
基于统计学的Web论坛增量更新策略研究
2017-07-10 10:27冯凯陈军王鹃王勇
计算机应用与软件 2017年6期
冯 凯 陈 军 王 鹃 王 勇
1(武汉大学国家多媒体软件工程技术研究中心 湖北 武汉 430072)2(武汉大学计算机学院 湖北 武汉 430072)3(武汉大学空天信息安全与可信计算教育部重点实验室 湖北 武汉 430072)
基于统计学的Web论坛增量更新策略研究
冯 凯1,2*陈 军1,2王 鹃2,3王 勇2,3
1(武汉大学国家多媒体软件工程技术研究中心 湖北 武汉 430072)2(武汉大学计算机学院 湖北 武汉 430072)3(武汉大学空天信息安全与可信计算教育部重点实验室 湖北 武汉 430072)
传统预测网页变化的模型将一种规律应用到所有网页之上,没有考虑各页面之间的区别,针对网络论坛索引页面提出了一种基于统计学规律的增量更新策略模型。通过相关论坛版块的索引页面进行数据的采集,观察并证明其变化大致呈现以日为周期的规律性变化,一日之内的变化曲线与人们的生活规律相吻合。然后采用最小二乘法多项式曲线拟合对其进行数学建模,得到合适的数学模型,并将其应用在索引页面的增量更新之上,从而可以准确预测索引页面下一次更新的时间间隔。实验结果表明,该模型在10%误差范围内,预测的准确率为93.9%。
增量更新 网页变化 统计学 数学建模
0 引 言
网络爬虫是用来从互联网上收集网页的程序,一般用于搜索引擎上。互联网上网页千变万化,更新速度快,所以网络爬虫需要获取到最新的页面来替换旧的页面, 更新本地存储。传统的方法是周期性访问网页实现更新,其需要重新下载所有已经下载的网页,而不管该页面是否真的发生变化。该方法不仅浪费爬虫系统资源,还会影响网络带宽,也会耗费一定的时间。由此,产生了对爬虫系统增量更新策略的研究[1]。爬虫系统增量更新主要是指只更新真正发生改变的页面,而未改变的页面不做处理。毫无疑问,该方法大大节约了系统资源和网络资源,提高了爬虫效率。该方法的难点就在于爬虫系统本身如何去判断一个页面是否发生了变化或者其变化程度为多少。
当前的研究主要有两种方法:一是通过实验手段对Web中的数据进行采样,研究样本的变化规律,从而估计整个Web的变化规律[1];二是事先从理论上建立数学模型,并用实验对模型进行验证,得出模型参数,最后利用模型对页面变化进行预测[9]。他们的研究适用于一般性的网站,并且将得到的网页更新频繁度应用到对应网页的任何时刻。但是我们相信不同的爬虫策略应该适用于不同特点和类型的网站,同一网页在不同时刻的更新频繁度也应该不同。本文的工作重点在于对网络论坛增量更新策略的研究。
作为UCC(User-Created Content)的典型代表,网络论坛在搜索引擎、数据挖掘等领域具有越来越重要的作用。沈文勤等[14]利用HTTP的head请求获取页面的元信息,从而避免了整个文件的传输。孟庆浩等[15]提出利用网页的Hash摘要来判断网页是否发生了变化。代鹏等[16]提出使用Simhash算法和汉明距离计算出网页相似度,根据网页相似度计算出网页采集周期。Cai等[17]提出了一种基于学习的论坛采集方法,通过离线分析论坛的总体结构特点,重建网站的站点地图,过滤无效链接,获得有效链接。蔡欣宝等[18]在其基础上,通过泊松模型对网页更新频繁度进行估计,实现论坛增量采集。李莎莎等[19]提出了一种改进的泊松模型,基于更新频率计算窗口、内容分析和网页隶属分析来预测更新时间。张皓等[20]提出基于去噪Hash的增量式网络爬虫,该算法针对经典的Hash算法对文本产生的Hash值过于敏感的问题提出了解决方法,并将其应用在Heritrix上[21]。
Kleinberg等[22]提出将网站页面分为索引页面和信息页面,同时Meng等[8]提出sina网大约0.05%的网页链接到其他20%的网页,20%的网页链接到其他50%的网页,50%的网页链接到其他90%的网页,所以通过对索引页面的观察可以掌握整个论坛网页的变化,如果只对索引页面进行增量监测,判断是否有新的链接,将新链接指向的内容下载下来,并不需要对所有页面进行对比。本文结合人们对网络论坛访问的统计学规律,利用人们生活作息本身的规律性,将当前主要的两种研究方法相结合,通过对论坛索引页面的采样和观察,发现其变化的规律性和周期性,然后采用合适的数学模型去描述该规律性和周期性,最后用该数学模型去预测索引页面下一次变化的时间,并与其他增量更新策略进行比较。实验结果证明,该模型可以有效预测网络论坛索引页面更新的时间,在10%误差范围内,可以获得93.9%的预测准确率。
1 相关定义
现有网络论坛的总体结构一般由多个版块组成,每个版块中又包含多个主题链接。所以,论坛中Web页面根据其功能大致可以分为两类:信息页面和索引页面[22]。前者主要用于展示基本信息内容,多为陈述信息的普通文本。后者则主要用于信息浏览的导航和组织,其内容主要是链接到信息页面的超链接,超链接的变化意味着信息页面也发生了变化,所以通过对索引页面的观察可以掌握整个论坛网页的变化。索引页面是本文的研究对象,参照文献[8],针对该种页面我们有如下定义:
定义1 网络论坛索引页面
网络论坛中包含多个信息页面链接、起信息页面目录作用、变化频繁的网页,我们称之为索引页面(如没特殊说明,文中的索引页面均指网络论坛中的索引页面)。
定义2 索引页面的有效链接数
索引页面是信息页面链接的合集,但是其中一般也包含指向论坛网站其他位置的链接,即噪音链接[23],于是我们将索引页面中除去噪音链接后的信息页面链接的数量称为其有效链接数。
那么我们如何获取一个索引页面的有效链接数?假设我们的爬虫系统在时刻t1获取索引页面a,得到其中全部链接的集合为s1;接着爬虫系统在时刻t2再次获取a,同样得到其中的全部链接的集合为s2。当T=t2-t1大于某一值时,索引页面a的有效链接即为:
s={l|l∈s2,l∉s1}
(1)
其中,s中链接的个数即为索引页面中有效连接的数量。从物理含义上解释,在经过时间T后,索引页面a中信息页面链接全部被新产生的信息页面链接所替换。T的大小与论坛的活跃度相关,一般活跃度越高,T越小,反之亦然。
定义3 索引页面有效链接变化数
对于索引页面a,爬虫系统在时刻t1得到其全部链接集合s1,在时刻t2得到其全部链接集合s2,那么在时间间隔T=t2-t1内,集合s={l|l∈s2,l∉s1}中链接个数n即为索引页面a在时刻t2有效链接变化数。其表示的物理含义是页面a在时间间隔T内产生了n条新的信息页面链接。
定义4 索引页面有效链接变化频率

定义5 索引页面变化率
索引页面a在时间间隔T=t2-t1内的有效链接变化数和索引页面的有效链接数的比值称为a在时间间隔T内的变化率。其表示的物理含义是索引页面a在时间间隔T内的变化程度。
2 策略模型
本节将对索引页面的变化规律作出合理性的假设,并在此假设的基础上对相关的数据进行采样和后处理,然后采用合适的数学模型去描述这种变化规律,最后将说明新建立的模型如何进行应用在索引页面的增量更新上。
2.1 变化规律假设
网络论坛的使用主体是人,人都有一定的生活作息规律,如晚上睡觉、白天上班等。所以,人们生活的规律性使得人们对论坛的访问也具有一定的规律性,进而使得网络论坛本身的更新频率也具有一定的规律性,如睡觉时间段3:00-6:00更新频率较小,上午9:00-11:00更新频率较大等。从而我们知道索引页面变化频率不是一成不变的,而是在一日之内随着时间的推移而发生变化,并且其变化周期为一天(我们将在3.1节中对其进行验证)。
基于这样的规律假设,我们就可以确定索引页面的更新时间间隔不是固定的,而是动态变化的。
2.2 数据采样与后处理


我们对不同天的同一时间的采样数据取平均值(即S中每一列取平均值):
(3)
得到数据集合{(ti,ai),1≤i≤n}。同时:
(4)
其中,ri表示ti时刻索引页面有效链接变化频率,进而可以得到我们的数据集:
Φ={(t1,r1),(t2,r2),…,(tn,rn)}
(5)
基于2.1节的假设,索引网页中有效链接变化频率呈现以日为周期的变化,此为典型的线性变化模型,于是我们采用最小二乘法多项式曲线拟合的方法对训练数据集进行处理,得到我们的数学模型。
2.3 最小二乘法多项式曲线拟合
根据给定的n个点,并不要求所求的多项式曲线精确地经过这些点,而是求一条近似曲线y=f(t)得近似曲线y=f(t)定的实际点之间的偏差最小,这就是线性模型中的曲线拟合[24]。
对于2.2节中的等式对应的数据集,拟合曲线y=f(t)的偏差平方和l为:
(6)
按照偏差平方和最小的准则,即求得y=f(t)使得l最小。
设拟合曲线满足下列多项式:
y=f(t)=a0+a1×t+…+ak×tk
(7)
那么:
(8)
等式为a0,a1,…,ak的多元函数,由此将问题转化为求l=l(a0,a1,…,ak)的极值问题。由多元函数求极值的必要条件,得:
(9)

(10)
进一步化简得到:
(11)
即X×A=Y,从而可以得到系数矩阵A,也得到了拟合曲线,进而得到了我们的数学模型。
2.4 模型应用
由2.3节中式(6)-式(11),我们得到了拟合曲线y=f(t),其表示的物理含义为索引页面有效链接变化频率随时间t的变化。那么索引页面在任意时间段内的有效链接变化数可以通过求曲线y=f(t)的积分来实现。
图1表示的是曲线y=f(t),横轴为时间,纵轴表示的是索引页面有效链接变化频率。那么时刻a和时刻b间隔内有效链接变化数n可以表示为:
(12)
当索引页面变化率达到z时,我们认为该索引页面应该进行更新。令索引页面有效链接的数量为v,我们在时刻a对索引页面进行了更新,下一次更新的时刻b应该满足如下公式:
(13)
从而可以计算出下一次索引页面最合适的更新时刻b。
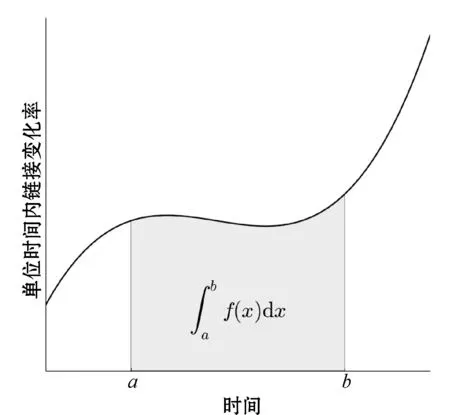
图1 模型应用说明
3 实验设计及结果分析
本节将对2.1节中的规律性假设进行实验验证,对该模型进行测试,并与现有的更新策略进行比较。
所有实验均在Ubuntu14.04机器上进行,机器配置:4 GB内存,Intel Core i7-3612QM处理器,100 MPbs网卡,实验均采用python2.7编码实现。
3.1 规律性验证
我们选取表 1中的四大论坛相关板块作为我们的实验对象,获取版块索引页面的有效链接变化数,并将其转化为有效链接变化频率(单位时间内链接变化数)。考虑到不同版块固有的访问量不同,对应的更新频率也会有所区别,所以我们对不同版块的采样周期也会有所不同。实验环境下,该采样周期通过观察相关版块日更新总数进行确定。

表1 实验使用的网络论坛及采样周期
我们对上述四个板块进行30天的数据采样,并绘制样本数据平均值和方差随样本容量的变化曲线。图 2和图 3分别表示的是样本平均值和方差的变化曲线。图 2横轴表示样本容量,纵轴表示有效链接变化频率的平均值,从中可以看出,不同论坛版块对应的链接变化频率的平均值不同,但是随着样本容量的增加,总体平均值趋向稳定。同时,图 3说明随着样本容量的增加,样本总体方差趋向于稳定。所以,我们可以认为样本对应时间序列是稳定的。

图2 样本总体平均值随样本数量变化曲线图
同时,我们对样本进行FFT变换[25],将其从时域变换到频域,并绘制出图4所示的频谱图。图4横轴表示的频率成分,纵轴表示的是幅值,对其进行主频率成分分析,得到最大幅值对应的频率,得到表2的结果。从表2中可以看出,四个论坛对应的变化周期均约为24小时。

图3 样本总体方差随样本数量变化曲线图
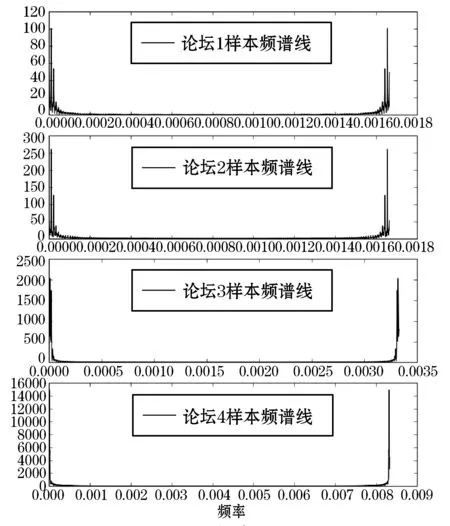
图4 样本频谱图
通过实验我们可知,不同论坛相关的索引页面更新频率不一样,但更新频率的变化大致以日为周期,具有周期性,从而可以通过合适的数学模型来描述这种周期性的变化,为以后的变化趋势做出更好地预测。
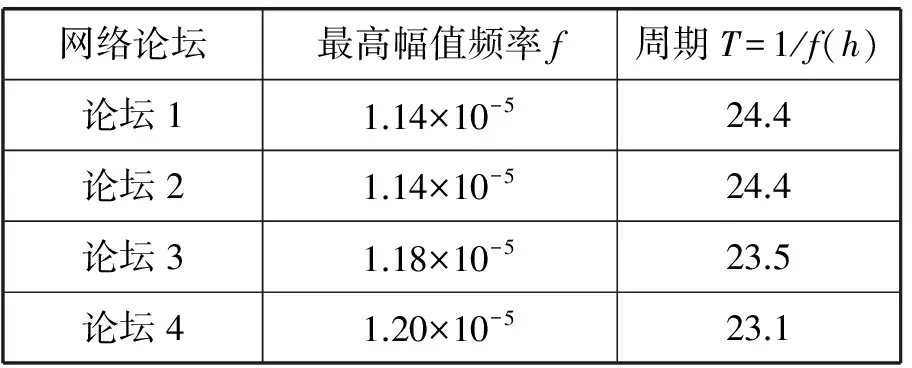
表2 论坛对应幅值频率及周期
3.2 模型测试及对比
从3.1节中我们得到了采集数据,根据2.2节中公式-对数据进行处理,求得平均值,得到如公式所示的采样数据集合,对该集合通过最小二乘法进行多项式曲线拟合,得到预测模型。我们将以论坛2为例进行阐述。
图5显示的是论坛2中公式对应的数据集、拟合曲线和平均变化频率。从该图中可以看出,从23点开始,索引页面链接变化频率开始下降,6:00-11:00为变化频率上升阶段,18:00左右会有小幅度的下降,17:00-22:00会有小幅度的上升,这与一般人们的日常生活规律相符。
为了对该模型进行测试,我们定义公式中的索引网页变化率z为50%[1],其物理含义是当索引网页有效链接变化数达到其全部有效链接数的一半时,我们认为该索引网页应该得到更新,爬虫系统应该去重新获取该网页。从而我们可以不断利用预测模型并结合公式来预测下一次合理的更新时间。同时我们选取下面两种方案作为对比:
• 常规的周期性更新策略,更新周期和采样周期相同,论坛2更新周期为10 min;
• 基于学习的周期性更新策略[26],即不考虑一天之内更新频率随时间的变化,得到总的平均有效链接变化率,从而确定采样周期。
对上述三种方案进行为期10天的测试,得到每次更新索引页面实际的变化率,并与期望的变化率z(50%)进行比较。

图5 索引页面链接变化数学模型
图6-图8表示的是测试结果,横轴均表示时间(HH:MM),纵轴均表示索引页面实际变化率(期望值为50%)。从图 6和图 7中可以看出,与期望的变化率50%相比,常规周期性更新策略和基于学习的周期性更新策略在00:00-09:00的误差较大,09:00-24:00误差率减少,并且后者的误差率小于前者。图 8为作者提出的数学模型对应的实验结果,从中可以看出00:00-09:00更新次数明显减少,这即与人们的生活规律相吻合,同时说明模型的正确性:索引网页变化频率降低时,爬虫系统增量更新的次数也应该降低;此外,索引页面的实际变化率大部分都位于期望值50%的附近。表 3是对图 6-图 8的统计结果。从表中可以看出,策略③相比策略①,平均每天的更新次数减少了27.0%,预测的准确性在A、B、C范围内分别提高了26.0%、65.3%、57.7%,总体而言,预测的准确性大幅提升。策略③相比策略②,平均每天的更新次数增加了26.4%,但是预测的准确性在A、B、C范围内分别提高了18.6%、57.5%、50.7%。总体而言,策略③通过牺牲一定的更新次数,在10%误差范围内,可以获得93.9%的预测准确率,从而为网络爬虫的增量更新确定合适的时间间隔。
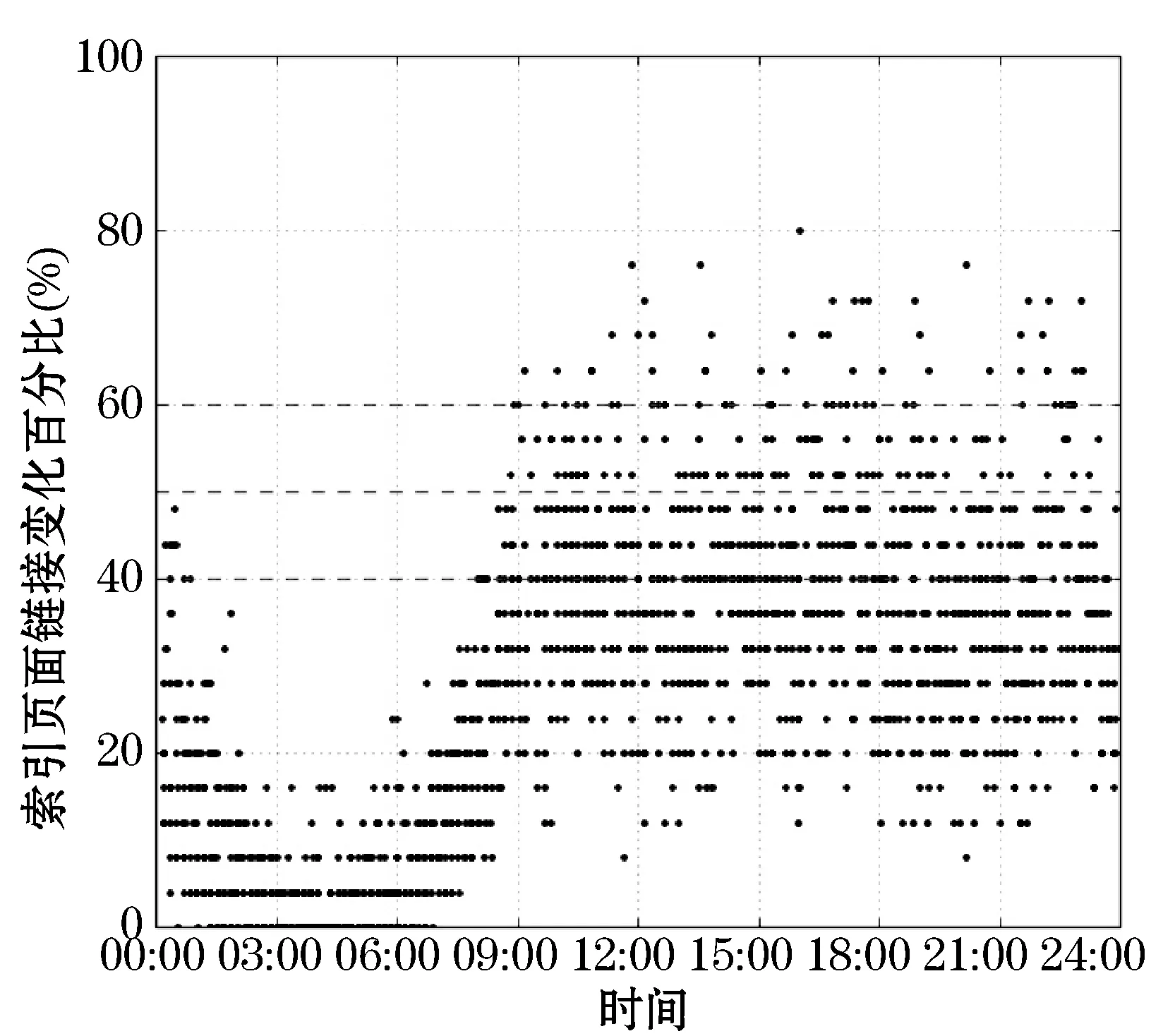
图6 常规周期性更新策略实验结果

图7 基于学习的周期性更新策略实验结果
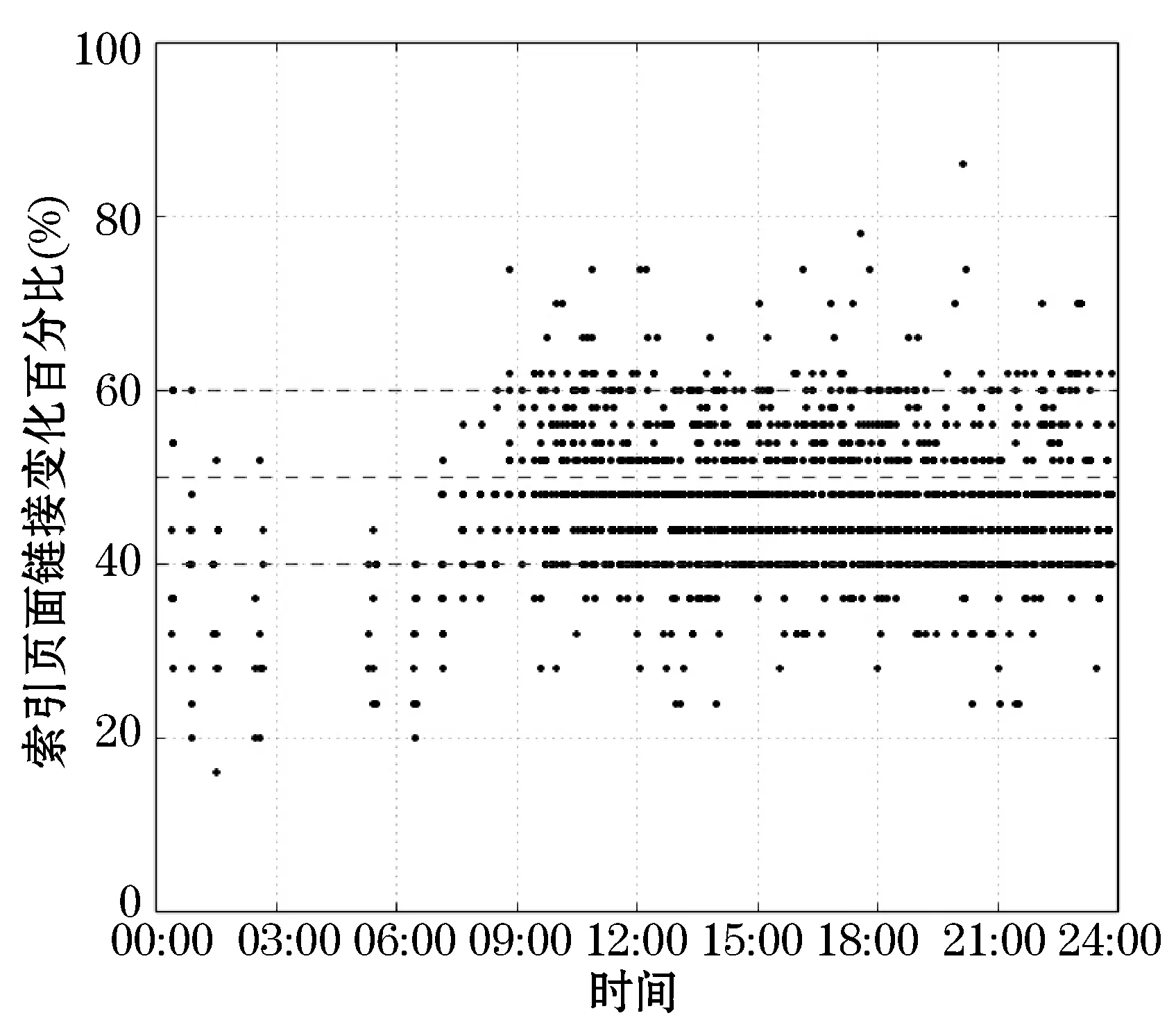
图8 基于数学模型预测的更新策略实验结果
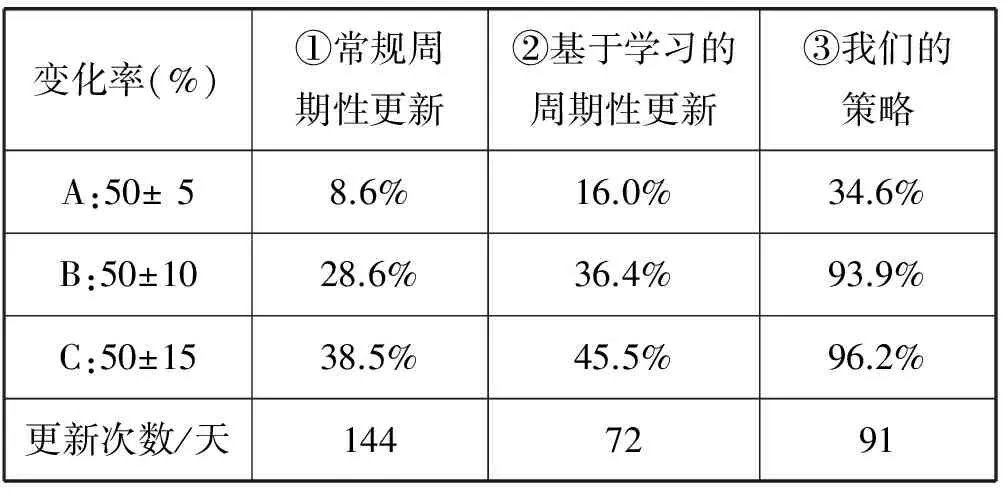
表3 不同更新策略实验结果比较
4 结 语
本文针对网络论坛索引页面提出了一种基于统计学规律的增量更新策略模型。通过对4大论坛相关版块的索引页面进行数据的采集,观察并证明其变化大致呈现以日为周期的规律性变化,一日之内的变化曲线与人们的生活规律相吻合。然后采用最小二乘法多项式曲线拟合对其进行数学建模,得到合适的数学模型,并将其应用在索引页面的增量更新之上,从而可以准确预测索引页面下一次更新的时间间隔。实验结果表明,在10%误差范围内,预测的准确率为93.9%。相比现有的方法,增加了约26%的更新次数,预测的准确率提高了57.5%。因为不同论坛版块访问量不同,导致其更新频率不同,所以不同论坛版块对应的日变化曲线不相同,并且该模型需要对数据进行较长时间的采样,从而限制了该模型在实际场景中的应用。
[1] Junghoo, GarciaMolina, Hector. The Evolution of the Web and Implications for an Incremental Crawler[C]// International Conference on Very Large Data Bases. Morgan Kaufmann Publishers Inc. 2000:200-209.
[2] Douglis F, Feldmann A, Krishnamurthy B, et al. Rate of Change and other Metrics: a Live Study of the World Wide Web[C]//USENIX Symposium on Internet Technologies and Systems. 1997, 119.
[3] Fetterly D, Manasse M, Najork M, et al. A large-scale study of the evolution of web pages[C]//Proceedings of the 12th international conference on World Wide Web. ACM, 2003: 669-678.
[4] Fetterly D, Manasse M, Najork M. On the evolution of clusters of near-duplicate web pages[J]. Journal of Web Engineering, 2003, 2(4): 228-246.
[5] Brewington B E, Cybenko G. How dynamic is the Web?[J]. Computer Networks, 2000, 33(1): 257-276.
[6] Brewington B E, Cybenko G. Keeping up with the changing web[J]. Computer, 2000 (5): 52-58.
[7] Francisco-Revilla L, Shipman III F M, Furuta R, et al. Perception of content, structure, and presentation changes in Web-based hypertext[C]//Proceedings of the 12th ACM conference on Hypertext and Hypermedia. ACM, 2001: 205-214.
[8] Meng T, Yan H, Wang J, et al. The evolution of link-attributes for pages and its implications on web crawling[C]//Proceedings of the 2004 IEEE/WIC/ACM International Conference on Web Intelligence. IEEE Computer Society, 2004: 578-581.
[9] Cho J, Garcia-Molina H. Synchronizing a database to improve freshness[J]. ACM Sigmod Record. ACM, 2000, 29(2): 117-128.
[10] Cho J, Ntoulas A. Effective change detection using sampling[C]//Proceedings of the 28th international conference on Very Large Data Bases. VLDB Endowment, 2002: 514-525.
[11] Ntoulas A, Cho J, Olston C. What's new on the web?: the evolution of the web from a search engine perspective[C]//Proceedings of the 13th international conference on World Wide Web. ACM, 2004: 1-12.
[12] Ipeirotis P G, Ntoulas A, Cho J, et al. Modeling and managing content changes in text databases[C]//Data Engineering, 2005. ICDE 2005. Proceedings. 21st International Conference on. IEEE, 2005: 606-617.
[13] Cho J, Garcia-Molina H. Estimating frequency of change[J]. ACM Transactions on Internet Technology (TOIT), 2003, 3(3): 256-290.
[14] 沈文勤,李庆超,邵志清. 搜索引擎的渐增式爬行和备份式更新模式[J]. 华东理工大学学报, 2004,30( 3): 284-287.
[15] 孟庆浩. 互联网数据增量采集系统的设计与实现[D]. 北京: 北京邮件大学, 2015.
[16] 代鹏. 基于Nutch的增量网页信息采集系统的设计与实现[J]. 软件, 2015, 36(11) : 100-104.
[17] Cai R, Yang J M, Lai W, et al. iRobot: An intelligent crawler for Web forums[C]//Proceedings of the 17th international conference on World Wide Web. ACM, 2008: 447-456.
[18] 蔡欣宝,郭若飞,赵朋朋, 等. Web 论坛数据源增量爬虫的研究[J]. 计算机工程, 2010, 36(9): 285-287.
[19] 李莎莎. 增量式 Web 信息采集与信息提取系统的研究与实现[D]. 武汉: 武汉理工大学, 2011.
[20] 张皓,周学广. 基于网页去噪 Hash 的增量式网络爬虫研究[J]. 舰船电子工程, 2014, 34(2): 86-90.
[21] 张皓, 周学广. 基于 Heritrix 的增量式网络爬虫研究[J]. 软件导刊, 2013, 12(11): 135-137.
[22] Kleinberg J M. Authoritative sources in a hyperlinked environment[J]. Journal of the ACM (JACM), 1999, 46(5): 604-632.
[23] Guo Y, Li K, Zhang K, et al. Board forum crawling: a Web crawling method for Web forum[C]//Proceedings of the 2006 IEEE/WIC/ACM International Conference on Web Intelligence. IEEE Computer Society, 2006: 745-748.
[24] 李航等.统计学习方法[M].北京:清华大学出版社,2012.
[25] Lyons R G. Understanding digital signal processing[M]. Pearson Education, 2010.
[26] 徐文杰, 陈庆奎. 增量更新并行 Web 爬虫系统[J]. 计算机应用, 2009, 29(4): 1117-1119.
RESEARCH ON INCREMENTAL UPDATING STRATEGY OF WEB FORUM BASED ON STATISTICS
Feng Kai1, 2*Chen Jun1,2Wang Juan2,3Wang Yong2,3
1(NationalEngineeringResearchCenterforMultimediaSoftware,WuhanUniversity,Wuhan430072,Hubei,China)2(CollegeofComputer,WuhanUniversity,Wuhan430072,Hubei,China)3(KeyLaboratoryofAerospaceInformationSecurityandTrustedComputingMinistryofEducation,WuhanUniversity,Wuhan430072,Hubei,China)
The traditional model of forecasting page changes applies a rule to all pages, without regard to the differences between pages. In this paper, we propose an incremental updating strategy model based on statistical rules for indexing web pages. Through the data collection and observation of the index page of the relevant forum, it is found that the index page shows a regular change in the daily cycle, and the curve of variation within a day coincides with the law of people’s life. The mathematical model is established by using the least square polynomial curve fitting, and it is applied to incremental updating of the index page, which can predict the time interval of the next updating of the index page. The experimental results show that the accuracy of the model is 93.9% within the 10% error range.
Incremental updating Page changes Statistics Mathematic modeling
2016-05-09。国家自然科学基金项目(61402342)。冯凯,硕士生,主研领域:模式识别与智能系统。陈军,教授。王鹃,副教授。王勇,硕士生。
TP3
A
10.3969/j.issn.1000-386x.2017.06.007
猜你喜欢
房地产导刊(2022年10期)2022-10-18
北京航空航天大学学报(2022年5期)2022-06-06
当代陕西(2022年6期)2022-04-19
当代水产(2021年8期)2021-11-04
现代信息科技(2021年21期)2021-05-07
成都信息工程大学学报(2021年6期)2021-02-12
中学生数理化·中考版(2019年9期)2019-11-25
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2018年2期)2018-04-18
