
基于多特征选择的聚类方法研究
2017-09-07 11:49马元元
数字技术与应用 2017年5期
马元元

摘要:特征选择是数据挖掘和机器学习领域中聚类分析的一种常用分析处理方式,目前已广泛运用于文本资源分类和数据集的聚类中,在未被标记的资源集处理环境中,让计算机自己学习使用一些特征相关度量的选择方法。总结了一种基于多特征选择算法的聚类方法(MFSC),在资源集中,对多特征进行聚类特征方法选择、分类,将关系相关性较强的划分为同类簇群,再依次从每个簇群中轮询特征代表性较强的归为一类集合,最终达到去除弱依赖特征和特征冗余的结果。实验证明MFSC特征集约效果较高、性能较稳定。
关键词:特征选择;多特征;聚类;MFSC
中图分类号:TP301 文献标识码:A 文章编号:1007-9416(2017)05-0139-03
Clustering Research Based on Multiple Feature Selection
Ma Yuanyuan
(Information Engineering School, Zhongshan Polytechnic, Zhongshan Guangdong 528404)
Abstract:feature selection is the clustering analysis of data mining and machine learning in the field of a common analysis method, has been widely used in text classification and clustering of resource data sets, in the unlabeled set of resources processing environment, let the computer choose their own learning methods using some characteristics related to measure. To explore and summarize a multiple feature selection algorithm (MFSC) feature selection and clustering method, which use the characteristic interval intermediate key single feature clustering, clustering method which features the concentration of resources in the feature selection classification, divides the relationship is strong for the same cluster, then from each cluster in the polling feature representative is classified as a class set, to remove the weak dependence and feature redundancy results. Experimental results show that the MFSC feature is highly effective and stable.
Key Words:Feature selection;Multi feature;Clustering;MFSC
1 引言
近年来,随着大数据、云计算、人工智能等前沿技术的广泛应用,互聯网庞大的信息的处理和使用,成为了广大业内学者研究的重要课题之一。这类课题研究都产生于标记资源集的数据处理中,对未知或者说未标记的资源集的处理研究则显得相对薄弱。其原因是因为:(1)未标记资源集特征选择是基于计算机自我学习和自我提升处理能力的;(2)未标记资源集特征选择是利用上下文(一组带属性的有序序列),进行自我对象认知和激活的过程,要求是自动服务,如同步数据到资源库、实时激活、事物的再处理的过程中充满了许多不确定性,获取的结果也难以验证和解释。本文对多特征选择聚类算法(Multiple feature selection clustering algorithm)进行研究,以降低特征空间维数、提升聚类的效果[1]。
2 文本分类的相关技术
聚类在web文本数据的归类中作为一种手段,利用的是计算机的自我分析和聚合。例如两个职员对音乐有兴趣,一个喜欢哲学,一个喜欢运动。这些数据并没有被预先计算好,它们是实时的从匹配查询语句的文档中动态计算生成的。首先将文本中挖掘的数据集分成若干个数据簇,要求有较强的依赖和相关性,而不同的数据簇相关性尽可能的小,然后对文本进行聚类分析后的分类信息可作为对用户行为相似度的分析[2]。
通常对文本数据采用向量空间标记来进行聚类描述。在这一设计模型中,每一单词都作为特征空间中的一维坐标系,而每一文本的数据簇作为一个向量。这种分析方法虽然简单和直接,但是在多维稀疏矩阵文本聚类中,效率和性能却很难让人满意。
为了解决上述问题,我们通过特征选择来进行分级汇总进行特征值的降序排序,根据标记和未标记资源集的特征选择进行分类。比如,在对文档的聚类中,文档归属于一种类型(type),而这些聚类分析后的类型存在于索引(index)中,我们对其中的字段(fields)进行搜索,步骤如下所示:
Relational DB -> Databases -> Tables -> Rows -> ColumnsSearch -> Indices -> Types -> Documents -> Fields
3 特征选择聚类算法研究endprint
在未标记的数据集中,数据的特征并不是孤立表现的,而是相关联的表现相似特征,这就构成了多特征的集。针对这些在区分类别时存在的冗余现象,本文提出了基于上下文多特征选择的聚类算法。主要思想是根据数据集表现的特征的相似度,对相似属性类的特征进行聚类汇总,然后在每个簇群中选择一个特征作为主键,簇群中的其他特征从候选特征集中标记为外键或对依赖性弱的进行剔除,这样保证特征集的相对独立性、降低高冗余度,进而对剩余的特征进行信息筛选后特征归类。
3.1 特征区间的选择
我们以web文本为例,对于DocType类型的文本中的每一特征作为一类的特征区间。如文档内容、URI和web的访问日志,对于文档内容和URI我们可以用向量区间模型表示,通过对语义的划分表示权值。但对于用户访问过的log信息,如果没有定义信息来源类别,将得不到任何关于词分类的信息。因此引入了一种从开发到用户使用之间的关系向量。
假设日志信息包含了m个上下文样本记录和n个查询特征,特征集F可表示为:
F=,(1≤K≤n).K指的是特征集,F进行聚类时被划分了K个不同的特征簇。
对于特征选择后的聚类,不确定性是特征评价的指标,它也是针对计算机信息增减变化的度量指标和依赖程度,可以理解为数据簇之间共同相似的信息含量。如果用ω表示web页面的上下文本记录,j表示查询次的访问过的页面,表示特征向量的空间。
V(ω) =
则可以利使用以上公式计算每个web页面的特征向量空间,对每个特征区间进行聚类汇总了。
3.2 多特征选择聚类算法(MFSC)
在聚类的选择特征中,对特征类型的分类是一个反复进行的过程,首先对探测到的未标记的数据集进行相关度计算并形成类别区间,基于多特征选择聚类的算法,会在此基础上进行降序特征排序,然后通过聚类算法在不同的子空间中检索数据簇,确定标记主键,然后形成特征子集的特征簇群。其处理过程如图1所示。
在实际的应用中,多特征选择聚类算法充分利用文本的多特征特性,为特征类的聚集确定主键,并进行分离出具有代表性的特征子集,这样在得到不同类别的类集后,在各个类集上进行特征选择并利用合并函数得到结果集。设M表示每个特征区间的数据集,代表一维的特征向量,代表聚类选择的第i个特征区间,CF代表合并的函数。那么算法程序的伪代码可以表示为:
for (n iterations of clustering) {
for (M feature character) {
Do clustering in feature char m
}
for (M feature character) {
for feature character m, do feature index using results in all freature character;
then
to combined score
f(x) = Voting(value())
}
}
其中,在程序代码的实现中利用到的算法,可以具体表示为:
Voting(value)
= (1)
公式(1)中,value可以用3.1节中标记资源集的特征选择聚集函数公式来计算,st是特征选择的阀值,可以通过以往统计的数据推出设定值。从算法中,我们可以发现基于上下文进行多特征选择的聚类方法在聚类时是利用主键的方式进行表示,采用分类别的簇间的不同性选择特征子集。在每一次特征集簇群选择后,聚类都会重新降序排列汇总,得到一组高聚类的特征子集。
3.3 实验结果比较
对于特征选择算法的评估,我应考虑到:(1)特征分类所获的结果相同时,子集的区间距离越短,其性能越优;(2)在大数据集测试时,特征分类的越稳定,其算法越好。
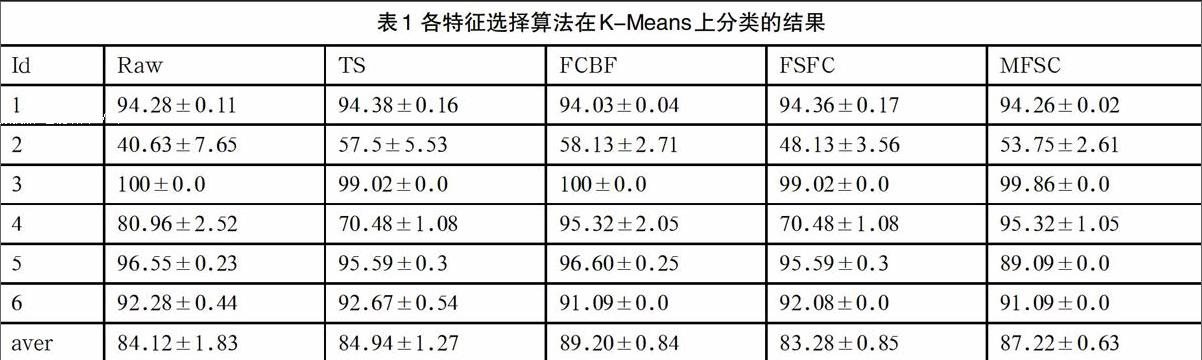
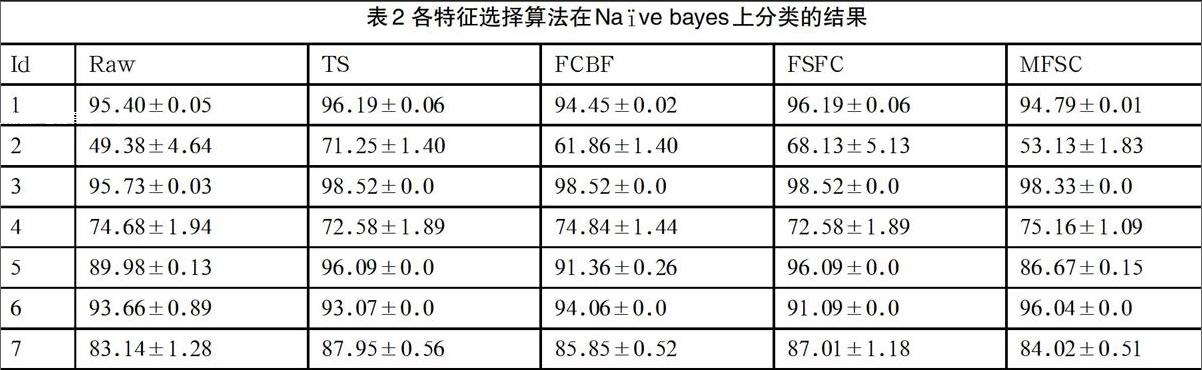
表1和表2分别对比了Raw(特征全集)、TS、FCBF、FSFC、MFSC等算法,在K-Means和Nave bayes分类器的分类结果,并由实验结果可以看出:(1)MFSC算法结果正态分布的稳定性;(2)MFSC在未标记数据集上的分类用时是高于其他特征方法的,其原因在于多特征的选择的分量,类区间内距离分量相比其他更小。(3)MFSC在数据集上的分类上,由于特征选择的子集区间分量较小,准确率相比其他更高和错误率更低[3]。
4 结论
本文提出一种在未被标记的资源集处理环境中,让计算机自己学习使用多特征相关的选择聚类的方法——MFSC。使用这一算法将有无标记或有无监督的特征选方法成功的运用到了聚类分析,利用了上下文的多种相似特征进行主成分分析,确立主键和区间内距离,并对子区间也进行了特征值降序排列,从而达到较为理想的效果。
参考文献
[1]樊东辉.基于文本聚类的特征选择算法研究[D].西北师范大学,2012.
[2]樊东辉,王治和,陈建华,许虎寅.基于DF算法改进的文本聚类特征选择算法[J].甘肃联合大学学报(自然科学版),2012(1):51-54.
[3]徐峻岭,周毓明,陈林,徐宝文.基于互信息的无监督特征选择[J].计算机研究與发展,2012(2):372-382.endprint
猜你喜欢
电子测试(2017年15期)2017-12-18
电子制作(2017年23期)2017-02-02
光学精密工程(2016年5期)2016-11-07
互联网天地(2016年1期)2016-05-04
电测与仪表(2016年23期)2016-04-12
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
智能系统学报(2015年4期)2015-12-27
电子设计工程(2015年6期)2015-02-27
振动工程学报(2014年4期)2014-03-01
