
基于用户偏好和K-means聚类的可信云资源选择算法
2017-08-07 15:01哈登喆袁伟涵袁伟珵衡水第一中学
大陆桥视野 2017年12期
哈登喆 袁伟涵 袁伟珵/衡水第一中学
基于用户偏好和K-means聚类的可信云资源选择算法
哈登喆 袁伟涵 袁伟珵/衡水第一中学
当前云平台上丰富的云资源和各类云服务吸引了大量的云用户。在云资源可信程度参差不齐的情况下,可信云资源能够量化显示云资源的可信程度,但用户的偏好各异。如何针对不同的用户偏好选择符合用户偏好的云资源是一个亟待解决的问题。首先采用极差标准化方法对多维属性的云资源集合进行归一化处理,然后在用户偏好基础上利用K-means算法对云资源进行聚类,从最贴近用户偏好的一类中选择最贴近的资源,为用户选择出最贴近其偏好的可信云资源。最后用仿真实验验证了该方法的有效性。
云资源选择;可信云资源;用户偏好;K-means聚类
当前,云服务已经深入人们的日常生活,并有很多用途,如:云相册、云邮件、云盘等。以百度的云服务帐户为例,可以将自己手机里的照片备份到云盘,并能够随时拍照、随时同步的便利——百度云服务使得我们不用担心照片会丢失,也不用担心手机的存储空间不够。云计算架构能够整合网络上的各类资源,能够为云用户提供按需服务。其中“云服务代理”技术更是受到普通用户的欢迎。由于大多数普通用户需求不高,可通过云代理把来自用户的服务请求整合在一起,向云服务提供商统一购买服务,这样可以降低云服务的使用成本,使普通用户能够享受“团购价”。云服务代理为了提高服务质量,通常会租用一些多余的资源作为预留资源,以帮助长期使用云服务的用户节省开支,而云资源预留方法的好坏,将直接影响到云代理的服务质量。
云资源预留是目前云服务代理中的研究热点,其目的是在节约成本的同时提高预留质量。当前的方法主要有两类:(1)基于统计学的方法,利用随机过程研究如何租用预留资源和按需预留资源使得花费最少;(2)基于预测的方法,对用户的需求进行预测,基于预测的结果,对云资源进行动态预留。文献[1,2]提出了云计算环境下提供符合用户个性化需求的可信服务推荐的方法。其中,提出了两种偏好相似度计算方法,后利用用户间的偏好相似度为目标用户找到可信任的历史用户。文献[3,4,5,6]研究了用户偏好或资源预留方法。其中,文献[4]提出了一种基于信誉属性的动态云资源预留方法,文献[5]给出了一种云服务提供商的信任评估框架,文献[6]提出了一种云服务中基于偏好的云服务预留方法。但是,未见文献研究基于用户偏好的云资源选择选择算法。
我们在前期完成了将信任评估引入到云服务代理中的工作,为平台中的云服务给出了信任值。但云资源可从价格、质量、及时性等多个维度进行描述,不同的用户对拟使用的资源具有不同的偏好。例如,有的用户偏好质量好的服务,有的用户偏好价格低的服务,有的用户偏好及时性高的服务等。因此,需要结合用户特定的、主观的偏好,为云服务代理研究更符合用户需求的云服务资源选择方法。为此,依据用户偏好和云资源的信任值,利用K-means方法对可供预留的云资源进行聚类,从最贴近用户偏好的云资源中选择信任值最高的云资源作为预留资源。
本文的结构是:第1部分给出作者已经完成的云服务的可信评估模型和用户偏好的定义;第2部分给出面向用户偏好的云服务综合信任值计算方法;第3部分给出基于线性极差变换的云服务信任值归一化方法;第4部分给出基于用户偏好和K-means算法的可信云资源选择算法;第5部分为仿真实验;第6部分是结论。
1.云服务的可信评估模型和用户偏好
鉴于云服务的多维属性,如:价格、质量、及时性等,我们对每个云服务给出了其各个维度上的信任值,建立了如下信任评估模型:

假设有m个云服务,每个云服务有n个属性,则这m个云服务的信任值可表示如下:

其中m表示云服务的个数,n表示云服务的属性个数,aij表示第i个云服务第j个属性的信任值。
定义2. 用户偏好. 用户偏好指用户对云服务的各属性的偏好程度,可形式化表示为如下的n维向量:
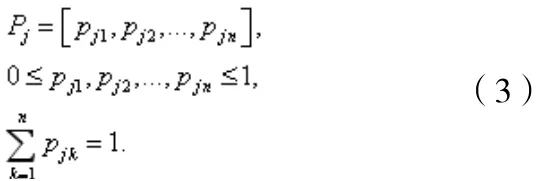
2.面向用户偏好的云服务综合信任值计算方法
公式(1)给出的是一段时间后云服务各属性的信任值。然而,由于用户所偏好的属性不同,不同偏好的用户利用公式(1)得到的对该云服务的综合信任值是不同的。因此,我们给出面向用户偏好的云服务综合信任值计算公式如下:

其中,trustij表示用户j对依据云服务i的n维属性评估值,结合用户j的用户偏好,得出的对服务i的综合信任值;tik表示用户j对服务i的第k个属性的信任评价值;pjk表示用户j对第k个属性的偏好值。
当学生具备了一定的发现和提出问题的能力之后,教师应减少引导,不要直接将学生引入教师预设好的问题,应让学生自主思考,探究自己想探究的问题。在提出问题阶段,可以先不考虑实施的可行性,鼓励学生发散思维,天马行空,提出尽量多的丰富多样的探究问题。之后,再考虑实际情况,评估确定几个在学校条件下可行性高的探究课题,组建课题小组。
3.基于线性极差变换的云服务信任值归一化方法
通过公式(1)可知,云服务的信任值是一个n维向量, 向量中的每个元素表示的是云服务特定属性的信任值。但是各个属性的信任值可能取值差异很大。例如,存在某云服务,用户对其质量属性的信任值评价普遍较高(如0.9);而用户对其价格属性的信任值评价普遍比较低(如0.4)。这样,由于云服务个属性的单位和量纲可能不一样,从而导致绝对值大的属性占主导作用,而绝对值小的属性不起作用。为了避免这种情况的发生,采用线性极差变换对公式(1)中的原始数据进行标准化,标准化公式为:
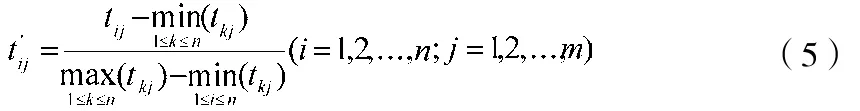
云服务每个属性的信任值,经过公式(5)的标准化处理以后,不同属性的信任值就具有了可比性。
4.基于用户偏好和K-means聚类的可信云资源选择算法
云服务的各个属性信任值标准化使得各属性具有了可比性,因而进一步以用户偏好作为权重,计算云服务针对特定用户的综合信任值,从而选择综合信任值最高的云服务作为该用户的预留云资源。
但云平台上预留云服务具有以下特点:
(1)云服务的规模通常很大,从中选择信任值最高的云服务,需要比较n-1次;
(2)由于存在大量的云用户,使得为某用户选择出的云服务可能被其他用户预留成功,因此经常会发生需要重新选择资源的情况。
考虑到上述两个特性,本文按照用户偏好,基于K-means聚类算法对云平台上的云服务进行聚类。算法的流程图如图1所示。

图1 基于用户偏好和K-means聚类的可信云资源选择算法
图1所示的流程为:
(1)由用户输入个性化偏好,其中用户偏好的定义参见定义2;
(2)对每个服务:以用户偏好(见公式(3))为权重,计算经过标准化处理后的各属性的信任值(见公式(5))的加权和(见公式(4)),以该加权和作为该服务针对该用户的综合信任值;
(3)输入要聚类的类别数;
(4)调用K-means聚类算法,对经过第(2)步处理后的各服务的综合信任值进行聚类,将其聚成第(3)指定的类别数;
(5)依据聚类算法算出的各个类别的距离值,选取距离最小的一类,作为要为用户选择预留云资源的一类,将该类别记为A;
(6)从A中选择综合信任值最高的一个云服务作为要预留的云资源。
算法伪代码如下所示:

其中,从A中选择最大值的算法如下:

5.仿真实验
本文用Eclipse实现第4节所构建的算法,并用仿真数据来验证基于用户偏好和K-means算法的可信云资源选择算法的有效性。
5.1 仿真实验数据
本文用Python的随机数生成API来生成实验的仿真数据,每个云服务有两个属性的信任值,仿真了1006个云服务、每个云服务两个属性(质量和及时性)的信任值。由于篇幅所限,整理其中的40条数据如表1所示。
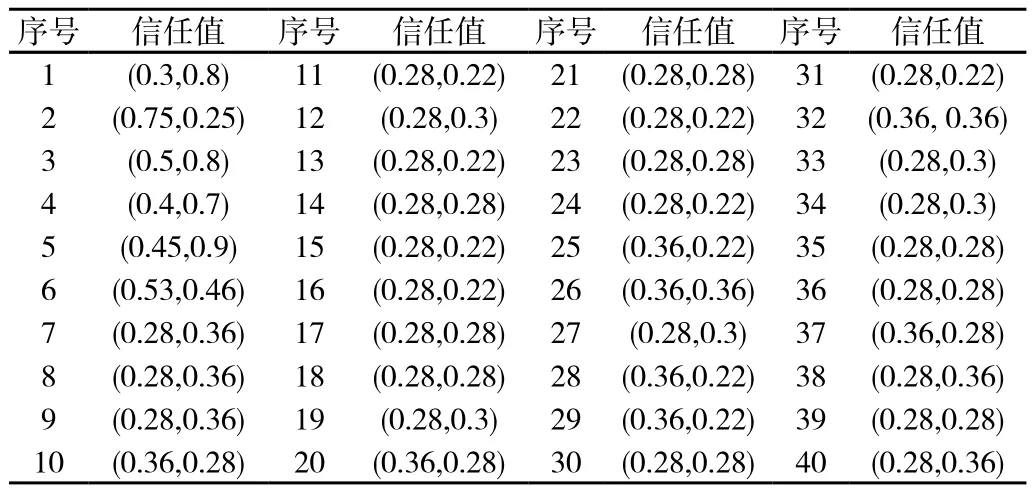
表1 40个云服务的信任值仿真数据
表1中的每个云服务的信任值,是由两个属性信任值构成的二维向量。本实验将两个属性信任值的用户偏好分别设为0.6和0.4。
5.2 聚类结果及分析
结合用户偏好,采用第4节建立的基于用户偏好和K-means聚类的可信云资源选择算法对1006条数据进行聚类,结果如图2所示。

图2 聚类结果
图2的横轴表示资源的质量属性的可信值,纵轴表示及时性属性的可信值,每个点表示一个云资源,曲线圈起的范围为本文所给的分类方法的分类结果。可以看到,共分成了3类。六个离群点也被分到了这3个类别中。注意,图中有些点重合在了一起,因此显示起来没有1006个云资源那么多。
将这些分类结果与人工分类结果比对发现,该方法的分类结果与人工分类结果相符。这说明:本项目给出的基于用户偏好的云资源分类方法能够有效依据用户偏好对云资源进行分类。
6.结论
本文针对如何为用户选择个性化云服务资源的问题,采用线性极差标准化方法对云资源属性的可信值进行归一化处理,并采用K-means方法对云资源进行聚类,并从最贴近用户偏好的云资源中选择信任值最高的云资源作为预留资源。实验结果表明,本文所提方法有效。此外,该方法在实际应用中的模糊用户偏好的表征问题,还有待进一步研究。
注:本文为第三十二届河北省青少年科技创新大赛一等奖(基于用户偏好的可信云资源预留方法,未公开发表)的部分内容经修改完善而成。
[1] 杜瑞忠,田俊峰,张焕国. 基于信任和个性偏好的云服务选择模型[J]. 浙江大学学报(工学版), 2013,01:53-61.
[2] 侯震. 基于多等级方案成对比较的云服务提供商选择研究[D]. 合肥工业大学, 2015.
[3] 孟顺梅. 云计算环境下可信服务组合及其关键技术研究[D].南京大学, 2016.
[4] 董娜. 基于信誉属性的动态云资源预留[D]. 河北大学,2013.
[5] Habib S. M., Varadharajan V., Muhlhauser M., et al. A framework for evaluating trust of service providers in cloud marketplaces[C]. Acm Symposium on Applied Computing, 2013: 1963-1965.
[6] Ioannis P.,Yiannis V.,Gregoris M. Preference-based cloud service recommendation as a brokerage service [C]. CCB’ 14 Proceedings of the 2nd International Workshop on Cross Cloud Systems,2014, 8.
哈登喆,男,衡水第一中学,在读高二学生,研究兴趣:云代理相关技术。
袁伟涵,女,衡水第一中学,在读高二学生,研究兴趣:云代理相关技术。
袁伟珵,男,衡水第一中学,在读高二学生,研究兴趣:云代理相关技术。
Cloud resources and various types of cloud services are attracting a large number of cloud users. A wide range of cloud resources whose trustiness is uneven, the trusted cloud resources can quantify the credibility of cloud resources. However, the user preference is various. This paper solves the problem that how to choose the most suitable cloud resources for different user preference. In this paper, the K-means algorithm is used to cluster the cloud resources on the basis of user preference, and choose the closest to the user preference. The simulation experiment is used to verify the effectiveness of this method.
Cloud resources selection; Trusted Cloud Resources; User preference; K-means clustering
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小学生学习指导(低年级)(2021年12期)2021-12-31
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
小学生学习指导(低年级)(2018年11期)2018-12-03
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
桃之夭夭B(2017年2期)2017-02-24
互联网天地(2016年1期)2016-05-04
高中生·青春励志(2014年11期)2014-11-25
