
基于FPGA的矩阵尺寸自适应的双精度浮点数矩阵乘法器
2017-07-10 07:08朱耀国党皓
电脑知识与技术 2017年14期
关键词:自适应
朱耀国+党皓


摘要:设计了一种基于FPGA的矩阵尺寸自适应的高速双精度浮点数矩阵乘法器。采用了基于XihnxISE中双口RAM及浮点数运算IP核,对矩阵元素进行缓存后,在运算的过程中根据矩阵的尺寸进行自适应处理,可支持矩阵尺寸最大32×32的矩阵乘法;同时通过流水线处理,弱化浮点数运算核自身延迟对设计带来的延迟效应。该设计通过基于TEXTIO的仿真对MATLAB产生的数据进行了运算及检验,验证了设计的功能与性能。
关键词:自适应;双精度浮点数;矩阵乘法器;流水线处理
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2017)14-0085-02
1概述
矩阵乘法在远程通信,网络传输,图像与信号处理等领域中有着广泛的应用。矩阵乘法在这些应用中,不仅需要面对大量的数据,还需要满足高精度与高速度的要求;针对不同的应用场合,被处理的矩阵的尺寸也不同。为了满足矩阵处理高速度高精度,适用于不同尺寸的被处理矩阵的要求,本文介绍了一种基于FPGA的设计,用于处理双精度浮点数矩阵的乘法器,该设计可适用于两个最大尺寸32×32的矩阵相乘,并采用了流水线技术提高运算效率,以满足高速度需求。
IEEE754标准规定了两种浮点格式,32bit单精度浮点数以及64bit双精度浮点数。这两种数据均包括符号位S、阶码E以及尾数M。根据浮点数类型的不同,阶码E和尾数M的位数有所不同。IEEE754标准所规定的双精度浮点数格式如图1所示。
根据IEEE754规定,尾数M隐含了一位数值为1的最高位,双精度浮点数的阶码包含了bias=+1023的偏移量,双精度浮点数的数值可由公式1获得:
2乘法器设计
对于矩阵乘法C=A×B,其中A、B和C分别是M×K、K×N和M×N维矩阵,其计算方法如公式2所示:
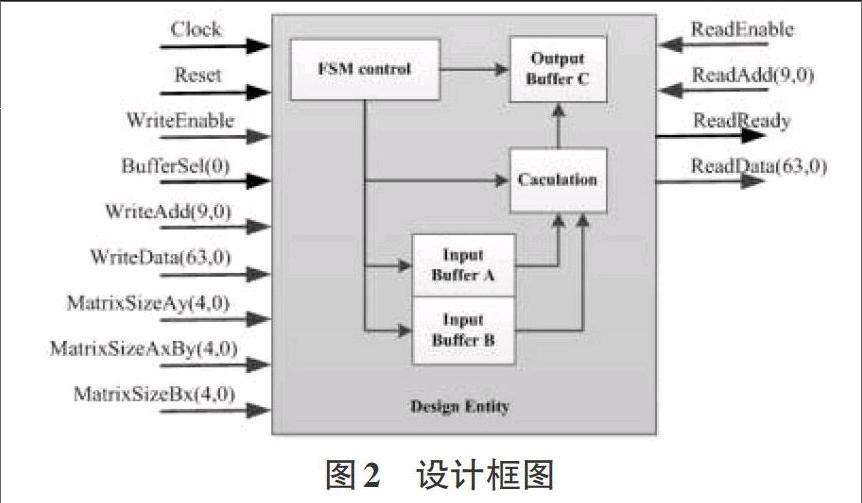
矩阵尺寸自适应的高速双精度浮点数矩阵乘法器的结构如图2所示。设计中,根据输入矩阵的矩阵尺寸对两组输入矩阵A、B进行缓存,并判断输出矩阵的尺寸对结果矩阵C进行缓存;利用有限状态机,对初始、缓存矩阵A、缓存矩阵B、计算、完成提示,这5个状态进行控制。图中的信号分别为:
1)时钟输入Clock;
2)重置输入Reset,写入使能输入WriteEnable,输入缓冲器片选输入BufferSel(0),读取结果的使能输入ReadEnable,指示运算完成的输出ReadReadv;
3)输入矩阵尺寸的输入MatrixSizeAy(4,0),MatrixSizeAxBy(4,0),MatrixSizeAxBy(4,0);
4)10位输入地址总线输入WriteAdd(9,0),64位输入数据总线输人WriteData(63,0);
5)10位輸出地址总线输入ReadAdd(9,0),64位输入数据总线输出ReadData(63,0)。
2.1矩阵尺寸自适应处理
当外部矩阵尺寸提供给算法后,在初始阶段中,算法对输入矩阵A和B的尺寸进行运算;根据运算结果,依次进人缓存矩阵A阶段,缓存矩阵B阶段,在每个时钟周期对矩阵中单个元素进行缓存,分别需MxK和KxN个时钟周期;当完成缓存后,算法进入计算阶段,在每个时钟周期分别从缓存中读取矩阵A和B的元素并进行计算,当矩阵C中MxN个元素均完成计算并被缓存后,进入完成提示阶段;在完成提示阶段中,FPGA输出ReadReady信号,高电平有效,提示外部设备可以对RAM C中的矩阵c进行数据读取。
2.2双口RAM
根据Xilinx ISE 13.4中的Core Generator可对所需的双口RAM进行配置,对矩阵A、B和C的输入缓存及读取。双口RAM的结构图和时序图分别如图3、4所示。其中clka和clkb为共享同一时钟。
2.3双精度浮点数乘法器,加法器
与双口RAM类似,双精度浮点数的乘法器和加法器通过配置相应的IP CORE实现,其结构框图均可由图5表示。
双精度浮点数加法器的工作时序图如图6所示,加法器需要12个时钟周期方可获得计算结果;乘法器的工作时序图与加法器相同,但需要9个时钟周期方可获得计算结果。需要注意的是,如果输入数据是连续的,那么在相应的处理时钟周期后,其输入结果也为连续输出的,且互不干扰,具有流水线处理能力,该要点为本设计的基础。
2.4计算流水化处理
1)矩阵C中单个元素Ci,j的得出,由公式(2)可知,需要K次乘法,以及K次累加(第一次与0累加);因为加法器与乘法器工作均有时间延迟,在完成单个ci,j的所有计算后再进行下一个ci,j的计算,将会将加法器和乘法器空置的时间最大化,效率最低,无法进行流水线处理;
2)为了避免乘法器的空置,将按时钟周期向乘法器提供缓存在Buffer A和B中的数据,在9个时钟周期后,乘法器按时钟依次输出双精度浮点数乘法结果;
3)为了避免加法器的空置,将按时钟周期向加法器提供乘法器的输出及加法器上一轮的累加结果,在12个时钟周期后,加法器依次输出双精度浮点数加法结果;
41加法器可视作一个深度为12的FIFO,在外部再添加一个深度为x的FIFO对加法器的输出进行缓冲,即加法器从输入到输出需要(12+X)个时钟周期;当乘法器按时钟依次对(12+X)个Ci,j各进行1次乘法运算,此时乘法器的输出便可与加法器的输出匹配;
5)当(12+X)个Ci,j的各所需的K次乘法和累加完成后,在各个ci,j的最后一次累加输出时,该数据便可依次缓存至Buf-fer C中;
6)当所有的ci,j还未完成运算,算法会进入下一组的(12+X)个Ci,j的运算,直至得出矩阵C中所有的元素并缓存;
7)完成运算后发出ReadReady信号,提示外部可对BufferC进行读取。
3设计验证
VHDL测试程序以100ns为时钟周期,向设计实体提供控制信号及地址信号,而数据信号为从TXT文件中读取的矩阵A、B的双精度浮点数;当矩阵A、B分别被缓存至设计实体后,测试程序进入等待。当设计实体完成矩阵C的运算后,测试程序接收到ReadReadv的高电平信号,向设计实体提供控制信号及地址信号,开始逐个读取设计实体所得出矩阵C中的元素,写入新的TXT1文件,并同时读取对照组TXT文件中的矩阵CO,将对比结果同时写入TXT1文件。设计验证结果如图8所示。计算过程用时(不含数据缓存)见表1。
猜你喜欢
计算机应用(2016年12期)2017-01-13
中国教育信息化·基础教育(2016年11期)2016-12-27
汽车科技(2016年5期)2016-11-14
中国新通信(2016年16期)2016-10-18
商场现代化(2016年7期)2016-04-27
