
基于数据挖掘的育龄妇女二孩生育意愿预测
2017-12-07 02:03李冬领
软件 2017年11期
李冬领
(南京邮电大学经济学院,江苏 南京 210046)
基于数据挖掘的育龄妇女二孩生育意愿预测
李冬领
(南京邮电大学经济学院,江苏 南京 210046)
探讨数据挖掘模型与传统的Logistic回归模型在育龄妇女二孩生育意愿预测上的准确性。采取五折交叉验证法,基于正确率、查准率、查全率、AUC和Press'Q检验这五个指标对四种分类方法(Logistic回归、支持向量机、决策树和随机森林)进行对比分析。结果表明:Press'Q的值均大于 3.84,说明所有分类方法均好于随机分类结果;从各指标均值看,随机森林表现最好,与Logistic回归相比,其正确率高1.7%,查准率高3.2%,查全率高0.2%,ROC曲线下的面积大0.3,Press'Q的值大1.7。本研究探索的数据挖掘新方法和模型,可为今后研究类似二孩生育问题提供新的思路和尝试。
数据挖掘;二孩生育意愿;建模;预测
0 引言
从我国2013年开始实施“单独二孩”政策, 到2015年 10月全面实施一对夫妇可生育两个孩子的政策,二孩生育意愿一直是学者们研究的热点问题。学者在研究育龄妇女二孩生育意愿时大都采用描述性统计分析和 Logistic回归的方法,而现实中影响育龄妇女生育意愿因素很多,许多不显著因素的综合作用可能会对生育意愿产生较大影响,但只有显著变量才可以引入Logistic回归模型中,因此Logistic回归方法不一定能够准确的对生育意愿进行判别和预测。数据挖掘的方法广泛应用于分类数据的判别与预测,在自然科学研究领域已广泛应用,但在人文科学研究领域还很少见。本文尝试采用数据挖掘的方法对育龄妇女二孩生育意愿进行建模和预测,以期新方法和模型可为今后类似研究提供新的思路和尝试。
1 研究现状
近年来,学者对育龄妇女二孩生育问题的研究较多。从研究内容上看主要有两个方面:一是研究生育意愿的变化[1];二是研究生育意愿的影响因素[2]。从研究方法上看,现有研究主要采取描述统计和Logistic回归方法。生育意愿在很大程度上决定了生育行为,在宏观层面上一般可以利用全国人口普查数据及人口抽样调查数据对育龄妇女的生育意愿进行估算;但在微观层面上,鲜有研究对生育意愿做出判别与预测。
数据挖掘的方法在分类的判别上已经得到普遍应用。主要的分类模型有决策树、支持向量机和随机森林等算法。决策树模型具有可读性高,分类速度快等优点[3]。李傅冬等在用决策树对意外妊娠妇女人群的流产方式选择进行预测时,误判率仅为11.90%,得出的模型较为稳定,拟合较好[4]。张琪等用决策树模型进行分类判别结核病治疗效果时,得出的准确率为78%[5]。支持向量机模型在分类时运用较多,将向量映射到一个更高维的空间里,对非线性、多维度的小样本数据表现较好[6]。李菲雅等对我国人口预测时,建立了支持向量机模型,结果表明,支持向量机比原有模型在预测查准率有了明显改进[7]。袁勇等将支持向量机方法应用到时间序列问题的预测上,并与神经网络模型预测的结果进行比较, 结果表明支持向量机方法有更高的查准率[8]。傅文杰等用支持向量机模型对土地利用进行分类,通过与最大似然分类算法对比,实验结果表明支持向量机模型在分类查准率上有了很大的提高[9]。随机森林模型是一种多数表决的分类算法,分类拟合效果较好,已得到广泛的应用[10]。马玥等用随机森林算法的农耕区土地利用分类研究,结果表明用随机森林算法的总体准确率为 85.54%[11]。李贞子等在随机森林模型对卵巢良恶性肿瘤进行建模分析,结果表明,随机森林回归模型的结果好于多元回归模型[12]。João Maroco在数据挖掘的方法对老年痴呆进行预测一文中,运用随机森林、支持向量机、神经网络等多种分类方法建立模型,发现随机森林模型的预测结果较好[13]。虽然支持向量机、决策树、随机森林的方法已经有广泛的应用,但在生育意愿问题方面还没有学者涉及,因此本文尝试用以上几种数据挖掘方法对育龄妇女二孩生育意愿进行建模和预测。
2 数据来源及研究方法
2.1 数据来源
本研究数据来源于2015年1月江苏省家庭生育意愿与生育行为研究问卷。调查采用分层抽样方法收集资料,按江苏省地级市进行分层,分别选取江苏省13个地级市;调查对象为20到35岁有江苏省县级及以下户籍的已育一孩的妇女,共发放问卷400份,最终回收有效问卷394份。调查内容包括四个方面:①个人与家庭基本情况,包括夫妻年龄、结婚时间、学历、职业、家庭人口数、经济情况、医疗情况等。②生殖及健康,包括一孩生育时间、小孩性别、夫妻健康状况、是否有人照顾小孩等。③对小孩的期望,包括期望小孩的文化程度、职业、成长满意度、身体健康等。④生育意愿与行为,包括理想孩子数及性别、生育意愿、生育计划、以及打算要或不要孩子的原因等。本文根据以往学者的研究及专家意见,选取对生育意愿有影响的29个变量为自变量,“是否愿意再生育一个孩子”为因变量;由于回答“不确定是否要生育二孩”的家庭,很大程度上是没有考虑过要不要生育二孩,为了减少建模时的不确定性,在分析育龄妇女二孩生育意愿时,仅对有明确意愿的264份数据进行分析。
2.2 分类方法
(1)Logistic回归算法。二项Logistic回归是常见的分类算法,由条件概率分布P(Y/X)表示,随机变量Y取值为1或0。它是研究二分类观察结果与一些影响因素之间关系的一种多变量分析方法,在社会科学领域应用较多[14]。
(2)决策树算法。决策树是一种基本的分类算法模型,模型以树状结构呈现,在分类时,基于基尼系数进行特征的选取;具有可读性好,拟合速度快等优点。在训练数据时,依据损失函数最小化的原则建立决策树模型;预测时,根据决策树模型对新的数据进行分类[3]。
(3)支持向量机算法。支持向量机一般通过分类器和核函数相结合的方法进行建模。通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。它的基本模型是定义在特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。支持向量机多用于分类和回归分析,将向量映射到一个更高维的空间里,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势[6]。
(4)随机森林算法。随机森林是由多个决策树组合而成的机器学习算法;首先,通过自助法采样法,从训练数据中重复随机有放回的抽取m个新的训练集,然后构建m个决策树,通过决策树组建随机森林,未被抽到的样本组成 m个袋外数据,进行误差估计;每棵树生长过程中,从所有特征变量中随机抽取一部分,抽取变量根据基尼系数最小的原则,选取属性最优的进行决策树分支;最后,根据多棵决策树对数据进行预测,根据多数表决的方法选取票数最高的类别;随机森林算法可以产生高准确度的分类器,对于不平衡分类,也能起到较好的建模效果[15]。
2.3 分类评价标准
True positives(TP)表示本身为正,实际也被预测为正的个数;False positives(FP)表示本身为负,但被预测为正的个数;False negatives(FN)是表示本身为正,但被预测为负的个数;True negatives(TN)表示本身为负,实际被预测为负的个数,混淆矩阵见表1。

表1 混淆矩阵Tab.1 Confusion matrix
本文根据以下几个指标评价模型的性能:(1)正确率(Accuracy),Accuracy =(TP+TN)/(TP+FN+FP+TN),是正确分类的样本数与总样本数的比值,正确率越高,分类效果越好。(2)查准率(Precision),precision=TP/(TP+FP),是精确性的度量,表示被分为正例的样本中实际为正的占比。(3)查全率(Recall),Recall=TP/(TP+FN),表示有多少个正例被分为正例。(4)AUC,是ROC曲线下面积,表示处于 ROC 曲线下方的那部分面积的大小,一般AUC的值在0.5到1.0之间,AUC越大,模型准确性越高。(5)Press’Q,是用来检测模型分类结果与随机的分类结果是否与显著性差异,其服从自由度为1的卡方分布,因此当Press’Q的值大于3.84的时候说明其在0.05的显著性水平上是显著的,值越大显著性越强其中N是总的样本数,n是被正确分类的样本数,k是分类组数。
3 建模过程
3.1 算法步骤
为了防止使用相同的数据造成的过拟合和随机现象,我们采用5折交叉验证法,并重复10次,对4种分类器进行训练和测试。步骤如下:(1)把总样本分为5份,每次取其中的4份作为训练集,剩余的1份作为测试集;(2)更换其中1份数据,重复5次训练和测试;(3)重复1、2步骤10次;(4)基于50次实验结果,比较各分类算法的性能。
3.2 模型参数设置及实现
(1)Logistic回归模型,建立模型时调用 R语言软件的“nnet”包里的“multinom”函数,然后用建立的模型对预测集进预测。
(2)决策树模型,建立模型时调用 R软件的“rpart”包;通过设置复杂性参数CP值,对树进行剪枝以确保其准确度,经过多次实验,发现把复杂性参数CP值确定为0.014,模型准确率最高,然后用建立的模型对预测集进行预测。
(3)支持向量机模型,建立模型时调用R语言软件的“e1071”包,建立支持向量机模型。模型的分类器有三种:C分类、nu分类、one分类;核函数一般有四种:线性核函数、多项式核函数、径向基核函数、神经网络核函数。为了选择较好的模型,把三种分类器和四种核函数相结合,共12种组合,分别用训练集建立模型,并检验模型的准确性。通过实验得到最终正确率较高的模型为 nu分类器和径向基核函数组合的支持向量机模型,然后用建立的模型对预测集进行预测。
(4)随机森林模型,调用 R语言软件的“randomForest”包,建立随机森林模型。其重要的参数“mtry”是建立随机森林模型时每次分支时所选择变量的个数,选择合适的“mtry”数量可以提高模型的准确率,通过多次实验,我们确定最佳“mtry”数为15。参数“ntree”是建立模型时生成决策树的数量,“ntree”参数设置较低时会使模型的错误率偏高,较高时会使模型复杂度变高,经过实验发现当“ntree”大于500时,模型的错误率趋于稳定,因此我们把“ntree”设置为 500;然后用建立的模型对预测集进行预测。
4 结果与分析
5折交叉验证法,10次实验的平均结果如表 2所示。随机森林的总体表现最好,与 Logistic回归相比,其正确率高 1.7%,查准率高 3.2%,查全率高0.2%,ROC曲线下的面积大0.3,Press'Q的值大1.7。支持向量机在正确率、查准率、Press’Q 三个评价标准的值也好于Logistic回归。

表2 各分类方法结果对比Tab.2 Th e results of the methods comparison
(1)正确率:图1为四种分类方法正确率的箱线图,可看出准确度最高的是随机森林,然后依次是支持向量机,Logistic回归和决策树。随机森林正确率结果比 Logistic回归集中,说明随机森林结果比较稳定。

图1 正确率箱线图Fig.1 The boxplot of accuracy
(2)查准率:图2为四种分类方法查准率箱线图,可以看出查准率最高的是随机森林,然后依次是支持向量机、Logistic回归和决策树。

图2 查准率箱线图Fig.2 The boxplot of precision
(3)查全率:图3为四种分类方法查全率箱线图,可以看出查全率最高的是随机森林,然后依次是Logistic回归、支持向量机和决策树。
(4)AUC:图4为四种分类方法AUC的大小,可以看出 AUC最高的是随机森林,然后依次是Logistic回归、决策树和支持向量机。
(5)Press’Q:图 5为四种分类方法 Press’Q 的大小,可以看出准确度最高的是随机森林,然后依次是支持向量机、Logistic回归和决策树。
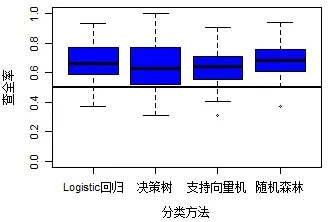
图3 查全率箱线图Fig.3 The boxplot of recall

图4 AUC 箱线图Fig.4 The boxplot of AUC
综上所述,四个分类模型的Press'Q检验结果的中位数均大于 3.84,表明所有分类方法都好于随机结果。在各模型中随机森林模型在正确率,查准率、查全率、AUC和Press'Q这5个评价标准中均表现最好;且随机森林结果较Logistic回归更为稳定。
5 结论
本文利用决策树、支持向量机、随机森林、Logistic回归模型,对育龄妇女二孩生育意愿建模,并对二孩再生育意愿进行预测。结果表明随机森林模型在5个分类评价标准的表现均好于学者广泛应用的 Logistic回归模型;支持向量机在准确率、查准率、Press’Q三个指标上也好于Logistic回归模型,因此在研究育龄妇女二孩生育意愿时可以考虑随机森林的方法进行建模,这种新方法和模型可为今后类似问题研究提供新的思路和尝试。随机森林对样本量较大数据分类结果更好,而本研究的样本量偏少,因此在实际研究工作中加大样本量可提升预测的准确率。
[1] 贾志科. 20世纪50年代后我国居民生育意愿的变化[J]. 人口与经济, 2009(4): 24-28.Jia Zhike. The Change of Chinese Inhabitants' Willing of Fertility in the 1950s[J]. Population and Economy, 2009;(4): 24-28.
[2] 孙奎立. 农村妇女生育意愿影响因素分析[J]. 人口学刊,2010, 2010(3): 20-24.Sun Kuili. An Analysis to the Factors Affecting the Fertility Desire of Rural Women. Journal of Population[J] , 2010;2010(3): 20-24.
[3] Breiman L, Friedman J H, Olshen R, et al. Classification and Regression Trees[J]. Biometrics, 2015, 40(3): 358.
[4] 李傅冬, 黄丽丽, 俞艳锦, 等. 决策树结合Logistic回归分析妊娠妇女选择人工流产方式的影响因素[J]. 浙江预防医学, 2015; (4): 328-333.Li Fudong, Huang Lili, Yu Yanjin, et al. Decision factors and logistic regression analysis of influencing factors of artificial abortion to pregnant women[J]. Zhejiang Preventive Medicine, 2015; (4): 328-333.
[5] 张琪, 周琳, 陈亮, 等. 决策树模型用于结核病治疗方案的分类和预判[J]. 中华疾病控制杂志, 2015; 19(5): 510- 513.Zhang Qi, Zhou Lin, Chen Liang, et al. The decision tree model used to classify and predict tuberculosis treatment programs[J]. Chinese Journal of Disease Control, 2015; 19(5):510-513.
[6] Cortes C, Vapnik V. Support-Vector Networks. Machine Learning, 1995; 20(3): 273-297.
[7] 李菲雅, 蒋若凡. 基于主成分和支持向量机模型在人口预测中的应用[J]. 西北人口, 2012; 33(1): 29-32.Li Feiya, Jiang Ruofan. Application of Principal Component and Support Vector Machine Model in Population Forecasting[J]. Northwest population, 2012; 33(1): 29-32.
[8] 袁勇, 王攀. 支持向量机在人口预测中的应用[J]. 计算机与数字工程, 2006; 34(5): 9-11.Application of Support Vector Machine in Population Forecasting[J]. Computer and Digital Engineering, 2006; 34(5):9-11.
[9] 傅文杰, 洪金益, 林明森. 基于光谱相似尺度的支持向量机遥感土地利用分类[J]. 遥感技术与应用, 2006; 21(1):25-30.Fu Wenjie, Hong Jinyi, Lin Mingsen. Remote sensing land use classification based on support vector machine[J]. Remote sensing technology and application, 2006; 21(1): 25-30.[10] Breiman L. Random Forests. Machine Learning, 2001, 45(1):5-32.
[11] 马玥, 姜琦刚, 孟治国, 等. 基于随机森林算法的农耕区土地利用分类研究[J]. 农业机械学报, 2016; 47(1):297-303.Ma Yue, Jiang Qi Gang, Meng Zhiguo, et al. Study on Land Use Classification of Farming Area Based on Random Forest Algorithm[J]. Journal of Agricultural Mechanics, 2016; 47(1):297-303.
[12] 李贞子, 张涛, 武晓岩, 等. 随机森林回归分析及在代谢调控关系研究中的应用[J]. 中国卫生统计, 2012; 29(2): 158-160.Li Zhenzi, Zhang Tao, Wu Xiaoyan, et al. Random Forest Regression Analysis and Its Application in the Study of Metabolic Regulation[J]. China Health Statistics, 2012; 29(2):158-160.
[13] Isabel S, Manuela G, Ana R, et al. Data mining methods in the prediction of Dementia[J]. Bmc Research Notes, 2011;4(1): 299-299.
[14] Hosmer D W J, Lemeshow S L. Applied Logistic Regression.Hoboken[J]. WILEY-INTERSCIENCE, 2000.
[15] Liaw A, Wiener M. Classification and Regression by randomForest[J]. R News, 2002, 23(23).
Prediction to the Second Childbearing Desire of Fertile Woman Based on Data Mining
LI Dong-ling
(Nanjing University of Posts and Telecommunications School of Economics, Nanjing 210046, P.R.China)
To discover the accuracy of the second childbearing desire of matured women based on the comparison between data mining methods and Logistic regression. Three classifiers derived from data mining methods (Support Vector Machines, Decision Tree and Random Forests) were compared to Logistic Regression in terms of overall classification accuracy, Precision, Recall, AUC and Press’Q. The results showed that the Press’ Q test showed that all classifiers performed better than chance alone(Press’Q >3.84). The Random Forests gained the best performance from the perspective of means, and the accuracy was 1.7% over Logistic regression, specificity 3.2%, sensitivity 0.2%, AUC 0.029 and Press’Q 1.7. The new methods and model this paper adapted would provide new perspectives for the following researches.
Data mining; Second childbearing desire; Modeling; Prediction
C924.24
A
10.3969/j.issn.1003-6970.2017.11.010
本文著录格式:李冬领. 基于数据挖掘的育龄妇女二孩生育意愿预测[J]. 软件,2017,38(11):55-59
江苏省研究生培养创新工程项目“基于数据挖掘的江苏省育龄妇女二孩生育意愿预测(SJLX16_0318)
李冬领(1988-),男,中级统计师,研究方向:信息统计与数据挖掘。
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
现代电子技术(2018年16期)2018-08-21
现代电子技术(2017年23期)2017-12-20
电力与能源(2017年6期)2017-05-14
计算机应用(2016年10期)2017-05-12
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
信息通信技术(2015年6期)2015-12-26
郑州大学学报(医学版)(2015年1期)2015-02-27
电子设计工程(2014年18期)2014-02-27
