
Semi-supervised dictionary learning with label propagation for image classif i cation
2017-06-19 19:20LinChenMengYang
Computational Visual Media 2017年1期
Lin Chen,Meng Yang,2,3()
Semi-supervised dictionary learning with label propagation for image classif i cation
Lin Chen1,Meng Yang1,2,3()
Sparse coding and supervised dictionary learning have rapidly developed in recent years, and achieved impressive performance in image classif i cation.However,there is usually a limited number of labeled training samples and a huge amount of unlabeled data in practical image classif i cation, which degrades the discrimination of the learned dictionary.How to ef f ectively utilize unlabeled training data and explore the information hidden in unlabeled data has drawn much attention of researchers.In this paper,we propose a novel discriminative semisupervised dictionary learning method using label propagation(SSD-LP).Specif i cally,we utilize a label propagation algorithm based on class-specif i c reconstruction errors to accurately estimate the identities of unlabeled training samples,and develop an algorithm for optimizing the discriminative dictionary and discriminative coding vectors simultaneously. Extensive experiments on face recognition,digit recognition,and texture classif i cation demonstrate the ef f ectiveness of the proposed method.
semi-supervised learning;dictionary learning;label propagation;image classif i cation
1 Introduction
In recent years,sparse representation has gainedmuch interest in the computer vision f i eld[1,2]and has been widely applied to image restoration[3,4], image compression[5,6],and image classif i cation[7–11].The success of sparse representation is partially because natural images can be generally and sparsely coded by structural primitives(e.g.,edges and line segments)and the images or signals can be represented sparsely by dictionary atoms from the same class.
In the task of image classif i cation based on sparse representation,signals need to be encoded over a dictionary(i.e.,a set of representation bases)with some sparsity constraint.The dictionary,which encodes the testing sample,can directly consist of the training samples themselves.For example, Wright et al.[12]f i rstly constructed a dictionary by using the training samples of all classes,then coded the test sample with this dictionary,and f i nally classif i ed the test sample into the class with the minimal class-specif i c representation residual. So-called sparse representation based classif i cation (SRC)[12]has achieved impressive performance in face recognition.However,the number of dictionary atoms used in SRC can be quite high,resulting in a large computational burden in calculating the coding vector.What is more,the discriminative information hidden in training samples cannot be exploited fully. To overcome the above problems,the problem of how to learn an ef f ective dictionary from training data has been widely studied.
Dictionary learning methods can be divided into three main categories:unsupervised[13], supervised[14–17],and semi-supervised[11,18–23].K-SVD[13]is a representative unsupervised dictionary learning model,which is widely applied to image restoration tasks.Since no label information is exploited in the phase of dictionary learning,unsupervised dictionary learning methods are useful for data reconstruction,but not advantageous for classif i cation tasks.
Based on the relationship between dictionary atoms and class labels,prevailing supervised dictionary learning methods can be divided into three categories:shared,class-specif i c,and hybrid. In the f i rst case,discrimination provided by shared dictionary learning is typically explored by jointly learning a dictionary and a classif i er over the coding coeffi cients[9,10].Using the learned shared dictionary,the generated coding coeffi cients,which are expected to be discriminative, are used for classif i cation.In class-specif i c dictionary learning,each dictionary atom is predef i ned to correspond to a unique class label so that the class-specif i c reconstruction error can be used for classif i cation[14,24].However,the learned dictionary can be very large when there are many classes.In order to take advantage of the powerful class-specif i c representation ability,and to reduce the coherence between dif f erent sub-dictionaries,the hybrid dictionary learning[15,25,26]combines shared dictionary atoms and class-specif i c dictionary atoms.
Suffi cient labeled training data and high quality training images are necessary for good performance in supervised dictionary learning algorithms. However,it is expensive and diffi cult to obtain the labeled training data due to the vast human ef f ort involved.On the other hand,there are abundant unlabeled images that can be collected easily from public image datasets.Therefore,semi-supervised dictionary learning,which ef f ectively utilizes these unlabeled samples to enhance dictionary learning, has attracted extensive research.
In recent years,semi-supervised learning methods have been widely studied[27–31].One classical semi-supervised learning method is co-training[29] which utilizes multi-view features to retrain the classif i ers to obtain better performance.In cotraining,the multi-view features need to be conditionally independent so that one classif i er can conf i dently select unlabeled samples for the other classif i er.Another important semi-supervised learning method is the graph-based method[27].In classif i cation,graph-based semi-supervised learning methods can readily explore the class information in unlabeled training data via a small amount of labeled data.A representative method based on graphs is label propagation(LP),which has been widely used in image classif i cation and ranking.Label propagation algorithms[27,28,33–35]perform class estimation of unlabeled samples by propagating label information from labeled data to unlabeled data. This is done by constructing a weight matrix(or affi nity matrix)based on the distance between any two samples.The basic assumption of LP algorithms is that if the weight linking two samples is high,they are likely to belong to the same class.
Semi-supervised dictionary learning[11,18,19, 21–23,36]has gained considerable interest in the past several years.In semi-supervised dictionary learning,the issue of whether the unlabeled samples can be accurately estimated for use as labeled samples for training is very important.For instance, a shared dictionary and a classif i er may be jointly learned by estimating the class conf i dence of unlabeled samples[18].In Ref.[23],the unlabeled samples are utilized to learn a discriminative dictionary by preserving the geometrical structure of both the labeled and unlabeled data.However, the class-specif i c reconstruction error which carries strong discriminative ability cannot be utilized to estimate the identities of unlabeled samples in the shared dictionary.A semi-supervised class-specif i c dictionary has also been learned in Ref.[19]. However,its model is a little complex due to many regularizations.
By combining the label information of the labeled samples and reconstruction error of unlabeled samples over all classes,the identities of the unlabeled training samples can be estimated more accurately.In this paper,we propose a novel semi-supervised dictionary model with label propagation.In our proposed model,we design an improved label propagation algorithm to evaluate the probabilities of unlabeled data belonging to a specif i c class.Specif i cally,the proposed label propagation algorithm is based on the powerful class-specif i c representation provided by the reconstruction error of unlabeled samples for each sub-dictionary.Simultaneously,the label information of labeled data can be utilized better by this graph-based method via label propagation. We also well exploit the discrimination providedby the labeled training data in dictionary learning by minimizing the within-class variance.We have conducted several experiments on face recognition, digit recognition,and texture classif i cation,which show the advantage of our proposed SSD-LP approach.
Our main contributions are summarized as follows:
1.We propose a novel discriminative semi-supervised dictionary learning method which can ef f ectively utilize the discriminative information hidden in both unlabeled and labeled training data.
2.By using label propagation,we estimate a more accurate relationship between unlabeled training data and classes,and enhance exploration of the discrimination provided by the unlabeled training data.
3.The discrimination provided by the labeled training data by minimizing within-class variance is explored during semi-supervised dictionary learning.
4.Experimental results show that our method has a signif i cantly better discrimination ability using unlabeled training data in dictionary learning.
The rest of this paper is organized as follows. In Section 2,we brief l y introduce related work on semi-supervised dictionary learning.Our model is presented in Section 3,and Section 4 describes the optimization procedure.Section 5 presents experimental results and Section 6 concludes the paper with a brief summary and discussion.
2 Related work
Based on the predef i ned relationship between dictionary atoms and class labels,semi-supervised dictionary learning approaches can be divided into two main categories:discriminative classspecif i c dictionary learning and discriminative shared dictionary learning.
Motivated by Ref.[24],Shrivastava et al.[19] learnt a class-specif i c dictionary by using Fisher discriminant analysis on the coding vectors of the labeled data.However,its model is complex:the training data is represented by a combination of all class-specif i c dictionaries,and the coding coeffi cients are regularized by both intra-class and inter-class constraints.
Another approach to semi-supervised dictionary learning is to learn a shared dictionary.Pham and Venktesh[11]took into account the representation errors of both labeled data and unlabeled data.In addition,the classif i cation errors of labeled data were incorporated into a joint objective function.One major drawback of the above approach is that it may fall into a local minimum due to the dictionary construction and classif i er design.Wang et al.[18]utilized an artif i cially designed penalty function to assign weights to the unlabeled data, greatly suppressing the unlabeled data having low conf i dence.Zhang et al.[22]proposed an online semi-supervised dictionary learning framework which integrated the reconstruction error of both labeled and unlabeled data,label consistency, and the classif i cation error into an objective function.Babagholami-Mohamadabadi et al.[23] integrated dictionary learning and classif i er training into an objective function,and preserved the geometrical structure of both labeled and unlabeled data.Recently,Wang et al.[21]utilized the structural sparse relationships between both the labeled and unlabeled samples to learn a discriminative dictionary in which the unlabeled samples are automatically grouped into dif f erent labeled samples.Although a shared dictionary usually has a compact size,the discrimination provided by class-specif i c reconstruction residuals cannot be used.
3 Semi-supervised dictionary learning with label propagation(SSD-LP)
Although several semi-supervised dictionary learning approaches have been proposed,there are still some issues to be solved,such as how to build a discriminative dictionary by using unlabeled data,how to utilize the representation ability of a class-specif i c dictionary,and how to estimate the class probabilities of the unlabeled data.In this section,we propose a discriminative semi-supervised dictionary learning method using label propagation (SSD-LP)to address the issues mentioned above.
3.1 SSD-LP model
Let A=[A1,...,Ai,...,AC]be the labeled training data,where Aiis the i th-class training data and each column of Aiis a training sample,and B=[b1,...,bj,...,bN]is the unlabeled training data with unknown labels from 1 to C,where N isthe number of unlabeled training samples.Here,as in prevailing semi-supervised dictionary methods[11, 18,19,21–23,36],we assume that the unlabeled training data belongs to some class of the training set.
In our proposed model,the dictionary to be learnt is D=[D1,...,Di,...,DC],where Diis the class-specif i c sub-dictionary associated with class i;it is required to well represent the i th-class data but to have a poor representation ability for all other classes.In general,we make each column of Dia unit vector.We can write Di,the representation coeffi cient matrix of Aiover D as Xi=whereis the coding coeffi cient matrix of Aion the sub-dictionary Dj. Further,yijis the coding coeffi cient vector of the unlabeled sample bjon the class-specif i c dictionary D i.
Apart from requiring the coding coeffi cients to be sparse,for the labeled training data we also minimize the within-class scatter of coding coeffi cients,−to make the training samples from the same class have similar coding coeffi cients,where Miis the mean coeffi cient matrix with the same size asand takes the mean column vector ofas its column vectors.
We def i ne a latent variable,Pi,j,which represents the probability that the j th unlabeled training sample belongs to the i th class.Pi,jsatisf i es 0and P.If the labeled training sample k belongs to class j,then Pj,k=1 and Pi,k= 0 for
Our proposed SSD-LP method can now be formulated as

For the labeled training data,a discriminative representation term,i.e.,and a discriminative coeffi cient term,i.e.,are introduced.Since Diis associated with the i th-class,it is expected that Aishould be well represented by Dibut not by Dj,.This implies thatshould have some signif i cant coeffi cients such thatis small,whileshould haveis eliminated as shown in Eq.(1). n e a rly zero coeffi cients.Thus the term
For the unlabeled training data,the probability that the sample belongs to each class is required.For instance,Pi,j=1 indicates that the j th unlabeled training sample comes from the i th-class,and the class-specif i c dictionary Dishould well represent the j th unlabeled training sample in thatis small.
Due to the good performance of graph-based label propagation on semi-supervised classif i cation tasks, we utilize it to select the unlabeled sample with high conf i dence and assign the unlabeled sample a high weight,as explained in detail in Section 4.1.
3.2 Classif i cation scheme
Once the dictionary D=[D1,...,Di,...,DC]has been learned,a testing sample can be classif i ed by coding it over the learned dictionary.Although the learned dictionary is class-specif i c,the testing sample is not always coded on each sub-dictionary corresponding to each class.As the discussion in Ref.[24],there are two methods of coding the testing sample.
When the number of training samples in each class is relatively small,the sample sub-space of class i cannot be supported by the learned sub-dictionary Di.Thus the testing samples btare represented on the collaborative combination of all class-specif i c dictionaries.In this case,the sparse coding vector of the testing sample should be found by solving:


When the number of training samples in each class is relatively large,the sub-dictionary Di,which has enough discrimination,can support the sample subspace of class i.Thus,we can directly code testing sample bton each sub-dictionary:
The class of testing sample btis then predicted by

4 Optimization of SSD-LP
The SSD-LP objective function is not convex in the joint variables of{D,X,P,y},but it is convex in each variable when the others are fi xed. Optimization of Eq.(1)can be divided into three sub-problems:updating P by fi xing D,X,y; updating X,y by fi xing P,D;and updating D by fi xing P,X.
4.1 Updating P by improved label propagation
Unlike the approach used in Ref.[28]to construct the weight matrix,our weight matrix is constructed from the reconstruction errors of the unlabeled samples over all classes rather than the distances between any two samples.Intuitively,since sub-dictionary Diis good at representng the i th-class but is poor at representing other classes,any pair of samples is likely to belong to the same class if they achieve minimum reconstruction error in the same class.
Specif i cally,to compute the weight value wij(if wijis large,then sample biand sample bjare likely to have the same class),we f i rst compute the reconstruction errors of both training samples biand bjover all classes.This gives ei=[ei1;...;eik;...eic]and ej=[ej1;...;ejk;...ejc] where eik=is the reconstruction error value of sample bion the class k andis the coeffi cient vector for class k.
After obtaining eiand ej,we compute the distancebetween them:

Finally,the weight linking samples biand bjis

where σ is a constant.After f i nding all weight values for every pair of samples,we can get the transition matrix T,which can be def i ned by normalizing the weight matrix using:

Let n=nl+nuwhere nl,nuare the total numbers of labeled and unlabeled training samples respectively.For the multi-class problem,the probability matrix is P=[Pl;Pu]where C is the number of classes,Plis the probability matrix for labeled samples,and Puis the probability matrix for unlabeled samples.We set Pl(i,k)=1 if sample biis a labeled sample with class k,and 0 otherwise.We initialize the probability matrix as P0=i.e.,the probability for the unlabeled training samples is set to zero.The improved label propagation algorithm for updating P is presented in Algorithm 1.Its convergence can be seen by refering to Ref.[27].Pt+1denotes the next iteration of Pt.Please note that the step 3.b is crucial as it ensures the label information of the labeled samples is preserved.
Compared with using a weight matrix based on the distances of any two original samples,there are two main advantages in our method.On one hand,the original method of constructing the weight matrix is a kind of single-track feedback mechanism in which the update of the probability matrix P can af f ect the dictionary update,but the update of the latter cannot af f ect the former because the distances between the original samples do not change.On the other hand,a weight matrix based on reconstruction errors over all classes more realistically ref l ects the similarity between two samples,which is helpful in estimating the class labels of unlabeled data.
4.2 Updating X and y
By f i xing the estimated class probabilities of the unlabeled training data(i.e.,P),the discriminative dictionary(i.e.,D)and coding coeffi cients(i.e.,X and y)can now be updated.
When the dictionary D is f i xed,the coding coeffi cients of the labeled training data can be easily updated.The objective function in Eq.(1)now reduces to


Algorithm 1:Improved label propagation based on reconstruction error
As discussed in Section 3.2,when the number of training samples in each class is relatively small,updating the coding coeffi cients of the unlabeled training data using a collaborative representation can achieve better classif i cation performance.Conversely,we choose a local representation when there are suffi cient training samples of each class.For the unlabeled training data,two coding strategies,i.e.,collaborative representation and local representation,are used. In the collaborative representation,the coding coeffi cient is solved via

where D=[D1,...,Di,...,DC]and yj=[;...;;...;];is the coding vector of the unlabeled sample bjfor the sub-dictionary Di.Here the dif f erent class-specif i c dictionaries Diwill compete with each other to represent bj.In order to ensure fair competition between dif f erent class-specif i c dictionaries,the encoding phase of collaborative representation ignores P.
In the local representation,the SSD-LP model associated with yichanges to

which is a standard sparse coding problem.
4.3 Updating D
After updating P,further unlabeled training samples are selected to train our model.If we f i x the size of the learnt dictionary,the discrimination of our dictionary cannot improve.Thus,after updating the probability matrix P,we should increase the size of each sub-dictionary to explore the discriminative information hidden in the unlabeled samples(i.e., an additional dictionary atom Eimust be initialized and added to sub-dictionary Di).
Since the unlabeled samples provide more discrimination,Eiis initialized by using unlabeled data:

We update Eiclass by class:

Then we combine all terms in Eq.(13):

Since we require the coding coeffi cients to be sparse, we compute the extended dictionary by singularvalue decomposition(SVD):
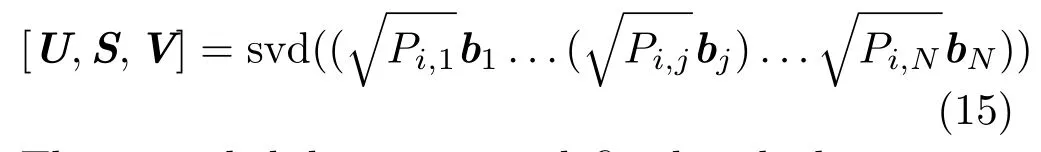
The extended dictionary is def i ned such that:

where n is the number of atoms in the extended dictionary.In all experiments shown in this paper, we set n=1,i.e.,each sub-dictionary adds a single dictionary atom after the update of probability matrix P.
The new sub-dictionary for class i is initialized using=[Di,Ei].By f i xing the coding coeffi cient X and probability matrix P,the problem in Eq.(1) is reduced to

Dictionary updating can be easily performed atom by atom by using Metaface[8].After updating the extended dictionary E,we need several iterations to update the dictionary and coeffi cients to guarantee the convergence of the discriminative dictionary.In our experiment,the number of additional iterations is set to 5.
The whole algorithm of the proposed semisupervised dictionary learning is summarized in Algorithm 2.The algorithm converges since the total objective function value in Eq.(1)decreases in each iteration.Figure 1 shows the total objective function value for the AR dataset[37].In all the experiments mentioned in this paper,our algorithm converges in less than 10 iterations.
5 Experiment results
We have performed experiments and corresponding analysis to verify the performance of our method for image classif i cation.We evaluate our approach on two face databases:the Extended YaleBdatabase[38]and the AR face database[37], two handwritten digit datasets:MNIST[39]and USPS[40],and an object category dataset:Texture-25[41].We compare our method with SRC[12],MSVM[17],FDDL[24],DKSVD[10],LCKSVD[16], SVGDL[42],S2D2[19],JDL[11],OSSDL[22], SSR-D[36],and the recently proposed USSDL[18] and SSP-DL[21]algorithms.The last six methods (S2D2,JDL,OSSDL,SSR-D,USSDL,and SSP-DL) are semi-supervised dictionary learning models;the others are supervised dictionary learning methods.

Algorithm 2:Semi-supervised dictionary learning with label propagation(SSD-LP)

Fig.1 Total objective function value on the AR database[37]versus number of iterations.
We repeated each experiment 10 times with dif f erent random splits of the datasets and report the average classif i cation accuracy together with standard deviation;the best classif i cation results are in boldface.For all approaches,we report their best results obtained after tuning their parameters.
5.1 Parameter selection and comparison with original label propagation
In our all experiments,the parameters of SSD-LP are f i xed to γ=0.001 and λ=0.01.The number of additional iterations is set to 5 in step 3.2 of Algorithm 2.In our experiment,since the subdictionary Diis initialized using the i th-class of labeled samples,the number of atoms Diis equal to the number of labeled samples for the i th-class(e.g., in the AR database,these are 2,3,5 as there are 2, 3,5 labeled samples respectively).After each update of the probability matrix P,each sub-dictionary adds an additional dictionary atom(the number of atoms of each sub-dictionary does not increase if the number of iterations exceeds the number of unlabeled training examples).
In order to show the ef f ectiveness of our algorithm, a test was conducted on the Extended YaleB dataset. As shown in Fig.2,we can see that for face recognition,recognition signif i cantly improves with iteration number.

Fig.2 Recognition rate versus iteration number for the Extended YaleB database with f i ve labeled training samples per class.
We also compare our proposed improved label propagation method with the original label propagation method(LP).As Fig.3 shows, SSD-LP has at least 10%improvement over the performance when the images are classif i ed directlyby the original label propagation method.With an increasing number of iterations,the recognition rate of our method grows,while the performance of the original label propagation algorithm is essentially unchanged.This is because the original label propagation is dependent on the distribution structure of the input data which does not change as the dictionary is updated.This is a kind of singletrack feedback mechanism between the original label propagation and dictionary learning as explained in Section 4.1.
We also compare the running time of our improved LP and the original LP using MATLAB 2015a on an Intel i7-3770 3.40 GHz machine with 16.0 GB RAM. The running time for the improved LP and original LP is 11.21 s and 7.54 s,respectively for two training examples per person(see Fig.3 up),and 11.73 s and 7.75 s,respectively for f i ve training examples per person(see Fig.3 bottom).We can see that the running time of the improved LP and original LP is comparable.

Fig.3 Recognition rate versus iteration number for the Extended YaleB database with two labeled training samples per person(up) and f i ve training samples per person(bottom).
5.2 Face recognition
In this section,we evaluate our method in a face recognition problem,for both AR and Extended YaleB databases,using the same experimental setting as Ref.[18].In both face recognition experiments,the image samples are reduced to 300 dimensions by PCA.
The AR database consists of over 4000 images of 126 individuals.In the experiment we chose a subset of 50 male and 50 female subjects.Focusing on illumination and expression changes,for each subject we chose 7 images from Session 1 for training,and 7 images from Session 2 for testing.We randomly selected{2,3,5}samples from each class in the training set as the labeled samples, and the remaining as the unlabeled samples. Five independent evaluations were conducted for the experiment with dif f erent numbers of labeled training samples.
As shown in Table 1,when the number of labeled samples was small(2 or 3),our algorithm performed better than all other methods,especially supervised dictionary learning models.This is because supervised dictionary methods cannot utilize the discriminative information hidden in the unlabeled training samples.The semi-supervised dictionary learning methods usually perform better than supervised dictionary learning methods:for instance,USSDL performs the second best.From Table 1,we can see that USSDL has very close results to SSD-LP,but we should note that USSDL needs more information in the dictionary learning task, including classif i er learning of the coding vectors.In addition,the optimization procedure of USSDL is more complex than that of SSD-LP.
We also evaluated our approach on the ExtendedYaleB database.The database consists of 2414 frontal face images of 38 individuals.Each individual has 64 images;we randomly selected 20 images as the training set and used the rest as the testing set. We randomly selected{2,5,10}samples from each class in the training set as the labeled samples,and used the remainder as the unlabeled samples.The classif i cation results are shown in Table 2.
It is clear that our proposed method provides better classif i cation performance than other dictionary learning methods.Especially when a small number of label samples is involved,the SSDLP performs singif i cantly better than supervised dictionary learning methods which are dependent on the number of the labeled samples.It also can be seen that SSD-LP improves by at least 1.5%over the other semi-supervised dictionary learning methods. When the number of labeled samples is small, the improvement is more obvious.That is mainly because our method has strong capability to utilize the unlabeled samples by accurately determining their labels and using them as labeled samples to train our discriminative dictionary.
5.3 Digit classif i cation
Next,we evaluated the performance of our method on both the MNIST and USPS datasets,with the same experimental setting as Ref.[21].The MNIST dataset has 10 classes.The training set has 60,000 handwritten digital images and the test set has about 10,000 images.The dimension of each digital image is 784.We randomly selected 200 samples from each class,using 20 images as the labeled samples,80 as the unlabeled samples,and the rest for testing.
The USPS dataset has 9298 digital images in 10 classes.We randomly selected 110 images from eachclass,using 20 as the labeled samples,40 as the unlabeled samples,and 50 as the testing samples. We used the whole image as the feature vector,and normalized the vector to have unit l2-norm.

Table 2 Recognition rate for various methods,for dif f erent number of labeled training samples,for the Extended YaleB database (Unit:%)
The results for the ten independent tests are combined in Table 3.It can be seen that our proposed SSD-LP method can ef f ectively utilize information from the unlabeled samples,achieving a classif i cation accuracy clearly higher than for the other dictionary methods.Using the additional unlabeled training samples,the size of the dictionary is enlarged adaptively to better utilize the discrimination provided by the unlabeled samples,which is why we can achieve better performance than other semisupervised dictionary methods mentioned in Table 3.
5.4 Object classif i cation
In this experiment we used the Texture-25 dataset which contains 25 texture categories,with 40 samples of each.We used low-level features[43,44],including PHOG[32],GIST[45],and LBP[46].Using the experimental setting in Ref.[18],PHOG was computed with a 2-layer pyramid in 8 directions, and GIST was computed on rescaled images of 256×256 pixels,in 4,8,and 8 orientations at 3 scales from coarse to f i ne.Uniform LBP were used. All the features are concatenated into a single 119-dimensional vector.In this experiment,13 images were randomly selected for testing and we randomly select{2,5,10,15}samples from each class in the training set as labeled samples.The average accuracies together with the standard deviation in f i ve independent tests are presented in Table 4.
It can be seen that SSD-LP improves by at least 3%over supervised dictionary learning when the number of labeled samples is 2 or 5.As the numberof labeled samples increases,the ef f ect is clearly enhanced,by about 10%.Table 4 shows that our method also gives better results than the other three semi-supervised dictionary methods.That is because as more samples are used for training,the estimates of the labels of the unlabeled training data become more accurate.The result fully demonstrates the classif i cation ef f ectiveness of label propagation based on reconstruction error.In addition,adaptively adding dictionary atoms makes our learnt dictionary more discriminative.JDL,which only uses the reconstruction error of both labeled and unlabeled data,does not work well.

Table 3 Recognition rate for various methods,for digit databases USPS and MNIST(Unit:%)

Table 4 Recognition rate for various methods,for dif f erent number of labeled training samples,for the Texture-25 database(Unit:%)
6 Conclusions
This paper has proposed a discriminative semi-supervised dictionary learning model.By integrating label propagation with that classspecif i c reconstruction error of each unlabeled training sample,we can more accurately estimate the class of unlabeled samples to train our model.The discriminative property of labeled training data is also well explored by using a discriminative representation term and minimizing within-class scatter of the coding coeffi cients. Several experiments,including applications to face recognition,digit recognition,and texture classif i cation have shown the advantage of our method over supervised and other semi-supervised dictionary learning approaches.In the future,we will explore more classif i cation questions,e.g.,the case in which the training samples may not belong to any known class.
Acknowledgements
This work was partially supported by the National Natural Science Foundation for Young Scientists of China(No.61402289),and the National Science Foundation of Guangdong Province(No. 2014A030313558).
[1]Elad,M.;Figueiredo,M.A.T.;Ma,Y.On the role of sparse and redundant representations in image processing.Proceedings of the IEEE Vol.98,No.6, 972–982,2010.
[2]Wright,J.;Ma,Y.;Mairal,J.;Sapiro,G.;Huang,T. S.;Yan,S.Sparse representation for computer vision and pattern recognition.Proceedings of the IEEE Vol. 98,No.6,1031–1044,2010.
[3]Chen,Y.-C.;Patel,V.M.;Phillips,P.J.;Chellappa, R.Dictionary-based face recognition from video. In:Computer Vision–ECCV 2012.Fitzgibbon,A.; Lazebnik,S.;Perona,P.;Sato,Y.;Schmid,C.Eds. Springer Berlin Heidelberg,766–779,2012.
[4]Mairal,J.;Elad,M.;Sapiro,G.Sparse representation for color image restoration.IEEE Transactions on Image Processing Vol.17,No.1,53–69,2008.
[5]Bryt,O.;Elad,M.Compression of facial images using the K-SVD algorithm.Journal of Visual Communication and Image Representation Vol.19, No.4,270–282,2008.
[6]Bryt,O.;Elad,M.Improving the k-svd facial image compression using a linear deblocking method.In: Proceedings of the IEEE 25th Convention of Electrical and Electronics Engineers in Israel,533–537,2008.
[7]Yang,J.;Yu,K.;Huang,T.Supervised translationinvariant sparse coding.In:Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition,3517–3524,2010.
[8]Yang,M.;Zhang,L.;Yang,J.;Zhang,D. Metaface learning for sparse representation based face recognition.In:Proceedings of the IEEE International Conference on Image Processing,1601–1604,2010.
[9]Mairal,J.;Ponce,J.;Sapiro,G.;Zisserman,A.;Bach, F.R.Supervised dictionary learning.In:Proceedings of the Advances in Neural Information Processing Systems,1033–1040,2009.
[10]Zhang,Q.;Li,B.Discriminative K-SVD for dictionary learning in face recognition.In:Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2691–2698,2010.
[11]Pham,D.-S.;Venkatesh,S.Joint learning and dictionary construction for pattern recognition.In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,1–8,2008.
[12]Wright,J.;Yang,A.Y.;Ganesh,A.;Sastry,S.S.;Ma, Y.Robust face recognition via sparse representation. IEEE Transactions on Pattern Analysis and Machine Intelligence Vol.31,No.2,210–227,2009.
[13]Aharon,M.;Elad,M.;Bruckstein,A.K-SVD:An algorithm for designing overcomplete dictionaries for sparse representation.IEEE Transactions on Signal Processing Vol.54,No.11,4311–4322,2006.
[14]Mairal,J.;Bach,F.;Ponce,J.;Sapiro,G.;Zisserman, A.Discriminative learned dictionaries for local image analysis.In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,1–8,2008.
[15]Yang,M.;Dai,D.;Shen,L.;Van Gool,L.Latent dictionary learning for sparse representation based classif i cation.In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,4138–4145,2014.
[16]Jiang,Z.;Lin,Z.;Davis,L.S.Learning a discriminative dictionary for sparse coding via label consistent K-SVD.In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,1697–1704,2011.
[17]Yang,J.;Yu,K.;Gong,Y.;Huang,T.Linear spatial pyramid matching using sparse coding for image classif i cation.In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,1794–1801,2009.
[18]Wang,X.;Guo,X.;Li,S.Z.Adaptively unif i ed semisupervised dictionary learning with active points.In: Proceedings of the IEEE International Conference on Computer Vision,1787–1795,2015.
[19]Shrivastava,A.;Pillai,J.K.;Patel,V.M.;Chellappa, R.Learning discriminative dictionaries with partially labeled data.In:Proceedings of the 19th IEEE International Conference on Image Processing,3113–3116,2012.
[20]Jian,M.;Jung,C.Semi-supervised bi-dictionary learning for image classif i cation with smooth representation-based label propagation.IEEE Transactions on Multimedia Vol.18,No.3,458–473, 2016.
[21]Wang,D.;Zhang,X.;Fan,M.;Ye,X.Semi-supervised dictionary learning via structural sparse preserving.In: Proceedings of the 30th AAAI Conference on Artif i cial Intelligence,2137–2144,2016.
[22]Zhang,G.;Jiang,Z.;Davis,L.S.Online semisupervised discriminative dictionary learning for sparse representation.In:Computer Vision–ACCV 2012.Lee,K.M.;Mu,K.;Matsushita,Y.;Rehg,J. M.;Hu,Z.Eds.Springer Berlin Heidelberg,259–273, 2012.
[23]Babagholami-Mohamadabadi,B.;Zarghami,A.; Zolfaghari,M.;Baghshah,M.S.PSSDL:Probabilistic semi-supervised dictionary learning.In:Machine Learning and Know ledge Discovery in Databases. Blockeel,H.;Kersting,K.;Nijssen,S.;ˇZelezn´y,F.Eds. Springer Berlin Heidelberg,192–207,2013.
[24]Yang,M.;Zhang,L.;Feng,X.;Zhang,D. Fisher discrimination dictionary learning for sparse representation.In:Proceedings of the IEEE International Conference on Computer Vision,543–550,2011.
[25]Zhou,N.;Shen,Y.;Peng,J.;Fan,J.Learning interrelated visual dictionary for object recognition.In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,3490–3497,2012.
[26]Deng,W.;Hu,J.;Guo,J.Extended SRC: Undersampled face recognition via intraclass variant dictionary.IEEE Transactions on Pattern Analysis and Machine Intelligence Vol.34,No.9,1864–1870, 2012.
[27]Zhu,X.;Laf f erty,J.;Rosenfeld,R.Semi-supervised learning with graphs.Carnegie Mellon University, Language Technologies Institute,School of Computer Science,2005.
[28]Wang,B.;Tu,Z.;Tsotsos,J.K.Dynamic label propagation for semi-supervised multi-class multilabel classif i cation.In:Proceedings of the IEEE International Conference on Computer Vision,425–432,2013.
[29]Blum,A.;Mitchell,T.Combining labeled and unlabeled data with co-training.In:Proceedings of the 11th Annual Conference on Computational Learning Theory,92–100,1998.
[30]Mallapragada,P.K.;Jin,R.;Jain,A.K.;Liu,Y. SemiBoost:Boosting for semi-supervised learning. IEEE Transactions on Pattern Analysis and Machine Intelligence Vol.31,No.11,2000–2014,2009.
[31]Gong,C.;Tao,D.;Maybank,S.J.;Liu,W.;Kang, G.;Yang,J.Multi-modal curriculum learning for semisupervised image classif i cation.IEEE Transactions on Image Processing Vol.25,No.7,3249–3260,2016.
[32]Bosch,A.;Zisserman,A.;Munoz,X.Image classif i cation using random forests and ferns. In:Proceedings of the IEEE 11th International Conference on Computer Vision,1–8,2007.
[33]Xiong,C.;Kim,T.-K.Set-based label propagation of face images.In:Proceedings of the 19th IEEE International Conference on Image Processing,1433–1436,2012.
[34]Cheng,H.;Liu,Z.;Yang,J.Sparsity induced similarity measure for label propagation.In: Proceedings of the IEEE 12th International Conference on Computer Vision,317–324,2009.
[35]Kang,F.;Jin,R.;Sukthankar,R.Correlated label propagation with application to multi-label learning.In:Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition,1719–1726,2006.
[36]Wang,H.;Nie,F.;Cai,W.;Huang,H.Semisupervised robust dictionary learning via effi cient lnorms minimization.In:Proceedings of the IEEE International Conference on Computer Vision,1145–1152,2013.
[37]Martinez,A.M.The AR face database.CVC Technical Report 24,1998.
[38]Lee,K.-C.;Ho,J.;Kriegman,D.J.Acquiring linear subspaces for face recognition under variable lighting. IEEE Transactions on Pattern Analysis and Machine Intelligence Vol.27,No.5,684–698,2005.
[39]LeCun,Y.;Bottou,L.;Bengio,Y.;Haf f ner, P.Gradient-based learning applied to document recognition.Proceedings of the IEEE Vol.86,No.11, 2278–2324,1998.
[40]Hull,J.J.A database for handwritten text recognition research.IEEE Transactions on Pattern Analysis and Machine Intelligence Vol.16,No.5,550–554,1994.
[41]Lazebnik,S.;Schmid,C.;Ponce,J.A sparse texture representation using local affi ne regions. IEEE Transactions on Pattern Analysis and Machine Intelligence Vol.27,No.8,1265–1278,2005.
[42]Cai,S.;Zuo,W.;Zhang,L.;Feng,X.;Wang, P.Support vector guided dictionary learning.In: Computer Vision–ECCV 2014.Fleet,D.;Pajdla,T.; Schiele,B.;Tuytelaars,T.Eds.Springer International Publishing,624–639,2014.
[43]Boix,X.;Roig,G.;Van Gool,L.Comment on“Ensemble projection for semi-supervised image classif i cation”.arXiv preprint arXiv:1408.6963,2014.
[44]Dai,D.;Van Gool,L.Ensemble projection for semisupervised image classif i cation.In:Proceedings of the IEEE International Conference on Computer Vision, 2072–2079,2013.
[45]Oliva,A.;Torralba,A.Modeling the shape of the scene:A holistic representation of the spatial envelope. International Journal of Computer Vision Vol.42,No. 3,145–175,2001.
[46]Ojala,T.;Pietikainen,M.;Maenpaa,T. Multiresolution gray-scale and rotation invariant texture classif i cation with local binary patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence Vol.24,No.7,971–987,2002.


Meng Yangis currently an associate professor in the School of Computer Science&Software Engineering, Shenzhen University,Shenzhen,China. He received his Ph.D.degree from Hong Kong Polytechnic University, Hong Kong,China,in 2012.Before joining Shenzhen University,he worked as a postdoctoral fellow in the Computer Vision Lab.of ETH Zurich.His research interests include sparse coding,dictionary learning,object recognition,and machine learning.He has published 10 AAAI/CVPR/ICCV/ICML/ECCV papers,and several IJCV,IEEE TNNLS,and TIP journal papers.
Open AccessThe articles published in this journal are distributed under the terms of the Creative Commons Attribution 4.0 International License(http:// creativecommons.org/licenses/by/4.0/),which permits unrestricted use,distribution,and reproduction in any medium,provided you give appropriate credit to the original author(s)and the source,provide a link to the Creative Commons license,and indicate if changes were made.
Other papers from this open access journal are available free of charge from http://www.springer.com/journal/41095. To submit a manuscript,please go to https://www. editorialmanager.com/cvmj.
eceived his B.S.degree in computer science and technology from Shenzhen University,Shenzhen,China, in 2015.He is currently pursuing his M.S.degree in the School of Computer Science&Software Engineering, Shenzhen University.
1 College of Computer Science and Software Engineering, Shenzhen University,Shenzhen,China.E-mail:L. Chen,chen.lin@email.szu.edu.cn;M.Yang,yang.meng@ szu.edu.cn().
2 School of Data and Computer Science,Sun Yat-sen University,Guangzhou,China.
3 Key Laboratory of Machine Intelligence and Advanced Computing(Sun Yat-sen University),Ministry of Education,China.
Manuscript
2016-09-04;accepted:2016-12-20
 Computational Visual Media2017年1期
Computational Visual Media2017年1期
- Computational Visual Media的其它文章
- A survey of the state-of-the-art in patch-based synthesis
- Estimating ref l ectance and shape of objects from a single cartoon-shaded image
- Robust facial landmark detection and tracking across poses and expressions for in-the-wild monocular video
- Dynamic skin deformation simulation using musculoskeletal model and soft tissue dynamics
- Boundary-aware texture region segmentation from manga
- Multi-example feature-constrained back-projection method for image super-resolution