
改进的互信息特征选择方法在垃圾邮件检测中的应用
2017-07-10 08:46王禾清
电脑知识与技术 2017年14期
王禾清


摘要:随着电子邮件数据量的不断增大,特征降维成为垃圾邮件检测研究中不可缺少的一环。目前常见的特征选择方法往往针对的是多分类问题,未能针对二分类问题进行特殊化的处理。因此,该文对传统的互信息特征选择方法进行了改进。除了针对其缺少词频信息,引入词频因子外,还针对二分类问题,引入了特征贡献比的概念。实验证明,采用改进的互信息特征选择方法大大提高了垃圾邮件的检测效果。
关键词:垃圾邮件检测;特征选择;互信息;词频因子;特征贡献比
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2017)14-0163-04
近些年,随着电子邮件文本数据规模的不断扩大,特别是特征维数的增大,采用向量空间模型表示的样本数据特征维数高且稀疏,在进行数据处理时占用了大量的存储空间。并且依据这些数据建立数学模型时,数据分析器很容易陷入过学习的状态,得到的模型泛化效果差。为了缓解“维数灾难”带来的种种问题,对原始数据进行降维处理成了文本数据分析过程中必不可少的一个环节。
目前特征降维的措施可以分为两类,一类是特征选择(fea-ture selection),还有一类是特征提取(feature extraction)。但是比较特征选择和特征提取可以发现,前者使用起来比较简单,便于直观地理解所选择的特征;而后者相对前者而言,它由于考虑了特征词之间的关联性,通过映射的方式,将原始高维特征空间中的数据投影到低维空间中,保留了样本中的重要信息。但相较于特征选择来说,其计算方法比较复杂,不易于理解,并且得到的结果也没有前者直观,容易理解。
特征选择研究的重点就是找到用来衡量特征词重要性的评估函数。文献[1-6]中对其中的一些方法进行了比较分析,发现这些方法互有优缺点。如基于文档频率的特征选择方法,它的假设前提是出现频率低的特征所含的信息量较小。但是这个假设是片面的,所以在实际应用中,频率高的特征词可以是一些停用词,如中文邮件中常见的“你”、“我”等代词。信息增益从信息论的角度出发,以某个特征针对分类系统的信息增量作为评价标准来选择有效特征,构成特征子集。但是它只考虑了某个特征对整个数据集的有效性,而忽略了某些只针对于某个类别的特征。互信息常用于衡量变量之间的相关性。在处理特征选择的问题中,它则用来度量某个特征词与某个类别之间的相关性。当某个特征词与某个类别的相关性很大的时,这个词的互信息值就会很大,反之,这个词的互信息值就会很小。互信息的不足之处在于它忽略词频信息,受特征词的边缘概率影响较大,容易偏向低频词。卡方统计量是通用计算实际值与理论值的偏差来评估理论的正确与否。在进行文本特征选择时,一般首先假设“某个特征词与某个类不相关”,然后计算该假设卡方统计量。其值越大,说明原假设与正确结果的错差越大,因此与原假设相反的结果成立的可能性就越高。但是由于它的计算中只考虑该特征词是否出现在样本文本中,忽略了其出现的次数,同互信息一样,夸大低频词的作用。期望交叉熵则是一种对特征词与样本集之间关联度的权衡。它通过计算存在某个特征词的条件下类别概率分布与不存在某个特征词条件下的类别概率分布之间的差值来评估特征词对于样本集的重要程度。如果某个特征词的期望交叉熵越大,则其对样本集的类别分布的影响就越大。它与信息增益的不同之处在于只计算某个特征词未出现在样本中的情况,忽略了特征词不出现的情况。
上述特征选择方法除了上述提到的缺点之外,还普遍存在一个问题,即这些传统的特征选择方法主要针对的是多分类问题,未对文本分类中存在的特殊情况,如垃圾邮件检测等二分类问题做特殊化的处理。因此如何对传统的特征选择方法进行改进,使之能够更好地处理垃圾邮件检测这种二分类问题是本文研究的重点。
本文以首先对邮件特征选择的特点进行了分析,然后在传统互信息特征选择方法的基础上提出一种改进的互信息特征选择方法,随后通过实验验证该方法的可行性,最后对全文进行了总结。
1邮件特征选择的特点
垃圾邮件过滤问题实际上是一个典型的文本二分类问题:假设存在一个邮件样本d,经过分词处理之后,文本d被表示为由n个特征词(设为t1,t2,t3,…,tn)构成的集合。垃圾邮件过滤即是判定d是否属于Ck(k=1,2)的过程,其中G表示垃圾邮件类,C2表示非垃圾邮件类。
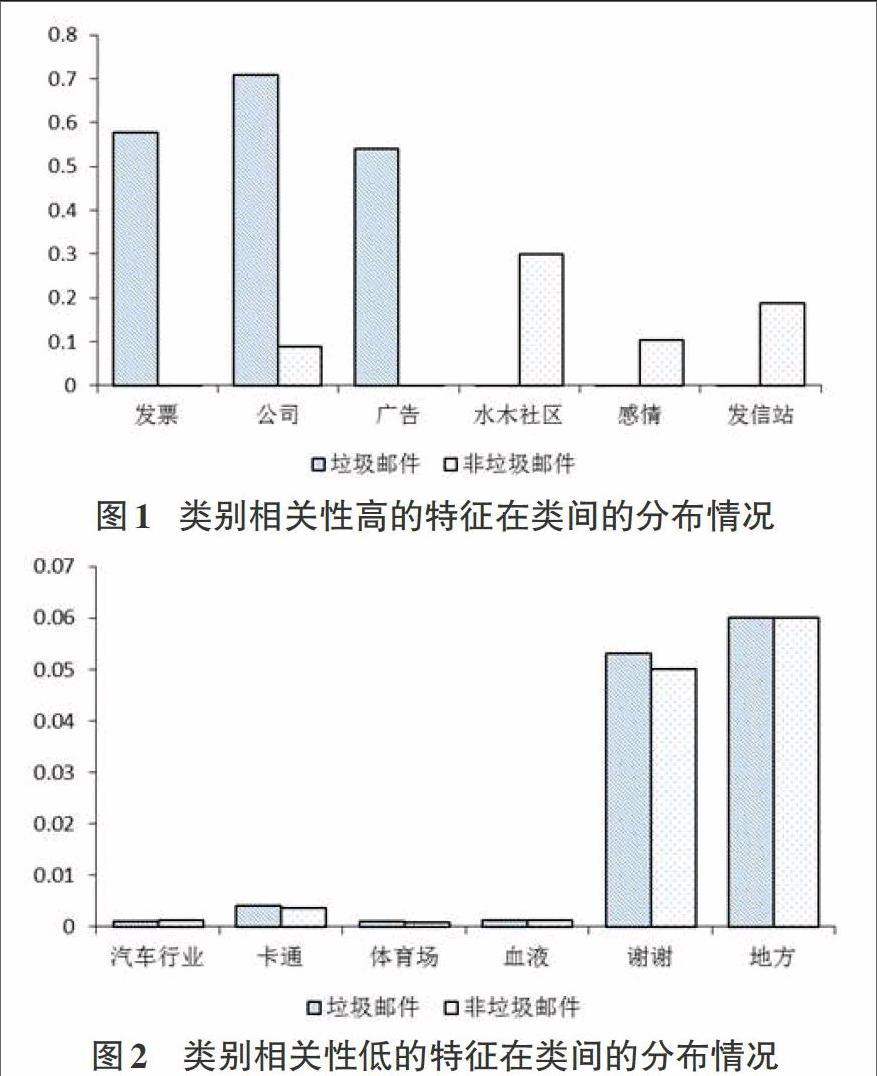
为了能够清晰地显示出邮件数据集中一些特征词与类别之间的关系,本节特别挑选了一些类别相关性比较高的词和类别相关性比较弱的词,统计这些特征在各类间的分布情况,如图1和图2所示。这两个图是根据从CCERT提供的中文垃圾邮件语料库提取出的某些类别区分能力较强和类别区分能力较弱的特征在垃圾邮件中和非垃圾邮件中的分布所绘制的(其中垃圾邮件4000封,非垃圾邮件4000封)。图中x轴坐标表示特征,Y轴坐标表示特征在不同类别中的文档频率(DF)。
分析图1和图2可以发现,与垃圾邮件类别相关的特征,如发票、公司、广告等。它们在垃圾邮件类中分布较为密集,而在非垃圾邮件类中分布较为稀疏。同理,与非垃圾邮件类别相关的特征,如水木社区、感情、发信站等。它们在非垃圾邮件类中分布较为密集,而在垃圾邮件类中分布较为稀疏。但是与两个类别都不相关的特征,如汽车行业、卡通、体育场、血液、谢谢、地方等。这些特征的分布对类别不敏感,在垃圾邮件类和非垃圾邮件类中都呈现较为稀疏状态。
文献认为在文本分类中,樣本特征词的频度、集中度以及分散度对分类效果都有着极其重要的影响。
其中,频度指的是特征词在某一类别中出现的次数。通常某特征词在某一类别中出现的次数越多,该特征词与此类别的相关性就越大,越应该被选人最优特征子集中。特征词频度其可以用词频TF(Term Frequency)来表示。
集中度通常指含有此特征词的类别个数。通常认为包含某特征词出现的类别越少,越说明该特征词与这些类别之间存在很强的关联性。
分散度指的是某类别含有某特征词的文档数目。通常分散度越高,越说明该特征词均匀分布在某类别中,该特征词也越能代表此类。
它们三者之间不是一种松散的关系,而是一种相互补充、相互促进的关系。如果存在这样一个特征词,尽管其频度很高,但是它频繁出现在不同的类别中,因此其并不能很好地代表某一类别,典型的如停用词。还有一些特征词,它确实只出现在单一类别中,但是它的频度很低,与类别的相关性并不高,因此它也不应该被选人最优特征子集,典型的如低频词。
从图1中可以发现,“发票”、“公司”、“广告”等特征词频度较高,分散度也较高。其集中分布于垃圾邮件中,在非垃圾邮件中分布较少,所以在做特征选择时优先选择这些特征加入最优特征子集;“水木社区”、“感情”、“发信站”等特征词虽然词频不高,分散度亦不高,但它们集中分布于非垃圾邮件中,所以在做特征选择时也会优先选择。但对于图2中的特征词,尽管其中存在某些特征词频不低,并且其分散度也很高,但其不仅在垃圾邮件类别中表现出较为集中的状态,同样也集中出现在非垃圾邮件类别中,使得其在不同类别中出现的比例呈现一种均衡的状态。对于这样的特征词,它们对分类效果的影响不大,不应该被选人最优特征子集。因此,如何从特征词的频度、集中度以及分散度三个角度出发,改进传统的特征选择方法,是研究的重点。
2改进的互信息特征选择方法
互信息方法作为常用的特征选择方法,有着实现简单,时间复杂度相对较低,易于理解的优点。但是它也存在一些不足,如前面所提及的受某个特征词的边缘概率影响较大,未能有效地引入特征词的词频信息,对特征词的集中度也未能进行很好的评估等等。
针对互信息存在的不足,很多研究者提出多种改进措施,比如在传统互信息方法上引入若干参数进行调节,以达到改进互信息方法的目的。还有将互信息方法与其他特征选择方法相结合,进行优势互补,以期达到更优的效果。但是这些改进方法并没有对特征词与类别之间的正、负相关性进行很好的评估,并且这些方法一般针对的是多分类问题,未能对于二分类问题进行特殊的处理。因此,针对目前各种互信息的改进型算法存在的不足,本小节在互信息方法除了引入词频信息外来降低在特征选择过程中特征词的边缘概率对特征词的影响,還针对二分类以及特征集中度问题,提出一种基于特征贡献比的改进互信息特征选择方法。
2.1互信息特征选择方法
猜你喜欢
计算机应用(2016年10期)2017-05-12
电子制作(2017年23期)2017-02-02
光学精密工程(2016年2期)2016-11-07
电测与仪表(2016年23期)2016-04-12
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
电测与仪表(2015年9期)2015-04-09
弹箭与制导学报(2015年1期)2015-03-11
振动工程学报(2014年4期)2014-03-01
