12.9%。性能分析可能会很复杂,因为不同情况下系统的瓶颈点不同,有的时候是网络,有的时候是磁盘,有的时候甚至是机房的交换机或者CPU,另外,负载均衡以及其他因素的干扰也会使得性能更加难以量化。
3总结
在本文中,作者通过分析数据库存储过程的特点,作者提出了基于蚁群算法的分布式数据库存储模型。此模型根据应用中心的海量数据的分布特性,以蚊群算法原理为基础,在充分考虑负载均衡的前提下,完成了基于蚁群算法的数据库存储模型的构建。同时,本文将存储容量均衡程度、吞吐量及响应延时作为评价指标。作者在Matlab仿真软件中进行数据库存储过程的仿真验证,进而对所设计的数据库存储模型进行性能验证。验证结果表明本文设计的基于蚁群算法的数据库存储模型较顺序数据库存储策略使数据库在吞吐量方面增加了18.3%,响应延时方面减少了14.2%,同时,能够实现各数据库的存储容量均衡分布。
