
InsunKBQA:一个基于知识库的问答系统
2017-11-08 12:11周博通孙承杰林磊刘秉权
智能计算机与应用 2017年5期
周博通 孙承杰 林磊 刘秉权

摘要: 针对大规模知识库问答的特点,构建了1个包含3个主要步骤的问答系统:问句中的命名實体识别、问句与属性的映射和答案选择。使用基于别名词典的排序方法进行命名实体识别,使用结合注意力机制的双向LSTM进行属性映射,最后综合前2步的结果从知识库中选择答案。该系统在NLPCC-ICCPOL 2016 KBQA任务提供的测试数据集上的平均F1值为0.809 7,接近已发表的最好水平。
关键词: 知识库; 自动问答; 语义相似度; 注意力机制
中图分类号: TP391
文献标志码: A
文章编号: 2095-2163(2017)05-0150-05
Abstract: To solve the specific problem in KBQA, the paper builds a question answering system based on large scale Chinese knowledge base. This system consists of three main steps: recognition of named entity in question, mapping from question to property in KB, and answering selection. In the research, use alias dictionary based ranking method to recognize named entity contained in question, and attention mechanism with bidirectional LSTM for questionproperty mapping. Finally, exploit results of first two steps to select the answer from knowledge base.The average F1 value of this system in NLPCCICCPOL 2016 KBQA task is 0.809 7, which is competitive with the best result.
Keywords: knowledge base; question answering; semantic similarity; attention mechanism
0引言
基于知识库的自动问答的核心在于对问句的语义理解。输入的问句是自然语言形式,而知识库中的信息却是结构化存储的,同时问句的表述与知识库中存储的信息的表述也存在较大的差异。如输入的问句为“请问华仔的妻子是谁啊?”,而知识库中相关的三元组为(“刘德华(香港著名歌手、演员)”,“配偶”,“朱丽倩”)。如何找到“华仔”与“刘德华”、“妻子”与“配偶”之前存在的联系,是解决这类问题的关键。
目前主流的研究方法可以分为2类:基于语义分析(Semantic Parsing-based, SP-based)的方法和基于信息检索(Information Retrieve-based, IR-based)的方法[1]。基于语义分析的方法首先将自然语言形式的问句转换为某种逻辑表达形式,如lambda表达式等,然后查询知识库,找到问题的答案。基于信息检索的方法首先通过粗略的方式从知识库中获取一系列的候选答案,然后抽取候选答案、问句与候选答案间的关系等方面的特征,对候选答案进行排序,选择排名靠前的作为最终的答案。
本文将基于知识库的自动问答分为2个步骤:命名实体识别和属性映射。在命名实体识别步骤中,本文使用基于排序的方法,首先构造别名词典以获取候选命名实体,然后对其进行排序;在属性映射步骤中,本文采用结合注意力机制的双向LSTM模型计算属性与问句的语义相关程度。
本文剩余部分的内容组织如下:第1节介绍了基于知识库的自动问答系统的国内外研究现状,第2节研究提出了具体命名实体识别和属性映射步骤采用的方法,第3节则探讨设定了所采用的数据集和评价指标,进而阐述展示了实验结果。
1国内外研究现状
基于知识库的自动问答系统在人工智能领域具有很长的发展历史。早期的研究主要针对小规模的专用知识库,使用的方法以语义分析为主。但这种方法往往需要人工标注“自然语言语句-逻辑表达形式”对,需要花费大量精力。后来研究人员利用问答对或其它形式的语料,基于弱监督学习方法进行语义解析。如前所述,目前主流的研究方法主要分为基于语义分析的方法和基于信息检索的方法两大类。基于语义分析的方法侧重于将自然语言形式的问句转换为某种逻辑表达式,常见的有lambda表达式[2]和依存组合语义树[3]等,然后从知识库中获取答案。
基于信息检索的方法侧重于抽取相关特征对候选答案进行排序。Yao等人[4]使用依存分析技术,获得问题的依存分析树,然后找到问句中涉及的主题,从知识库中找到对应的主题图Topic Graph,根据问题的依存树和主题图抽取特征,将其送入逻辑回归模型中进行排序。随着神经网络技术的不断进步, Bordes等人[5-6]使用前馈神经网络对候选答案的各方面信息设计生成编码,将问句和候选分别转换为维度相同的实数向量,最后以2个向量的点积作为候选答案的得分。Li等人[1]使用Multi-Column CNN分别对问句中隐含的答案类型、关系和上下文信息进行编码,同时对候选答案的这3类信息也给出了设计编码,最后对这3类信息的语义向量的点积经由加权处理得到最后的得分。Zhang等人[7]在文献[1]的基础上,使用注意力机制对于候选答案的不同内容训练不同的问句表示。
在中文领域,2016年的NLPCC-ICCPOL KBQA任务提供了一个大规模的知识库,在此基础上,展开了相关的研究工作。Wang等人[8]使用卷积神经网络和GRU模型进行问句的语义表示。Xie等人 [9]使用CNN网络研发命名实体识别,并使用BiLSTM和CNN具体实现属性映射。Yang等人[10]通过提取多种特征,使用GBDT模型探索推进命名实体识别研究,使用NBSVM和CNN支持设计属性映射。Lai等人[11]通过简单的词向量余弦相似度运算,结合细粒度的分词进行属性映射,同时结合多种人工构造的规则和特征,在该任务上取得了最好的效果。endprint
2基于LSTM模型和注意力机制的问答系统
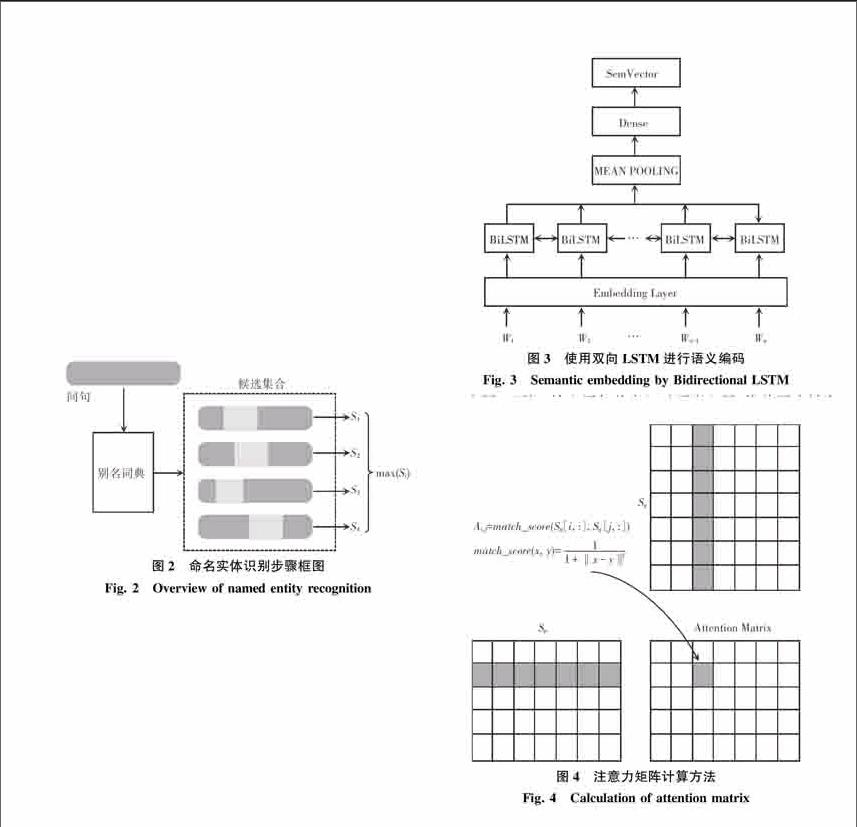
本文将基于知识库的自动问答拆分为2个主要步骤:命名实体识别步骤和属性映射步骤。其中,实体识别步骤的目的是找到问句中询问的实体名称,而属性映射步骤的目的在于找到问句中询问的相关属性。该系统的大体框图如图1所示。
如图1所示,输入的问句为“石头记是谁写的?”,首先通过实体识别步骤找出其中提及实体的部分“石头记”,进而找到知识库中所有正式名或别名为“石头记”的所有实体作为候选实体。如“红楼梦(小说)”和“红楼梦(电视剧)”;属性映射将候选实体的所有相关属性作为候选相关属性,在本例中即为“作者”、“创作年代”和“导演”,然后计算每个候选属性与问句剩余部分,即“__是谁写的?”的语义相关度,选择得分最高的属性“作者”;最后通过查询知识库,得到三元组(“红楼梦(小说)”,“作者”,“曹雪芹”),最终得到问题的答案“曹雪芹”。
2.1知识库简介及预处理
本文所采用的知识库由NLPCC-ICCPOL 2016 KBQA任務有效提供。该知识库是中文领域第一个大规模的通用知识库,包含6 502 738个实体、587 875个属性以及43 063 796个三元组。知识库文件中每行存储一个事实(fact),即三元组(实体、属性、属性值)。因此,该知识库本质上是一个三元组的集合。该知识库中的内容如表1所示。
同时,该知识库中存在同一实体的三元组分布在知识库文件中不同位置的情况。为了提高知识库查询的效率,本文将关于同一实体的所有三元组集中起来,并为知识库建立索引文件。索引文件每行的格式为:实体名、起始位置、内容长度,表示每个实体的所有内容在知识库文件中的起始位置和内容的总长度(均以字节为单位)。在知识库中查找某一实体时,首先从索引文件中获得该实体的起始位置和内容长度,直接从知识库文件中找到该实体的所有信息,而不用从头至尾遍历知识库,极大地提高了知识库的查询效率。
2.2命名实体识别
实体识别步骤的目的在于找出问题中询问的命名实体。该部分的大体框架如图2所示。首先根据别名词典查找问句中存在的所有命名实体作为候选。图2的候选集合中每个候选的浅色部分表示候选实体名及其在问句中的位置。此后通过模型为每个候选命名实体计算一个得分NER_SCORE,选取得分最高者作为正确命名实体。
2.2.1别名词典构建
本文首先构建一个别名词典,用于命名实体识别步骤的候选获取,同时也可以查找某个命名实体能够指代的所有实体。本文使用模版来匹配NLPCC知识库中具有别名意义的属性,抽取相关别名信息。如果一个属性能够匹配下列模版之一,则将其对应的属性值作为对应的实体的别名。具体情况如下所示:
1)以“名”结尾:别名、中文名、英文名、原名等。(第X名、排名等除外)。
2)以“称”结尾:别称、全称、简称、旧称等。(XX职称等除外)。
3)以“名称”结尾:中文名称、其它名称等。(专辑名称、粉丝名称等除外)。
除此之外,如果实体名中存在括号,如“红楼梦(中国古典长篇小说)”,则将括号之外的部分作为该实体的别名,即“红楼梦”作为实体“红楼梦(中国古典长篇小说)”的别名。如果实体名中包含书名号,如“《计算机基础》”,则将书名号内的部分作为该实体的别名,即“计算机基础”作为实体“《计算机基础》”的别名。根据上述方法,最终得到一个包含了7 304 663个别名的别名词典。
2.2.2候选命名实体排序
通过对大量问答样例的观察,本文抽取2个相关特征进行候选命名实体的排序,分别为候选命名实体的长度L(以字为单位)和逆文档频率(Inverse Document Frequency,IDF)。通过对2个特征的加权得到候选命名实体的得分。如下所示:
NER_SCORE=α*L+(1-α)*IDF[JY](1)
2.3属性映射
经过命名实体识别步骤,对于输入的问句“装备战伤理论与技术是哪个出版社出版的?”,可以得到其询问的命名实体“装备战伤理论与技术”。依据别名词典,可以找到知识库中以该命名实体为正式名或别名的所有候选实体,本例中只有一个实体:一本名为“装备战伤理论与技术”的书籍。知识库中关于该实体的三元组共5个,其属性分别为“别名”、“中文名”、“出版社”、“平装”和“开本”。属性映射步骤的目的在于找出这5个候选属性中与问句语义最为相近的属性,该属性即为问句询问的内容。
本文使用长短时记忆网络(Long Short Term Memory,LSTM)对问句和属性进行编码,得到对应的语义向量,计算这2个向量的余弦相似度来表示问句与属性的语义度。
在对数据进行观察和简单实验后,研究发现属性映射阶段的重点在于找到属性中的单词与问句中的单词的对应关系。如问句“请问西游记是什么时候写的?”与知识库中的属性“创作年代”就存在这种对应关系:“创作”和“写”、“年代”和“时候”,而这种对应关系可以通过这种注意力机制更好地发现。因此,本文根据文献[12]中应用于卷积神经网络的注意力机制的启发,融合注意力机制与卷积神经网络进行属性映射。
2.3.1基于双向LSTM的语义编码
使用双向LSTM对输入的问句和属性独立进行编码,得到对应的语义向量,如图3所示。
由图3可知,输入语句首先经过词嵌入层,将单词映射为固定维度的词向量。然后送入双向LSTM中,将双向LSTM每一时刻的输出取平均,将得到的结果送入一个全连接层,最终得到输入语句对应的语义编码。
2.3.2基于单词语义相似度的注意力机制
本节对研究应用的注意力机制进行具体介绍。该注意力机制首先需要计算一个注意力矩阵,如图4所示。endprint
2.3.3额外词汇特征
为了进一步提高属性映射的结果,本文抽取2个额外的词汇特征,然后与双向LSTM的输出一起送入逻辑斯蒂回归模型中,得到属性映射步骤的最后得分PROP_SCORE。人工选择的特征根据属性与问句的重叠长度(以字为单位)计算,即属性与问句中共有的字的个数除以属性的长度得到特征OVP,除以问句的长度得到特征OVQ。
2.4答案选择
[2.4.1命名实体重排序
在选择答案前,首先使用属性映射步骤的得分对命名实体识别的结果进行重排序。假如在实体识别步骤,正确的命名实体没有排在第一位,在属性映射步骤,其候选属性的最高得分仍然会高于错误的命名实体。考虑问题“李军医生是什么学校毕业的”,在命名实体识别步骤,正确的命名实体“李军”的得分2.81要低于“军医”的得分3.23。但“李军”对应的属性识别步骤的最优相关属性为“毕业院校”,得分为0.97,该分数要远高于“军医”对应的最优属性识别“出版社”的得分0.30。由表4可以看出,在測试集上该模型的准确率可以达到94.56%,而正确候选得分排在前3位(Top3)的样例已经达到99.13%。
本文使用中文维基百科作为语料,使用Google word2vec工具训练词向量,词向量维度为300。属性映射步骤的BiLSTM的隐含层为200维。在进行模型训练时,由于数据集中正例远少于负例,因此本文将正例进行重复,达到与负例相同的程度,最终正负例比例为1∶1。表5给出了指定几种模型的训练和测试结果。
[官方评测最终结果采用的评价指标为平均F1值。由于每个样例的标准答案和候选答案均为集合的形式,因此每个样例都可以得到一个F1值,最后取所有样例F1值的平均。
选用在属性识别上取得最好结果的模型。经过在NLPCC问答数据集上进行实验,发现当对命名实体识别重排序的权重α取0.3时,可以取得最好的问答结果。在NLPCC提供的数据集上进行实验,得到实验结果如表6所示。
从表7和表8中可以看出,使用属性映射步骤的结果对候选命名实体进行重排序后,命名实体识别的准确率有了很大的提升,问答的准确率也随之提升。
与参与NLPCC-ICCPOL 2016 KBQA评测任务的所有结果相比,前2名的结果分别为0.824 4与0.815 9。但这两者都使用了其它较复杂的特征和人工规则。本文在仅使用神经网络模型和少量简单文本特征的情况下,取得了与其接近的效果,证明了本文提出的模型在该任务上的有效性。
4结束语
实体识别和属性映射是构建基于大规模知识库问答系统的2个难点,本文提出了相应的方法解决这2个挑战。在展开实体识别研究时,首先采用别名词典获取候选,然后抽取相关特征进行排序。在探讨属性映射时,考虑到属性与问句中的词对应关系,使用结合注意力机制的双向LSTM模型,再结合简单文本特征获取正确的属性。在得到属性映射的结果后,利用其对命名实体识别的结果进行重排序,然后实现答案选择。本文构建的问答系统在NLPCC-ICCPOL 2016 KBQA任务的数据集上取得了接近目前已发表最好成绩的效果。
参考文献:
LI Dong, WEI Furu, ZHOU Ming, et al. Question answering over freebase with multicolumn convolutional neural networks[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Beijing, China:ACL, 2015:260-269.
[2] ZETTLEMOYER L S, COLLINS M. Learning to map sentences to logical form: Structured classification with probabilistic categorial grammars[C]// Proceeding UAI'05 Proceedings of the TwentyFirst Conference on Uncertainty in Artificial Intelligence. Edinburgh, Scotland:ACM, 2005:658-666.
[3] BERANT J, CHOU A, FROSTIG R, et al. Semantic parsing on freebase from questionanswer pairs[C]// EMNLP. Seattle, Washington, USA:ACL, 2013: 6.
[4] YAO X, DURME B V. Information extraction over structured data: Question answering with freebase[C]// Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. Baltimore: ACL, 2014: 956-966.
[5] BORDES A, CHOPRA S, WESTON J. Question answering with subgraph embeddings[J]. arXiv preprint arXiv:1406.3676, 2014.endprint
[6] BORDES A, WESTON J, USUNIER N. Open question answering with weakly supervised embedding models[C]//ECML PKDD 2014 Proceedings of the European Conference on Machine Learning and Knowledge Discovery in Databases. Nancy, France:ACM, 2014: 165-180.
[7] ZHANG Y, LIU K, HE S, et al. Question answering over knowledge base with neural attention combining global knowledge information[J]. arXiv preprint arXiv:1606.00979, 2016.
[8] WANG Linjie, ZHANG Yu, LIU Ting. A deep learning approach for question answering over knowledge base[M]// LIN C Y, XUE N, ZHAO D, et al. Natural Language Understanding and Intelligent Applications. ICCPOL 2016, NLPCC 2016. Lecture Notes in Computer Science, Cham:Springer, 2016: 885-892.
[9] XIE Zhiwen, ZENG Zhao, ZHOU Guangyou, et al. Knowledge base question answering based on deep learning models[C]// LIN C Y, XUE N, ZHAO D, et al. Natural Language Understanding and Intelligent Applications. ICCPOL 2016, NLPCC 2016. Lecture Notes in Computer Science. Cham:Springer, 2016: 300-311.
[10]YANG Fengyu, GAN Liang, LI Aiping, et al. Combining deep learning with information retrieval for question answering[C]//LIN C Y, XUE N, ZHAO D, et al. Natural Language Understanding and Intelligent Applications. ICCPOL 2016, NLPCC 2016. Lecture Notes in Computer Science. Cham:Springer, 2016: 917-925.
[11]LAI Yuxuan, LIN Yang, CHEN Jiahao, et al. Open domain question answering system based on knowledge base[C]// LIn C Y, XUE N, ZHAO D, et al. Natural Language Understanding and Intelligent Applications. ICCPOL 2016, NLPCC 2016. Lecture Notes in Computer Science. Cham: Springer,2016: 722-733.
[12]YIN W, SCHTZE H, XIANG B, et al. Abcnn: Attentionbased convolutional neural network for modeling sentence pairs[J]. arXiv preprint arXiv:1512.05193, 2015.endprint
猜你喜欢
计算机应用文摘·触控(2021年21期)2021-12-13
智能计算机与应用(2019年3期)2019-07-01
电子技术与软件工程(2019年5期)2019-06-20
知识文库(2019年2期)2019-06-11
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
管理观察(2018年7期)2018-05-09
现代电子技术(2018年8期)2018-04-13
出版广角(2017年17期)2018-01-09
软件工程(2017年11期)2018-01-05
