
基于Hadoop的ADS-B数据解析与存储方法*
2017-11-21 04:23冯兴杰
航天控制 2017年5期
冯兴杰 刘 芳
1.中国民航大学计算机科学与技术学院,天津 300300 2.中国民航大学信息网络中心,天津 300300
基于Hadoop的ADS-B数据解析与存储方法*
冯兴杰1,2刘 芳1
1.中国民航大学计算机科学与技术学院,天津 300300 2.中国民航大学信息网络中心,天津 300300
广播式自动相关监视系统(Automatic Dependent Surveillance-Broadcast,ADS-B)是国际民航组织(ICAO)推荐使用的集数据通信、卫星导航和监视技术于一体的新一代航空器运行监视系统,可以自动的接收和发送飞机及其周围的信息。随着监视区域内航班数量的增加,对于以秒为单位进行收发信息的ADS-B而言,单机环境已经无法满足海量ADS-B数据的解析、存储与分析,本文利用Mapreduce模型提供的高效分布式编程和运行框架对ADS-B数据进行解析,将解析后的数据存储到基于Hive的ADS-B数据仓库,并通过Mysql建立的索引表联合Hive中的分桶操作对信息种类进行划分,有效提高了数据解析效率并避免了Hive中索引不完善引起的查询效率低的问题。实验表明对于海量的ADS-B数据,利用Mapreduce进行解析并利用Hive进行存储分析的效率明显提升。
ADS-B;Hadoop;Mapreduce;Hive;解析;存储;分桶
ADS-B是基于GPS定位和地/空数据链通信的航空器运行监视系统,是国际民航组织(ICAO)推荐使用的集数据通信、卫星导航和监视技术于一体的新一代航行系统的重要组成部分[1]。ADS-B技术通过给飞行员提供更多的飞机及其周边环境信息,提升了空中交通安全的可靠性和准确性。相对于雷达技术来说具有数据更新速率快、数据精度高、全天候运行和成本低等特点。MH370等一系列航班失事事件加速了全球民航界对飞机飞行定位系统和航线追踪技术的研究。美国 FlightAware公司和 Aireon公司已经开始合作研发GlobalBeacon系统,拟通过铱星提供星基 ADS-B 服务,计划 2018 年投入运营,并将在 2021 年实现 1 分钟间隔飞行追踪的要求[2]。
近年来,中国民用航空运输业务迅速发展,2015年统计的全国起降架次达到1040万架,并且仍以16%的速度持续增长。为了在快速增长的同时有效保证空中交通安全,国家正有计划地加快ADS-B等新技术的部署。通过ADS-B接收并存储的海量数据不仅可以分析航迹信息,还可以更加准确地预测飞机预计到达时间,提高飞机正点率。
1 相关工作
目前,针对ADS-B技术的研究主要集中在硬件系统的实现、单机环境下解析以及航迹安全间隔分析等方面。例如,文献[3]对ADS-B数据的解码以及其他数据的融合。文献[4]实现了ADS-B关键应用软件系统。文献[5]提出运用危险碰撞模型评估航路安全间隔,并将其运用在ADS-B航迹数据上。文献[6-7]分别研究了基于ADS-B数据和GPS数据融合,并验证了其航迹信息的准确性。文献[8]提出了基于JSON格式实现ADS-B数据的分类管理。以上文献对ADS-B数据的处理以及存储都是在单机环境下进行的。但是,面对越来越大的数据量,普通的存储和分析平台已经无法满足需求,需要将数据解析和存储移植到分布式计算环境下。文献[9]将按CAT033协议解析出来的ADS-B数据直接存储在Hive中,利用GIS工具对其航迹信息进行分析。但是没有对数据进行数据仓库的构建,不利于后续数据的扩展。
分布式计算环境是将数据的存储、分析和计算等建立在网络之上由多个服务器构成的集群。基于Hadoop的Mapreduce分布式框架是典型的分布式计算环境,将ADS-B海量数据的解析放入Mapreduce框架中,能够提高处理数据的速率。同时,利用Hive数据仓库存储ADS-B数据能较好地满足航空公司分析数据的需求。与传统的XML,JOSN或者数据库等存储格式相比具有更高的扩展性。
本文提出基于Hadoop的ADS-B数据解析与存储方法,其基本思路是:首先研究1090兆赫扩展电文(1090MHz ES)ADS-B的数据格式和解码方法,然后实现基于Mapreduce框架数据解析算法,并将处理后的数据导入基于Hive的ADS-B数据仓库。
2 ADS-B报文数据结构及解析方法
2.1 ADS-B系统
现行的ADS-B系统一般采用3种典型的数据链架构,分别是UAT数据链、VDL-4数据链和Mode S数据链。本文主要围绕中国民航大学自行开发的ADS-B系统开展研究,该系统基于Mode S模式应答机技术(1090 MHz Extended Squitter) ,采用脉冲位置编码在下行频率为1090MHz的数据链上进行数据传输。被传输的每一个脉冲被分为2部分:前半部分都为1,其余的都是0。由于ADS-B系统采用固定长度报文进行传输,描述一个飞机的完整信息需要连续解析、综合多个报文才能得到。另外,根据描述飞机不同的状态特征(如:位置、速度及飞机标识等),消息更新的频率也不同。例如,关于位置和速度的消息每0.4~0.6s广播一次,关于飞机标识的信息每4.8~5.2s广播一次,关于意向改变消息每1.6~1.8s广播一次[10]。对于接收到的多条ADS-B报文,需要根据1090ES编码标准综合为一条完整的飞机描述信息。图1为ADS-B消息的传输波型图。

图1 ADS-B消息传输波形
2.2 ADS-B报文数据结构
ADS-B报文长度为112比特,采用16进制编码。根据RCTA[10]标准, ADS-B 报文的基本结构为: Bit 1-5为下行链路格式域(DF),DF在取不同值时有不同的含义。 DF=17格式表示S模式应答机发射的ADS-B消息;DF=18格式表示用于非S模式应答机发射的ADS-B消息或者TIS-B消息;DF=19格式预留为军事应用[11]。Bit 6-8为CA域,表示S模式应答机能力;Bit9-32为AA域,表示应答机24比特ICAO地址; Bit 33-88为ADS-B消息域ME,承载飞行器报告的重要状态信息,其中前 5个比特为消息类型字段,随后的3个比特为消息子类型,剩余的48个比特为飞行器状态信息;最后的24比特为校验域 PI[11]。图2为ADS-B消息格式结构。

图2 ADS-B消息格式结构
2.3 ME字段的解析
飞行器状态信息位于ADS-B报文的33-88位的ME字段中,根据消息类型字段的不同,此字段中可能包含空中位置消息、地表位置消息、飞机ID与类型消息、空中速度消息、航线改变消息以及飞机运行状况消息等。参考RCAT[10]标准,对接收到的ADS-B原始编码报文进行解析,得到飞机实时的位置以及周边信息。在解析过程中,需要根据接收报文的消息种类字段,运用相对应的算法进行解析,核心的算法有用于解析航班号的IA5算法、用于解析经纬度的CPR算法[12-13]、用于解析高度和速度的格雷算法。其中CPR算法又分为全球解码和本地解码,具体情况要根据接收到消息的奇偶性进行判断。具体报文解析算法流程图如图3。

图3 ADS-B报文信息解析
3 Hadoop相关技术
3.1 Hadoop
Hadoop是一个分布式处理大数据的软件平台,提供了一种分布式并行编程的框架,它包含Mapreduce和HDFS(Hadoop Distributed File System)这2个核心模块,其中Mapreduce是一种分布式编程模式,将普通的编程模式用Mapreduce框架进行分布式运算处理,而HDFS是一种分布式的文件系统,为整个系统提供底层的存储支持。在这2个核心框架之上有一系列的分布式处理软件,例如Hive,Hbase,Pig等。总体来说,就是在Hadoop的分布式框架上采用Mapreduce的运算模式在大规模集群中处理海量数据,并将处理后的数据存储在HDFS上[14]。
3.2 Mapreduce
Mapreduce 主要支持基于集群的海量数据分布式计算,是在庞大数据集上执行高度并行化和分布式算法的框架[15]。其执行过程为:Mapreduce框架将输入的数据分成大小相同的数据块,通过map接收并形成
3.3 Hive
Hive中包含的组件有CLI(command line interface),JDBC/ODBC,Thrift Server,WEB GUI,MetaStore和Driver(Complier,Optimizer和Executor)。它建立在Hadoop上,是基于Hadoop一个数据仓库工具,能将结构化的文件映射为一张数据库表,并提供完好的sql查询性能,能对存储在Hadoop中的大规模历史数据进行批量处理操作。Hive将简单定义的sql语句称为hql,将hql语句转化成Mapreduce任务来提高查询速率。它没有具体定义数据的格式,用户可以灵活地自定义类型格式,并且能够存储struct,map和array结构的数据。
但是Hive中的索引优化还不完善,在查询海量数据时,在索引表中找到需要查询的记录,获取到该记录在HDFS中的文件名以及偏移量,用一个map 任务进行查询,理论上减少了扫描全表的时间,但是每次查询都会用一个job扫描索引表。假设索引表的列值非常稀疏,那么索引表自身也会十分大,这样反而增加了查询负担。文献[16]中将数据划分主题,构建数据仓库,利用Mysql索引表存储主题编号,在Hive中按照Mysql中的主题编号对主题进行分桶,根据主题序号只需要查找一个桶的数据,从而提高了查询速率。但是本文是直接解析的海量ADS-B数据,对解析出来的数据进行融合分析,直接利用Hive中的分区分桶操作。
4 基于Hadoop的ADS-B数据平台搭建
4.1 数据仓库的总体架构
基于Hive的ADS-B数据仓库的设计最终目标是为了更高效地分析数据,为了更好的划分ADS-B数据信息的主题,以便为民航安全提供更好的辅助决策,提高航空公司的效益,所以系统架构主要由5层构成:数据源、数据解析、数据存储、数据分析及应用层, 如图4所示。其中,数据源层的数据是通过ADS-B接收机接收到的真实数据,原始数据以28位十六进制编码的格式存储在TXT文件中,在传递过程中可能会出现缺失、错位等情况。
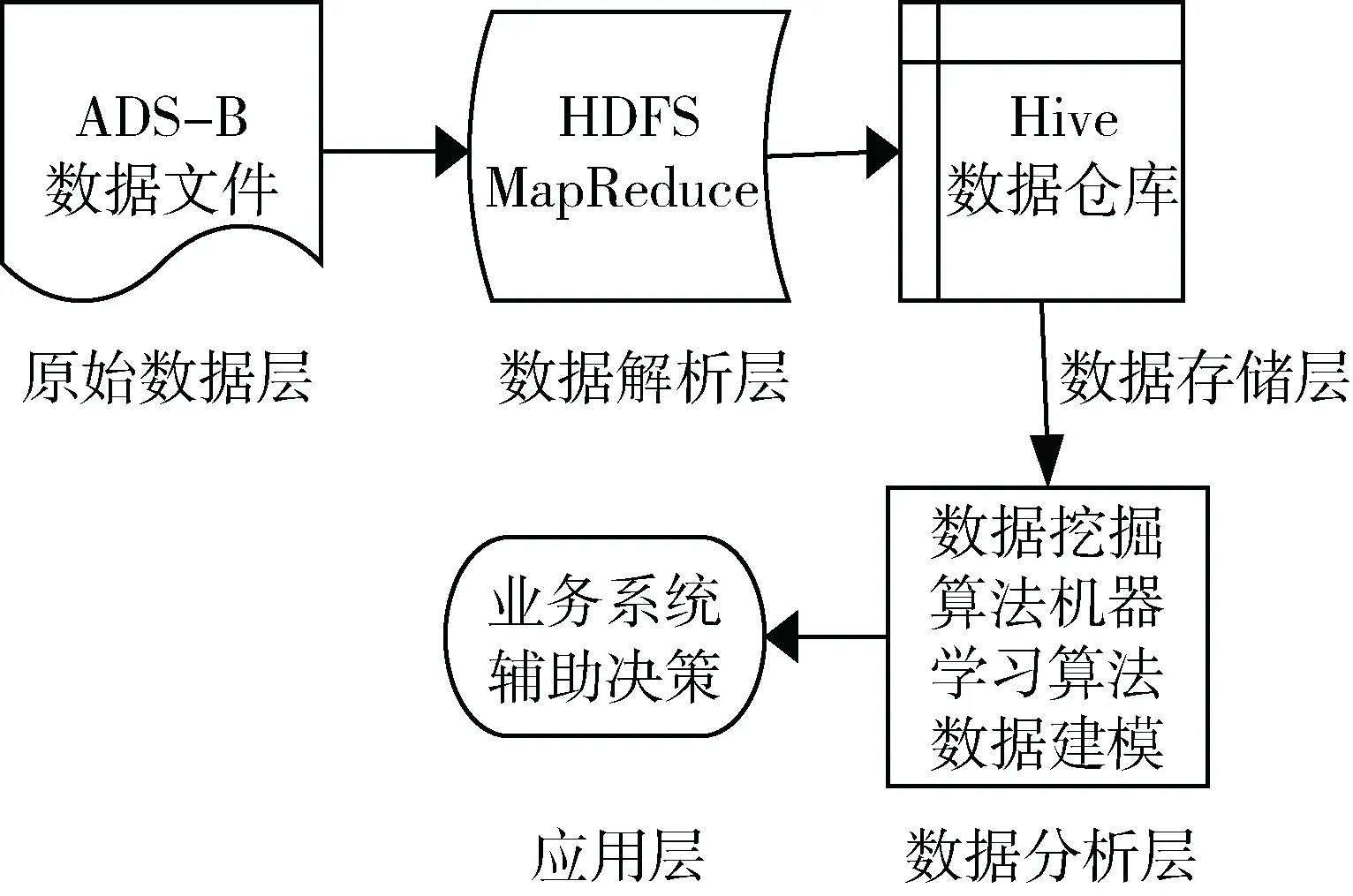
图4 数据仓库的架构
数据解析层主要在分布式文件系统下,根据标准结合Mapreduce框架对搜集到的海量数据进行解析,通过Map将每一条数据的ICAO地址作为key,将其余信息作为value进行并行处理,同时在value值中根据标准将数据进行解析。将Map处理的数据进行Reduce计算,将相同的ICAO键放在一起,对应相应的value值。
数据存储层是将解析后的数据通过Hive数据仓库进行存储、分类和提取,结合Mysql将数据按消息种类存储,即能存储海量数据,又能提高查询速率,方便以后对数据的扩展以及分析。
数据分析和前端应用层是利用聚类分析、频繁挖掘和机器学习等方法对Hive中的数据进行处理,更好地分析其航迹安全,航迹间隔,提高经济效益[17-19]。为实现真正的“自由飞行”提供良好的决策作用。
4.2 基于Mapreduce的ADS-B数据解析
文献[3-4]是基于单机环境下设计实时ADS-B数据解析系统,对于海量历史数据的分析以及存储没有提及。本文改进了单机环境下的基于Mapreduce的解析算法,有效处理海量ADS-B历史数据,对以后在分布式平台下的数据挖掘提供基础。
Mapreduce的运行机制可以分为4部分:slipt,map,shuffle和reduce。在map处理完成后由shuffle将相同key值的value整合成一个list,交给reduce计算。由于ADS-B数据的收发都是以毫秒进行的,但是本文中接收机接收到数据的时间只显示到秒,所以在每秒都会有若干不同或者重复的数据出现。因此,本文将ICAO地址作为key值,时间以及其他信息作为value值传入map,在reduce阶段对shuffle中同一架飞机的list列表进行数据预处理。预处理阶段包括去除重复的数值,填充缺失值,对飞机高度、速度及方向等有明显错误的数据进行清洗。具体过程如图5。

图5 Mapreduce处理
4.3 数据存储策略
由于解析的历史ADS-B数据是不同航班不同时刻不同消息类型的混合数据,为了今后对数据的挖掘处理,需要将数据进行融合,整合成每个时间点对应的一条完整的航迹信息。所以本文将数据按照消息种类的不同划分为不同的主题,在Mysql中实现主题序号的存储,与Hive中的ADS-B数据仓库构成星型结构[20]。主题表的划分如图6所示。在Hive中使用Mysql替代分区功能定位到数据所在的位置,根据主题编号将数据分成多个桶。在查询数据时针对其中一个桶进行操作,这样的存储结构不仅提升对海量数据的查询速率,在对航迹信息进行分析时可以随时查询一个航班不同日期的航迹,还可以查询同一个时间段内不同航班的航迹。
其中,ICAO代表飞机标识的唯一地址,Time是接受数据的时间,ADS-B数据每秒广播的消息是关于速度、位置、高度、飞机航班号等中的任何一条,但是每条消息中都会广播ICAO地址,所以在Mysql中建立时间、ICAO和各种消息类型的编码,将每条信息的具体消息存放于Hive数据仓库中,根据消息编号查找其中一个桶中的信息,提高Hive中的查询速率,避免Hive数据仓库中索引不完善的缺陷。建立的基于Hive的数据仓库不仅有利于以后对更多消息的扩充,还可以高效地查询一个航班某个时间的各种信息,节约空间和时间,为之后对航迹安全和航空公司经济效益的分析提供决策。

图6 Hive数据仓库构建
5 实验与分析
5.1 实验环境与数据
实验使用的数据是中国民航大学的ADS-B接收机接收的真实数据,共 10G。实验环境由9台电脑组成的,Hadoop集群搭建在32位Ubuntu14.04操作系统上。主节点配置为i7-3770处理器,4G内存,1T硬盘。从节点配置使用的是e2140处理器,1G内存,250G硬盘,集群版本Hadoop2.4.0 。
5.2 实验结果与分析
挖掘分析历史ADS-B数据就要解析接收到的
海量原始数据,所以第1项测试的目的是对比单机环境下解析海量ADS-B历史数据与Hadoop集群环境下通过Mapreduce解析数据的耗时量,实验结果如图7所示。

图7 解析对比耗时
从对比实验中可以看出单机情况下,随着数据量越大耗时越长;相反,集群中数据量增多的情况下耗时比率缓和增长,对于分析海量ADS-B历史数据来说,集群通过分布式并行解析ADS-B数据具有明显的优势。
第2项测试是对比将解析后的不同大小的数据量分别导入Mysql和Hive中后查询某个航班每天每个时间航迹和同一天每个时刻所有航班航迹信息的速率。结果如图8和9所示。

图8 查询某个航班耗时对比

图9 查询某天航迹耗时对比
通过对比可以看出,对于查询信息,小数据量的查询在Mysql中的速率大于Hive,但是数据量一旦增加,Mysql中的查询耗时明显增加;相反,在Hive中查询耗时缓慢的增加。
对于查询航班航迹信息来说,同一天所有航班的航迹信息有助于分析超限事件,同一航班不同天的航迹有助于分析轨迹异常检测。
第3项实验是对780cc0航班一周的航迹信息和2016/07/13日所有航班航迹信息的显示,该实验使用GIS Tools for Hadoop工具,通过自定义UDF将其运用在自己的ADS-B数据中,并使用MapInfo在地图中显示出来,如图10和11所示(图中不同线条代表不同的日期或者不同的航班。)。

图10 780cc0航迹

图11 2016/07/13航迹显示
通过ADS-B传递出的海量航迹信息可以更加精确地分析航迹安全问题和航迹异常行为检测。
目前文献中,针对ADS-B数据的处理都是单机实现解析,并且没有存储在Hive数据仓库中。基于Hive的ADS-B数据仓库的建立可以更方便对数据进行挖掘分析,结果也更精确,同时Hive数据仓库有较好的扩展性,随着ADS-B的不断发展,其在Hive中存储也将不断的完善。
6 结束语
对于航空公司来说,随着民航的不断发展,机场的不断扩建,飞机的数量也在剧烈增加,解析并且存储海量的历史数据对分析航迹信息,促进经济效益,提高飞行安全十分必要。国内ADS-B系统在不断完善,针对现有ADS-B海量历史数据解析和存储方面的问题,本文设计了针对ADS-B数据基于Mapreduce并行的解析,提高了海量ADS-B历史数据的解析速率,通过构建Hive仓库进行存储,为以后的数据挖掘与分析提供更好的平台。下一步将在Hadoop中利用数据挖掘算法或者机器学习方法对Hive中的数据进行航迹安全间隔分析或者对多维轨迹异常进行检测分析。
[1] 熊辉. 基于 C/S 架构的 ADS-B 区域数据中心系统设计[J]. 科技创新与生产力, 2016,(3):59-61.(Xiong Hui. ADS-B Regional Data Center System Design Based on C/S Architecture [J]. Science and Technology Innovation and Productivity, 2016(3):59-61.)
[2] 王元元.值得关注的商用航空技术[N]. 中国航空报, 2017.1.19.(Wang Yuanyuan. Noteworthy Commercial Aviation Technology [N]. China Aviation News, 2017.1.19 (007).)
[3] 王琦. 基于ADS-B的飞行航迹获取研究与实现[D]. 吉林大学, 2015.(Wang Qi. Research and Implementation of Flight Path Acquisition Based on ADS-B [D]. Jilin University, 2015.)
[4] 宋伟. 基于ADS-B数据的航迹处理子系统设计与实现[D]. 电子科技大学, 2012.(Song Wei. Design and Implementation of Data Based Track Processing Subsystem [D]. University of Electronic Science and Technology of China, 2012.)
[5] 王红勇,王晨,赵嶷飞. 基于ADS-B统计数据的航路安全间隔研究[J]. 中国安全科学学报,2013,(2):103-108.(Wang Hongyong, Wang Chen, Zhao Yifei. Research on Air Route Safety Separation Based on ADS-B Statistical Data [J]. China Safety Science Journal, 2013, (2): 103-108.)
[6] Christoph Reck, Max S Reuther, Alexander Jasch. Verification of ADS-B Positioning by Direction of Arrival Estimation[J]. International Journal of Microwave and Wireless Technologies, 2012,4(2):181-186.
[7] Busyairah Syd Ali1,Wolfgang Schuster,Washington Ochieng. Analysis of Anomalies in ADS-B and Its GPS Data[J]. GPS Solut, 2016(20):429-438.
[8] 姜建,王泽渟,高伟成. 基于JSON的ADS-B数据管理策略研究[J]. 信息与电脑,2016,(3):40-41.(Jiang Jian, Wang Zeting, Gao Weicheng. Research on ADS-B Data Management Strategy Based on JSON [J]. China Computer & Communication, 2016, (3): 40-41.)
[9] E Boci,S Thistlethwaite. A Novel Big Data Architecture in Support of ADS-B Data AnalyticC[C].Integrated Communications Navigation and Surveillance Conference (ICNS),Herdon,VA,USA,2015.
[10] RTCA DO-260B.Minimum Operational Performance Standards for 1090MHZ Automatic Dependent Surveillance-Broadcast(ADS-B)[S].2003.
[11] 胡俊. 1090ES ADS-B接收机嵌入式软件设计[D].电子科技大学,2010.(Hu Jun. Embedded Software Design of 1090ES ADS-B Receiver [D]. University of Electronic Science and Technology of China, 2010.)
[12] 许亮. 1090ES广播式自动相关监视系统的报文接收与解析[D].吉林大学,2015.(Xu Liang. 1090ES Automatic Dependant Surveillance-Broadcast System′s Message Receiving and Parsing[D]. Jilin University, 2015.)
[13] 丁维昊. 1090ES ADS-B系统中CPR算法与实现[J]. 指挥信息系统与技术,2016(2):57-62.(Ding Weihao. Compact Position Report(CPR) Algorithm and Its Realizatoin in 1090ES ADS-B System [J]. Command Information System and Technology, 2016(2): 57-62.)
[14] 刘云飞. 基于Hadoop的数据迁移与存储的研究[D]. 北京邮电大学, 2015. (Liu Yunfei. Researsh of Data Migration and Storage Based on Hhdoop[D]. Beijing University of Posts and Telecommunications, 2015.)
[15] 熊倩,张郭明,徐婕. Mapreduce Shffule性能改进[J]. 计算机应用,2017,(S1):1-11. (Xiong Qian, Zhang Guoming, Xu Jie. Improvement of Mapreduce Shffule Performance[J]. Journal of Computer Applications, 2017, (S1): 1-11.)
[16] 冯兴杰,吴稀钰,赵杰.QAR数据仓库在Hive中的构建[J].计算机工程与应用,2017,53(11):90-94. (Feng Xingjie, Wu Xiyu, Zhao Jie. QAR Data Warehouse Room Construction [J] Computer Engineering and Applications, 2017,53(11):90-94.)
[17] 毛嘉莉,金澈清,章志刚. 轨迹大数据异常检测:研究进展及系统框架[J]. 软件学报,2017,28(1):17-34. (Mao Jiali, Jing Cheqing, Zhang Zhigang. Anomaly Detection for Trajectory Big Data: Advancements and Framework [J]. Software, 2017, 28(1): 17-34.)[18] 潘新龙,王海鹏,何友,等. 基于多维航迹特征的异常行为检测方法[J]. 航空学报,2017,38(4):254-263.(Pan Xinlong, Wang Haipeng, He You, et al. Abnormal Behavior Detection Method Based on Multidimensional Trajectory Characteristics [J] .Acta Aeronautica Et Astronautica Sinica, 2017,38(4):254-263.)
[19] 王全跃,朱海涛,马瑞霞. 基于数据挖掘的ADS-B航迹数据偏差分析方法研究[J]. 科技创新与应用,2014,(13):35-36. (Wang Quanyue, Zhu Haitao, Ma Ruixia. Studies ADS-B Track Data Variance Analysis Based on Data Mining Method [J].Innovation Technology and Application, 2014, (13): 35-36.)
[20] 郇秀霞,王红. 基于数据仓库的QAR数据分析[J]. 计算机工程与设计,2008,(10):2685-2688. (Huan Xiuxia, Wang Hong. QAR Data Analysis Based on Data Warehouse [J]. Computer Engineering and Design, 2008, (10): 2685-2688.)
TheDataAnalysisandStorageofADS-BBasedonHadoop
Feng Xingjie1,2, Liu Fang1
1.College of Computer Science & Technology, Civil Aviation University of China, Tianjin 300300, China 2. Information Network Center, Civil Aviation University of China, Tianjin 300300, China
Automaticdependentsurveillance-broadcas(ADS-B)isanewgenerationofaircraftoperationmonitoringsystemthatintegratesdatacommunications,satellitenavigationwithsurveillancetechnologyrecommendedbytheinterbationalcivilaviationorganization(ICAO)canreceiveandsendtheinformationoftheaircraftandit’ssurroundingautomatically.Withtheincreasingnumberofflightswithinthesurveillancearea,fortheADS-Binsecondstosendandreceiveinformation,thestand-aloneenvironmenthasbeenunabletomeetthemassiveADS-Bdataanalysis,storageandanalysis.Inthispaper,theADS-BdataisparsedbyusingtheefficientdistributedprogrammingandruntimeframeworkprovidedbytheMapreducemodel.TheparseddataisstoredintheADS-BdatawarehousebasedonindextablecreatedbyMysqlcombinedwiththebucketinHiveoperationtoclassifythemessage,whicheffectivelyimprovestheefficiencyofdataanalysisandavoidstheproblemthatthequeryefficiencycausedbyimperfectindexinHiveislow.
*国家自然科学基金委员会与中国民用航空局联合基金项目(U1233113)
RegardingthemassiveandhistoricaldataofADS-B,itisproventhattheparsingbymap-reduceframeandefficiencyofstorageanalysisbyHiveispromotedobviously.
ADS-B; Hadoop; Mapreduce; Hive;Parsing;Storage;BucketADS-B

V19
A
1006-3242(2017)05-0080-07
2017-05-24
冯兴杰(1969-),男,天津人,博士,教授,主要研究方向为云计算、数据仓库和智能信息处理;刘芳(1992-),女,山西人,硕士研究生,主要研究方向为云计算、智能信息处理。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
青年歌声(2019年12期)2019-12-17
当代陕西(2019年14期)2019-08-26
自然资源信息化(2019年4期)2019-03-29
北京航空航天大学学报(2017年7期)2017-11-24
电子制作(2016年15期)2017-01-15
山东工业技术(2016年15期)2016-12-01
北京航空航天大学学报(2016年6期)2016-11-16
中学数学杂志(初中版)(2016年5期)2016-11-01
中国教育信息化(2015年10期)2015-08-23
