
基于SPARK平台的钓鱼网站识别技术研究
2017-07-01 20:28朱子涵陈霖
湖南邮电职业技术学院学报 2017年2期
朱子涵,陈霖
(中国移动湖南公司信息安全管理部,湖南长沙410001)
基于SPARK平台的钓鱼网站识别技术研究
朱子涵,陈霖
(中国移动湖南公司信息安全管理部,湖南长沙410001)
目前网络消费变得越来越频繁,但钓鱼网站给网上交易平台及相关用户带来较重的经济损失,如何有效甄别钓鱼网站,减少用户损失,显得尤为重要。文章通过URL特征、网页内容、网页图片特征等属性来描述网页,根据钓鱼网页不同类型,针对各个特征属性,构建不同的分类器,然后通过逐步判别方式,达到动态预测各待检测网页的目的。工具上,针对处理大数据集,利用SPARK平台计算结果,通过实验测试,取得了良好的分类效果。
钓鱼网站;逐步动态分类;SPARK平台
钓鱼网站常指通过冒充银行和电商等机构,利用欺骗性垃圾邮件、虚假广告等手段,窃取用户个人账户和密码等私密信息的网站。近年来,通过仿冒真实网站的URL地址及其页面内容的“钓鱼网站”已威胁到用户的隐私和财产安全。这不仅给用户造成了损失,也给企业形象造成了负面影响。
目前关于钓鱼网站的研究很多,研究方法大体上可以分为四类:
1)基于黑名单的检测。此方法虽然精确度高,但只能检测到包含在名单里的网站,而钓鱼网站在线时间普遍较短,平均大概只有4天,因此,黑名单方法实时性不强,且更新黑名单耗时耗力,应用范围有限。
2)基于图像相似性的检测。此方法将钓鱼网站的检测转化为图像匹配问题,主要通过区别网页中的关键点,利用感知哈希方法等计算网页间的相似性,达到检测的目的。但随着技术的发展,钓鱼网站与正规网站相比,越来越逼真,利用图像相似性的方法检测准确率降低。
3)基于URL和网站内容特征的检测。通常URL特征属性包括IP地址、hosts、特殊符号如”@”等,网站内容特征有标题(title)、关键词(keywords)等。此方法是常用的钓鱼网站检测方法,但具体实施时,选择哪些特征属性作为分类依据,针对不同类型的钓鱼网站,需要具体考虑。
4)基于搜索引擎的检测。此方法依据的主要原理是利用正规网站的URL搜索能够得到大量排名靠前的网站,而用钓鱼网站的URL搜索得到的网站没有排名或者排名很靠后。
各类方法各有优缺点,本文基于以上各研究类型,针对种类繁多的钓鱼网站,提出了逐步构建基于URL特征、网页文本内容、网页图片的单个分类器,依次检测出对应特征明显的钓鱼网站,最后达到检测出所有钓鱼网站的目的。
1 钓鱼网站特征提取及识别过程
1.1 网页特征分析
1)URL特征
钓鱼网站为了吸引用户浏览,往往通过模仿URL地址达到目的,尤其是模仿域名用以迷惑用户。因此,可以选取网站域名,作为检测网站的特征,采集数据时通过目标网站与钓鱼网站的URL获得相应的域名,计算两域名的编辑距离。
2)网页内容特征
钓鱼网站另一个手段就是网站内容尽量和目标网站一致,因此,可以通过网站文本内容的相似性度量评价网站是否为钓鱼网站。整理数据时爬取目标网站与待测网站文本内容,通过simhash算法,转变为哈希值,计算两网站海明距离。
3)网页图片特征
对于钓鱼网页,通常包含的图片与目标网站都基本一致,因此,可以爬取其包含的所有图片,利用感知哈希算法,计算得到网页的指纹集,作为评价特征。
假定目标网站G有n张图片,指纹集为:

待测网站H有m张图片,对应指纹集为:

设距离函数为:

则两个网站的相似性度量为:

由于各待测网站图片数量不同,为统一度量,取相似性度量的平均值,即:

1.2 钓鱼网站识别过程
本文首先通过计算PageRank值,剔除部分排名靠前的网站,然后从URL特征、网页文本内容、网页图片特征三个方面识别可疑网站,具体识别步骤如下:
1)计算待检测网站PageRank值,排名靠前的剔除,剩下的网站进入下一步;
2)计算待检测网站与目标网站的域名编辑距离,筛选出一部分钓鱼网站,余下数据进入下一步;
3)利用SimHash算法计算待测网站和目标网站文本内容的海明距离,较小的为可疑网站,再一次筛选网站,剩下数据进入下一步;
4)利用感知哈希算法计算待检测网站和目标网站图片特征的海明距离,越小的越相似,为可疑网站;
5)综合集成上面结果,判定筛选出最终的钓鱼网站结果。
2 相关算法描述
2.1 PageRank算法
PageRank根据网站的外部链接和内部链接的数量和质量来衡量网站的价值,核心思想为:
1)如果一个网页被很多其他网页链接到,pagerank值相对较高;
2)如果一个pagerank值很高的网页链接到一个其他的网页,被链接的网页pagerank值相应的被提高。计算公式如下:

kjout是节点k的出度,即节点k指向的节点数目。常数c为随机跳转概率,保证没有被指向的节点同样有值。
2.2 最小编辑距离算法
编辑距离是测量一个字符串转换成另外一个字符串需要操作(插入、删除、置换)的最小次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。本算法中,编辑距离越小,两个字符串的相似度越大。计算公式如下:

其中,对于字符串s1与s2,d[i-1,j]表示s2改变一个字母,d[i,j-1]表示s1改变一个字母,xi表示s1中的第i个字母,yj表示s2中的第j个字母。
通过上述计算公式,可通过对钓鱼网站的URL关键字符进行编辑距离计算,得出相似度阈值。
2.3 Sim Hash算法
Simhash算法的主要思想是降维,将高维的特征向量映射成一个低维的特征向量,通过两个向量的Hamming距离来确定待测网站内容是否重复或者高度近似。算法见图1,具体步骤如下:
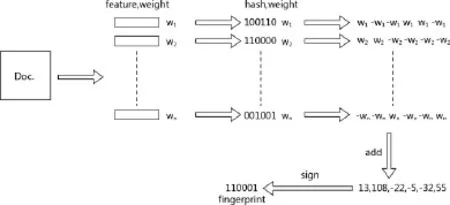
图1 SimHash算法过程图
1)对于给定的一段语句,进行分词,得到有效的特征向量;
2)为每一个特征向量设置一个权值,权值根据tfidf公式得到;
3)对每一个特征向量计算hash值,为0、1组成的n-bit签名;
4)所有特征向量进行加权(1则为正,0则为负),进行累加;
5)对于n-bit签名的累加结果,如果>0置1,否则置0;
6)得到该语句的simhash值;
7)根据不同语句simhash的海明距离就来判断相似程度。
SimHash中为每一个抓取到的网页内容通过hash的方式生成一个指纹(fingerprint),目的是为了让整个分布尽可能地均匀,输入内容哪怕只有轻微变化,hash就会发生很大地变化。采用的哈希函数中,需要对几乎相同的输入内容,产生相同或者相近的hashcode,即hashcode的相似程度要能直接反映输入内容的相似程度。
2.4 海明距离
对于二进制字符串的a和b,海明距离等于在a XOR b运算结果中1的个数,比如1011101 XOR 1001001为0010100,运算结果里有两个1,海明距离就是2。本文用的海明距离都是二进制编码海明距离。
2.5 TF-IDF算法
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度,本文主要表示对应文本特征的权重。计算公式如下:

其中:

ni,j是词ti在文件dj中的出现次数,则是文件dj中所有词的出现次数之和,|D|为语料库中文件总数,为包含词ti的文件数目。
2.6 感知哈希算法
感知哈希算法的实现方式很多,本文具体实现方式如下:
1)将图片缩小到8*8的尺寸,共64个像素,其作用是摒弃不同尺寸、比例带来的图片差异;
2)将缩小后的图片,转为64级灰度,即所有像素点只有64种颜色;
3)计算所有64个像素的灰度平均值;
4)将每个像素的灰度,与平均值比较,大于或等于平均值的记为1,小于平均值的记为0;
5)将上一步的比较结果组合在一起,就构成了一个64位的字符串,得到图片的指纹;
6)计算该图片与目标图片指纹的海明距离。如果海明距离小于一定阈值,就表明两张图片相似度很大,否则,相似度很小。
2.7 逐步动态分类
检测钓鱼网站的方法手段很多,但钓鱼网站的类型也很多,有模仿URL域名的,有主要模仿内容的等。因此,用单一的检测手段很难有效地检测种类繁多的钓鱼网站。鉴于此类现状,可以根据不同特征,采用不同检测方法,逐步筛选出钓鱼网站。主要原理就是在每一步过程中,保持低误判率,逐步降低漏判率,最终检测出各类型的钓鱼网站,详细过程见图2。

图2 逐步分类过程图
3 Hadoop与Spark技术平台
Hadoop是一个开源的可运行于大规模集群上的分布式并行编程框架,其最核心的设计包括:MapReduce和HDFS。基于Hadoop,可以轻松地编写可处理海量数据的分布式并行程序,并将其运行于由成百上千个结点组成的大规模计算机集群上。Spark相比于Mapreduce有其优势,主要表现为MapReduce通常将中间结果放到HDFS上,Spark是基于内存并行大数据框架,中间结果存放到内存,对于迭代数据Spark效率高;MapReduce总是消耗大量时间排序,而有些场景不需要排序,Spark可以避免不必要的排序所带来的开销等,针对这些特点,本文主要利用spark计算。具体实现框架如图3:
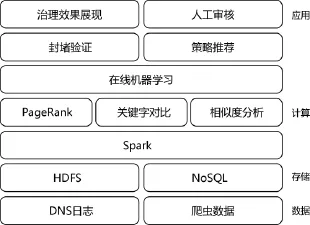
图3 实验框架图
获取用户上网日志数据,结合爬虫集群,以海量的页面数据作为数据源;在数据存储上采用经典的分布式存储系统HDFS与NOSQL类分布式数据库(例如:MongoDB)相结合的方式;在计算层上则采用目前热门的Spark计算框架,在Spark上实现关键的钓鱼网站甄别算法。
4 实验结果与评估
实验使用数据以用户上网日志数据和分布式爬虫获得的页面数据为主,通过逐步筛选方法,得到了最终实验结果,验证了这种方法的有效性和可行性。
4.1 实验评估方法
模型好坏一般利用混淆矩阵(表1)中的数据计算准确率、覆盖率等评估模型,本次试验中用到的评估参数有正类准确率(PR)、正类覆盖率(PA),计算公式如下:

其中,TP表示本来为正类预测也为正类的个数,FP表示本来为负类预测为正类的个数,FN表示本来为正类预测为负类的个数,TN表示本来为负类预测为负类的个数。PA表示分类器的敏感程度,PR表示分类器的正类准确度。如表1所示。

表1 混淆矩阵表
由于本次实验中通过逐步筛选,每一次检测都会得到混淆矩阵,因此,最终的混淆矩阵是前几步得到的混淆矩阵对应值之和。假定每一步得到的对应值为TPi、FNi、FPi、TNi,则评价最终结果的(13)-(14)式可写为:

4.2 各步检测结果比较
试验中从正规网站和钓鱼网站中随机抽取100000条记录作为样本集,做十次独立试验,取十次实验得到的结果,根据公式(13)-(14)得到各步之间的结果比较,如图4与图5所示。

图4 各实验正类覆盖率对比图

图5 各实验准确率对比图
从图4中可以看出各步实验结果的正类覆盖率,其中PA-1表示通过URL特征检测得到的正类覆盖率,PA-2表示通过网站内容检测得到的正类覆盖率,PA-3表示通过网页图片得到的正类覆盖率,PA-T表示最终检测结果的正类覆盖率,图像表示单独用网页图片特征检测网站得到的正类覆盖率。通过比较,PA-1最低,说明钓鱼网站中通过URL域名模仿正规网站的比例不高,单纯从URL特征检测钓鱼网站效果不大好,而通过网页内容检测网站,召回率达到了近90%,这也符合钓鱼网站模仿正规网站内容,欺骗用户的事实,同时说明网页内容是用来检测钓鱼网站的主要特征,图片也属于网页内容,但最后一步检测正类覆盖率较低,可能的原因是通过前两步检测,剔除了大部分的钓鱼网站,剩下的不仅在内容和URL上模仿的不好,图片做的也比较粗糙,但总的结果表明这只是一少部分。为了说明图片为特征的检测效果,以同样的样本单独做检测,正类覆盖率平均值约为65%,比以文本内容为特征的检测效果要差,说明一部分钓鱼网站在制作上不是足够精细,只是为了快速达到欺骗用户的目的。通过累计前几步的结果,最终得到结果的正类覆盖率PA-T平均为94.7%,检测效果良好。
通过图5可以看到,各检测方法的正类准确率比较高,说明各分类器效果较好。还可以看到通过文本内容检测的正类准确率比总结果的正类准确率还高,结合图4可知,这是增加了图片检测,通过适当降低正类正确率,提高召回率,得到更好的检测效果。
4.3 与其他检测方法比较
为了说明检测效果,试验中做了与朴素贝叶斯检测结果的对比,如图6所示,通过同一样本,各做十次实验,逐步检测结果正类覆盖率在92-95%之间,朴素贝叶斯分类结果的正类覆盖率在87-93%之间,说明本文提出的逐步分类检测效果更好,且更稳定。

图6 与朴素贝叶斯检测结果比较图
5 总结
本文提出逐步检测钓鱼网站的方法,基于URL特征、网站文本内容和网站图片特征,通过编辑距离、SimHash、图片感知哈希等算法,逐步检测网站,最终达到分类的目的。本次实验基于spark平台,实验结果表明,逐步检测效果良好,并比传统的朴素贝叶斯分类效果要好。下一步继续总结钓鱼网站特征,更全面地分析检测因素,改进各步检测算法,提高检测钓鱼网站效率。
[1]顾晓清,王洪元,倪彤光,丁辉.基于贝叶斯和支持向量机的钓鱼网站检测方法[J].计算机工程与应用,2015(4):87-90.
[2]Pan Y,Ding X.Anomaly Based Web Phishing Page Detection [J].Acsac,2006:381-392.
[3]Anti-PhishingWorking Group.Phishing activity trends report [EB/OL].http://antiphishing.org/APWG_Report_March_2007. pdf,2007.
[4]Chen T-C,Dick S,Miller J.Detecting visually similar Web pages:Application tophishingdetection[J].ACM Transactionson InternetTechnology(TOIT),2010(2):5.
[5]Chen K-T,Chen J-Y,Huang C-R,et al.Fighting phishing with discriminative keypoint features[J].Internet Computing, IRRR,2009(3):56-63.
[6]卢康,周安民.基于图像相似性的钓鱼网站检测[J].信息安全与通信保密,2016(3):115-117.
Research on phishing site identification technology based on SPARK p latform
ZHU Zi-han,CHEN Lin
(Information SecurityManagementDepartment,ChinaMobileGroup Hunan Co.,Ltd,Changsha, Hunan,China410001)
Network consumption is becomingmore andmore frequent,but the phishingwebsites have caused serious economic loss for the online trading platform and related users.So how to effectively identify phishing sites and reduce the loss of users is becoming more and more important.This paper describes the webpages through such attributes as the URL features,web content,web images features.According to the different types and attributes of phishing webpages,different classifiers are built and then through stepwise discriminantmethod to achieve the purpose of dynamic forecast for thewebpages to be tested.For dealingwith large datasets,SPARK platform isused to calculate the resultsand through the experimental test,good classification resultsare achieved.
phishingwebsite;step-by-step dynamic classification;SPARK Platform
10.3969/j.issn.2095-7661.2017.02.009】
TP393.08
A
2095-7661(2017)02-0030-05
2016-11-16
朱子涵(1989-),男,湖南慈利人,中国移动通信集团湖南有限公司信息安全管理部,北京邮电大学软件学院学士,研究方向:信息安全。
猜你喜欢
成都信息工程大学学报(2021年6期)2021-02-12
小学生导刊(2018年34期)2018-12-18
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2017年2期)2017-05-17
小学生导刊(低年级)(2016年8期)2016-09-24
山东青年(2016年3期)2016-02-28
小学科学(2015年6期)2015-07-01
小学科学(2015年6期)2015-07-01
小学科学(2015年5期)2015-06-08
