
基于历时语料的词语稳定性度量
2017-06-15 15:07张卫华
河南科技 2017年7期
张卫华
(郑州大学电气工程学院,河南郑州 450001)
基于历时语料的词语稳定性度量
张卫华
(郑州大学电气工程学院,河南郑州 450001)
词语是能独立使用的最小语法单位,词汇大纲是语言教学的基础,研制一个科学的、反映语言生活现实与人类认知规律的词表,对于提高汉语教学效果具有重要意义。本文基于历时语料,从词频和词义两方面对词语的稳定性进行度量,以期为汉语词表的构建提供参考。对词频稳定性的2种统计指标进行相关性分析,在词义稳定性度量中引入词向量,对词语的稳定性分布情况进行考察。通过对HSK汉语水平考试词汇等级大纲(2012年修订)的分析表明,总体上,本文提出的稳定性度量能较好地体现出大纲的等级分布,即大纲级别越低,词语稳定性越高,并可以为大纲的更新与调整提供依据。
历时语料;词语稳定性;词频稳定性;词义稳定性;HSK词汇大纲
随着社会的快速发展,语言也在不断发展和演化,社会语言学与自然语言处理的许多任务都依赖于词汇信息,研究和度量词汇稳定性必不可少。自然语言是动态的,随时间演变适应其用户和环境的需要[1],根据词汇的历时信息不仅可以判断其在特殊时期及相应领域的使用情况,而且还能反映相应的社会状况和人民生活的变化。每个时间段上的词汇都带有以往的语言历史,是历史的混合产物。
词汇稳定性的研究有助于现代汉语水平大纲的编写,词汇的历时信息更能帮助汉语学习者了解和认识汉语的历时演变。例如,通过对比和分析《汉语水平词汇与汉字等级大纲》[2]与统计稳定度得到汉语词汇的异同,不仅发现和收录词汇大纲未录用的常用词,而且可以删除稳定度较低的历史词汇。通常利用统计分析方法,如词频、信息熵等度量词汇的稳定性。王治敏[3]利用语料的频次信息和时间跨度,通过不同的时间点,统计得到历时变化的汉语常用词表。统计词表不仅为《汉语水平词汇与汉字等级大纲》新词的录用和历史性词语的删除提供了有价值的数据,也为初学汉语者提供了可靠的参考。
本文基于历时语料,从词频和词义两方面对词语的稳定性进行度量,以期为汉语词表的构建提供参考。对词频稳定性的2种统计指标进行相关性分析,以了解不同指标之间的关系。在词义稳定性度量中引入词向量,利用“观其伴,知其义”的思想,通过观察词义相近词的情况来度量词义稳定性。最后把词语稳定性应用于HSK汉语水平考试词汇大纲的分析,并为词汇大纲的修订提供依据。
1 相关研究
研究人员针对历时语料的词语稳定性研究已经采取了诸多方法。针对词频稳定性方面,荀恩东等[4]采用自然语言处理的相关技术,基于词语的频次、频率以及香农熵的方法分析研究历时新闻语料,开发了现代汉语词汇历史检索系统,此系统对词汇的语义、语用等方面的研究较为突出,反映新词的变化过程及公共领域的词语信息;王治敏[5]根据历时语料词语的频繁和稳定程度判断常用词汇,提出词语稳定程度参数U来判断词语随时间变化的稳定性,该方法得出的常用词词表可实现《汉语水平词汇与汉字等级大纲》(简称HSK词汇大纲)的半自动更新,以及为利用新闻语料研究常用词提供强有力的依据;Kulkarni等[6]利用词频模型捕捉词语随时间变化的各个方面,频率的变化与词语产生新词义或失去词义的变化相一致,所以利用词频变化获取词义变化。
关于词义稳定性方面,Yoon Kim等[7]利用神经语言模型训练历时语料得到词向量,其中利用前一年的词向量来初始化后一年词向量的训练,根据计算词语在不同时间段的余弦相似度衡量语义的稳定性;Popescu和Strapparava[8]采用政治、社会等某些术语与情感词语的频率统计检验识别语言变化和时间段之间的相关性;胡俊峰等运用点互信息(Pointwise Mutual Information,PMI)计算每个词对的分布相似性,而PMI是采用构建共现向量和余弦的权重或归一化点积的方法,根据语义相似的交集揭示了词语的语义或用法在较短时间间隔内趋于稳定,以及可以获得历时敏感词语和历时不敏感词语;Jey-Han Lau等将主题模型应用到词义归纳(Word Sense Induction,WSI)上,通过历时语料分析具有高边际概率的主题词识别随时间变化的词语语义。
2 词频的稳定性度量
本文基于历时语料,使用统计分析方法即词频和信息熵度量词语稳定性。衡量词语稳定程度的参数U(公式1)和信息熵(公式4)作为衡量词语稳定性的指标,其中衡量词语稳定程度的参数U反映词语在语料中出现的平均频次及词语随时间波动等因素[5],即:

式(1)中,fˉ表示词语出现的平均频次,计算公式如(2)所示,stdev(f)代表词语出现的频次标准差,计算公式如(3)所示。

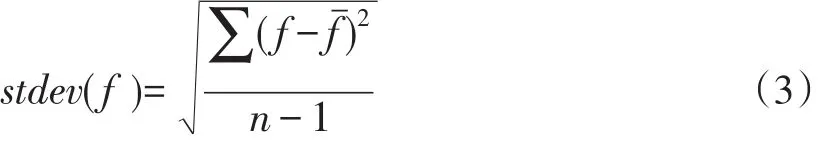
其中,式(2)与式(3)中的n为词语统计频次f的个数。
词语稳定度参数U值与词语在历史语料库中出现的平均频次成正比,与词语出现频次的标准差成反比,根据U值的排序,判断词语的稳定性。
信息熵作为衡量词语稳定性的指标,描述词语的不确定性的数量,熵越大,不确定性越大。H(X)代表词语的信息熵,即:

式(4)中,p(x)为词语x每一年的概率,即词语在每一年出现的频次与该词语在历年出现总频次的比值,R为该词历年出现情况的集合。
3 词义的稳定性度量
与传统语言模型相比,本文基于历时语料,采用神经语言模型获取更深层次的词义信息。神经语言模型依赖的一个核心概念就是词向量,而词向量是用一个向量来表示一个词,一定程度上可以刻画词之间的语义距离。利用上下文信息进行词表示,具有相同(类似)上下文信息的词应该具有相同(类似)的词表示即词向量。我们使用Mikolov等提出的Word2vec模型中的Skip-gram模型训练词向量。Skip-gram模型是通过语料库中每个词预测周围的词语,Skip-gram的输入是当前词的词向量,而输出是周围词的词向量。
词语在词义上彼此接近同样在词向量空间里也相近,通过余弦距离表示词语在向量空间里的距离,从而得到词语词义相近的词。定义词语w从时间y1到时间y2的语义稳定性指数(Sense Stability Index,SSI),计算公式如(5)所示。
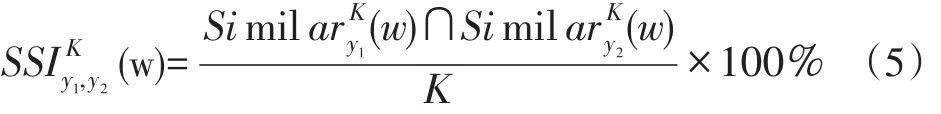
4 实验与分析
实验考察1946-2005年度的《人民日报》词语稳定性,包括词频稳定性和词义稳定性度量。利用中科院ICTCLAS汉语分词系统对60年《人民日报》进行分词,在分词结果基础上度量词语稳定性。同时,利用词频稳定性和词义稳定性指标与2012年版《汉语水平词汇与汉字等级大纲》(简称HSK词汇大纲)词语等级进行比较。
4.1 词语的词频稳定性实验与分析
通过spearman相关系数比较词语稳定度U与信息熵的相关程度,计算得到词语稳定度U值与信息熵的spearman相关系数值为0.98,显著性水平p<0.001。词语稳定度U值和信息熵高度相关,选择其一即可,本文采用词语稳定度U值度量词频稳定性。spearman相关系数的计算公式如(6)所示。

式(6)中,di为信息熵和词语稳定度的排行差分集合,N为词语的个数。
度量词语的词频稳定性,统计1946-2005年度《人民日报》中每年的词频,计算每个词语的平均频次fˉ和词语出现的频次标准差stdev(f),根据公式(1)计算出衡量词语稳定程度的参数U,将U值进行排序,选取数值排名靠前的10个词语,如表1所示。根据词语的词频稳定性U值大小,统计每个稳定度阶段词语的个数,如表2所示,词频稳定参数阶段的U值越大,其词语的词频稳定性越高,而其包含的词语个数越少,说明使用量大的汉语稳定性不高,其稳定性容易受历史事件等影响。
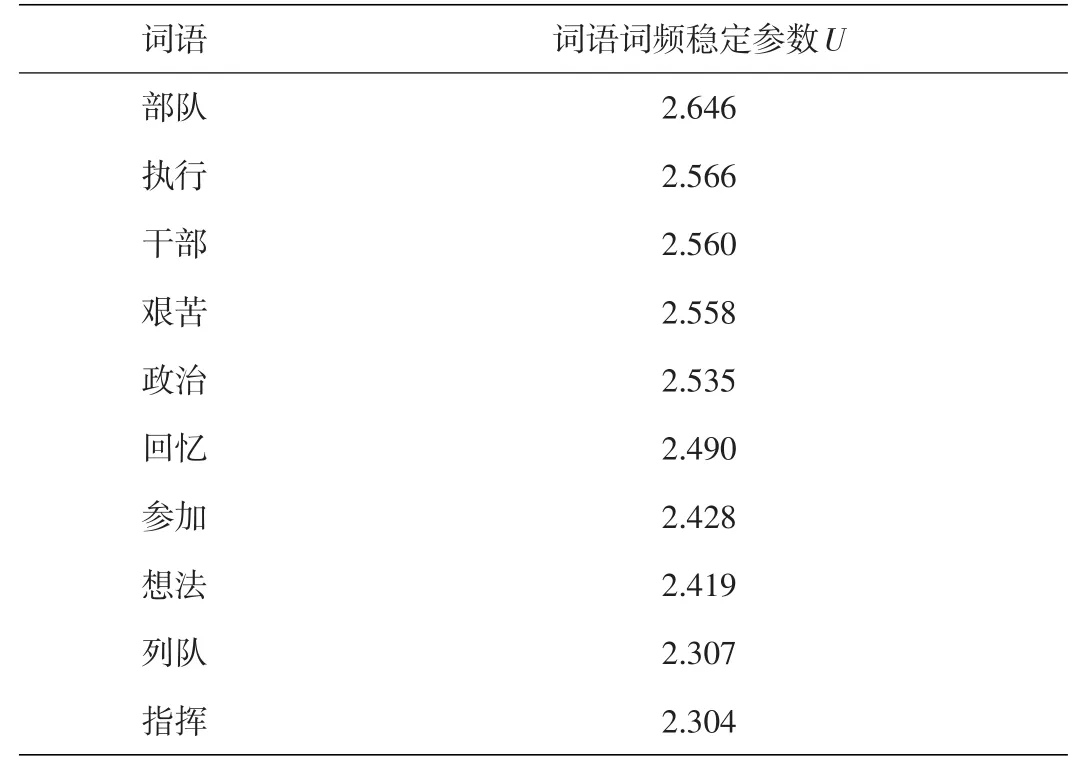
表1 U值排名靠前的词语
词语稳定度参数U值与词语在历史语料库中出现的平均频次成正比,词语的平均频次反应在语料中使用该词语的频繁程度,而与词语出现频次的标准差成反比,标准差反应该词语频次波动程度,在历年语料中词语分布越不稳定,标准差越大,U值越小,比如和年度突发事件的词语标准偏差很大,参数U就会把这些词语排除在外。本文针对1946-2005年度的《人民日报》,“部队”“干部”“列队”这些词语在早期就被频繁使用,随着时间的推移,这类词语的使用频次一直稳定且幅度较为平稳,所以U值排名较高,词语比较稳定。

表2 词语词频稳定度分布表
4.2 词语的词义稳定性实验与分析
度量词语的词义稳定性,使用Word2vec模型中的Skip-gram模型对每一年《人民日报》语料训练词向量,模型参数设置为窗口大小为2,向量维度为200维。每个词语在每一年的词向量通过余弦距离计算,选取与其距离最近的K=100个词语,本文选择2005年与1946年作为时间y1到时间y2,根据公式(5)计算得到语义稳定性指数(SSI),将SSI值进行排序,选取数值排名靠前的10个词语,如表3所示。根据词语“只有”在60年《人民日报》中语义分布画出曲线变化图,将2005年作为y2,1946-2004年中每一年作为y1,计算SSI值,如图1所示。
根据表3中语义稳定性指数SSI值排名,发现SSI值较高的词语中虚词居多,这符合虚词的语义稳定特征,根据“只有”的语义变化曲线,分布平稳,因此,该词语的稳定性较高。而SSI值较低的词语的词义稳定性随时间发生变化,选取词语“透明”(SSI=0),画出“透明”在60a《人民日报》中语义分布画出曲线变化图,如图2所示。
根据图2显示,词语“透明”在1997年左右SSI值变化幅度巨大,说明该词语的词义发生巨大变化,根据“透明”在2005年和1998年的语义相似词语的交集:“公正,公开,阳光,公平,有序,无色,专账,参与权,整洁,暗箱,自由,严格,一望,明亮”,表明“透明”词义发生隐喻变化,产生抽象的新词义,指的是市场、政府和法律等的公开化;起初,“透明”的词义是玻璃,水和其他物理事物的性质。因此,“透明”的词义稳定性低。

表3 SSI值排名靠前的词语
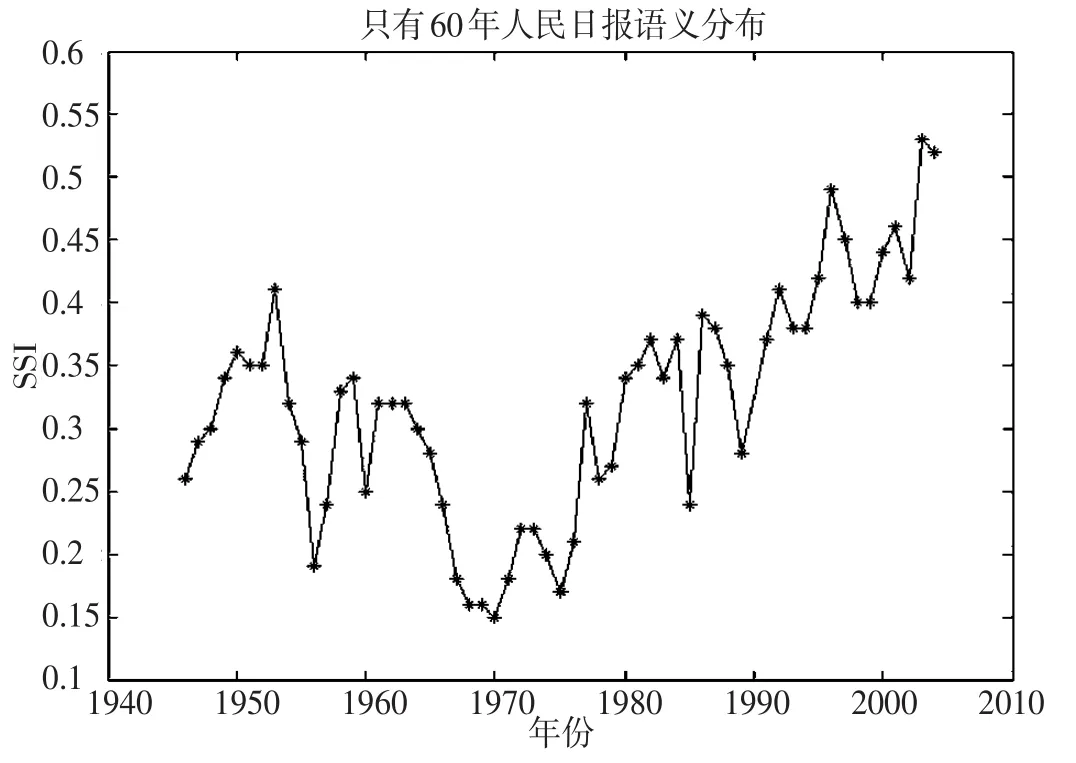
图1 词语“只有”60年的语义变化曲线
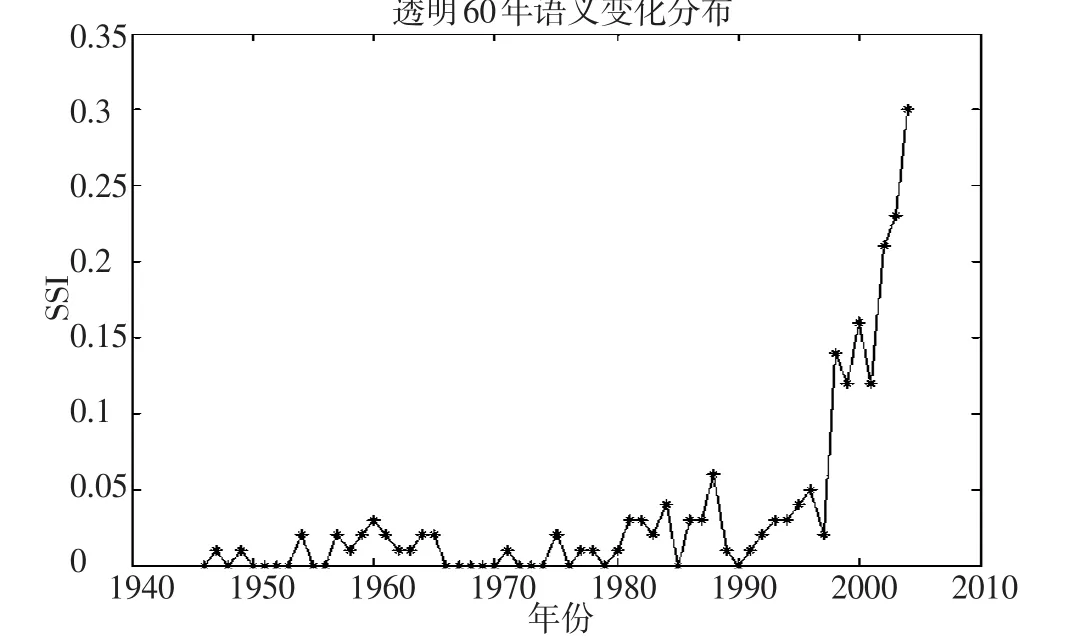
图2 词语“透明”60年的语义变化曲线
4.3 词语的稳定性指标与HSK词汇大纲等级比较
《汉语水平词汇与汉字等级大纲》(简称HSK词汇大纲)的词语具有等级划分,根据词语的常用度分为1~6个等级。利用本文提出的词频稳定性指标U值和词义稳定性指标SSI值对HSK词汇进行词频稳定性和词义稳定性度量,将词汇U值和SSI值按照HSK的等级划分为6个区间,分别对每个区间的U值和SSI值求均值,如表4所示,计算公式如(7)(8)所示。
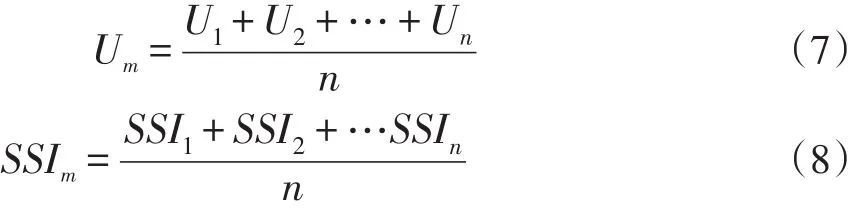
式(7)(8)中,n为每个区间所求U值和SSI值词语的个数。

表4 词语稳定性与HSK词汇大纲比较
HSK词汇等级越低其常用性就越高,根据表4所示HSK等级低的词语的U值和SSI值高,因此,这些词语的稳定性就高、常用性高。因此,可以利用本文提出的度量词语稳定性指标对HSK词汇大纲中的词汇进行更新,若某些词语的词频稳定参数U或词义稳定性指数SSI低于上述标准,就可以过滤HSK中过时的词汇或者更新其等级,实现HSK的半自动更新。例如,词语“政府”在HSK词汇大纲里的等级为5,根据本文提出的词语稳定性指标计算出U值为1.758,SSI值为0.09,明显大于表中所求的值。所以,可以考虑调低其在HSK词汇大纲里的等级。
5 结语
本文提出基于历时语料的词语稳定性度量方法,包括词频稳定性和词义稳定性两方面。在词频稳定性度量中,得出了词频稳定参数与信息熵两个统计指标的一致性结论。在词义稳定性度量中,引入了深度学习中的词向量方法。在60年人民日报历时语料基础上,对词语稳定性度量结果进行了定量考察。最后,尝试把词语稳定性度量结果应用于HSK词汇等级大纲的分析与调整。
词语稳定性作为词语的一个重要属性,也可以为词汇语义研究的目标词选择提供依据,可以从使用最稳定的那些词作为切入点开始某一项研究任务。词义的历时演变将是下一步研究的重点,词语的稳定性可以表明哪些词发生了变化,但具体怎样变化、变化的模式是什么需要进一步研究。
郑州大学信息工程学院研究生郑一对本文的数据处理和实验分析等工作有重要贡献。
[1]Aitchison J.Language Change:Progress or Decay?[J].Language in Society,1983(2):411.
[2]国家汉语水平考试委员会办公室考试中心.汉语水平词汇与汉字等级大纲[M].北京:经济科学出版社,2001.
[3]王治敏,杨尔弘.面向汉语教学的常用动词计量研究[J].语言教学与研究,2012(1):1-6.
[4]荀恩东,饶高琦,谢佳莉,等.现代汉语词汇历时检索系统的建设与应用[J].中文信息学报,2015(3):169-176.
[5]王治敏.基于时间跨度的汉语教学常用词表统计研究[J].华文教学与研究,2010(4):49-55.
[6]Kulkarni V,Alrfou R,Perozzi B,et al.Statistically Significant Detection of Linguistic Change[J].Computer Science,2014:625-635.
[7]Kim Y,Chiu Y,Hanaki K,et al.Temporal Analysis of Language through Neural Language Models[J].Computer Science,2014 (3):153-178.
[8]FBK-irst,Trento,Popescu O,et al.Strapparava.2013.Behind the Times:Detecting Epoch Changes using Large Corpora[A]// International Joint Conference on Natural Language Processing,2013:347-355.
Measuring Word Stability Based on a Diachronic Corpus
Zhang Weihua
(School of Electrical Engineering,Zhengzhou University,Zhengzhou Henan 450001)
Word is the smallest grammatical unit that can be used independently while lexicon is the foundation of language teaching.To improve the effectiveness of Chinese teaching,it is of great significance to develop a scientific vocabulary that reflects the reality of language life and the laws of human cognition.Based on a diachronic corpus, This paper measured the stability of words from two aspects,word frequency and word meaning,to provide a reference for the construction of Chinese vocabulary.This paper made a statistical correlation analysis of the two word frequency stability measures,and introduced word embeddings into the word sense stability measure.Quantitative analysis of word stability distribution was carried out based on the diachronic corpus.After investigation of the HSK vocabulary level outline,it showed that the computed word stability could correlate well with the vocabulary levels,and provided a good knowledge source for the updating and adjustment of the outline.
diachronic corpus;word stability;word frequency stability;word sense stability;HSK vocabulary outline
TP391.1
A
1003-5168(2017)04-0056-04
2017-03-25
张卫华(1963-),女,大专,研究方向:图书情报。
猜你喜欢
工会博览(2022年33期)2023-01-12
汉字汉语研究(2021年1期)2021-06-11
汉字汉语研究(2021年1期)2021-06-11
红楼梦学刊(2019年5期)2019-04-13
汉字汉语研究(2018年3期)2018-11-06
中国修辞(2017年0期)2017-01-31
军事体育学报(2016年2期)2016-06-15
读者·校园版(2015年7期)2015-05-14
图书馆论坛(2014年8期)2014-03-11
心理学报(2014年4期)2014-02-02
