
基于局部特征选择的微博中文文本分类研究
2017-09-28 10:31单世超栾翠菊
现代计算机 2017年23期
单世超,栾翠菊
(上海海事大学信息工程学院,上海 201306)
基于局部特征选择的微博中文文本分类研究
单世超,栾翠菊
(上海海事大学信息工程学院,上海 201306)
微博文本内容短小、用词不规范等缺点,使得微博文本的研究区别于通常的文本研究。目前微博研究很多,但缺少合适的带有标签的微博语料库。分析微博数据获取方案给出合适的带有分类标签的微博语料库,然后通过传统分类算法进行分类评估验证;由于微博短文本维度高存在严重的特征稀疏问题,全局特征选择算法容易忽略对某个类别重要但对语料集关联度小的特征,并采用局部特征选择方案。实验结果证明局部特征选择方法可以获得更高的分类效果。
微博;中文文本分类;全局特征选择;局部特征选择;WEKA
0 引言
新浪微博在国内作为重要的社交网络平台,极大影响了人们的生活方式。随着网络的发展,人们越来越多的通过微博平台交流,这样使得对微博的研究价值越来越大。对新浪微博的研究工作与人们的生活也日益密切相关。据微博发布的2016年第三季度财报显示:截止2016年9月30日,微博月活跃人数已达到2.97亿,较2015年同期相比增长34%[1]。
Farzindar[2]首先指出Twitter文本短小、语法不规范,使得对其的研究存在很多新的挑战,然后提出一种关于Twitter流的事件检测技术研究;王[3]回顾和总结国内外近几年在微博短文本研究方面的主要成果,认为微博短文本研究离商业应用还有相当长的路,然而微博短文本的学习及应用研究仍有广阔的研究空间;刘[4]鉴于微博文本短小特点,训练语料集生成主题模型,对微博短文本利用主题扩展方式减缓微博文本短带来的影响;王[5]和黄[6]则分别利用关联规则和语义相似实现对微博短文本扩展。
虽然目前国内微博研究有很多,但存在一个普遍现象是过多研究分类算法本身,并没有给出统一、合适的带有类别标签的微博语料集。然而对于数据挖掘或机器学习研究,数据才是基石,因此对微博文本的研究合理性必须建立在确切合理的语料集之上。(1)文章通过研究微博数据的获取方案,给出合理的微博文本语料集,并介绍合适的预处理方案。通过传统的文本分类模型评估验证语料集的合理性。(2)在特征选择方案上,针对全局特征选择方法偏向于选择对整体语料集关联程度强但对单个类别关联程度低的特征,提出局部特征选择方法。对给出的语料集,实验结果证明局部方法要优于全局方法。
1 相关工作
微博文本分类的流程包括微博文本预处理,文本表示,特征选择,分类器模型评估四个过程,文章基于WEKA平台实现分类评估阶段处理过程。分类流程图如图1,详细介绍如下:
a.信息提取:从半格式化的数据源TXT文档集中提取出只包含分类信微博的text字段信息,组成文档集,通过NLPIR汉语分词系统分词得到分词文档集。
b.数据格式转换:通过WEKA平台提供的TextDi⁃rectoryLoader类,将分词后的语料集生成WEKA可以处理的ARFF文件。
c.空间向量转换:使用WEKA平台提供的String⁃ToWordVetor,对每一篇文档生成向量空间模型。权重采用TFIDF。
d.特征选择:采用IG,CHI两种。
e.分类评估:分类器采用NaiveBayesM。
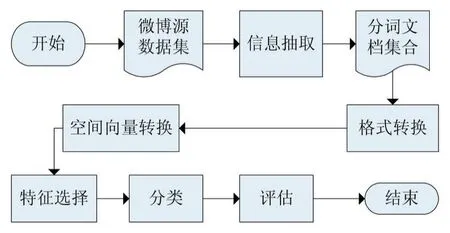
图1 微博文本分类流程图
1.1 VSMVSM文本表示模型和TFIDFTFIDF权重
在文本分类领域文本表示模型有多种,空间向量模型(VSM)作为最常用的文本表示模型。语料集D中的每一篇文档d都是由一组词组成的向量表示,即d=(w1,w2,…,wn),D={d|d=(w1,w2,…,wn)}。
其中wi(i=1,2,…,n)表示对应的词的权重。首先假设语料集的全部词特征为t1,t2,…,tnn个特征,w表示相关特征t对文档d的代表程度。即向量(w1,w2,…,wn)代表所有特征对文档的表示程度,该向量越是表示该文档的程度越强表示该权重表示方法越好。传统的权重表示方法有词频(TF),逆文档频(IDF),和词频文档频(TFIDF)。如公式(1)-(3):
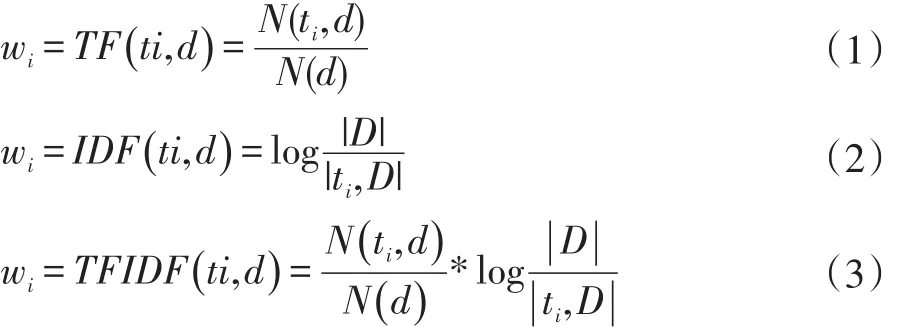
其中N(ti,d)表示词ti在文档d中出现的次数;N(D)表示文档d中所有词的数目;|D|表示语料集中的文档数目,|ti,D|表示语料集D中包含词ti的文档数目;其中加1是为了防止分母为0做的平滑处理。词频表示词在文档中出现的次数越多越可以表示该文档;逆文档频表示词在越少的文档中出现越可以表示该文档。TFIDF算法则表示两者的结合方案。
1.2 IIGG和CCHHII特征选择算法
对于大的语料集,文档中的词数目有上万维,不可能把所有文档表示为上万维的特征空间。因此必须从上万维的特征空间中选择出更能表征语料集的特征,即用到了特征降维方法。常用的特征降维方法有特征选择和特征生成算法[7],文章中主要利用特征选择算法。
特征选择算法规定一个函数,函数表征每一个特征对语料集的重要程度,经过排序确认最靠前的特定数目的特征。下面介绍常用的两种:信息增益(IG)和卡方(CHI)特征选择算法。
(1)信息增益特征选择算法
IG特征选择算法基于信息熵概念,熵用来衡量数据集信息量的多少。熵越小说明信息量越少数据集越纯[8],信息增益比较原语料集信息熵与某特征条件下的数据集信息熵的差值。信息增益越大,证明该特征可以更好地划分语料集,该特征条件下数据里的熵越小数据越纯。如公式(4)-(6):

其中假设文档D分为c1,c2,…,cn个类别;H(D,tj)表示有tj的所有文档的分类信息熵,同理H(D,-tj)表示不含有tj的所有文档的分类信息熵。信息增益公式见公式(6)。
(2)卡方特征选择算法
卡法特征选择算法基于统计学中的卡方假设检验,首先假设结论H成立,如果卡方统计值大于阈值就认为假设不成立推翻假设H。在文本分类中,衡量特征是否与类别相关,假设特征与类别相关,如果特征与类别的卡方统计值越大就认为两者越相关。定义为公式(7):
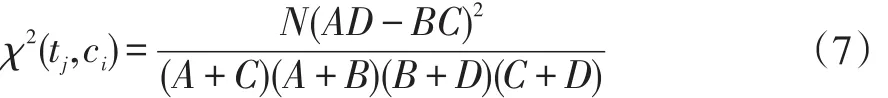
其中N表示所有文档数目,A表示包含单次tj并且属于ci的文档数目,B表示包含tj不属于ci的文档数目,C表示不包含tj但属于ci的文档数目,D表示不包含tj又不属于ci的文档数目。卡方值越大表示tj与ci越关联,而一般需要计算tj对整个语料集的关联程度,通常认为该值为特征对所有类别卡法值的最大值,如公式(8):

1.3 分类器与评估指标
分类器用来确定模型,通过一定的分类算法实现模型的建立过程,并通过合适的评估指标验证。文章选取NaiveBayesM和SVM分类器,评估准则使用F1值。
(1)NaiveBayesM 分类器
NaiveBayesM基于朴素贝叶斯定理,如公式(9):
在已知文档下的类别的条件概率称为后验概率,可以通过计算类别的先验概率和类别条件下文档出现的条件概率,并且基于假设:d中的特征ti相互独立。通常情况下,P(t|c)表示c类别中出现t词的文档频率,但是由于这样会丢失词在文档中的出现频次,因此多项式模型认为P(t|c)为词t在c类别中出现的词频比例。如公式(10):

(2)SVM 分类器
SVM分类器是针对小数量集表现优异的分类器。在线性可分的情况下,寻找可以分割两类的超平面,同时使得边界的支持向量到超平面的距离最大化。即通过最大化间隔的方法寻找最优的分类超平面。针对线性不可分的情况,通过构造高维空间将问题转换为线性可分。针对构造高维空间难以计算的问题,引入核函数代替。
(3)评估准则
分类结果评估方法有准确率P、召回率R、F1值,准确率表示每类分类结果预测为真的数目中确实为真的数目所占的比例,衡量分类结果的可信任度;召回率表示分类结果确实为真的数目中预测出来的数目所占的比例,衡量分类结果的文本丢失率;F1是综合P,R的一种分类性能度量值。
2 微博数据获取和预处理方案
2.1 数据获取方案
虽然目前有很多关于微博文本的相关研究,但是到目前为止却没有合适的带有标签的微博文本语料集。微博数据获取方案有两种[9],通过API接口获取或者页面解析。API数据获取方案简单,但每次只能获取有限的微博,分为公共用户、关注用户、和双向关注用户的微博三种,限制数据的获取,也没有标签。页面解析方案可以实现将页面看到所有内容都获取,但实现起来有很多困难。文章采用页面解析方案获取微博内容,主要解决以下问题:
模拟登录:微博页面数据采用延迟加载策略,并不是一次性获取无限数据。如未登录状态,只能浏览很少量的微博数据。实验采用请求携带cookie方式,每次发送请求会被认为登录状态。
自动加载:数据延迟加载策略要求是动态的获取数据,即需要不断的发送带有分页标识的请求。实验通过模拟实现请求自动生成,不断顺序获取数据。
展示全文:微博取消140字符的限制长度后,出现很多长文微博。需要点击“显示更多”发送请求才可以查看全文。实验模拟如果博文中有查看更多会自动生成请求并发送。
定时请求:新浪出于对数据的保护,不可能让不断的获取数据。因此在获取每个类别的微博文本时会出现无响应的情况,此时实验设计停止该类别开始下一个类别的数据获取任务。另外,为了获取更多的微博数据,实验设计实现隔一小时获取一次数据。最终实现3天获取大约两万条微博数据。
2.2 预处理方案
页面解析后的数据保存为以微博编号为名字的txt文档,有微博编号、博主昵称、博主编号、发表日期、发表内容和所属类别字段。预处理首先需要做微博内容字段提取,分词,停用词过滤四个步骤。
(1)微博内容提取
页面解析后保存的是微博各元数据组成的文件,实验部分仅仅需要分析微博内容。解析程序实现对内容字段的提取。
(2)分词
采用的分词方法是中科院分词系统NLPIR汉语分词系统,NLPIR新增微博分词、新词发现与关键词提取。程序使用NLPIR提供的Java程序接口,编写程序实现微博文本分词,词性标注,新词识别,用户字典等功能。其中新词识别效果很好,识别出像“麻婆豆腐”,“蓝瘦香菇”,“倒计时”等新词。
(3)停用词过滤
在基于NLPIR汉语分词系统基础之上,扩展去停用词的程序。除了基本的中英文停用词表外,还添加有HTML页面标签转义符,微博停用词表。解析页面获得数据难免有很多HTML的转义符,如空格的转义#nbsp;另外在观察微博文本过程中发现很多垃圾的词语,如“L网页链接”,“O秒拍视频”等词加入微博停用词表。
3 局部特征选择算法
在CHI特征选择算法中,认为特征对语料集的CHI值为特征对所有类别CHI值的最大值。然后通过排序对比所有特征对语料集的CHI值,最后选取最高的M个特征。但是这种方法容易忽略与某个类别相关,但是CHI值很小的某些特征。即对某个类别相关的特征并没有对整个类别的CHI很大,而忽略该特征。局部特征选择方法从类别角度出发,从特征与类别的CHI值矩阵中,抽选对每个类别影响CHI值最大的前M/C个特征。C表示类别数目,这样可以使得特征选择算法并不偏袒于某个类别。
图2 IG和CHI+BayesM实验F1值趋势图
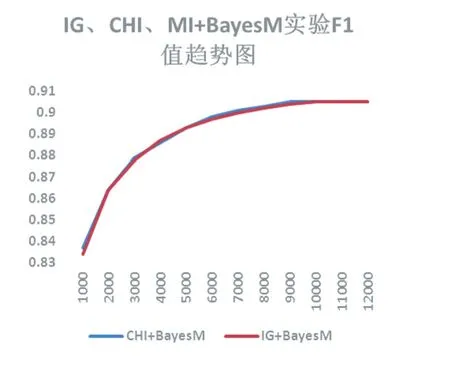
图3 IG和CHI+BayesM时间效率趋势图
4 实验与结果分析
“新浪微博发现栏块”[10]具有分类的微博数据,实验通过对该页面的9个类别的不同页面解析,获取微博数目近10万条。包括电影,动漫,科技,美食,美妆,萌宠,时尚,时事和体育类别。实验1分别采用IG和CHI特征选择算法,NaiveBayesM分类器;实验2针对CHI特征选择算法做局部特征选择。实验环境是Win10 64位操作系统,8G内存,i7-6700HQ CPU,Eclipse开发工具。
4.1 语料集验证实验
特征选择数目选择1000-12000个,每隔1000做一次实验,总的特征数目为12267。IG和CHI特征选择算法与NaiveBayesM分类器结合的F1值实验结果图如图 2,3。
观察图2、3,从F1评估结果图可以看出IG和CHI特征选择大致相同,随着特征数目的增多F1不断提高,但最后都趋于最高值,最高达到0.905,由此可以看出文章给出的语料集是很适合的。从时间效率图可以看出随着特征数目的增多,分类器的训练时间也增多,IG特征选择算法稍微耗时高。由于在试验中发现SVM分类算法时间效率高达965.163秒,故并没有针对SVM分类器做实验对比。
4.2 局部特征选择实验
对CHI特征选择算法采用局部特征选择算法,分类器使用NaiveBayesM。实验结果如图4,5。
图4,5中横坐标1000/968表示每个类别选取1000均分9份(类别数)111个最高的特征,最终合并的时候是968个特征,有32个特征重合。以此类推。从图中可以明显看出局部特征选择算法的优异性能,在每个划分下效果都要比全局特征选择方案好,并且实际用的是更少的特征(如1000到968)。局部特征选择方法在实际特征数目为8千多情况下效果最优,F1值为0.917。比全局特征选择算法最高F1值0.905高1.2%,并且实际特征数目是8866个。从图5也可以看到局部方法时间效率也有很大程度提高,最长14.48秒是全局28.49秒的0.5倍。
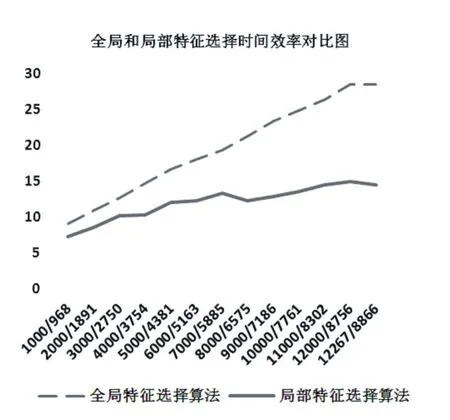
图5 全局与局部特征选择算法时间效率对比图
5 结语
实验中涉及微博数据获取程序,微博语料集,预处理程序,和相关的分类程序[11-13]。
文章通过微博数据获取方案给出合适的带有标签的微博语料集,并通过实验方法证明语料集的可用性;然后针对全局特征选择算法的缺点,采用均分的局部特征选择方法,实验证明效果有很明显的提高。但文章的研究还存在不足之处,因为文章是采用均分的局部特征选择策略并没有考虑不同类别的影响程度,因此将来的研究可以在此基础之上提出更加完善的局部特征选择方法。
[1]新浪微博数据中心.http://mt.sohu.com/20170206/n479989368.shtml[EB/OL].[2017-03].
[2]Farzindar Atefeh,Weal Khreich.A Survey of Techniques for Event Detection in Twitter[J].Computational Intelligence,2015,31(1):132-164.
[3]王连喜.微博短文本预处理及学习研究综述[J].图书情报工作,2013,57(11):125-131.
[4]刘丽娟.基于LDA特征扩展的微博短文本分类[D].河北:燕山大学,2015.
[5]王细微.一种基于特征扩展的中文短文本分类方法[J].计算机应用,2009,29(3):843-845.
[6]黄贤英.一种新的微博短文本特征词选择算法[J].计算机工程与科学,2015,37(9):1761-1767.
[7]LI J,ChENG K,WANG S,et al.Feature Selection:A Data Perspective[J].2016.
[8]韩家炜.数据挖掘概念与技术(第3版)[M].机械工业,2012.
[9]廉捷.新浪微博数据挖掘方案[J].清华大学学报,2011,51(10):1301-1305.
[10]新浪.微博发现栏块微博分类页面[EB/OL].[2016-10-11].http://d.weibo.com/102803_ctg1_1199_-_ctg1_1199.
[11]单世超.分类程.[EB/OL].[2017-4-22].https://pan.baidu.com/s/1c1I7fLu.
[12]单世超.爬虫程序.[EB/OL].[2017-4-22].https://pan.baidu.com/s/1pLhTfuj
[13]单世超.有标签的微博语料集[EB/OL].[2017-4-22].https://pan.baidu.com/s/1geXZZWn.
Research on Chinese Text Classification Based on Partial Feature Selection
SHAN Shi-chao,LUAN Cui-ju
(College of Information Engineering,Shanghai Maritime University,Shanghai 201306)
Microblogging text because of short content,words and other disadvantages,making microblogging text is different from the usual text study.At present,there are many microblogging research,but the lack of appropriate microblogging corpus with tags,through the analysis of microblogging data acquisition program gives a suitable tag with the microblogging corpus,and then through the traditional classification algorithm for classification and verification.Due to the serious feature sparse problem,the global feature selection algorithm is easy to ig⁃nore the feature that is important to a certain category but has a small correlation degree to the corpus.Adopts the local feature selection scheme.The experimental results show that the local feature selection method can obtain higher classification effect.
1007-1423(2017)23-0011-06
10.3969/j.issn.1007-1423.2017.23.003
单世超(1992-),男,河南省许昌市,硕士研究生,主要研究方向:数据挖掘、软件设计;Email:1363180272@qq.com栾翠菊(1974-),女,吉林省梅河口市,副教授,博士,研究方向为智能决策、数据挖掘等
2017-05-04
2017-07-20
Microblogging;Chinese Text Classification;Global Feature Selection;Partial Feature Selection;WEKA
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19
南京理工大学学报(2021年4期)2021-09-15
小猕猴智力画刊(2021年6期)2021-08-05
小型微型计算机系统(2018年5期)2018-07-04
小学生作文·小学低年级适用(2018年12期)2018-04-11
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年15期)2016-07-04
校园英语·下旬(2016年2期)2016-03-18
作文大王·低年级(2016年3期)2016-03-11
中学理科·综合版(2008年3期)2008-03-07
