
一种并行化的分类算法研究
2017-07-15 15:05李慧彦
智能计算机与应用 2017年3期
李慧彦


摘要:研究并实现TJIT Spark的KNN算法的并行构建。分析了MapReduce模型和Spark在处理迭代计算方面的优劣,结合KNN算法的自身特点设计了对应的Map算子和Reduce算子,实现了KNN算法的spark并行化。实验结果表明,较传统的KNN串行算法和MapReduce并行KNN算法,基于Spark的并行KNN分类算法具有较好的效率和较高的可扩展性。
关键词:Spark;KNN:MapReduce
0引言
随着信息技术的发展,在电子商务、科学研究和互联网应用等领域积累了海量的数据资源,而且数据量正呈现激增态势。从海量的数据中寻获有意义的信息以提供更佳体验,必须采用有效的数据挖掘技术,其中K-Nearest Neighbor(KNN)算法是时下常用的一种数据挖掘算法,但KNN计算的时间复杂度较高,在大數据处理面前,则难掩效率逊色的不争事实。目前,许多学者采用MapReduce进行KNN算法的并行化构建,执行效率则得到了显著提高。MapReduce计算框架对迭代计算缺乏一种特性支持,即在并行计算的各个阶段提供重要的数据共享时,Map函数需要将中间结果写入到磁盘,而Reduce函数在进行读取时将增加了磁盘IO。基于此,本文即主要结合KNN算法的自身特点展开了Spark技术在KNN算法上的应用研究。
1Spark简介
Spark是伯克利大学在2012年提出的一个基于内存的分布式计算框架,其核心是弹性分布式数据集(ResilientDistributed Datasets,RDD),这是对集群上并行处理数据的分布式内存的抽象。spark是一个大数据分布式编程框架,具有Map算子、Reduce算子以及计算框架,能够实现任务调度、RPC、序列化和压缩,同时还可为运行在其上的上层组件提供API。由于引进RDD概念,Spark可以在计算中将中间输出和结果分布式缓存在各个节点内存中,并且允许用户进行重复使用,省去了磁盘大量的IO操作,从而大幅缩短了访问时间。
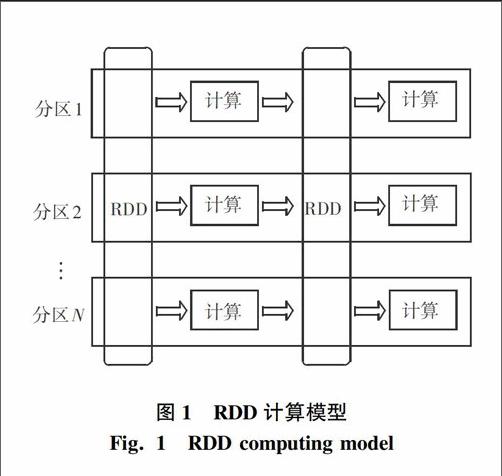
RDD可以看作是对各种数据计算模型的统一抽象,Spark的计算过程主要是RDD的迭代计算过程,具体如图1所示。spark应用在集群上以独立的执行器运行在不同的节点上,主程序中以SparkContext对象来设计展开总体调度。目前,YARN、Mesos、Standalone、EC2等都可以作为Spark的集群资源管理器,集群资源管理器的作用可描述为在不同Spark应用间掌控处理资源分配。集群资源管理器主要用于资源的分配与管理,就是将各个节点上的内存、CPU等资源分配给应用程序以尽可能实现数据的本地化计算。运行架构即如图2所示。
