
基于ARIMA模型的南宁房地产销售分析与预测
2017-06-20 22:57陆尚辉
现代经济信息 2017年7期
陆尚辉

摘要:本文应用RStutio软件并基于ARIMA模型对南宁房地产销售额进行了分析与预测。本文建立了两个模型,然后通过模型对比得到最优模型,且模型的MAPE值和TIC值均显示模型的拟合精度良好。因此,模型对相关房地产的模型研究起到有一定的参考意义。
关键词:ARIMA模型;房地产销售;RStudio
中图分类号:F299.23 文献识别码:A 文章编号:1001-828X(2017)007-0-03
房地产业既是我国基础性和先导性产业,也是我国经济发展的支柱之一,对房地产产业的观察有助于我们从侧面了解一个地区的经济发展情况。房地产产业的健康发展对区域经济的影响有着举足轻重的作用。一个地区的房地产的销售反映了该地区的房地产市场的火热程度和經济的发展情况。南宁的房地产在进入新世纪之后,开始进入了快速发展的轨道。特别是南宁作为自治区首府且将房地产作为支柱产业进行扶持之后,南宁的房地产更是有了飞跃式的发展。近两年,根据官方公布的数据,随着全面二孩的开放和各项利好政策的出台,南宁房地产的销售实现了20%左右的增长。
而随着自治区政府和南宁市政府决定将南宁建成面向东盟开放合作的区域性国际城市和中央提出“一带一路”的政策之后,人们对南宁房地产的发展充满信心。另外,从近些年房地产的销售数据来看,也反映的人们对南宁房地产发展的信心。本文以南宁近四年的房地产销售额数据作为研究对象,采用RStudio软件和ARIMA模型对南宁房地产销售额进行建模,最后对南宁房地产销售额进行预测,最后分析了南宁房地产销售额的增长发展特点和造成这个特点的原因。
一、模型分析
1.模型理论
本文所使用的模型为简单季节疏系数模型,即通过趋势差分、季节差分将序列转化为平稳序列后,再对序列进行建模。其模型结构如下:
式中
(1)D为季节周期,d为为对序列进行去趋势信息而进行的差分阶数
(2)为白噪声序列,且E(
(3),为q阶移动平均平均系数多项式,且至少有一个系数为0
(4)Φ(B)=1-φ1B-…φpBp为p阶自回归系数多项式,且至少有一个系数为0
2.分析思路
由ARIMA模型的理论知,ARIMA模型一般是对平稳的序列进行建模,因此在进行ARIMA建模之前,需先对序列进行平稳化。常用的平稳化方法为:首先对原始序列进行d阶差分去趋势,如果d阶差分后的数据具有周期性,则需再对差分后的数据进行周期差分以去季节。在ARIMA模型中,要求模型中的符合上述(2)的要求。建立ARIMA模型的关键点在于,需要对移动平均多项式和自回归多项的阶数q和p进行定阶和参数的估计,然后对参数进行显著性检验并剔除不显著的参数。
要使模型中的符合上述(2)的要求,本文采用对残差进行白噪声检验,当p值小于0.05时认为其为白噪声序列,即符合(2)的要求。q和p的定阶按如下规则进行。
由于真实的数据的自相关系数和样本偏自相关系数几乎不会呈现出理论上的完美截尾性,因此一般以它们落入二倍标准差范围内作为判断是否截尾的依据。一般情况下,它们在最初的d阶明显大于2倍标准差范围,d阶之后几乎有95%的样本相关系数或样本自相关系数落入2倍标准差范围内,且它们衰减到0值附近波动非常突然,则可以认为d阶截尾。反之,有超过5%的样本相关系数或样本偏自相关系数落入2倍标准差之外,或者在衰减到0值附近波动的过程非常的缓慢或者连续,则可以认为它们具有拖尾性。
二、实证分析
1.样本数据获取及数据预处理
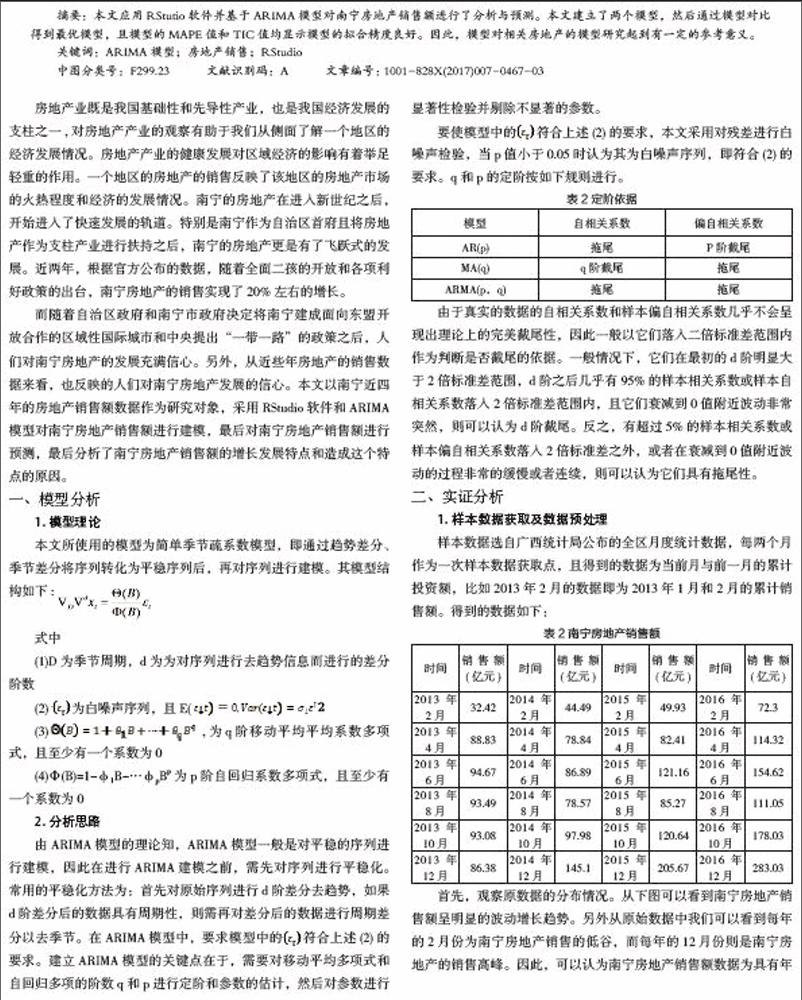
样本数据选自广西统计局公布的全区月度统计数据,每两个月作为一次样本数据获取点,且得到的数据为当前月与前一月的累计投资额,比如2013年2月的数据即为2013年1月和2月的累计销售额。得到的数据如下:
首先,观察原数据的分布情况。从下图可以看到南宁房地产销售额呈明显的波动增长趋势。另外从原始数据中我们可以看到每年的2月份为南宁房地产销售的低谷,而每年的12月份则是南宁房地产的销售高峰。因此,可以认为南宁房地产销售额数据为具有年度周期的数据。
基于上述理由,决定对数据进行一阶差分后在进行周期为6的季节差分。数据处理后的时序图如图2所示,从图中可以看到经过去趋势和季节差分后,序列基本在0值附近波动,即认为预处理后的数据的均值为0,另外可以看出预处理后的数据基本上没有明显的趋势和周期,初步认定处理后的数据平稳。
为进一步确认判断是否正确,现对经过预处理后的数据进行无趋势无常数项的单位根检验,检验结果如下:
结果显示预处理后的数据平稳。进一步地,对预处理后的数据进行白噪声检验,检验结果如下:
图3的结果显示预处理后的数据不是白噪声数据,这说明预处理后的数据存在着相关信息。综上可知预处理后的数据平稳且非白噪声数据,适合建立ARIMA模型。
为对模型的p和q进行定阶,现在观察预处理后的数据的自相关系数图和偏自相关系数图如下:
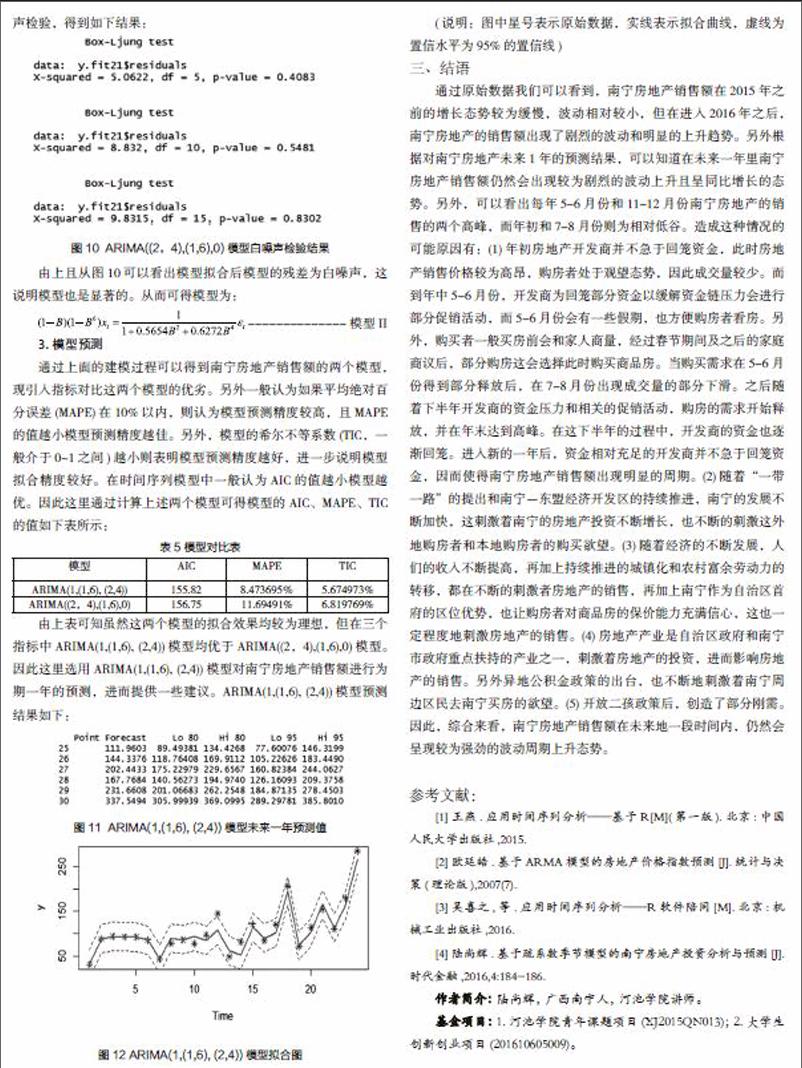
从图4可以看出自相关系数均具有一定的拖尾性,从图5可以看出偏相关系数4阶截尾。这表明预处理后的数据具有短期相关性,这与ADF检验的结果一致。根据图4和图5,因考虑对预处理后的数据进行无常数均值的ARMA(1,4)和AR(4)模型。并对模型和模型系数的显著性进行检验,然后根据AIC准则选择最优模型。
2.数据建模
首先对数据进行ARIMA(1,(1,6),4)模型拟合,其结果如下:
图6 ARIMA(1,(1,6),4)模型系数拟合结果
接下来对模型的各项系数进行显著性检验。其结果如下:
根据表4,剔除检验p值大于0.05的系数项,由此拟合疏系数季节模型ARIMA(1,(1,6),(2,4)),得到结果如下:
