
Spark DAG优化MapReduce协同过滤算法*
2017-06-19 15:59廖彬张陶于炯国冰磊张旭光刘炎
中山大学学报(自然科学版)(中英文) 2017年3期
廖彬,张陶,于炯,国冰磊,张旭光,刘炎
(1. 新疆财经大学统计与信息学院, 新疆 乌鲁木齐 830012; 2. 新疆大学信息科学与工程学院, 新疆 乌鲁木齐 830008; 3. 新疆医科大学医学工程技术学院, 新疆 乌鲁木齐 830011; 4. 清华大学软件学院,北京 100084)
Spark DAG优化MapReduce协同过滤算法*
廖彬1,张陶2,3,于炯2,国冰磊2,张旭光1,刘炎4
(1. 新疆财经大学统计与信息学院, 新疆 乌鲁木齐 830012; 2. 新疆大学信息科学与工程学院, 新疆 乌鲁木齐 830008; 3. 新疆医科大学医学工程技术学院, 新疆 乌鲁木齐 830011; 4. 清华大学软件学院,北京 100084)
大数据的规模效应给数据存储、管理以及数据分析带来了极大的挑战,高效率低成本的大数据处理技术成为学术界及工业界的研究热点。为提高协同过滤算法的执行效率,对MapReduce架构下的算法执行步骤进行了分解,并对算法执行缺陷进行了分析。结合Spark适于迭代型及交互型任务的特点,提出将算法从MapReduce平台移植Spark平台的改进思路。设计了算法在Spark中的实现流程,并通过参数调整、内存优化等方法进一步提高算法效率。实验结果表明:与MapReduce平台中的算法相比,基于Spark DAG调度的算法能够减少65%以上的HDFS重复I/O操作,执行效率与能耗效率分别提升近200%及50%。
协同过滤;MapReduce;Spark;算法优化;能耗优化
大数据时代,数据从简单的处理对象开始转变为一种基础性资源,如何更好地管理和利用大数据已经成为普遍关注的话题,大数据的规模效应给数据存储、管理以及数据分析带来了极大的挑战[1]。据文献[2]统计,2007年全球数据量达到281EB,而2007-2011年这5年时间内,全球数据量增长了10倍。数据量的高速增长伴随而来的是存储与处理系统规模不断的扩大,这使得运营成本不断的提高,其成本不仅包括硬件、机房、冷却设备等固定成本,还包括IT设备与冷却设备的电能消耗等其它开销。以至于文献[1]中指出:在能源价格上涨、数据中心存储规模不断扩大的今天,高能耗已逐渐成为制约云计算与大数据快速发展的一个主要瓶颈。一方面,虽然MapReduce逐渐成为工业与学术界事实上的海量数据并行处理标准,但MapReduce的优势在于处理批处理作业。对于具有复杂业务处理逻辑的互联网数据挖掘类作业,MapReduce计算效率并不理想。另外,在能耗利用效率方面,文献[3-4]研究结果表明:MapReduce集群内部服务器存在严重的高能耗低利用率问题。已有研究通常围绕存储、索引及迭代计算等方面对MapReduce进行效率改进[5-6],而文献 [7-18] 则针对MapReduce或HDFS存在的能耗问题进行改进。但是,由于MapReduce的设计灵感来源于函数式编程语言(如:Lisp、Scheme、ML等),并且在进行架构设计时就没有考虑到系统的能耗问题,导致已有的能耗优化效果并不显著。
在此背景下,高效率低成本的大数据处理技术成为学术界及工业界的研究热点。Spark站在巨人的肩膀上,依靠Scala强有力的函数式编程、Actor通信模式、闭包、容器、泛型,借助统一资源分配调度框架Mesos,融合了MapReduce和Dryad,最后产生了一个简洁、直观、灵活、高效的大数据分布式处理框架。与Hadoop不同,Spark一开始就瞄准性能,将数据(包括部分中间数据)放在内存中进行计算。将重复利用的数据缓存到内存,以此提高计算效率,因此Spark尤其适合迭代型和交互型任务。但是随着MapReduce计算框架的广泛应用,已有的协同过滤算法大多基于MapReduce框架实现。与文献[3-4]研究结果一致,我们在前期研究[19-20]中发现MapReduce框架下的协同过滤算法执行效率较为低下。为了提高协同过滤算法的效率,本文做了如下工作:首先,对MapReduce框架下的协同过滤算法的实现步骤进行分解,在此基础上对算法的效率缺陷进行了分析;其次,在对MapReduce效率分析的基础上将算法从MapReduce移植到Spark平台,并对实现流程、移植方法及平台优化进行了研究;最后,通过实验证明了算法移植后在任务执行时间及能耗效率等方面的提升。
1 相关研究
协同过滤推荐算法的输入可以表示为m×n的用户项目评分矩阵(如表1所示)。其中m表示用户数量,n表示物品数量,Rij表示第i个用户对第j个物品的评分(其中i∈[1,m],j∈[1,n])。Rij值的范围可以根据实际应用系统的特点进行设定,连续或离散的情况都有,大多应用系统中采用数值为1~5的离散值来表示评分,而0则表示用户尚未对该项目进行评分。

表1 用户项目评分矩阵
传统的协同过滤系统主要分为基于用户、物品及混合协同过滤3种类型。其中基于用户的协同过滤的主要思想是:如果用户i没有对项目j进行评分,则找到与用户i最相似的k个邻居用户(通常采用Pearson相关系数计算用户之间的相似性);然后利用这k个邻居用户对项目j的评分加权平均来预测用户对项目j的评分值Rij。采用Pearson相关系数计算用户x与y的相似度公式为:
(1)
设用户u对物品i的评分值Ru,i计算公式为:
(2)
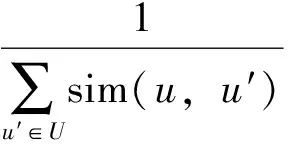
基于物品过滤的协同过滤主要思想是:如果用户i对项目j没有评分,设Rij=0;找到与物品j最相似的k个近邻(通常采用余弦距离计算相似性);然后利用k个邻居对项目j的评分的加权平均来预测用户i对项目j的评分。利用基于物品过滤的协同过滤方法计算用户u对商品i的评分公式为:
(3)
其中N表示商品i的近邻集合,相似性计算公式可采用余弦距离。混合协同过滤则是在基于用户的协同过滤基础上,在计算两个用户之间的相似度时嵌入了item-based CF思想,对相似性的度量进行了改进。
除了以上3种常用协同过滤算法之外,还有基于内容的协同过滤[21-22]、基于规则的协同过滤[23-24]、基于人口统计信息的协同过滤[25-26]、基于网络结构的协同过滤[27-28]及混合过滤[20, 29-34]等。以上这些协同过滤研究工作的目的都是以提高算法在特定应用领域的推荐质量为首要目标,很少针对算法的运行平台、算法平台之间的移植及算法的执行效率进行研究。在此背景下,本文以基于Item的协同过滤算法为例。首先对MapReduce架构下的协同过滤算法运行方式的缺陷进行了分析;利用Spark相比于MapReduce的优点,将算法从MapReduce平台移植到Spark平台,从而较大程度上的提高算法的效率(包括时间、资源利用、能耗等效率)。
2 基于MapReduce的协同过滤算法及缺陷分析
本文以基于Item的协同过滤算法为例,分析在MapReduce平台下实现协同过滤算法存在的问题。之所以选择基于Item的协同过滤算法为例,这是由于Item与Item之间的相似度比较稳定,并且可以进行离线计算,可实现定期更新功能,这使得基于Item的协同过滤算法在电子商务领域运用更为广泛。
首先,基于Item的协同过滤算法认为相似的Item获得同一用户的评价也应该相似。所以,算法的基本思路是:首先计算用户(User)对物品(Item)的喜好程度;然后根据用户的喜好,计算Item之间的相似度;最后找出与每个Item最相似的前N个Item推荐给用户。在进行算法实现时,可将算法切分为以下7个MapReduce任务,具体的切分如表2所示。

表2 基于Item的系统过滤算法MapReduce实现步骤切分
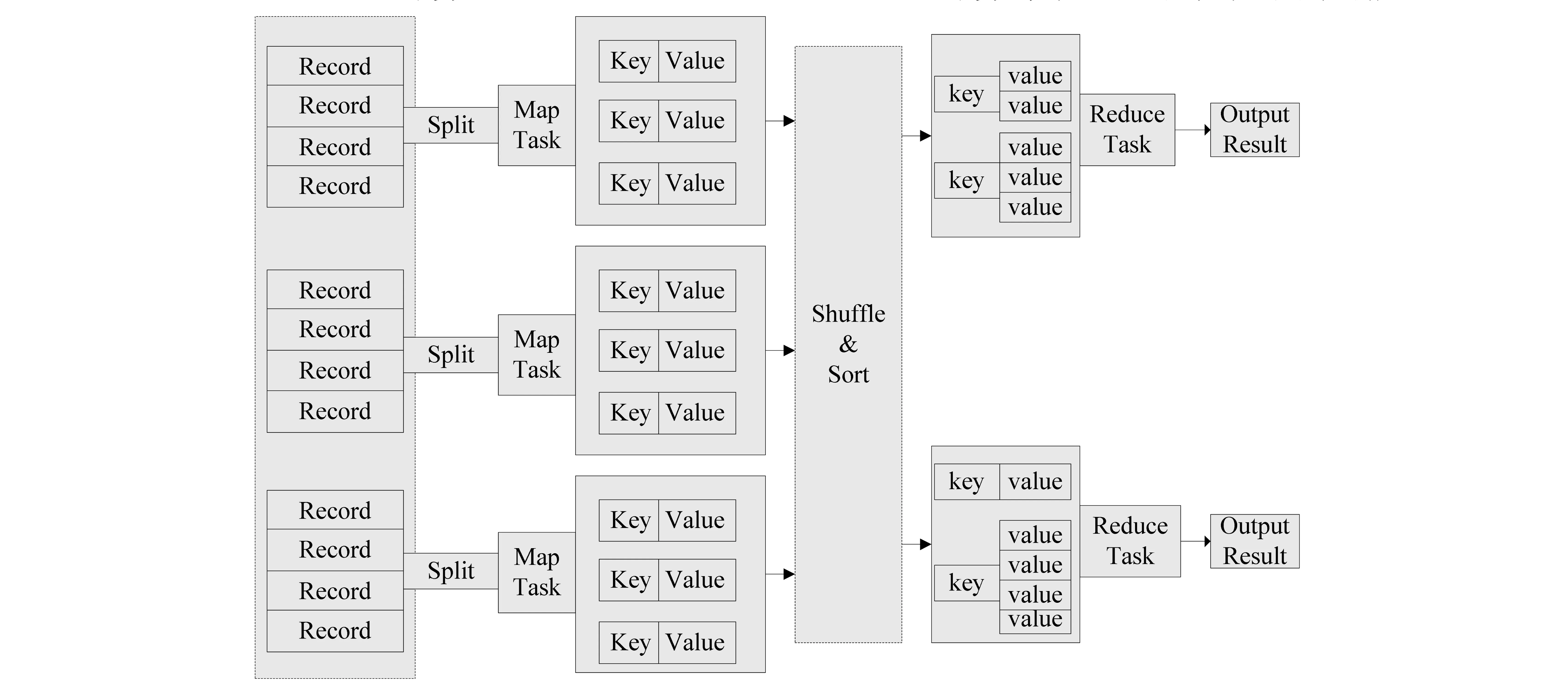
图1 MapReduce作业的任务分解Fig.1 MapReduce job decomposed into tasks

图2 算法MapReduce作业关系图Fig.2 MapReduce Job relationship diagram
如表2所示,在MapReduce平台中实现基于Item的协同过滤算法一共需要执行7个MapReduce作业(Job)。如图1所示为MapReduce的作业切分模型,每个MapReduce作业都会被切分为多个Map与Reduce任务(Task)。Map任务执行过程中需要将数据从HDFS中读取进来,计算完毕后再通过Shuffle与Sort操作将
如图2所示为算法7个作业之间的联系图,由于基于Item的协同过滤算法一共有7个MapReduce作业,意味着算法需要进行7次的HDFS读取及写入操作,这些重复的数据读写操作耗费集群资源的同时降低了算法执行的效率。并且,MapReduce作业在集群中进行调度,当集群资源出现“竞争”,或任务之间出现“等待”现象时,将对算法的执行效率产生影响。为了解决这些MapReduce计算效率低效的问题,本文将在下一章对基于Spark DAG调度的优化算法进行详细介绍。
3 基于Spark DAG调度的优化算法
本章一共分为3个小节,首先将协同过滤算法从MapReduce移植Spark平台的优势进行了分析;其次介绍了在Spark平台中算法的执行流程;最后介绍通过分区参数优化、内存优化及集群规模优化等方法提高算法执行效率。
3.1 算法移植Spark平台原因
本文将推荐算法从Hadoop平台移植到了Spark平台,移植的原因主要有以下3点:
(i) Spark的中间数据直接缓存到内存中,对于Hadoop迭代运算效率更高。
Spark相比Hadoop更适合做迭代运算。因为Spark里的RDD(Resilient Distributed Dataset)直接cache到内存中。每次对RDD数据集的操作之后的结果,都存放到内存中,下一个操作可以直接从内存中输入,相比MapReduce省去了大量的重复磁盘IO操作。
(ii) Spark 实现业务逻辑比Hadoop更灵活。
与Hadoop只提供Map和Reduce两种基本操作不同,Spark提供的数据集操作类型则更为丰富,比如map, filter, flatMap, sample, groupByKey, reduceByKey, union, join, cogroup, mapValues, sort, partionBy等,而这些操作可统称为Transformations。并且,Spark同时还提供count, collect, reduce, lookup, save等多种action。Spark这些多种多样的数据集操作类型,给上层应用编程提供了更多的自由度。各个处理节点之间的通信模型不再像Hadoop那样就是唯一的Data Shuffle一种模式。用户可以命名,物化,控制中间结果的分区等,使得Spark的编程模型比Hadoop更灵活。
(iii) Spark编程代码更为简洁。
由于Spark在设计时模仿了Scala的函数式编程风格及API。而MapReduce的设计灵感来自于函数式编程语言LISP。所以,在进行MapReduce向Spark移植的过程其本质是两种编程风格的移植。尽管Spark的主要抽象是RDD,实现了map,reduce等操作,但这些都不是Hadoop的Mapper或Reducer API的直接模仿。这些转变也往往成为将Mapper和Reducer类平行迁移到Spark的障碍。与Spark中经典函数语言实现的map和reduce函数相比,原有Hadoop提供的Mapper和Reducer API 更灵活也更复杂。如下代码所示:在实际的移植过程中,Spark省略了Hadoop如下繁琐的Map与Reduce函数代码,只需直接编写业务实现代码。
public class MyMapper extends
Mapper
protected void map(LongWritable lineNumber, Text line, Context context)
throws IOException, InterruptedException {
∥Map函数业务代码
}
}public class MyReducer extends Reducer
protected void reduce(IntWritable length, Iterable
Context context) throws IOException, InterruptedException {
∥Reduce函数业务代码
}
}
Spark中,输入只是String构成的RDD,而不是key-value键值对。Spark中对key-value键值对的表示是一个Scala的元组,用(A,B)这样的语法来创建。Spark的RDD API有reduce方法,但它会将所有key-value键值对reduce为单个value。这并不是MapReduce编程模型中的行为,Spark中与之对应的是reduceByKey。
3.2 基于DAG调度的算法实现
经过上节的分析,可知相比与MapReduce,Spark提供了更加灵活的DAG(Directed Acyclic Graph)编程接口,包含map、reduce接口的同时,还增加了filter、flatMap、union等操作接口,使得编写Spark程序更加灵活方便。在Spark中实现基于Item的协同过滤算法如图3所示。
如图3所示为基于Item的协同过滤算法在Spark中的实现流程,整个流程分为8个阶段,18个RDD数据。将算法从MapReduce平台移植到Spark平台,并将算法流程从图2变换为图3;至少在以下3个方面优化了算法执行时间及资源的利用。
(i) Spark中的RDD(Resilient Distributed Dataset)数据模型相对于存储在HDFS中的数据在读写方面更为高效。算法在Spark平台执行过程中的中间数据都以RDD的形式存储(实质是RDD分布存储于各slave节点的内存中),相对于MapReduce大大的减少了计算过程中读写磁盘的次数。另外,RDD还提供了Cache机制,比如RDD3进行Cache后,RDD4和RDD7都可以同时访问RDD3的数据。相对于MapReduce平台减少了MR JOB2和MR JOB3(如图3所示)重复从HDFS中读取相同数据的问题。
(ii) Spark作业启动后会立即申请所需的Executor资源,并且所有Stage的Tasks以线程的方式运行,共用Executors资源。这相对于MapReduce以心跳的方式管理Slot资源,Spark申请资源的次数大大的减少,导致资源管理效率高于MapReduce。

图3 基于Item的协同过滤算法在Spark中的实现流程Fig.3 The implementation flow of item based collaborative filtering algorithm in Spark
(iii) Spark实现方法最重要的改进是,MapReduce中一共有7个Job,而通过Spark中的DAG编程模型,可以实现将7个MapReduce作业简化为一个Spark DAG作业。如图所示,Spark会将DAG作业分解为8个Stage,每个Stage包含多个可并行执行的Tasks。Stage之间的数据通过Shuffle传递,而在算法的数据输入与输出方面,Spark也只需要读取和写入HDFS一次,从而减少了6次HDFS数据的读写操作。
3.3 系统层级优化方法
实验过程中我们发现,算法在Spark平台执行过程可通过分区参数优化、内存优化、集群规模优化及系统参数优化4个方面对算法执行效率进行改进。优化方法所对应的说明如表3所示。

表3 优化方法及说明
4 实验评价与比较
4.1 实验环境
为了对算法改性效果进行对比,实验的测试数据量为5亿,其中数据的格式为(uid,itemId,ratingScore),含义为用户uid对itemId的评分结果为ratingScore。实验在2组不同规模集群上进行测试,第1组节点规模为10,第2组节点规模为20。为了保证测试的有效性,每组测试实验重复进行20次。实验的配置参数如表4所示。
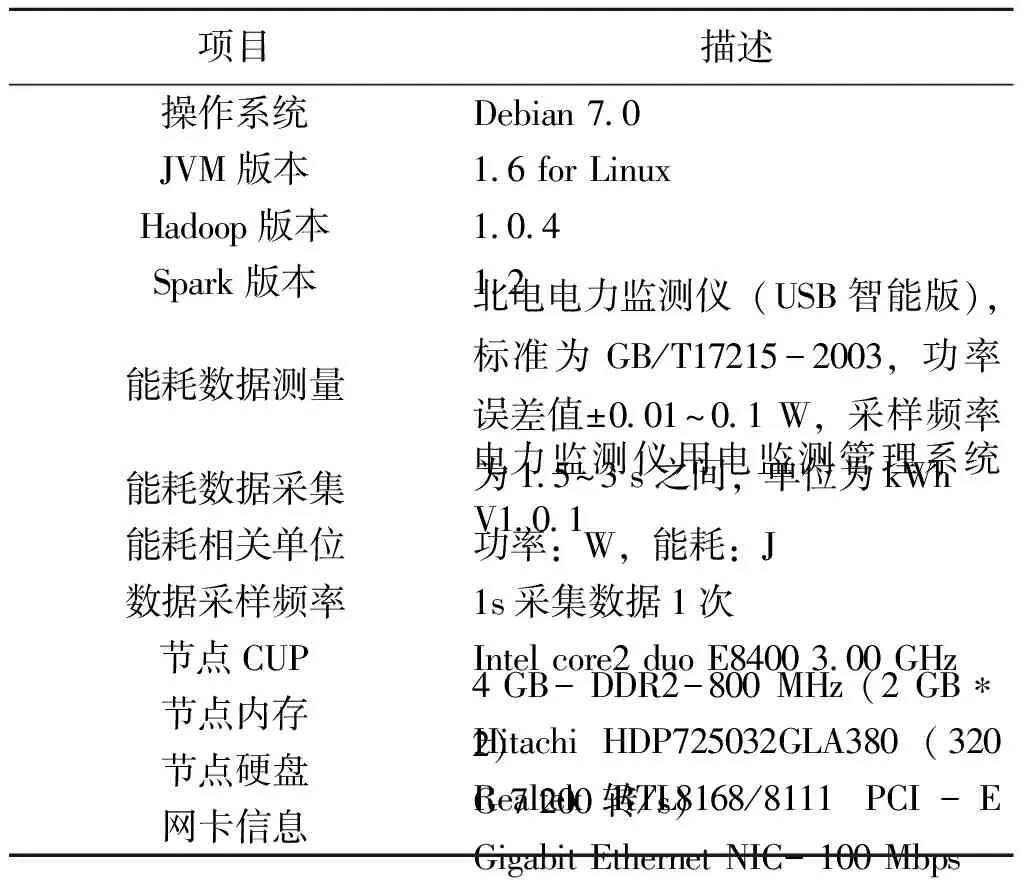
表4 总体实验环境描述
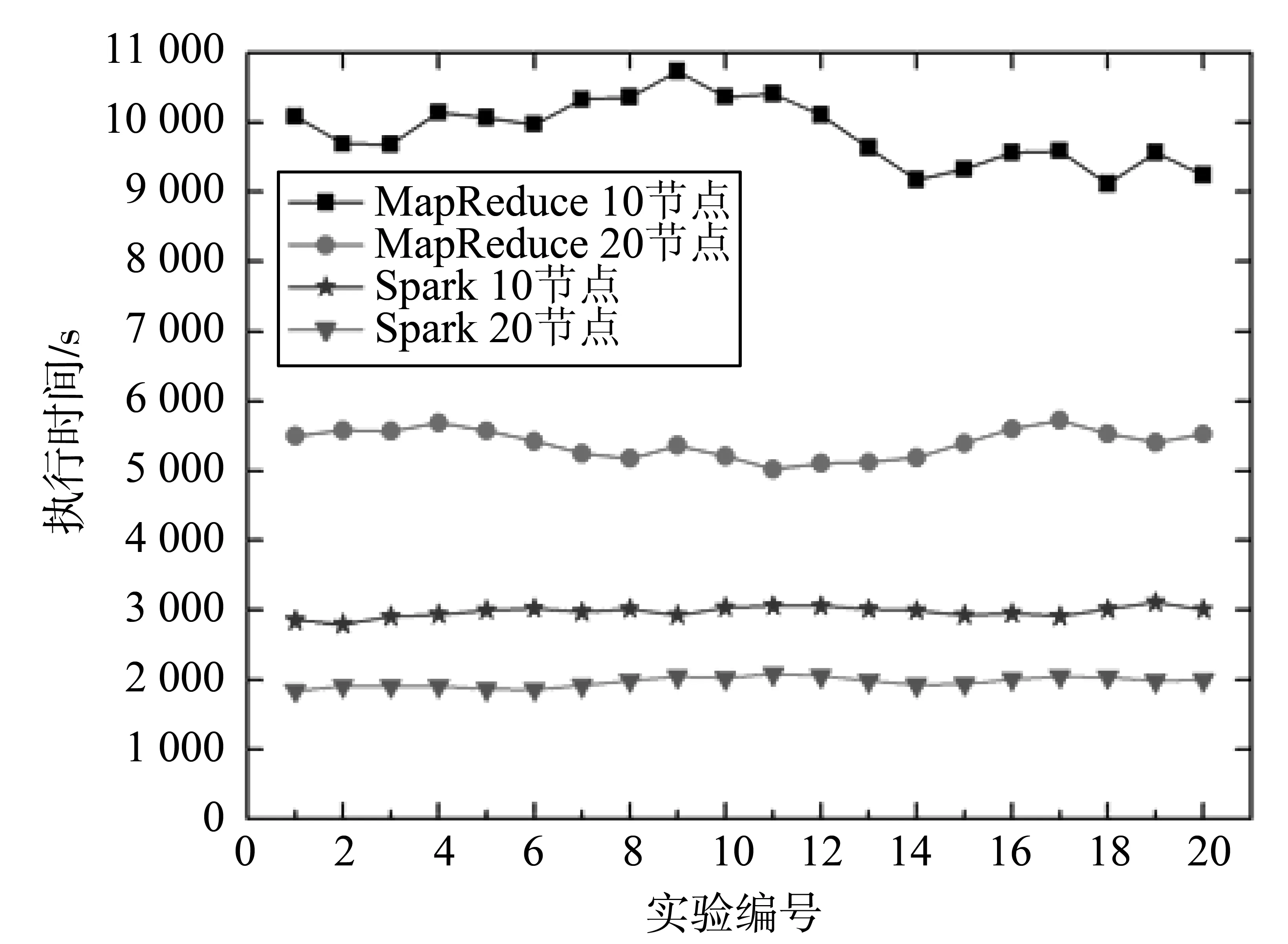
图4 算法执行时间对比Fig.4 The algorithm execution time comparison
本文将从算法执行效率、算法移植后的平台优化以及算法能耗优化3个方面展开。
4.2 算法完成效率对比
实验一共分为4组,分别为MapReduce集群10节点、MapReduce集群20节点、Spark集群10节点及Spark集群20节点。为了减小实验误差,将每组实验至少成功执行20次。不同实验组的任务执行时间如图4所示。
如图4所示为算法执行时间对比,分别将20组实验执行时间求平均,得到MapReduce集群中10节点与20节点执行时间分别为9 854、5 400 s;Spark集群中10节点与20节点执行时间分别为2 976、1 970 s。可以看出,集群节点数量的增加,分别提高MapReduce与Spark集群82.5%、51.1%的算法执行时间效率提升。MapReduce与Spark算法效率比较,集群规模为10时,Spark较MapReduce效率提升了近231.1%;当集群规模为20时,效率提升了近174.1%。由此可得出结论,借助于Spark的迭代计算和内存计算优势,将协同过滤算法从MapReduce移植到Spark环境,能够大幅度提升算法的执行效率。另外,我们在实验过程中发现,Spark集群中的算法执行失败率小于MapReduce集群,这与集群的稳定性及任务执行时间密切相关。
算法资源利用方面,由于通过Spark中的DAG编程模型,将原始的7个MapReduce作业简化为一个Spark DAG作业。Spark将DAG作业分解为了8个Stage,每个Stage包含多个可并行执行的Tasks。而Stage之间的数据通过Shuffle传递,而在算法的数据输入与输出方面,Spark也只需要读取和写入HDFS一次,从而减少了6次HDFS数据的读写操作。在MapReduce集群中,任务运行时伴随大量的磁盘及网络I/O操作;而Spark中磁盘及网络I/O操作相比MapReduce得到了较好的控制,密集的I/O操作都发生在算法执行的前后。总体上,Spark中的DAG模型减少了65%以上的HDFS重复读写I/O操作,提高资源利用效率的同时缩短了算法的执行时间。
4.3 Spark平台优化效率
实验过程中发现针对平台做优化可提高算法的执行效率(算法在不同环境下的计算时间),常用的平台优化方法如表3所示。
如图5所示为平台优化前后的任务完成时间对比,其中对比实验一共有2组,节点规模分别为10与20,每组实验分别运行优化前后的算法10次进行对比实验。
图5及图6分别表示在不同集群规模环境下,平台优化前后的算法执行时间对比。表5对不同集群规模的优化效率进行了对比,其中当集群规模为10节点时,优化平均值为10.62%;规模为20节点时,平均优化率为11.57%。随着集群规模的增加,优化后的集群执行效率越高。

表5 平台优化率对比
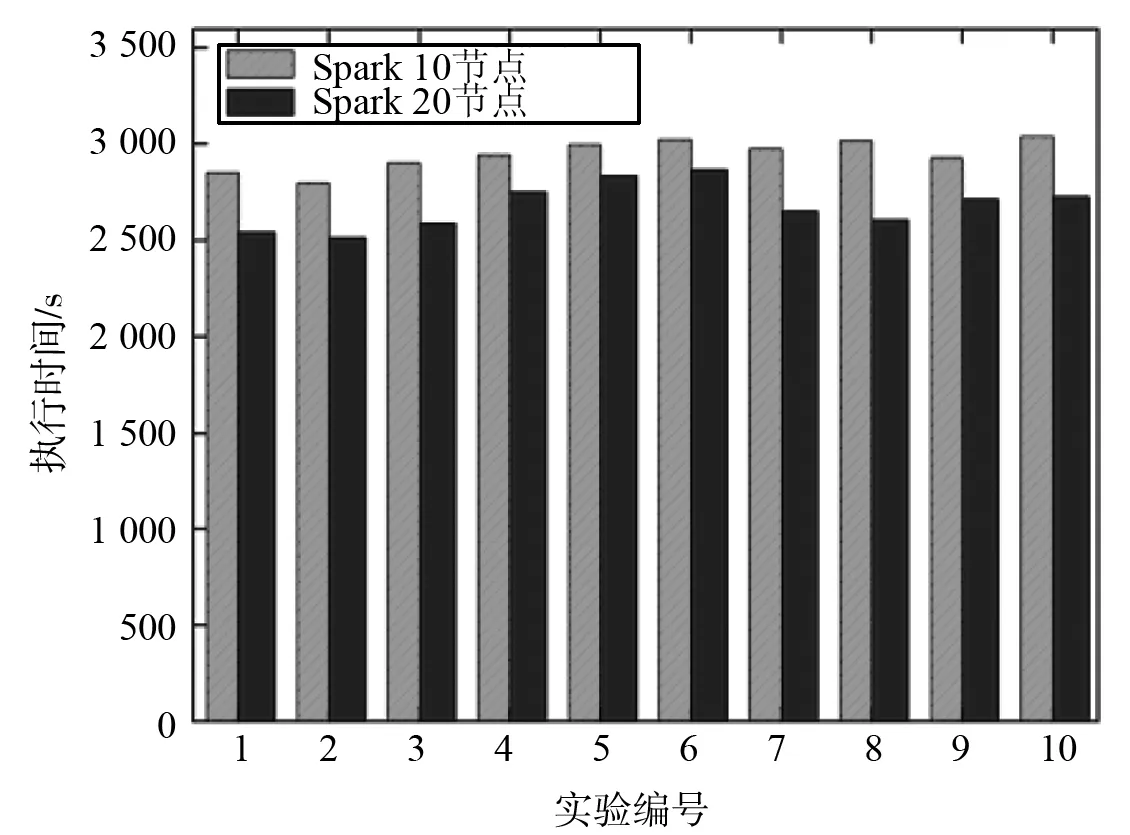
图5 优化前后的任务完成时间对比(10节点集群规模)Fig.5 The task completion time comparison (10 node clusters)
4.4 算法能耗优化
无论是MapReduce还是Spark平台,任务执行过程中消耗的资源包括CPU、磁盘、内存、网络等,而任务的执行能耗则是由这些资源所产生的能耗累加而成。其中,CPU的能耗模型受到处理器的活动状态、指令执行情况、高速cache使用情况、当前执行频率及制造工艺等因素的影响。设Pcpu表示CPU利用率为ucpu时的功率,根据Kansal等在文献[35]中提出的能耗模型,Pcpu与ucpu关系可表示如下:
(4)
其中,acup与λcpu为CPU能耗模型的常数,不同的CPU之间存在着差异,其值可通过大量的训练获得。
已有大量工作针对内存的能耗模型进行了研究,发现影响内存能耗的主要因素是内存读写数据的吞吐量[23]。记录内存最后一层Cache(LastLevelCache)的缺失次数,是一种轻量级的内存吞吐量评估方法。根据吞吐量指标,设Emem(T)表示内存在任务执行的T时间区间内的能耗,N表示最后一层Cache缺失次数,内存模型表达如下[35]:
(5)
其中,amem与λmem为内存能耗模型的常数。
磁盘能耗与读写数据量密切相关,设Edisk(T)表示一条SQL执行过程中T时间区间内磁盘的能耗,r与w分别表示在T时间区间内磁盘的读写数据量,磁盘能耗模型可表达如下[36-37]:
(6)
其中,ar与aw分别表示磁盘读写参数,λdisk表示磁盘的静态能耗,3个参数的值可通过大量的能耗数据分析与训练获得。
与磁盘能耗模型类似,网卡的能耗与发送、接收到的数据量成正比。设Enet(T)表示网卡在T时间区间内(一条SQL的执行时间)的能耗,s与v分别表示在T时间区间内网卡发送与接收到的数据量,网卡能耗模型可表达如下:
(7)
其中,as与av分别表示网卡在发送、接收数据时的能耗参数,λnet为网卡的静态能耗参数。
设任意任务执行成功后的能耗为E,由于任务执行过程中主要消耗了CPU、磁盘、内存及网络资源,所以在任务执行完毕的时间周期T=[ts,te]内,其能耗可由下式得到:
(8)
通过(8)式可知,可通过减小同一任务的执行时间及优化任务执行过程中的资源使用情况两方面达到优化任务能耗利用率的目的。本文中通过电力监测仪动态的收集相似度计算算法执行过程中的能耗数据,从而得到算法优化前与优化后的能耗效率(不同环境完成相同任务所需能耗的比值)对比。如图7所示为6组实验在3种(Hadoop平台下、Spark平台下及优化后的Spark平台下)不同的情况下的能耗对比。
如图7所示,结合公式(8)的分析,虽然Hadoop平台上的平均功耗在101~105W之间,相比Spark平台的平均功耗121~125W要小不少,但是由于Spark平台上的执行时间比Hadoop时间大大缩短。所以,Spark平台的算法能耗效率比Hadoop有所提高,并且由于系统的优化,能耗效率进一步的提升。当集群节点数为10时,Spark平台相比MapRedcue能耗效率提高63.92%;当集群节点数为20时,Spark平台相比MapRedcue能耗效率提高56.45%。在执行相同规模的任务时(5亿数据量),执行平台相同时,MapReduce平台节点规模为20时相对规模为10时能耗值有所提高,导致能耗效率下降10.45%;Spark平台与MapReduce现象一致,并且能耗效率下降了33.03%。这表明执行相同任务时,集群规模越大,能耗效率越低,这是因为当集群规模增大时,任务之间的数据传输增加,任务之间的关联变得复杂,任务协调成本增加,从而导致作业执行能耗增加。
值得注意的是,Hadoop平台的平均功耗相比Spark平台的平均功耗要小不少。这是由于平台对资源的使用方式造成的,因为Spark使用RDD直接将数据cache到内存中,资源利用率(如:CPU、内存等)比Hadoop高;而Hadoop在执行任务过程中不少节点之间存在任务等待的情况,资源利用效率不如Spark。
5 结论及展望
虽然MapReduce逐渐成为工业与学术界事实上的海量数据并行处理标准,但MapReduce的优势在于处理批处理作业。对于具有复杂业务处理逻辑的互联网数据挖掘类作业,MapReduce计算效率并不理想。并且,由于在进行架构设计时就没有考虑到系统的能耗问题,导致已有的能耗优化工作效果并不显著。由于在前期研究中发现MapReduce框架下的协同过滤算法执行效率较为低下。本文首先对MapReduce框架下的协同过滤算法的实现步骤进行分解,在此基础上对算法的效率缺陷进行了分析;进而在对MapReduce效率分析的基础上将算法从MapReduce移植到Spark平台,并对实现流程、移植方法及平台优化进行了研究;最后,通过实现证明了算法移植后在任务执行时间及能耗利用率方面的有效性。下一步工作主要是在本文的基础上,将MapReduce平台中,基于内容、基于规则及基于网络结构等更多的协同过滤算法移植到Spark平台。
[1] 孟小峰,慈祥. 大数据管理:概念、技术与挑战[J]. 计算机研究与发展, 2013,50(1):146-149.MENGXF,CIX.Bigdatamanagement:concepts,techniquesandchallenges[J].JournalofComputerResearchandDevelopment, 2013: 50(1): 146-149.
[2]GANTZJ,CHUTEC,MANFREDIZA,etal.Thediverseandexplodingdigitaluniverse:Anupdatedforecastofworldwideinformationgrowththrough2011 [EB/OL]. [2015-2-25].http:∥wwww.ifap.ru/library/book268.pdf.
[3]TIMESNY.Power,pollutionandtheinternet[EB/OL]. [2016-5-20].http:∥www.nytimes.com/2012/09/23/technology/data-ceneters-waste-vast-amounts-of-energy-belying-industry-image.html.
[4]BARROSOLA,HLZLEU.Thedatacenterasacomputer:Anintroductiontothedesignofwarehouse-scalemachines[R].Morgan:SynthesisLecturesonComputerArchitecture,Morgan&ClaypoolPublishers, 2009.
[5] 黄山, 王波涛, 王国仁,等.MapReduce优化技术综述[J]. 计算机科学与探索, 2013, 7(10): 865-885.HUANGS,WANGBT,WANGGR,etal.AsurveyonMapReduceoptimizationtechnologies[J].JournalofFrontiersofComputerScienceandTechnology, 2013, 7(10): 865-885.
[6] 刘义, 景宁, 陈荦,等.MapReduce框架下基于R-树的k-近邻连接算法[J]. 软件学报, 2013, 24(8): 1836-1851.LIUY,JINGN,CHENL,etal.Algorithmforprocessingk-nearestjoinbasedonR-treeinMapReduce[J].JournalofSoftware, 2013, 24(8):1836-1851.
[7]CHENY,KEYSL,KATZRH.Towardsenergyeffcientmapreduce[R].Berkeley:EECSDepartment,UniversityofCalifornia, 2009-10-9.
[8]LEVERICHJ,KOZYRAKISC.Ontheenergy(in)efficiencyofhadoopclusters[J].ACMSIGOPSOperatingSystemsReview, 2010, 44 (1): 61-65.
[9]KAUSHIKRT,BHANDARKARM.GreenHDFS:Towardsanenergy-conserving,storage-efficient,hybridhadoopcomputecluster[C]∥Proceedingsofthe2010InternationalConferenceonPowerAwareComputingandSystems.Piscataway,NJ:IEEE, 2010: 1-9.
[10]KAUSHIKRT,BHANDARKARM,NAHRSTEDTK.EvaluationandanalysisofGreenHDFS:Aself-adaptive,energyconservingvariantofthehadoopdistributedfilesystem[C]∥Proceedingsofthe2ndIEEEInternationalConferenceonCloudComputingTechnologyandScience.Piscataway,NJ:IEEE, 2010: 274-287.
[11] 彭利民. 高效节能的虚拟网络重构算法[J]. 中山大学学报(自然科学版), 2015, 54(5): 5-10.PENGLM.Anenergyefficientvirtualnetworkreconfigurationalgorithm[J].ActaScientiarumNaturaliumUniversitatisSunyatseni, 2015, 54(5): 5-10.
[12]WIRTZT,GER.ImprovingMapReduceenergyefficiencyforcomputationintensiveworkloads[C]∥GreenComputingConferenceandWorkshops(IGCC), 2011International.IEEE, 2011: 1-8.
[13]GOIRI,LEK,NGUYENTD,etal.GreenHadoop:leveraginggreenenergyindata-processingframeworks[C]∥Proceedingsofthe7thACMEuropeanConferenceonComputerSystems.ACM, 2012: 57-70.
[14]CHENY,GANAPATHIA,KATZRH.Tocompressornottocompress-computevs.IOtradeoffsformapreduceenergyefficiency[C]∥ACMSIGCOMMWorkshoponGreenNetworking,NewDelhi, 2010: 23-28.
[15] 宋杰,李甜甜,朱志良,等.云数据管理系统能耗基准测试与分析[J].计算机学报, 2013,36(7):1485-1499.SONGJ,LITT,ZHUZL,etal.Benchmarkingandanalyzingtheenergyconsumptionofclouddatamanagementsystem[J].ChineseJournalofComputers, 2013, 36(7): 1485-1499.
[16] 廖彬,于炯,孙华,等. 基于存储结构重配置的分布式存储系统节能算法[J].计算机研究与发展, 2013, 50(1): 3-18.LIAOB,YUJ,SUNH,etal.Energy-efficientalgorithmsfordistributedstoragesystembasedondatastoragestructurereconfiguration[J].JournalofComputerResearchandDevelopment, 2013: 50(1): 3-18.
[17] 廖彬,于炯,张陶,等. 基于分布式文件系统HDFS的节能算法[J]. 计算机学报, 2013,36(5):1047-1064.LIAOB,YUJ,ZHANGT,etal.Energy-efficientalgorithmsfordistributedfilesystemHDFS[J].ChineseJournalofComputers, 2013, 36(5): 1047-1064.
[18]LINJC,LEUFY,CHENYP.ImpactofMapReducepoliciesonjobcompletionreliabilityandjobenergyconsumption[J].IEEETransactionsonParallel&DistributedSystems, 2015, 26(5): 1364-1378.
[19]LIAOB,YUJZHANGT,etal.Energy-efficientalgorithmsfordistributedstoragesystembasedonblockstoragestructurereconfiguration[J].JournalofNetworkandComputerApplications, 2015, 48(2): 71-86.
[20] 杨兴耀, 于炯, 吐尔根·依布拉音, 等. 融合奇异性和扩散过程的协同过滤模型[J]. 软件学报, 2013,24(8):1868-1884.YANGXY,YUJ,IBRAHIMT,etal.Collaborativefilteringmodelfusingsingularityanddiffusionprocess[J].JournalofSoftware, 2013, 24(8): 1868-1884.
[21]GHAUTHKI,ABDULLAHNA.Learningmaterialsrecommendationusinggoodlearners’ratingsandcontent-basedfiltering[J].EducationalTechnologyResearchandDevelopment, 2010, 58(6):711-727.
[22]UDDINMN,SHRESTHAJ,JOGS.Enhancedcontent-basedfilteringusingdiversecollaborativepredictionformovierecommendation[C]∥IntelligentInformationandDatabaseSystems, 2009.ACIIDS2009.FirstAsianConferenceon.IEEE, 2009: 132-137.
[23]NGUYENAT,DENOSN,BERRUTC.Improvingnewuserrecommendationswithrule-basedinductiononcolduserdata[C]∥ACMConferenceonRecommenderSystems.ACM, 2007: 121-128.
[24]CHUNJ,OHJY,KWONS,etal.Simulatingtheeffectivenessofusingassociationrulesforrecommendationsystems[C]∥AsianSimulationConferenceonSystemsModelingandSimulation:TheoryandApplications.Springer-Verlag, 2004: 306-314.
[25]QIULY,BENBASATI.Astudyofdemographicembodimentsofproductrecommendationagentsinelectroniccommerce[J].InternationalJournalofHuman-ComputerStudies, 2010, 68(10): 669-688.
[26]CHENT,HEL.CollaborativeFilteringBasedonDemographicAttributeVector[C]∥InternationalConferenceonFutureComputerandCommunication.IEEE, 2009: 225-229.
[27]JIACX,LIURR,SUND,etal.Anewweightingmethodinnetwork-basedrecommendation[J].PhysicaAStatisticalMechanics&ItsApplications, 2008, 387(23): 5887-5891.
[28]ZHOUT,RENJ,MEDOM,etal.Bipartitenetworkprojectionandpersonalrecommendation[J].PhysicalReviewEStatisticalNonlinear&SoftMatterPhysics, 2007, 76(2): 046115.
[29]YAMASHITAA,KAWAMURAH,SUZUKIK.Adaptivefusionmethodforuser-basedanditem-basedcollaborativefiltering[J].AdvancesinComplexSystems, 2011, 14(2): 133-149.
[30]LIUZB,QUWY,LIHT,etal.AhybridcollaborativefilteringrecommendationmechanismforP2Pnetworks[J].FutureGenerationComputerSystems, 2010, 26(8): 1409-1417.
[31]BARRAGANS-MARTINEZAB,COSTA-MONTENEGROE,BURGUILLOJC,etal.Ahybridcontent-basedanditem-basedcollaborativefilteringapproachtorecommendTVprogramsenhancedwithsingularvaluedecomposition[J].InformationSciences, 2010,180(22): 4290-4311.
[32]PHAMMC,CAOYW,KLAMMAR,etal.Aclusteringapproachforcollaborativefilteringrecommendationusingsocialnetworkanalysis[J].JournalofUniversalComputerScience, 2011, 17(4):583-604.
[33]LIUFK,LEEHJ.Useofsocialnetworkinformationtoenhancecollaborativefilteringperformance[J].ExpertSystemswithApplications, 2010, 37(7): 4772-4778.
[34]KAGIEM,vanderLOOSM,VANWEZELM.Includingitemcharacteristicsintheprobabilisticlatentsemanticanalysismodelforcollaborativefiltering[J].AICommunications, 2009, 22(4): 249-265.
[35]KANSALA,ZHAOF,LIUJ,etal.Vitrualmachinepowermeteringandprovisioning[C]∥Proceedingsofthe1stACMSymposiumonCloudComputing.Indianaposlis,USA, 2010:39-50.
[36]BAOY,CHENM,RUANY,etal.HMTT:Aplatformindependentfull-systemmemorytracemonitoringsystem[J].ACMSIGMETRICSPerformanceEvaluationReview, 2008, 36(1): 229-240.
[37] 廖彬, 张陶, 于炯, 等. 适应节能与异构环境的MapReduce数据布局策略[J]. 中山大学学报(自然科学版), 2015, 54(6): 55-66.LIAOB,ZHANGT,YUJ,etal.Anenergy-efficientandheterogeneousenvironmentadaptivedatalayoutstrategyforMapReduce[J].ActaScientiarumNaturaliumUniversitatisSunyatseni, 2015, 54(6): 55-66.
Optimization of collaborative filtering algorithm based on DAG Spark scheduling
LIAOBin1,ZHANGTao2,3,YUJiong2,GUOBinglei2,ZHANGXuguang1,LIUYan4
(1.College of Statistics and Information,Xinjiang University of Finance and Economics, Urumqi 830012,China; 2. School of Information Science and Engineering, Xinjiang University, Urumqi 830008, China; 3. Department of Medical Engineering and Technology,Xinjiang Medical University, Urumqi 830011,China; 4. School of Software, Tsinghua University, Beijing 100084, China)
The scale effect of big data has brought great challenges to data storage, management and analysis. And the high efficiency and low cost big data processing technology has become a hotspot research in academia and industry. In order to improve the efficiency of collaborative filtering algorithms, the implementation of the algorithm under the MapReduce architecture is decomposed in order to analysis the defects of the algorithm. For the Spark suitable for the iterative and interactive tasks, this paper presents the methods to improve the execution efficiency from the MapReduce platform to the Spark platform. The implementation flow of the algorithm in Spark is designed, and efficiency is improved by parameter adjustment and memory optimization. Experimental results show that: based on spark DAG scheduling, the algorithm can reduce more than 65% HDFS I/O operations and enforce the efficiency and energy efficiency were increased by nearly 200% and 50%.
collaborative filtering; MapReduce; Spark; algorithm optimization; energy consumption optimization
10.13471/j.cnki.acta.snus.2017.03.008
2016-04-26 基金项目:国家自然科学基金(61562078,61262088);新疆维吾尔自治区自然科学基金(2016D01B014);新疆财经大学博士启动基金(2015BS007)
廖彬(1986年生),男;研究方向:绿色计算、数据挖掘及大数据计算模型等;E-mail: liaobin665@163.com
TP393.09
A
0529-6579(2017)03-0046-11
猜你喜欢
昆钢科技(2022年2期)2022-07-08
当代水产(2021年10期)2022-01-12
建材发展导向(2021年23期)2021-03-08
军事运筹与系统工程(2019年4期)2019-09-11
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
信息化建设(2019年2期)2019-03-27
华人时刊(2018年15期)2018-11-10
电子制作(2018年11期)2018-08-04
知识就是力量(2017年2期)2017-01-21
