
桌面遥感图像处理系统并行处理架构选择与实验分析
2017-06-20 17:38彭检贵张良李维良李林华周佳雯
软件导刊 2017年4期
彭检贵+张良+李维良+李林华+周佳雯

摘要:介绍了桌面遥感影像处理系统对高性能计算的需求及其现状,针对多核CPU与GPU这两种当前单机系统中最重要计算资源的结构与功能差异,总结不同并行架构所具有的运算特点及适用范围,以遥感影像多项式几何校正为例,对比分析了同时代多核CPU与GPU在进行高计算密集度且运算逻辑较简单算法的高性能处理之间的性能差异,探讨了并行处理架构选择的实践准则。
关键词:并行架构;遥感图像处理系统;多核CPU;CUDA
中图分类号:TP317.4
文献标识码:A
文章编号:16727800(2017)004020104
0引言
面向桌面级应用的遥感影像高性能计算,从本质上讲,是充分利用现有单机系统所提供的计算资源来提高遥感影像处理运算效率的一种有效途径。多核CPU与GPU作为现有计算机中配置的两种最常见的并行处理器,构成了当前单机系统上能够被开发的最主要的计算资源,也势必会在桌面遥感影像处理系统的高性能处理过程中发挥重要作用。目前,国内外有不少专家学者都对此做了大量工作。Shahbahrami A等[1]从任务并行和数据并行两个角度研究了基于多核CPU的GLCM影像纹理特征提取;Fitzgerald D F等[2]研究与探讨了基于多核CPU的遥感影像分割算法实现,提出了一种影像数据子图块不匹配的应对策略;Paz Abel等[3]研究对比了集群环境下与GPU环境下的高光谱遥感影像目标与异常检测;Antonio Plaza等[4]对比研究了Beowulf集群、可编程门阵列(FPGA)以及GPU(CUDA)架构下高光谱影像像素纯度指数的计算;Fan Zhang等[5]对基于GPU的复杂场景合成孔径信号模拟方法进行了深入研究。 本文针对桌面遥感影像处理系统高性能计算中所使用的多核CPU与GPU这两种主要并行架构,通过理论分析与对照实验相结合的方法,对各自的结构与功能特点进行深入研究,总结不同并行架构之间不同的运算特点及适用范围,同时从算法运算逻辑复杂度与数据存储复杂度对各关键算法进行对比分析与实验,提出一系列并行架构选择的实践准则。最后,以遥感影像多项式几何校正为例,对比分析同时代多核CPU与GPU在进行高计算密集度且运算逻辑较简单算法的高性能处理之间的性能差异,对并行处理架构选择的实践准则作进一步说明。
1并行处理架构对比分析与选择
1.1多核CPU与GPU在结构与功能上的不同
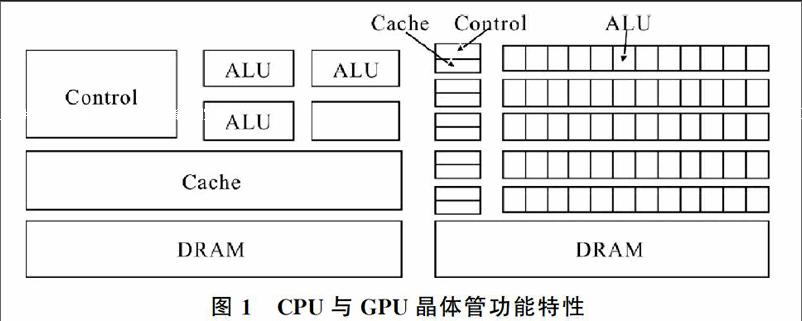
多核CPU与GPU作为桌面遥感影像处理系统所使用的两种主要并行架构,具有不同的结构与功能特性[6]。如图1所示,CPU的设计目标是使执行单元以很低延迟获取数据和指令,能够适应各种不同的运算环境,擅长复杂逻辑运算,因此将大量晶体管用于复杂控制逻辑单元及大容量的缓存单元;而GPU的设计目标是使大量线程实现面向吞吐量的数据并行计算,因此大量晶体管被用于执行单元来运行更多相对简单的执行线程,而逻辑控制和缓存单元则相对较少[8]。 正是由于CPU与GPU这两种处理器设计结构上的差异,导致两者在处理功能上也有明显不同。从功能上讲,CPU对延迟更敏感,而GPU则侧重于提高整体的数据吞吐量。多核CPU较GPU而言尽管在处理速度上有很大劣势,但是由于复杂的控制逻辑、分支预测和大量缓存等关键技术的应用,多核CPU对复杂运算的并行化支持力度更大;GPU是特地为支持计算密集、并行度高的运算而设计,但是由于缓存单元与逻辑控制单元相对较少,对于逻辑复杂、并行度不大的运算,GPU并不能很好地支持其并行化。
1.2高性能计算中并行架构选择准则
GPU能够处理大量数据的通用并行计算问题,但并不意味着所有遥感影像处理算法的高性能计算问题都能利用GPU技术轻易实现。因此,理清GPU在各类算法实现中的优势与缺陷,对桌面遥感影像处理系统的高性能计算非常重要。面向桌面应用的遥感影像高性能计算,首先应根据自身特点从全局上对各关键算法进行分类,综合把握,根据算法自身特点选择最合适的并行处理架构。根据多核CPU与GPU两者之间的硬件结构与程序运行的特点,本文提出3点并行架构选择的实践准则:①待并行化处理的算法在运算过程中,结果影像各像素的确定过程是否彼此独立,互不影响,即结果影像各像素值在确定过程中是否需要获取邻近像素或者像素集合的基本信息;②待并行化处理的算法在运算时,结果影像中是否逐渐形成多个具有某种逻辑关联的像素集合,且后续运算过程需要获取这些集合中像素的光谱信息或相关空间统计信息,即同一遍渲染过程使用前面像素集合的计算结果;③待并行化处理的算法在运算过程中是否会频繁或不规律地出现内存与外设(如磁盘文件)之间影像数据或算法实现过程中相关辅助数据的转存与交换现象,即在整个运算过程中,处理器所需要的影像数据或者相关辅助数据是否一直位于内存中,而无需从相关磁盘文件中调度所需数据。 利用多核CPU与GPU两种架构提升桌面遥感影像处理系统的运行效率,需要根据这两种并行处理器的功能特性,结合算法本身的运算逻辑与实现方式,对需要进行并行化处理的遥感影像处理算法进行类别划分,即适合利用多核CPU进行高性能处理的算法、适合利用GPU进行高性能处理的算法。根据以上3个准则,在桌面遥感影像处理软件内置的主要算法中,同时满足以上3个条件的算法一般具有逻辑相对简单、并行度较大的特点,包含了多数较为常见的影像处理算法,如:影像几何校正、影像监督分类、影像卷积运算等,通常非常适合利用GPU进行算法加速处理,本文称这类算法为“简单算法”。而不能完全满足以上3个条件算法的高性能处理采用GPU一般不易实现。具体而言,在CUDA架构下,一般采用大量线程来执行计算密集、并行度高的指令,在桌面遥感影像处理系统高性能计算中,通常一个线程会对应一个像素的计算处理。当算法不满足条件(1)或(2),即运算逻辑较为复杂,算法在运行过程中目标影像会形成若干具有内在逻辑的像素集合,且后续运算需要获取同类集合中像素的光谱信息或相关空间信息时,CUDA程序会变得较难编写,即使勉强编写出来,也会严重影响CUDA计算性能的发挥,有违CUDA设备的设计初衷。此类算法的代表有KMeans非监督分类、Isodata非监督分类、多尺度分割等特征级影像处理方法。CUDA设备在计算过程中的直接数据来源为显存,显存与磁盘文件之间数据交换、转存的实现远比CPU内存与磁盘文件之间数据交换、转存的实现复杂。当算法无法满足条件(3)时,即一个算法在运行过程中,需要频繁地或者不规律地将显存中的数据交换到磁盘文件或从磁盘文件中调度相关数据进入显存,编写CUDA程序也会变得困难,此类算法的代表为遥感影像多尺度分割算法。当算法无法同时满足以上3个条件,一般而言,利用CUDA技术难以进行其高性能计算工作,然而算法在实现过程中确实能够做到一定程度的并行执行,在这种情况之下,可以考虑采用多核CPU进行处理,本文称这类算法为复杂算法。 一般而言,简单算法易于利用CUDA进行算法加速处理,当然,需要注意的是,简单算法同样也可比较容易地利用多核CPU进行并行化处理。从理论上讲,由于GPU在处理简单算法运算时的速度一般高于同时代的多核CPU,因此,推荐使用GPU,下文将对此问题进行对比实验,以实验验证来提升理论分析的严密性。〖HJ*3〗 无论复杂算法还是简单算法,在高性能处理过程中,鉴于所选用的并行架构与遥感影像本身的特点,其都会面临着一系列待解决的关键问题。复杂算法在不满足条件(1)和(2)时,可能会出现各个数据分块在并行处理完毕之后接边不能很好地吻合而无法直接合并的问题;复杂算法在不满足条件(3)时,在影像数据量较大的情况下,可能会出现影像数据子区的多线程读写问题。简单算法实現起来相比于复杂算法较为容易,一般不存在数据分块之间的接边问题,大数据量影像的处理问题一般也较易解决,简单算法高性能处理问题的关键在于如何利用CUDA设备特殊的结构与功能特性进行算法优化,其中,影像数据以及相关辅助数据的存储与访问策略优化显得尤为重要。 当然,需要指出的是,本文所提出的一系列原则只是针对多数常用遥感影像处理算法在选择高性能计算架构的问题而言,可能无法涵盖所有处理算法,这些有待于后续的深入研究。
2运算逻辑较简单情况下并行架构对比分析
在桌面遥感影像处理软件中,当某个算法能够同时满足上文提到的3个并行架构选择的实践准则时,一般而言,算法便于利用GPU进行并行化处理,当然,也同样便于在多核CPU架构下进行高性能计算。从上述分析可知,同时代GPU运算速度一般快于多核CPU,因此为达到遥感影像高性能计算运算效率的最大化,优先采用GPU进行并行化实现。为了证明这一点,本节以遥感影像多项式几何校正为例,对比利用GPU与利用多核CPU进行简单算法高性能计算的效率提升程度。 本节研究的重点是在满足较轻易实现算法高性能计算条件下,对比同时代多核CPU與GPU的计算速度差异,因此对于利用多核CPU或者GPU实现遥感影像高性能计算的详细过程和所面临的关键问题及解决方法不作讨论。
2.1多项式几何校正算法
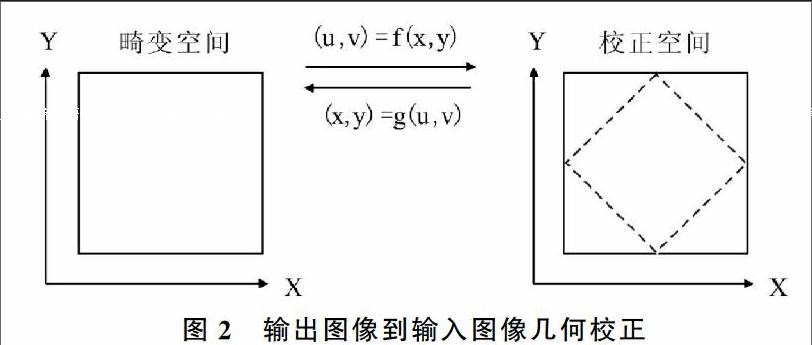
遥感影像几何校正是以某种预先确定的数学模型来校正成像过程中所造成的各种几何畸变,产生一幅符合某种地图投影或图形表达要求的新影像。校正前后的影像空间分别为畸变空间和校正空间。
遥感影像几何校正首先要确定从畸变空间到校正空间的变换函数。基于多项式变换的校正方法是实践中经常使用的一种方法,原理直观,对各种类型的传感器有良好适用性。多项式变换校正法的基本思想是:使用多项式来拟合图像校正过程中从畸变空间到校正空间的正向变换函数,然后用向后映射重采样方法(又称间接法)来完成输入图像到输出图像的几何校正,如图2所示。假设正向变换函数为:
本文以完全二次多项式为例来讨论算法实现,式(5)和(6)、式(7)和(8)分别表示正向和逆向变换函数。正向变换函数中的参数,对于系统几何校正而言,是利用已知的或可预测的参数,如卫星轨道参数、传感器姿态参数等来直接构成,而对于几何校正,则需利用控制点数据来求取[8]。本文实验所采用的正向变换函数均为根据利用控制点数据来求取拟合得到的完全二次多项式。
算法有像素坐标变换与像素亮度的重采样两个基本环节,校正的主要处理过程如图3所示。首先,根据式(5)和式(6)求出输出影像的范围,如图2右边校正空间中实线内的范围,一般通过计算图像的全局边界来加以确定;由于校正算法采用向后映射方式进行,因此第二步必须求取从校正空间到畸变空间的逆向多项式变换函数,如式(7)和式(8),逆变换的参数是利用输入和输出图像上的若干个同名像点对,按最小二乘原理求解;第三步是几何位置变换,将前面确定的输出图像范围内的像素坐标(u,v)逐个代入逆变换函数得到其在输入影像中的对应位置;第四步则是根据输入影像位置(x,y)周围像素的灰度值,按某种重采样算法得到校正影像(u,v)处的灰度值。
常用的重采样算法包括双三次卷积、双线性插值和最邻近像素法等。本文以双线性插值算法为例加以介绍,如果选择一个坐标系统使得4个已知点的坐标分别为(0,0),(0,1),(1,0),(1,1),那么插值公式可以表示为:p(x,y)=p(0,0)(1-x)(1-y)+p(1,0)x(1-y)+p(0,1)(1-y)y+p(1,1)xy(9)
遥感影像几何校正过程中,第一步求取输出图像的范围(只需要边界像素坐标参与计算)和第二步用粗网格点求取逆变换函数的参数,相对于后两个步骤而言计算量很小,几乎可以忽略不计,并行化的重点是在第三步几何位置变换和第四步灰度值重采样上,将这两个步骤统称为重采样。
2.2实验结果与分析
根据以上研究思路,本节以遥感影像多项式几何校正为例,重点在于对比同时代多核CPU与CUDA设备在同时满足能够较轻易实现算法并行处理情况下的计算速度差异。本次实验所使用的硬件实验环境为:NVIDIA GEFORCE GT 425M显卡,该显卡所使用的GPU内置两个SM,每个SM拥有48个SP,共96个SP,显存容量为1G;Intel CORE i5 CPU,该CPU拥有两个核心;内存容量为2G。本次实验软件实验环境为:Windows 7操作系统及Vs2010编译器。
2.2.1几何校正结果对比
实验首先对比多核CPU架构、CUDA架构下几何校正高性能计算与结果。实验数据采用两幅有重叠地区的GeoEye影像,尺寸均为500*500,两幅影像的空间分辨率不同。为便于实验观察,以低空间分辨率影像为参考影像,高空间分辨率影像为畸变影像,如图4所示。
几何校正结果如图5所示,其中图5(a)为多核CPU架构下几何校正高性能计算结果,图5(b)为CUDA架构下几何校正高性能计算结果。在结果影像中,畸变影像被校正到参考影像空间后所对应的部分为白色框所划定的影像块。
2.2.2几何校正计算效率对比 接下来,对比多核CPU架构下几何校正高性能计算与CUDA架构下几何校正高性能计算的计算效率。实验数据与2.1节中相同。实验分四组进行,其中第一组为多核CPU架构下单线程程序运行时间,第二组为多核CPU架构下两线程程序运行时间,第三组为多核CPU架构下四线程程序运行时间,最后一组为CUDA架构下几何校正高性能计算的计算时间,实验结果如表1所示。
由表1可知,遥感影像多项式几何校正作为可在多核CPU与CUDA架构下同时实现高性能计算的运算逻辑并不复杂的代表性算法,多核CPU架构下的高性能计算方式可以在一定程度上提升其运算效率,这一点可以从第1列与第2列、第1列与第3列的数据对比中得出。然而,对比第1列与第4列的结果数据可知,同时代的CUDA设备对于算法的运行效率提升更为显著。因此,在桌面遥感影像处理系统的高性能计算过程中,针对运算逻辑和数〖LL〗据存储方式均较为简单的算法,一般推荐在CUDA架构下进行高性能计算,以达到程序运算效率提升的最大化。
3结语
本文主要介绍在进行桌面遥感影像处理系统高性能计算时针对算法的内在特点所面临的并行架构选择问题。深入研究多核CPU与GPU这两种当前单机系统中最重要计算资源的结构与功能差异,总结不同并行架构所具有的运算特点及适用范围。从全局上统筹分析各关键算法运算逻辑复杂度与数据存储复杂度,提出了一系列针对具体算法选择合适并行处理架构的实践准则。同时,以多项式几何校正为例,验证了在进行简单算法的高性能计算时优先采用GPU的观点,对实践准则进行了补充阐述。 当然,本文所提出的一系列原则只是针对多数常用遥感影像处理算法在选择高性能计算架构的问题而言,可能无法涵盖所有处理算法,这些有待于后续深入研究。
参考文献:
[1]ASADOLLAH SHAHBAHRAMI,TUAN ANHPHAM,KOEN BERTELS.Parallel implementation of gray level cooccurrence matrices and haralick texture features on cell architecture[J].Journal of Supercomputing,2012,59(3):14551477.
[2]FITZGERALD D F,WILLS D S,WILLS L M.Realtime, parallel segmentation of highresolution images on multicore platforms[J].Journal of RealTime Image Processing,2014.
[3]PAZ ABEL,PLAZA ANTONIO.Clusters versus GPUs for parallel target and anomaly detection in hyperspectral images[J].EURASIP Journal on Advances in Signal Processing,2010.
[4]ANTONIO PLAZA,JAVIER PLAZA,HUGO VEGAS.Improving the performance of hyperspectral image and signal processing algorithms using parallel,distributed and specialized hardwarebased systems[J].Journal of Signal Processing Systems,2010,61(3):293315.
[5]FAN ZHANG,ZHENGLI,BINGNANWANG,et al.Hybrid generalpurpose computation on GPU (GPGPU) and computer graphics synthetic aperture radar simulation for complex scenes[J].International Journal of Physical Sciences,2012,7(8):12241234.
[6]HWU W.Rethinking computer architecture for throughput computing[C].Keynote of 2013 International Conference on Embedded Computer Systems: Architectures, Modeling and Simulation (SAMOS),Greece,2013:129.
[7]周海芳.遙感图像并行处理算法的研究与应用[D].长沙:国防科学技术大学,2003.
[8]陈国良.并行计算——结构·算法·编程[M].第3版.北京:高等教育出版社,2011.
(责任编辑:孙娟)
