
Crypt-JDBC模型:洋葱加密算法的优化改进*
2017-08-16 11:10田秀霞袁培森金澈清
计算机与生活 2017年8期
陈 鹤,田秀霞,2,袁培森,金澈清+
1.华东师范大学 计算机科学与软件工程学院 数据科学与工程研究院,上海 200062
2.上海电力学院 计算机科学与技术学院,上海 200090
3.南京农业大学 信息科技学院,南京 210095
Crypt-JDBC模型:洋葱加密算法的优化改进*
陈 鹤1,田秀霞1,2,袁培森3,金澈清1+
1.华东师范大学 计算机科学与软件工程学院 数据科学与工程研究院,上海 200062
2.上海电力学院 计算机科学与技术学院,上海 200090
3.南京农业大学 信息科技学院,南京 210095
CryptDB是一种典型的密文存储技术,它根据运算操作语义使用洋葱加密算法将SQL语句改写到不同的洋葱密文列,从而仅暴露数据的部分属性即可执行查询任务。针对洋葱加密算法的不足之处提出了一种名为Crypt-JDBC的改进模型:(1)鉴于洋葱层数多,且相邻层功能差异大,新模型把洋葱列分为主列与辅助列,并压缩洋葱层的改进方法(主列使用双向算法可还原明文,辅助列使用单向算法提供属性,保证安全性);(2)鉴于等值连接算法复杂低效,新模型通过简化一个关键模块(差异性转换)来降低复杂度;(3)鉴于列名的明文、密文名称对应性弱,新模型重新设计了明密文列名称的对应关系,减少了上下文信息,加强了密钥整体性。实现了Crypt-JDBC模型,用JDBC替换中间件软件MySQL-Proxy。实验结果表明,该模型具有较高的执行效率。
CryptDB;加密数据库;Crypt-JDBC模型;洋葱加密算法;密文数据库
1 引言
随着计算机技术的快速发展和因特网的普及,数据管理技术得到迅速发展,各种互联网应用和云端应用蓬勃发展,这增加了数据被盗的风险。
在相当长一段时间内,数据以明文形式存储在数据库中,并通过防火墙、安全口令等方式来确保数据安全。然而,黑客可以通过窃取数据库用户的账号与密码来访问数据,因而无法绝对保证数据安全。
更新型的数据保护方法则利用现代密码学成果,以全密文方式存储关键数据。当数据拥有者查询数据时,需完全解密密文数据,才能够得到明文信息。在这种情况下,即使黑客破译了数据库用户的账号与密码,也只能够获取密文数据,而无法还原出真实信息,从而有效地保证了数据安全。
然而,上述数据管理方式需要不断解密密文,从而显著地降低了执行效率。因此,一些学者也在探索能否直接基于密文数据来执行典型的数据库查询。
2011年,美国麻省理工学院的Popa等人提出了CryptDB,允许用户在前端以明文方式定义查询和接收结果,后端所有的运算操作均直接由密文承载。这种新型的类全同态加密方式使用了洋葱加密算法,把明文列分拆为多密文列,且各列承载不同的多密文层结构。CryptDB通过这种改写SQL语句的方式来完成密文的查询操作,包括Eq密文列对应等值比较(对称加密算法)操作,Ord密文列对应大小比较(OPE算法)操作,HOM密文列对应求和、求平均(paillier同态加密算法)操作,Search密文列对应模糊查找操作。Popa把这种SQL语句的改写方法称作洋葱加密算法。
然而,CryptDB所涉及的洋葱加密算法仍然存在以下几点不足:(1)多层密码层的设计并不能起到安全性的叠加,且上下层间属性差异性较大,存在密码层间继承性的冲突;(2)有些洋葱密码层(如等值连接层EqJoin、大小连接层OrdJoin)的实现方式复杂且低效;(3)明文列与密文列没有对应关系和转化方式,增加了SQL语句改写时对上下文信息的依赖。
本文的主要贡献如下:
(1)提出了压缩洋葱层、扩展洋葱列的设计,把洋葱层分为主列和辅助列(前者使用双向密码算法可还原明文,后者使用单向密码算法保证运算功能和安全性),解决了洋葱层冗余与上下密码层差异性较大的不足。
(2)提出了新的等值连接Eq_Join算法,简化原算法的两部分操作(确定性转化与差异性转化),并提高RND层参数IV的利用率,从而提高性能。
(3)提出了新的明密文列转换设计,减小了执行SQL语句时对上下文信息的依赖性,规范了密钥管理接口,使中间件仅存储密钥信息,解决了原算法SQL执行时前后查询语句耦合度高的问题。
本文组织结构如下:第2章介绍相关工作;第3章详细说明洋葱密码算法存在的问题和改进想法;第4章提出了Crypt-JDBC的设计思路,给出了一些改进方法;第5章针对CryptDB与Crypt-JDBC进行了实验对比;最后总结全文并展望未来工作。
2 相关工作
密文数据库已经被研究了相当长一段时间。早期工作主要通过对数据进行加密来存储,并且在进行每次查询时,再对数据进行解密来获取查询结果。这种方式简单明了,但是效率低下。另一类代表性工作是同态加密算法,其目标是设计出能够在密文上执行的全同态操作方法。但是这种方式仍处于研究之中,没有较好的解决办法。CryptDB提供了一种均衡的解决办法,它没有使用太过复杂的理论化加密方法,也没有执行效率低下的全解密过程,是一种使用多个现代密码学算法的动态调整查询语句指令的算法。
2.1 CryptDB
Pola等人在2011年提出了CryptDB的概念,并开源了其代码[1-3]。其使用开源软件MySQL-Proxy充当上下层交互的媒介,来操控和改写从前端接收到的SQL指令与后端返回的结果集合。MySQL-Proxy提供了lua脚本接口,可通过C链接库对lua脚本的逻辑进行扩充。CryptDB使用了脚本中预设的4个函数接口,包括read_auth()、disconnect_client()、read_query(packet)、read_query_result(inj)。其脚本函数的触发调用时机分别是:读取客户端的认证信息时调用,失去客户端连接时调用,代理收到客户端的查询请求时调用,收到MySQL的返回结果集合时调用。
在文献[4]中,Popa等人提出了洋葱加密算法,其主要思想是:把一个明文列(column)分拆成多个密文列(field),并在每个列上以洋葱加密的方式层层加密value值,当执行SQL语句时,改写该查询语句并在密文数据上执行(为了简单起见,本文称明文列为column,密文列为field)。如图1所示,洋葱加密算法本质上是一种改写SQL语句的方法,根据运算属性的不同,动态地选择改写方式。
2.2 L-EncDB
Li等人在2015年提出了L-EncDB[5],使用保存格式加密算法(format-preserving encryption)、模糊查询加密算法(fuzzy query encryption)、保序加密算法(order-preservingencryption)来解析不同的SQL语句。
L-EncDB结构如图2所示。不难看出,L-EncDB的结构与CryptDB相似,也使用多密码学算法承载了明文的不同运算属性。
2.3 MrCrypt
Tetali等人在2013年提出了MrCrypt,定义了特定的同态加密模式,以在密文上执行特定的运算,如加法同态pallier、乘法同态ElGamal、相等判断DET、大小判断OPE[6-7],如图3所示。
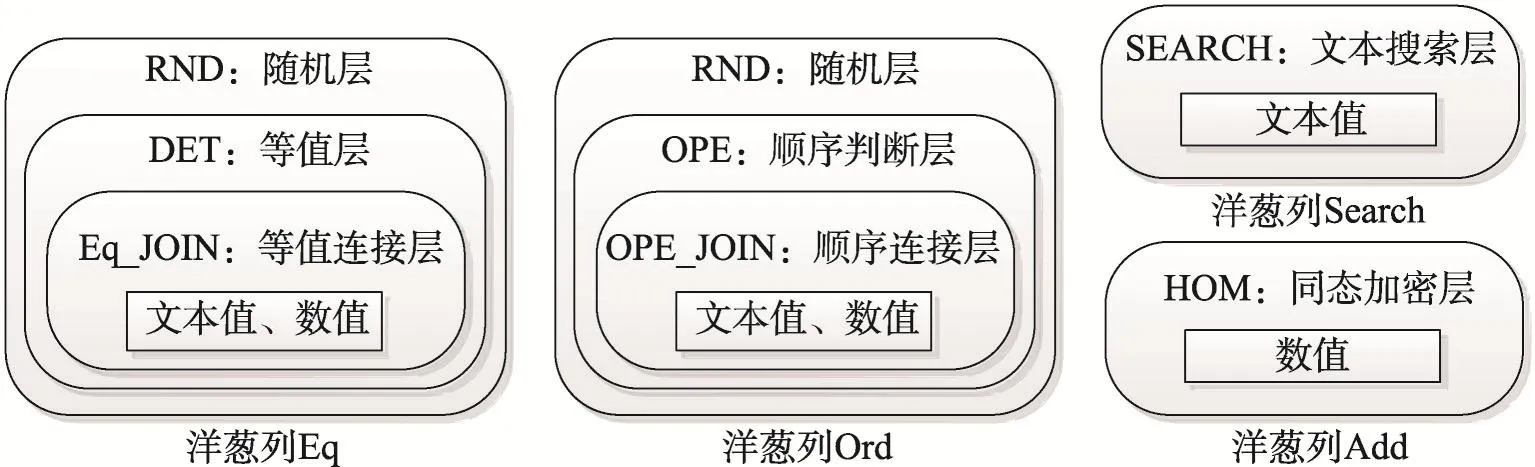
Fig.1 Onion encryption layers图1 洋葱层示例
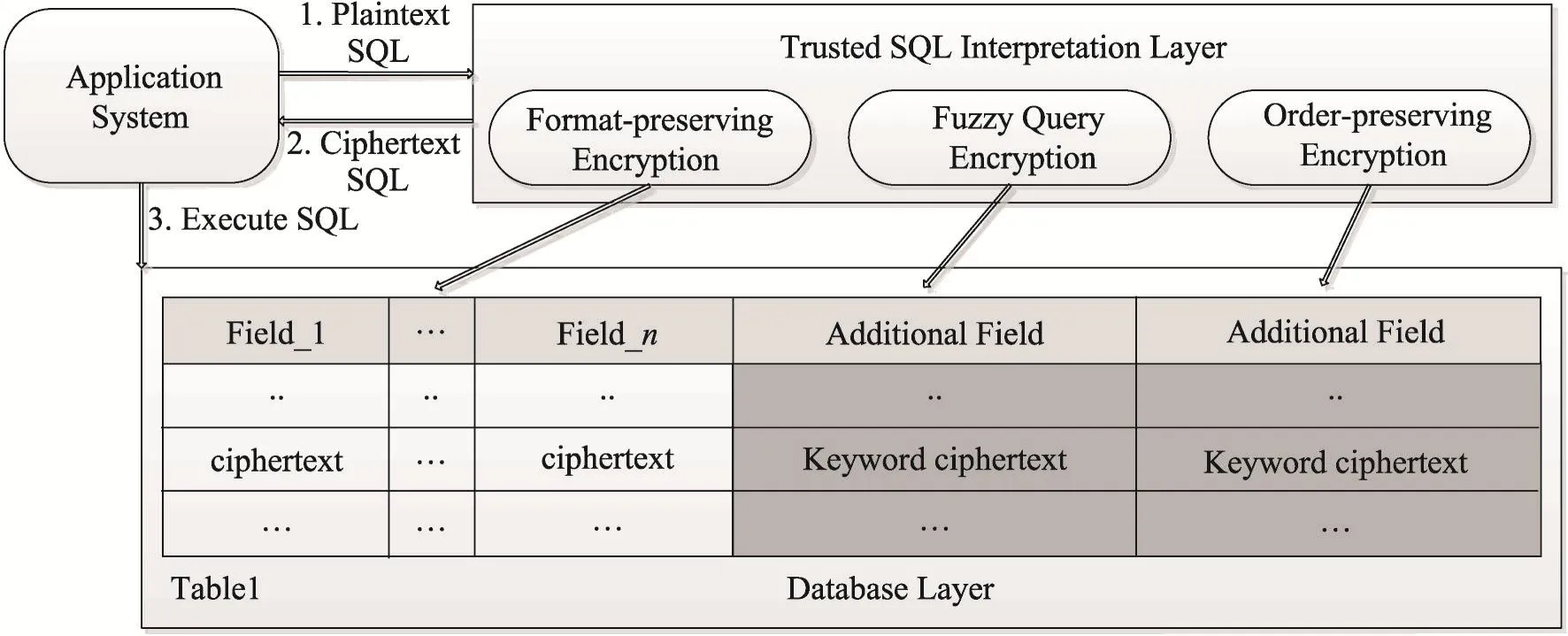
Fig.2 L-EncDB architecture图2 L-EncDB结构
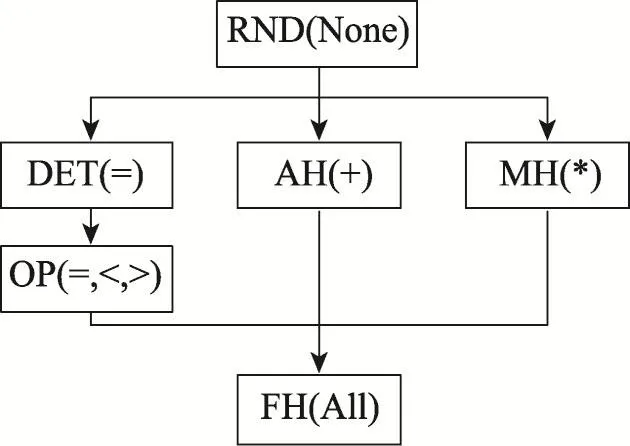
Fig.3 Encryption schemes of MrCrypt图3 MrCrypt的加密模式
该文侧重于MapReduce的密文改写执行方法,并给出了改写示例。其利用了多个同态算法来承载不同的属性运算,与CryptDB中洋葱加密算法的思路相类似,也给出类似的压缩洋葱层的设计。由于Map-Reduce框架简单高效,故十分适合该方法。
3 洋葱加密算法
由图1~图3可以看出,通过使用多密码学函数来承载功能不同的运算属性,可以近似达到在密文上执行SQL指令的结果,因而是一种集合式的全同态加密算法。本文将进一步分析各个加密层,并给出主列与辅助列的改进密码集合方法。
第3.1节讨论了洋葱加密算法中洋葱层与各密码学算法的对应关系和特性。第3.2节总结了洋葱加密算法的不足,并提出了简化洋葱加密算法的思路:(1)压缩洋葱层,扩展洋葱列;(2)双向性密码学算法保证数据准确性(Eq列),多个单项性密码学算法确保仅暴露部分数据属性(如Ord列),从而保证安全性;(3)设计列名的明文密文对应规则,减少对上下文信息的依赖。
3.1 加密层特性
洋葱加密算法分拆了明文列属性到多个密文列,且不同密文列的洋葱结构不同,加密算法也不同。有些密码学算法仅需要密钥作为唯一参数,而有些密码学方法则需要更多参数,这些参数需要在密钥管理模块中设计与组织。本节将介绍各加密层的设计思想。
RND(random):该密码层要求较大程度的随机化,以提升安全性,即使以相同密钥值构建的相同加密算法来加密相同的明文值,其密文值也不相同。原因在于,其通过密码分组链接(cipher block chaining,CBC)模式下的组对称加密算法(如AES、Blowfish)实现,在该模式下,密钥并不是全部的输入参数,还包括输入参数IV。而即使服务器端知晓了IV值,但不知密钥的话,也无法解密密文数据,故具有较高的安全性。
DET(deterministic):该密码层要求同一列中明文与密文的确定性,在同一加密算法下,如果两项密文的明文值相同,则其对应的密文值也相同。与RND相比,DET体现了双向特性,即能够在明文和密文之间相互转换。这要求算法本身是一种伪随机序列算法(pseudo-random permutation,PRP),从而能够通过算法本身的随机性,来保证整个DET密码层的随机性。因为IV没有参与,故与RND方法相比较,其安全性较大程度上依赖于算法本身的安全性。
OPE(order-preserving encryption):该密码层要求同一列中数值的大小比较。换言之,如果x〈y,那么OPE_k(x)〈OPE_k(y)。这种算法针对数值比较,这是由OPE算法的特性决定的。OPE算法最初是在文献[7]中提出的,是一种全新的密码学设想,即在一次加密过程后,除了数值大小的信息被暴露之外,其余信息都保持安全性。这种算法的初衷,是把原始数值用另外的数值替换,从而可通过比较新数之间的大小来确定原数之间的大小。文献[8-9]在此基础上进行了扩展,提出了新的安全性概念IND-OPCA。但Boldyreva指出无法实现真正意义上的IND-OPCA,于是基于伪随机函数的安全性定义POPF-CCA,并提出了利用超几何分布在各数值区间产生随机数值的方法。这种方法最先在文献[3]中采用,也应用在开源代码中。但是Popa等人在文献[10]中重新梳理了OPE方法,认为OPE算法均存在一个弊端,即密文一旦确定就无法改变,于是提出了动态保序的思想mOPE。该算法通过平衡树存储数值,根据叶子节点到根节点之间的走势得到01序列,而平衡树的自平衡功能则可以动态改变序列编码,从而更新密文数值的大小。这种方式具有较强的安全性,但实现起来较为复杂,使用了大量的UDF(user defined function)功能函数,且需要客户端程序的配合。
HOM(homomorphic encryption):该密码层要求可以在密文上直接计算得到和与平均。可使用paillier算法[11],当需要计算某一数值列的SUM或者AVG值时,调用MySQL中的UDF功能把该列上所有的值相乘取模,得到的密文值返回解密,即可得到最终的明文结果值。
Search(word search):该密码层要求可以在密文上进行模糊搜索。此时模糊搜索的粒度是词,其实验思想并不复杂。通过对明文句中的单词进行分隔,对每一个单词实现单独加密,得到的密文结果保存在数据库中。当需要查找指定词时(如name like‘Alice%’),直接加密该词获得密文,并使用like关键字重构SQL语句且执行(如name like‘XXX%’),将查找到的结果返回解密。故该设计思想仅支持全单词匹配。
Join(JOIN和OPE-JOIN):该密码层在文献[3]中提出,是两表连接时所需的密码层级,分别对应了等值连接操作(如s.id=t.id)和大小比较连接操作(如s.id〉t.id)。Join密码层在文献[12]中使用了很大篇幅,在后续论文中也有对其运行方式的思索。在两列密文以不同密钥加密的前提下,算法仍然能够通过不同列的Join层执行连接操作。这种特性能够很好地支持密文上的连接操作,具有很好的应用性。
3.2 洋葱加密算法的不足与改进思路
洋葱加密算法存在一些不足。
(1)洋葱层冗余与上下密码层差异性较大。不同洋葱密码层承载了不同的运算操作,这体现了算法的功能性与安全性。但是执行上下密文层转换的主体是数据库本身,最终该列的安全性将由最内层密码算法保证。因此,多密码层没有使安全性得到叠加,却增加了上下层转换时的运算开销。且上下层间的功能性差异较大,没有完全的继承性,功能性略显冲突(如DET与Eq_Join)。
(2)原等值连接算法的低效性。原算法先用伪随机函数转换明文,后通过椭圆加密算法与不同指数上标计算得到不同密文。改变指数上标即可改变密文值,从而实现对应。本质上,这种方法由两部分组成,确定性转化与参数差异性转化(前者保护了明文安全,后者产生差异)。上述特性的实现,存在更加简化的方法,因此原算法的步骤略显复杂和低效。
(3)明文列与密文列名称没有对应性。明文列与密文列名称间相互转换,洋葱加密算法存储映射列表以对应明文与密文列名,这种方式对上下文信息的要求较高,尤其算法主体运行在中间层,这必然导致多次SQL之间的信息共享,无疑会增加操作之间的耦合性。
针对上述不足,提出了改进思路。
(1)压缩洋葱层,扩展洋葱列,并把洋葱列分为主列与辅助列(前者使用双向算法可还原明文,后者使用单向算法提供各种运算属性支持却不能还原明文)。
(2)简化等值连接算法的两步转换方式,其中差异性转换可利用RND层存储在数据库上的参数IV,以减少中间件需要保存的数据。
(3)设计明文列与密文列名称的对应关系,减少执行SQL语句时对上下文信息的依赖(如密文列“XXX_Eq”可直接解密得到“sid”,无需记录对应关系),中间件仅保存密钥信息,从而确保各执行操作之间的低耦合性。
下面将根据这些思想对洋葱加密算法进行改进。
4 基于改进洋葱加密算法的Crypt-JDBC模型
首先描述Crypt-JDBC模型的基本架构。如图4所示,该模型是一个轻量型的基于JDBC的SQL语义改写方法。
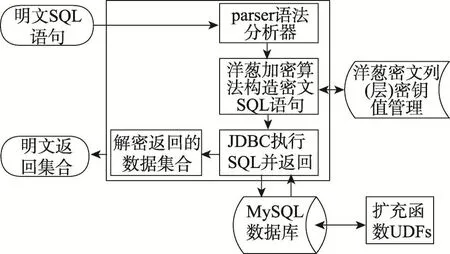
Fig.4 Crypt-JDBC model图4 Crypt-JDBC模型
Crypt-JDBC模型做了以下改进:(1)采用JDBC替换了原中间件程序MySQL-Proxy,简化了结构;(2)压缩洋葱层,扩展洋葱列,把洋葱列分为主密文列(如Eq列)与辅助密文列(如Ord列、Search列等),主列使用双向的加密算法,可解密得到原始值,辅助列则使用单向加密算法支持各种运算操作,不可解密还原;(3)改进密文上的等值连接算法,简化步骤,减少中间件存储信息;(4)修改密钥管理模块以匹配新的洋葱列模型,增加列名称的明密文转换以减少改写步骤对上下文的依赖,最终使中间件仅维护各密文列的密钥,实现低耦合高内聚。
Crypt-JDBC将明文SQL语句改写成密文SQL语句并执行,且解密返回的密文结果集。此时,数据库中存放的所有数据均以密文形式存储,从而保证数据安全。
定义1(明文SQL语句)改写前的SQL语句,如“create table student(sid int not null)”、“insert into student(sid)values(1)”等。
定义2(密文SQL语句)通过洋葱加密算法分拆明文列后组织起来的语句,如“create table S(XXX_Eq varchar(64),XXX_Ord BigInt,XXX_Add varchar(256))”、“insert into S(XXX_Eq,XXX_Ord,XXX_Add)values(‘abc’,200,‘xyz’)”等,其中insert语句中value括号内的值为对应密文列的密码值。
4.1 密文列加密算法
多洋葱层设计的初衷,原本是为了更强的安全性与功能性,但是上下层间的属性差异性较大,如DET与EQ_JOIN层,这影响了功能性;并且执行加层去层的主体是数据库本身,这影响了安全性。因此原方法在功能与安全上均不能达到预期,却增加了上下层转换的计算开销。
改进措施包括:压缩洋葱层,扩展洋葱列,把层叠的密码层分拆为更多的洋葱列,如表1所示。由于不再有多层次,这种改进的洋葱列被称为密文列。

Table1 Onion fields contrast表1 洋葱列对照表
如表1中所示,对比图1,首先考虑将等值连接层(Eq_Join)与比较连接层(Ord_Join)分离,作为单独的列。其次,将所有的RND层去除。因为执行密文上下层转换的主体是第三方服务器,在这种情况下,处在最外层的RND层则无法起作用。
更进一步,可以把洋葱列分为主密文列(如Eq列)与辅助密文列(如Ord列、Search列等)。主列使用双向加密算法,可解密得到明文;而辅助列使用单向加密算法,支持各种运算操作,却不能解密。
图5描述了洋葱加密算法的改进,由于大大减少了洋葱层的使用,称之为密文列加密算法。它同样将明文列(如sid)分拆为多列(如Eq、Ord等),多密文列各自承担不同的运算。
举一个简单例子说明不同加密列承载了不同的运算操作,例如,“select sid from student where sid〉1 and sname=‘Alice’”会被改写为“select sid.eq from student where sid.ord〉OPE(1)and sname.eq=DET(‘Alice’)”。值得注意的是,此示例忽略了一些细节操作,如密钥选择,密文列名称修改等。详细的算法会在4.3节中详细介绍。
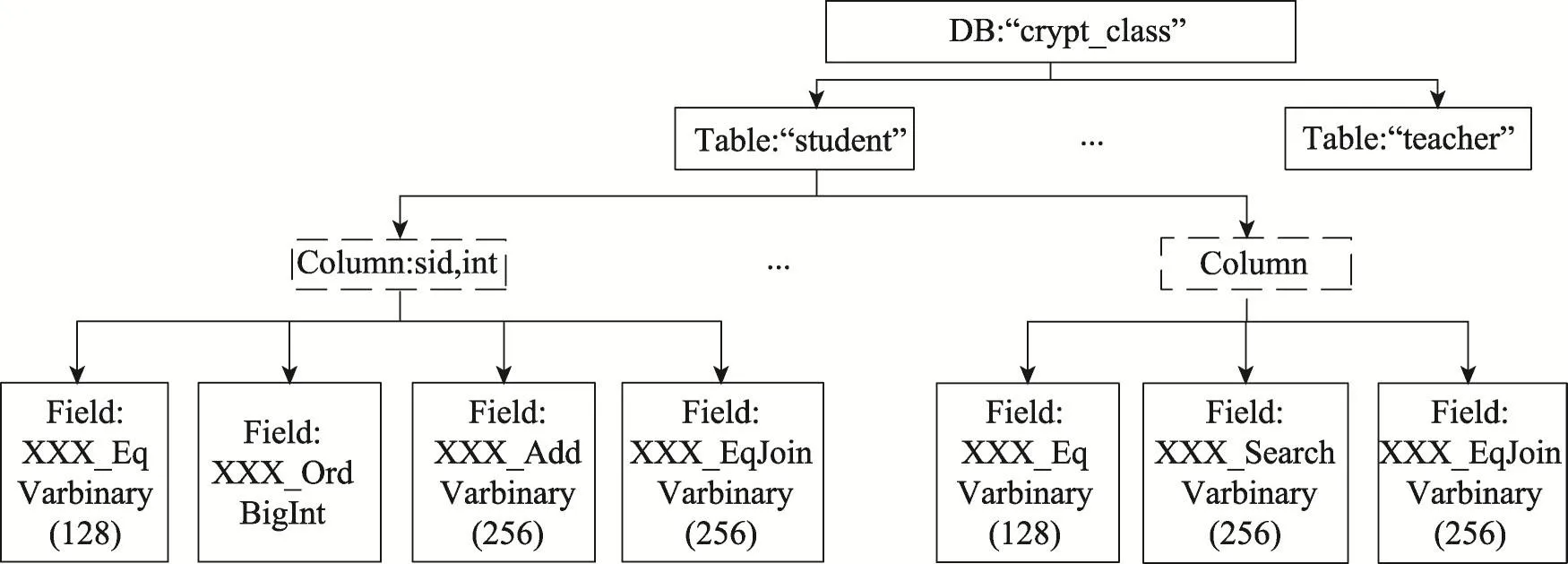
Fig.5 Improved field encryption algorithm图5 改进后的密文列加密算法
4.2 多列等值连接的改进执行方法
等值层所要解决的问题如下:即使两列密文以不同密钥进行加密,算法仍然能够对其执行连接操作。那么如何在这种情形下做等值连接呢?例如“select*fromA,BwhereA.a=B.b;”。
原算法中的等值连接操作使用了椭圆加密算法,并存在一个公共点P,并通过公式计算每个列的对应值[2]:

其中,K代表此列所存密钥,而K0为公共值。当请求连接c和c′两列时,中间层将计算ΔK=K/K′,并通过如下式子将两列转换为相同密钥加密的密文值:
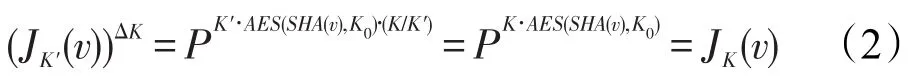
如此可在不同密文列上实现连接操作。这种方式实现比较复杂,效率较为低下,需要设计复杂的比较方式,以及大量UDF代码的支持。
该方法可分成两部分:第一部分实现了明文到中间密文值的转换,是一一对应的;第二部分实现了参数差异性转换,不同的参数对应不同的转换结果,当参数相同时密文值相同。这种等值比较方式,在静态环境下能保证完全的无关性,但在动态环境下会揭露出不同列中相同值的对应关系。
分析可得,因为执行等值比较的主体是数据库本身,所以它在执行过程中总是会了解这种对应关系。因此,无论多么复杂的算法,最终只能够保证静态环境下的安全性。
故本文提出了简化方法:第一步,替换更简便的哈希算法(如MD5算法,长度128位)。第二步,把中间密文值与参数IV(RND层的参数,长度128位)进行按位异或运算,得到最终的密文值。
当插入数值v时,首先计算v的消息摘要,再与该行的IV值进行按位异或运算,得到最终值,并将该值插入到密文列中。当查询时,则需要UDF功能的配合,如下所示。
考虑一个等值连接语句“select*froms,t wheres.sid=t.tid”。分析where子句表达式,可确定其执行了等值连接操作。故将该语句改写为“select*froms,t where udf_eqjoin(sid,IV)=udf_eqjoin(tid,IV)”。其中,udf_eqjoin()是用户自定义函数UDF,是扩充的功能代码,能够被MySQL所识别。
用户自定义接口是数据库自带的可扩展接口,可以在不修改DB源码的情形下扩充功能。其扩充后的函数可以像abs()函数一样方便使用。由于UDF不会对数据库的其他部分产生影响,是一种非常实用也非常流行的数据库扩展技术。
4.3 列名对应关系改进与密钥管理
原作中采用了如下方式来管理密钥:Kt,c,o,l=PRPMK(table,column,onion,layer),通过传入表名、列名、洋葱列、加密层来确定加密层的密钥值。但这种方式仅考虑了加密层的密钥获取,而没有考虑列名称的对应。
本文设计了列名的明文密文对应方式。该方式管理着两组密钥索引,分别对应转换数据的密钥和转换列名的密钥。为了叙述方便,本文以column表示明文列(如“sid”),field表示密文列(如“XXX_Eq”或“XXX_Ord”)。前者是上式的变形,存储了键值对〈k,v〉:表名table、明文列column、密文列field和该密文列对应的密钥,如((student,sid,XXXoEq),Gen(XXXoEq)),其中Gen()函数的功能是生成密钥,它根据密文列field的属性,选择不同的方法生成密钥,例如Eq选择AES或Blowfish,Ord选择OPE算法等。后者则是存有明文列名column与密文列名field相互转换的密值,如((student,sid),key)和((student,XXXoEq),key)。当通过密钥把明文列名column转换成密文列field后,需要同时将这2个键值对加入到索引中,以同时支持明文列与密文列间的相互转换。
5 查询语句的改写过程
以下将描述Crypt-JDBC模型中的密文列加密算法,并简述其改写查询语句的过程,包括密钥的管理使用和改写SQL语句的方法。
5.1 Create语句改写过程
Create语句改写方法首先解析SQL语句,分析并生成各密文列密钥。其算法伪代码如下。
算法1CREATE SQL rewrite function
输入:明文SQL语句
输出:密文SQL语句
1.Statement st=Jsqlparser();//解析明文SQL语句
2.Statement nst=new Statement();
3.Foreachc∈st.create.columns do
4. FieldKey k1=KeyFieldGen(c);//生成列名称密钥
5. Key k2=KeyGen(c);//生成密文列密钥
6. List lfs=Rewrite(c);//根据c是字符型还是数值型,改写明文列column到多密文列fields
7. nst.add(lfs);
8.Return nst;
为了使得明文列column的名称和密文列field的名称能够相互对应,使得列名变得有意义,并简化SQL改写过程中的操作,前端保存两者列名之间转换的密钥值,可减少中间件需要记录的数据。
5.2 Insert语句改写过程
Insert语句改写过程需要知道明文列与密文列间的对应关系,及各列的加密密钥。这种对应关系可以通过前端保存的密钥索引来快速寻找。类似的,密钥也可通过前端索引快速获得。其算法伪代码如下。
算法2INSERT SQL rewrite function
输入:明文SQL语句
输出:密文SQL语句
1.Statement st=Jsqlparser();//解析明文SQL语句
2.Statement nst=new Statement();
3.Foreachc∈st.insert.columns do
4. FieldKey k1=KeyFieldGet(c);//获取列名称密钥
5. List lk=KeysGet(c);//获取所有的密文列密钥
6. Ifc.value instance of int then
7. List lfs=Rewrite_int(c,lk);//改写明文列column到多密文列fields
8. Else
9. Listlfs=Rewrite_string(c,lk);//改写明文列column到多密文列fields
10. EndIf
11. nst.add(lfs);
12.Return nst;
此时,改写过程所需要的全部信息均为密钥值,这统一了前端后端通信的接口,使得密钥管理模块更加高效。
5.3 Select语句改写过程与解密返回集合
Select语句和前面两种语句稍有区别,它含有更多的表达式,如where子句和and子句。在这些子句中,包含有各种运算操作。这些运算操作由运算符和运算值所组成,如“sid=1”,“sid〉2”,“sname like‘Alice%’”等。
改写时,首先需要判断运算符的格式,依此修改明文列名到不同的密文属性列,以及修改明文值到不同的密文值。例如“sid=1”可修改为“XXX_Eq=Enc(1,key)”,其中XXX由“sid”加密得到。
算法3SELECT SQL rewrite function
输入:明文SQL语句
输出:密文SQL语句
1.Statement st=Jsqlparser();//解析明文SQL语句
2.Statement nst=new Statement();
3.Foreachc∈st.select.whereand.condition do
4. 依据c的运算属性改写condition,更新nst;
5.Foreacht∈st.select.sellist do
6. 改写返回列名,更新nst;
7. Return nst;
使用JDBC执行该密文SQL语句,并得到返回结果集合。该集合由列名与行元素组成,对该数据集合解密后可得到明文数据。
算法4SELECT SQL rewrite returnset function
输入:密文数据集合
输出:明文数据集合
1.解析密文数据集合;
2.定义临时密钥列表tmplist;
3.获取列名res_fields、行数据res_rows;
4.Foreachf∈res_fields do
5. 获取f对应的解密密钥key;
6. tmplist.add(key);
7.Dec(res_rows,tmplist);//解密密文数据
8.构建明文数据集合并返回;
综上,容易发现,密钥管理模块贯穿了整个改写算法的始终,且明文列与密文列的对应使得多条查询语句间的耦合性大大降低,减少了各语句间的关联性,具有极好的设计结构。
6 实验
本文实现了Crypt-JDBC模型,使用JDBC作为连接MySQL的中间件,以取代MySQL-Proxy软件[13]。实验运行在Ubuntu12.04环境下,MySQL版本为5.5.47。中间件MySQL-Proxy的版本是0.8.5[14](Crypt-DB开源代码中的Proxy版本为0.8.4,本实验修改了开源代码的安装指令[15-16],替换了较新的版本)。Crypt-JDBC运行在Eclipse中,Java版本为1.8.0_77。
本实验对比了CryptDB与Crypt-JDBC的执行效率。由于仅支持少量的SQL语句,本实验主要以增删查改SQL语句为例,测试它们在连续执行5、15、30、50条语句后的时间消耗。
图6描述了连续执行多条create语句的效率对比,可以看出随着执行语句条数的增加,CryptDB的上升幅度远远超过Crypt-JDBC模型的上升幅度。而随着n的增加,两条曲线在15到30阶段所增加的幅度要大于30到50阶段。这说明随着create语句的增多,其上升幅度放缓。图7描述了每条create语句所需的平均时间,可以发现它呈现阶段上升的趋势。
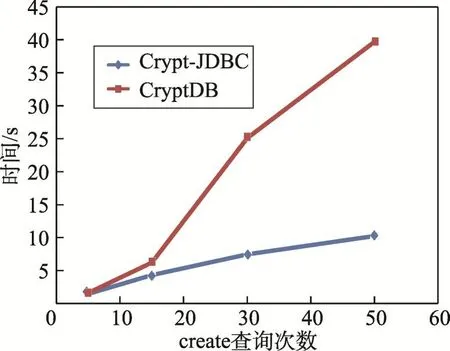
Fig.6 Efficiency for executing multiple create statements图6 连续执行多条create语句的效率对比
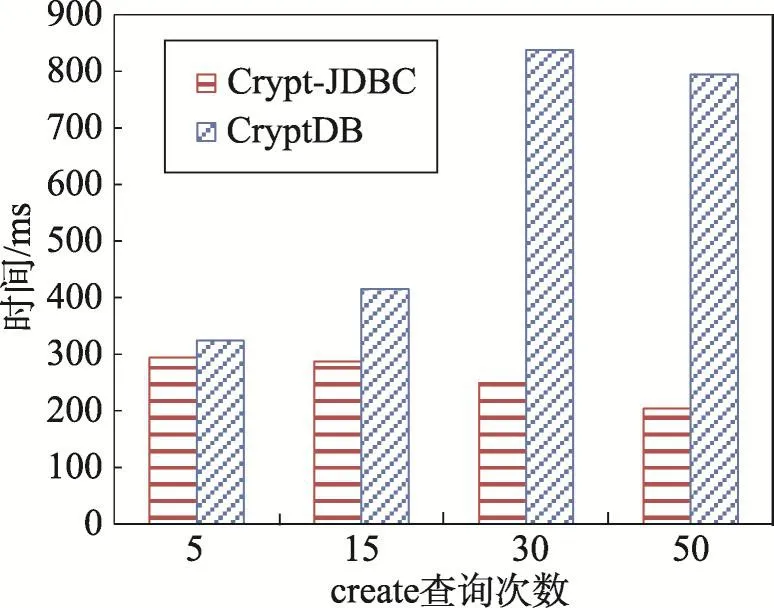
Fig.7 Average time of each create statement图7 单条create语句的平均执行时间
图8描述的是连续执行多条insert语句的时间对比,可以看出执行insert语句的时间与条数存在一种大致的线性关系,和create语句中阶梯上升的情形相区别。同时,从图9中可以发现一个有趣的现象,随着insert语句执行次数的增加,每条insert语句所需要的平均单位时间有所降低。
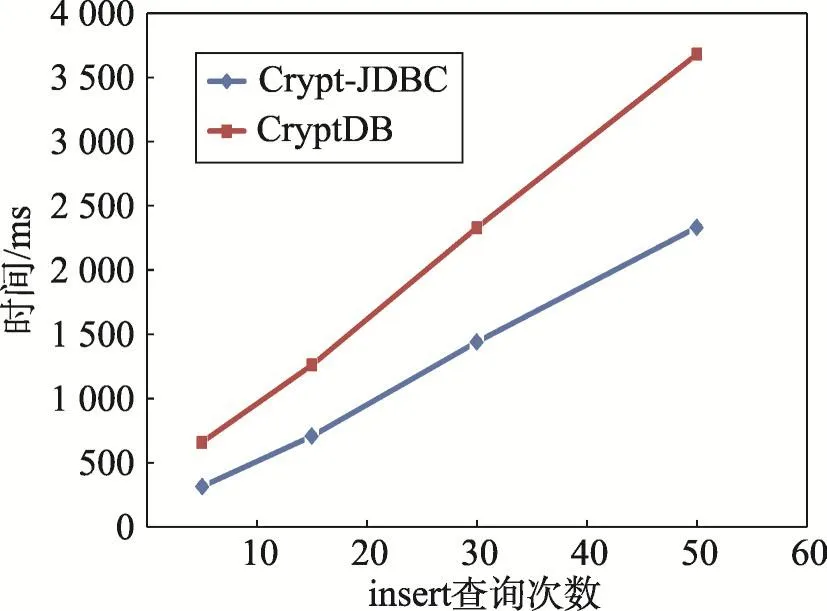
Fig.8 Efficiency for executing multiple insert statements图8 连续执行多条insert语句的效率对比
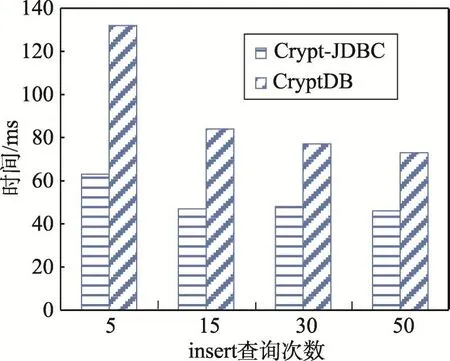
Fig.9 Average time of each insert statement图9 单条insert语句的平均执行时间
图10中的纵坐标代表数据量,横坐标代表执行多次select语句所需时间,n为执行语句数。该图描述了在不同数据量的表上执行多次select语句所需总时间。如图所示,相同数据量下,执行多条select语句所需的总时间,随着执行次数的增大而增大;同理,执行次数相同时,总时间也与数据量正相关。
图11描述了不同数据量下Crypt-JDBC与Crypt-DB的select语句执行效率对比。连续执行40次select指令可消除单次执行的误差,并与图10中数据相对应。图12展示了存放在MySQL中的部分数据,从左到右分别是Eq、Ord、Add列。
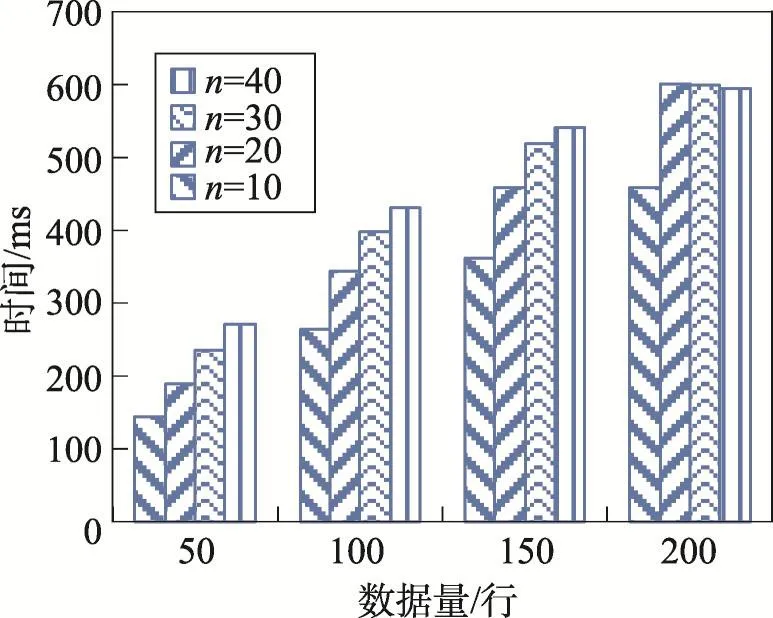
Fig.10 Average time of each select statement in Crypt-JDBC model图10 Crypt-JDBC模型中select语句的平均执行时间
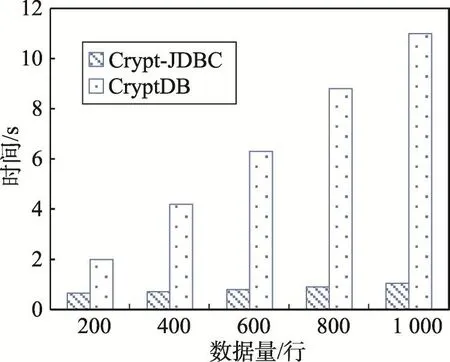
Fig.11 Efficiency for executing 40 select statements图11 执行40次select语句的效率对比
Fig.12 Part of cipher text stored in DB图12 存储的部分密文数据
通过实验可以看出,Crypt-JDBC模型的执行效率要高于CryptDB,原因有两点:(1)CryptDB使用MySQL-Proxy软件作为程序的中间件,而Proxy需要向前端与后端发送数据,因而其运行时间比直接使用JDBC大了很多;(2)Crypt-JDBC在设计上比Crypt-DB少了一些洋葱密码层却多了一些洋葱密文列,这是一种用空间换取时间的策略。Crypt-JDBC模型使用单向密码算法来确保安全性,使用UDF代码来确保功能性,达到了安全性与功能性的统一。
7 总结
本文探讨了CryptDB的发展历程和设计理念,深入分析了洋葱加密算法,并发现了三点不足之处:洋葱层冗余与上下密码层差异性较大,等值连接算法的低效性,明文列与密文列名称没有对应性。针对以上不足,提出了新模型Crypt-JDBC,替换了中间件MySQL-Proxy,具有较好的执行效率。
本文还依据“压缩洋葱层,扩展洋葱列,并把洋葱列分为主列与辅助列”的思想,改进了洋葱加密算法。由于改进后的洋葱列上仅有一层或两层洋葱密文层,故这种改进后的算法也可以称作密文列加密算法。本文还分析了等值连接方法的特性,简化了两步转换的方式,提出了新的等值连接方法。本文也扩充和修改了密钥的管理,使明文列与密文列名称建立对应关系,减少了SQL执行过程中对上下文信息的依赖。
当然,本文模型在实际应用中还有若干问题需要解决,如用到的UDF功能算法的设计,更多SQL语句的改写方式,扩充到其他数据库或大数据库的可行性等。
[1]Popa RA,Redfield C M S,Zeldovich N,et al.CryptDB:protecting confidentiality with encrypted query processing[C]//Proceedings of the 23rd ACM Symposium on Operating Systems Principles,Cascais,Portugal,Oct 23-26,2011.New York:ACM,2011:85-100.
[2]Popa RA,Zeldovich N,Balakrishnan H.CryptDB:a practical encrypted relational DBMS,MIT-CSAIL-TR-2011-005[R].CSAIL,MIT,2011.
[3]Tu S,Kaashoek M F,Madden S,et al.Processing analytical queries over encrypted data[C]//Proceedings of the 39th International Conference on Very Large Data Bases,Trento,Italy,Aug 26-30,2013.Red Hook,USA:Curran Associates,2013:289-300.
[4]Popa RA.Building practical systems that compute on encrypted data[D].Cambridge,USA:Massachusetts Institute of Technology,2014.
[5]Li Jin,Liu Zheli,Chen Xiaofeng,et al.L-EncDB:a lightweight framework for privacy-preserving data queries in cloud computing[J].Knowledge-Based Systems,2015,79:18-26.
[6]Tetali S D,Lesani M,MajumdarR,et al.MrCrypt:static analysis for secure cloud computations[J].ACM SIGPLAN Notices,2013,48(10):271-286.
[7]AgrawalR,Kiernan J,SrikantR,et al.Order preserving encryption for numeric data[C]//Proceedings of the 2004 ACM SIGMOD International Conference on Management of Data,Paris,Jun 13-18,2004.New York:ACM,2004:563-574.
[8]Amanatidis G,BoldyrevaA,O’NeillA.Provably-secure schemes for basic query support in outsourced databases[C]//LNCS 4602:Proceedings of the 21st Annual IFIP WG 11.3 Working Conference on Data and Applications Security,Redondo Beach,USA,Jul 8-11,2007.Berlin,Heidelberg:Springer,2007:14-30.
[9]BoldyrevaA,Chenette N,O’NeillA.Order-preserving encryption revisited:improved security analysis and alternative solutions[C]//LNCS 6841:Proceedings of the 31st Annual Conference on Advances in Cryptology,Santa Barbara,USA,Aug 14-18,2011.Berlin,Heidelberg:Springer,2011:578-595.
[10]Popa RA,Li F H,Zeldovich N.An ideal-security protocol for order-preserving encoding[C]//Proceedings of the 2013 Symposium on Security and Privacy,San Francisco,USA,May 19-22,2013.Piscataway,USA:IEEE,2013:463-477.
[11]Paillier P.Public-key cryptosystems based on composite degree residuosity classes[C]//LNCS 1592:Proceedings of the 17th International Conference on Theory and Application of Cryptographic Techniques,Prague,May 2-6,1999.Berlin,Heidelberg:Springer,1999:223-238.
[12]Popa RA,Zeldovich N.Cryptographic treatment of CryptDB's adjustable join,MIT-CSAIL-TR-2012-006[R].CSAIL,MIT,2012.
[13]Curino C,Jones E P C,Popa RA,et al.Relational cloud:a database service for the cloud[C]//Proceedings of the 5th Biennial Conference on Innovative Data Systems Research,Pacific Grove,USA,Jan 9-12,2011:235-240.
[14]Taylor M.MySQL proxy web site[EB/OL].(2016-04)[2016-07-04].https://launchpad.net/mysql-proxy.
[15]Shoup V.Alibrary for doing number theory[EB/OL].(2013-05)[2016-07-04].http://www.shoup.net/ntl/.
[16]Popa RA,Redfield C M S,Zeldovich N,et al.CryptDB web site[EB/OL].(2015-11)[2016-07-04].http://css.csail.mit.edu/cryptdb.
Crypt-JDBC Model:Optimization of Onion EncryptionAlgorithm*
CHEN He1,TIAN Xiuxia1,2,YUAN Peisen3,JIN Cheqing1+
1.Institute for Data Science and Engineering,School of Computer Science and Software Engineering,East China Normal University,Shanghai 200062,China
2.College of Computer Science and Technology,Shanghai University of Electric Power,Shanghai 200090,China
3.College of Information Science and Technology,NanjingAgricultural University,Nanjing 210095,China
+Corresponding author:E-mail:cqjin@sei.ecnu.edu.cn
CHEN He,TIAN Xiuxia,YUAN Peisen,et al.Crypt-JDBC model:optimization of onion encryption algorithm.Journal of Frontiers of Computer Science and Technology,2017,11(8):1246-1257.
CryptDB is a typical encrypted data storage technology that uses onion encryption algorithm to rewrite the SQL statement to the different columns of the onion,so that only partial attributes of data are exposed for conducing different operations.To overcome the multiple weaknesses of onion encryption algorithm,this paper proposes a new Crypt-JDBC model:(1)As the existence of too many layers of onion,and poor inheritance of neighbor layers,the new model compresses layers of onion,and divides onion-fields into the main field and auxiliary fields(the main field uses a two-way algorithm for restoring the plain text,and the auxiliary fields use one-way algorithm for operations and security);(2)As the existence of inefficient join function,the new model simplifies one important part(difference transformation)to reduce complexity;(3)As the existence of low corresponding between the namesof columns and fields,the new model redesigns the corresponding relationship between columns(plain text)and fields(cipher text),reduces the context information,and enhances the integrity of keys.This paper implements the Crypt-JDBC model,and uses JDBC to replace the middleware MySQL-Proxy.The experimental results show that the model is efficient.
CryptDB;crypto database;Crypt-JDBC model;onion encryption algorithm;cipher text database
ia was born in 1976.She
the Ph.D.degree from Fudan University.Now she is a professor and M.S.supervisor at Shanghai University of Electric Power.Her research interests include information security and database security,etc. 田秀霞(1976—),女,河南安阳人,复旦大学计算机科学技术学院博士,上海电力学院教授、硕士生导师,主要研究领域为信息安全,数据库安全等。

CHEN He was born in 1992.He is an M.S.candidate at School of Computer Science and Software Engineering,East China Normal University.His research interests include databases,information security and location-based service,etc.陈鹤(1992—),男,安徽淮北人,华东师范大学计算机科学与软件工程学院硕士研究生,主要研究领域为数据库,信息安全,基于位置的服务等。

YUAN Peisen was born in 1980.He is a lecture at NanjingAgricultural University.His research interests include dataintensive computing and data mining,etc.袁培森(1980—),男,河南淮阳人,南京农业大学讲师,主要研究领域为海量数据处理,数据挖掘等。
A
:TP392
*The National Natural Science Foundation of China under Grant Nos.61370101,U1501252,61532021,61502236,61202020(国家自然科学基金);the National Basic Research Program of China under Grant No.2012CB316203(国家重点基础研究发展计划(973计划));the Innovation Program of Shanghai Municipal Education Commission under Grant No.14ZZ045(上海市教委科研创新重点项目).
Received 2016-07,Accepted 2016-09.
CNKI网络优先出版:2016-09-08,http://www.cnki.net/kcms/detail/11.5602.TP.20160908.1458.032.html
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology 1673-9418/2017/11(08)-1246-12
10.3778/j.issn.1673-9418.1608037
E-mail:fcst@vip.163.com
http://www.ceaj.org
Tel:+86-10-89056056
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年10期)2021-11-19
湖北师范大学学报(自然科学版)(2021年4期)2021-11-19
网络安全技术与应用(2020年11期)2020-11-14
沈阳工业大学学报(2020年2期)2020-04-11
电子制作(2019年9期)2019-05-30
民间故事选刊·上(2018年1期)2018-01-02
计算机测量与控制(2017年6期)2017-07-01
小小说月刊·下半月(2016年6期)2016-05-14
火控雷达技术(2016年1期)2016-02-06
